
基于最长前缀频繁子路径树的Web日志挖掘算法
2013-09-18 02:25:34林开标朱顺痣王震岳
成都大学学报(自然科学版) 2013年3期
翁 伟,林开标,朱顺痣,王震岳
(厦门理工学院计算机与信息工程学院,福建厦门 361024)
基于最长前缀频繁子路径树的Web日志挖掘算法
翁 伟,林开标,朱顺痣,王震岳
(厦门理工学院计算机与信息工程学院,福建厦门 361024)
现有的Web日志频繁访问路径挖掘算法往往不能在追求时间效率的同时准确挖掘出符合用户浏览顺序的频繁路径.提出了有效挖掘Web日志中频繁访问路径的算法,将事务数据库转换为Web访问路径树,根据支持度进行剪枝构造最长前缀频繁子路径树,然后进行频繁路径挖掘,实验证实了此方法的有效性,并分析了支持度设置对频繁路径生成的影响.
Web日志挖掘;频繁访问路径;访问路径树
0 引言
Web日志挖掘近年来逐渐成为数据挖掘领域的热点.Web站点日志存储了用户访问网站的踪迹.目前常见的Web日志数据格式有NCSA、扩展W3C和IRCache等[1],记录的数据主要包括用户的IP地址、访问时间、访问页面、访问方式、引用页面等.Web日志频繁路径挖掘通过分析Web日志记录发现用户的访问规律,分析和掌握用户访问Web站点的行为,对重构网站、个性化推荐、广告投放等方面有重要的参考价值[2].目前,Web日志挖掘研究主要集中在2个方面,一是认为用户的浏览频度就反映了用户的访问兴趣[3-6],二是泛化兴趣度的计算方法[7-9].兴趣度定义本质上在于从不同角度来约简频繁路径,减少问题规模,如何快速准确地挖掘出日志中隐含的频繁访问路径是各类算法追求的共性目标.本研究在访问路径树性质的研究基础上,给出了一种高效的基于最长前缀频繁子路径树的Web日志挖掘算法.
1 相关概念
Web日志数据经过数据清洗、用户识别、会话识别等预处理步骤后,将访问信息转换为访问事务数据库,该数据库的记录为用户的会话,由按访问顺序的页面所构成.这些记录集是频繁访问路径挖掘的对象.
定义1 设U是网站中所有页面的集合,记U={p1,p2,…,pn},会话S表示用户对网站的一次完整访问,记作S=〈pi,pi+1,…,pi+m〉,其中pi,pi+1,…,pi+m∈U,也就是说,会话是由有顺序的页面标记所构成的字符串,亦即访问路径序列,pi是用户访问的第一个页面,pi+m是用户访问的最后一个页面,但这些页面可以重复,S的子串称为访问路径,简称路径.
定义2 Web访问事务数据库由某一时间区间的会话集合构成,每一条会话为该数据库中的一条记录,也称事务,事务由项目构成.
定义3 如果一条访问路径,p=〈pj,pj+1,…,pj+m〉,满足以下条件,

则称路径p为频繁访问路径.其中0≺N≺1是预先定义好的最小支持度.
定义4 如果一条访问路径q=〈pk,pk+1,…,pk+n〉是路径p=〈pj,pj+1,…,pj+m〉(m≻n)的子路径,并且k=j,那么称q为p的前缀子路径.类似可以定义后缀子路径,若q是频繁的,则称q是p的频繁前缀子路径,进一步,如果p中不存在更长的频繁前缀子路径,则称q是p的最长频繁前缀子路径.
定义5 若路径p=〈pj,pj+1,…,pj+m〉的前缀子路径q=〈pj,pj+1,…,pj+m-1〉是路径r=〈pk,pk+1,…,pj+n〉的后缀子路径,则定义路径r与p之积r×p=〈pk,pk+1,…,pk+n,pj+m〉,否则r×p为空.一般而言,r×p不等于p×r.路径集合PS1与路径集合PS2之积PS1×PS2为PS1中每条路径与PS2中每条路径之积的结果集.
2 算法描述
本研究提出的算法如图1所示.

图1 频繁访问路径挖掘算法示意图
2.1 输入事务数据库
输入事务数据库主要是将Web日志数据进行数据清洗、用户识别和会话识别,这样就可将Web日志数据转换成了事务数据库.Web日志包含网页上所有多媒体元素,比如有后缀为.ico、.gif、.jpg、.css、.wmv、.swf等文件读取的记录,这些内容与频繁路径挖掘无关,需要清洗掉;用户识别主要是根据用户的IP地址、浏览器类型或网站拓扑结构来判断2条记录是否是同一用户的访问行为;会话是用户对网站的一次连续有效的访问,表现形式就是访问路径序列,如果同一用户先后请求的两个页面在规定的时间间隔内,则这2个页面属于同一会话,因此,一个用户对应的访问记录可能对应一条或多条会话记录.
2.2 构建访问路径树
Web日志数据经过数据预处理后,形成事务数据库,如表1所示.对该数据库的记录逐条处理生成访问路径树,该路径树每条从根节点到叶子节点的路径由一条或多条记录构成,如图2所示.

