
面向航空制造业的海量数据处理研究
2013-09-12 03:23王东勃
机械设计与制造工程 2013年4期
吴 恒,王东勃
(西北工业大学机电学院,陕西西安 710072)
面向航空制造业的海量数据处理研究
吴 恒,王东勃
(西北工业大学机电学院,陕西西安 710072)
为了向航空制造业的海量数据处理提供一种新颖的模式,以Hadoop开源软件平台为架构,介绍了HDFS分布式存储系统和Map-Reduce编程模式,分析了航空制造业海量数据处理需求,提出了一种应用于航空制造业的海量数据处理模型,即将数据格式划分为若干个主要字段,按照该数据格式在分片中对数据进行深度优先挖掘,将提取出的数据以键值对的形式并按照一定的存储格式存储于HDFS中,利用Map-Reduce并行算法对存储的数据进行排序和分区处理。最后提出了基于K-NN的并行化数据挖掘算法,且分析了海量数据处理模型的扩展性、实时性和快速处理等性能。
航空制造业;海量数据;Hadoop;数据处理模型;键值对;算法
航空制造业的数据发生了很大的变化。从航空制造过程看,产品的设计研发产生的二维文档或三维模型数据,生产制造产生的BOM表、工装数据和日志数据,实验过程中采集的数据,到最后的装配数据,这些数据总量至少是PB级别。从数据结构来看,除了结构化数据,生产制造过程产生的更多是非结构化数据和半结构化数据。然而目前使用的关系型数据库很难胜任海量数据的存储和分析计算,大多数面向航空制造业的优秀产品数据分析处理软件也很难满足海量数据处理的要求。因此,需要寻求一种新的海量数据处理方式来支持航空制造业的海量数据处理。
本文所研究的内容是基于Hadoop[1]开源软件平台,它集成应用了机器集群技术、网格技术和分布式文件系统,可以方便实现存储空间的扩展、数据容错以及数据的高效处理。
1 Hadoop核心技术和Map-Reduce编程模型
Hadoop是一种开源软件平台,能够更加容易地编写可处理海量数据的并行应用程序。它使用了一种分布式文件存储系统HDFS[1],这种分布式文件系统提供一个分布式集群存储环境,使得海量数据能够遍布存储于该大集群环境上,并且将之前分类好的数据再进行分块序列式存储。
HDFS是一个主从体系结构[1],如图1所示。HDFS提供了访问海量数据的支持。HDFS分为两种节点:名称节点(Namenode[2])和数据节点(Datanode[2])。这两种节点是运行在计算机上的软件。在集群中,只有一台专门计算机负责运行唯一的名称节点,其他机器则分别运行着数据节点。名称节点负责维护文件的命名空间以及文件数据块复制的大小。数据节点将HDFS数据块存储在本地文件系统中[2]。

图1 HDFS主从体系结构
Map-Reduce[3]是一种可用于处理数据的编程模型。这种模型是采用并行运行的模式,因此可以将海量数据处理任务交给任何一个拥有机器集群的系统,Map-Reduce的优势就在于可以高效处理海量数据。这种编程模型的任务过程拥有两个处理阶段,依次是Map阶段和Reduce阶段。
在Map阶段之前,输入的数据被切分为若干个数据片段,并且数据以(Key-Value)键值对[1]的形式输入,记为(K1,K2)。每个Map函数接收一个数据片段,这些Map函数是分布在若干个计算机节点上执行的,处理的结果是输出(K2,V2),并且作为Reduce阶段的输入数据。Reduce阶段之前,对这些(K2,V2)数据进行分类,得到数据集(K2,list(V2)),然后分布在不同节点上的Reduce函数将对数据集进行处理汇总,得到(K3,V3)并存储在HDFS上。
2 海量数据处理模型的建立
2.1 航空制造业海量数据处理需求
由于航空制造产业链数据量大、种类多等特点,所以对这些数据进行分类、计算分析、搜索等相关处理是个庞大的任务。这就要求:(1)数据处理模型在处理数据时具有很好的实时性,即能够及时处理实时数据,保持数据的及时更新。例如一个零件的数据更改后,后续零件加工和装配的数据需及时更新,确保数据的一致性。(2)要能够从不同应用程序中提取出相关数据并且进行分类汇总,便于数据分析。例如从CAD、CAM、PDM、BOM和其他信息管理系统中挖掘提取出某一产品的设计数据、制造数据、元数据和材料等数据,需对这些数据进行分析汇总,计算出制造这种产品的周期、费用或者报表等。(3)要能够从海量数据日志中挖掘提取出所需信息。例如对某一加工过程产生的数据日志进行数据分析,得到设备的使用情况,零件加工合格率情况和加工时间等信息。(4)要能够确保数据存储的可扩展性,这是考虑到由于产品的不断更新,历史数据需要保存备份,且不断开发新的产品,数据源源不断产生,因此就要求系统有很好的扩展性,能够很好地存储新的海量数据。(5)要能够做到容灾性,一旦某个节点上的数据发生错误或丢失,要能够确保数据的及时恢复,以免造成严重的数据损失。
2.2 海量数据的数学问题描述
数据集是从数据源头也就是CAD系统、SAP系统、PDM系统和PLM等系统中获取的信息,并且直接存储在HDFS中。假设每条数据包基本信息(可根据实际扩展字段名)含文件名Name、文件格式 Format(doc、dwg、prt、txt、rm 等)、创建日期Date、创建者 Person、位置 Location和版本 Version等6类信息,建立数据集A={Xi;Xi∈Y,i=0~5},其中Xi是一条数据的具体信息,Y是Xi集合。求解的目标是从数据集中提取出所需的信息,并且对信息进行检索、排序、加权等分析。对建立的数据格式描述如下:Name表示文件名;Format表示文件的格式;Date表示文件创建的日期;Person表示文件的创建者;Version表示文件的版本;Location表示文件存储的节点位置;ID表示文件的唯一标识。
2.2.1 数据挖掘
按照数据在HDFS中存储的结构(如图2所示),对数据进行深度优先挖掘。算法步骤如下:(1)选择一个未挖掘节点。如果所有的节点已经挖掘完,算法结束。(2)在已经选择的节点中,选择一个尚未挖掘的分片,如果本节点下的所有分片已经完成数据挖掘,返回步骤(1)。(3)在已经选择的分片中,依次对文件元数据字段进行挖掘,直到挖掘完成所有的字段。(4)返回步骤(2),对未挖掘的分片继续挖掘。
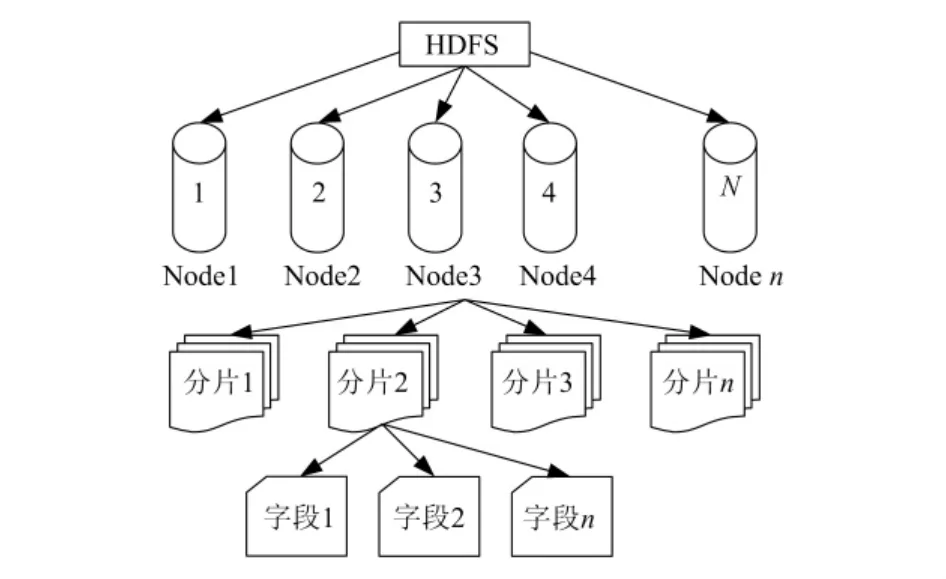
图2 数据在HDFS的存储结构
2.2.2 数据的提取和存储
将挖掘出的数据按照键值对形式存储在分布式文件系统HDFS中,其中默认文件类型(如txt、doc、rmvb等格式)为Key。这些数据将作为Map-Reduce程序处理的输入源头,如何对其中的有效信息进行提取处理将是很关键的环节。
数据的提取就是从数据挖掘过程中得到的一条条信息里取出我们需要的数据,并且设计一种格式,再次保存在HDFS中,然后再覆盖原文件。根据上文的数学描述,需要从