表1 一个Web访问事务数据库
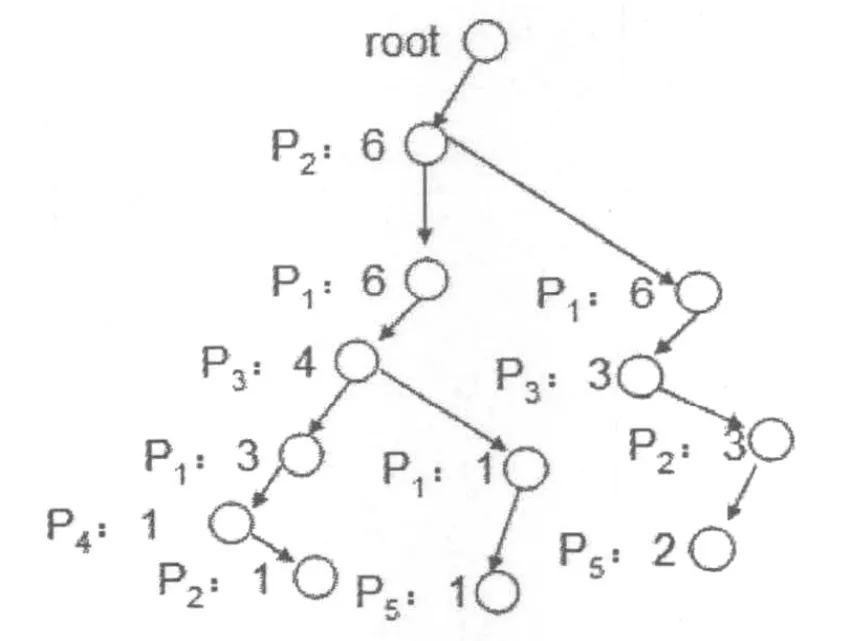
图2 Web访问路径树
Web访问路径树除root节点外,其余各节点均代表页面及该页面出现的次数,分别用page和num表示.由Web访问事务数据库构建Web访问路径树采用孩子兄弟法存储.
算法1 构建Web访问路径树.

2.3 生成最长前缀频繁子路径树
路径树上节点的num值反映了该节点访问的频繁度,例如图2中最左侧分支中的节点p1的num值为3,反映了前缀为p2p1p3p1的访问路径有6条.若|事务数据库 D|*N=3,那么由p2p1p3p1生成的P2P1、P1P3、P2P1P3、P3P1、P1P3P1 和 P2P1P3P1 均是频繁路径.根据这个思路,只要找到路径树上每条从根到叶子的路径中的最长频繁子路径,就可以根据这些最长频繁子路径生成频繁路径.
从图2可发现,若将所有的最长频繁子路径合成为一个树,则该树是图2的子图,并且该图是原图的上半部分.例如,若|D|*N=3,那么图2所示的Web访问路径树的所有最长频繁子路径合成的图如图3所示,不妨称该图为最长前缀频繁子路径树.对此,先序遍历Web访问路径树,删除num值少于|D|*N的节点所表示的子树,即可生成最长前缀频繁子路径树.
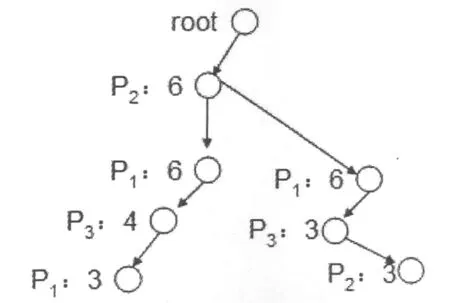
图3 最长前缀频繁子路径树
算法2 构建最长前缀频繁子路径树.

2.4 产生频繁访问路径集
先考虑单支最长频繁前缀子路径产生频繁访问路径集的过程,例如图3中的路径P2P1P3P1,表2是其挖掘过程.

表2 单支最长频繁前缀子路径产生频繁访问路径的挖掘过程
频繁访问路径集合frequentPS初始值为空,当前访问节点为P2,frequentPS1和frequentPS2为中间结果,初始值均为空.frequentPS1i=frequentPS2i-1∪frequentPS3i-1表示第i步的frequentPS1等于第i-1步的frequentPS2并上第i-1步的frequentPS3.当某步骤中frequentPS2为空时程序结束.
对整棵最长前缀频繁子路径树而言,可以遍历出所有从根到叶子的路径,再逐条路径进行产生频繁访问路径,也可以根据有些路径其前缀是相同的这一点设计算法,从而减少重复计算.
3 实验分析
在实验分析时,本研究采用DePual大学提供的标准数据集[10],来自 DePaul CTI Web 服务器(http://www.cs.depaul.edu)数据的采集是随机抽取在2002年4月2个星期中访问这个网站的用户.本实验采用cit.tra和cti.cod这2个数据集,cit.tra中包含了13 745条访问路径,这些路径均由cit.cod中的683个页面中的一个或多个组成.将每个页面用一个整数标志,那么访问路径序列也就转换为一系列有序整数.
相对传统的Apriori算法,本研究所提算法不必进行链接操作来生成频繁项集,而是直接用最大频繁项集来生成各子频繁项集;相对文献[6]来说,虽然都是利用了树结构,但文献[6]中又将访问路径树转换成邻接表,再通过邻接表转换为频繁路径,而本研究算法直接利用二叉树进行剪枝,减少了运算过程中问题规模.比较而言,本研究所提算法的时空效率显然具有明显的优势.
本实验主要研究支持度N与叶子节点数、频繁路径数的关系,实验中除去了长度为1的频繁路径.实验所生成的频繁路径符合实际情况(见图4),从实验结果可以发现,0≤N≤6时,随着支持度N的增加,叶子节点急剧减少,但再增加N的值,叶子节点缓慢变小,且最长前缀频繁子路径树的叶子节点数目的关系也有类似的现象,同时还发现,支持度N为8的时候,可以将频繁路径条数控制在1 000以内.

图4 支持度N与叶子节点数、频繁路径数的关系
4 结语
目前大多数Web日志频繁访问路径挖掘算法可以归为2类:类Apriori算法和访问路径树算法.类Apriori算法运算量大,需要多次扫描数据库,中间结果非常占内存;频繁树算法一般只需扫描一次事务数据库,但需要多次构建树,空间消耗大,并且存在不能挖掘出连续可重复的频繁访问路径的问题.本研究提出的算法属于访问路径树算法,构建访问路径树只需扫描一次事务数据库,从上到下遍历此树各节点,删除下端的非频繁节点,即将该树减枝成一棵最长前缀频繁树,再根据从根到叶的路径生成频繁路径,保证了频繁路径与用户访问路径是一致的.实验分析可以看出,支持度的变化对频繁路径数目的影响,当支持度大于6时频繁路径数目变化趋于平缓,因此可以将6设置为大型网站频繁访问路径挖掘算法支持度的经验值.
:
[1]NLANR/NSF.IRCache Users guide[EB/OL].[2008-03-18].http://www.ircache.net/.
[2]韩家炜,孟小峰,王静,等.Web挖掘研究[J].计算机研究与发展,2001,38(4):405-413.
[3]Chen M S,Park J S,Yu P S.Data mining for path traversal patterns ina Web environment[C]//Proceedings of the16th International Conference on Distributed Computing Systems.Hong Kong:IEEE Press,1996:385-392.
[4]战立强,刘大昕.基于访问树路径的Web频繁访问路径挖掘算法研究[J].计算机应用研究,2005(1):96-98.
[5]Agrawal R,Imielinski T,Swami A.Mining association rule between sets of items in large databases[C]//Proceedings of ACM SIG-MOD Conference on Management of Data(SIGMOD'93).Washington,USA:ACM Press,1993:207-216.
[6]曹忠升,唐曙光,杨良聪.Web-Log中连续频繁访问路径的快速挖掘算法[J].计算机应用,2006,1(26):216-219.
[7]翁伟.Web日志频繁访问路径挖掘算法[J].信息与电脑,2012(24):76-77.
[8]邢东山,沈钧毅,宋擒豹.从Web日志中挖掘用户浏览偏爱路径[J].计算机学报,2003,26(11):1518-1523.
[9]王思宝,李银胜.基于Web日志挖掘用户的浏览兴趣路径[J].计算机应用与软件,2012,29(1):164-167.
[10]Mobasher B.Research Interests[EB/OL].[2013-01-01].http://maya.cs.depaul.edu/~ classes/ect584/resource.html.
Web Logs Mining Algorithm Based on Longest Prefix Frequent Sub-path Tree
WENG Wei,LIN Kaibiao,ZHU Shunzhi,WANG Zhenyue
(College of Computer and Information Engineering,Xiamen University of Technology,Xiamen 361024,China)
The existing web logs mining algorithm for frequent access path often can not accurately meet the users'accessing order in pursuit of time efficiency.An efficient web logs mining algorithm for frequent access path is proposed,which converts the transaction database to web access path tree and prunes the tree branches to create the longest prefix frequent sub-path tree according to support degree,and then the mining process is implemented.The experiment confirms the effectiveness of this method,and analyzes the impact of the settings of frequent support degree on frequent paths generation.
web logs mining;frequent access path;WAP-tree
TP311.1
A
1004-5422(2013)03-0285-04
2013-05-28.
厦门市科技计划高校创新课题(3502Z20123037)、福建省教育厅B类课题(JB09196)资助项目.作者简介:翁 伟(1979—),男,硕士,讲师,从事知识发现与Web数据挖掘技术研究.
猜你喜欢
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
保健医苑(2022年1期)2022-08-30 08:39:14
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
河南水利年鉴(2020年0期)2020-06-09 05:43:44
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
电子设计工程(2014年19期)2014-02-27 12:00:42
长春大学学报(2013年8期)2013-06-21 09:04:04
电脑爱好者(2011年11期)2011-06-22 08:20:18
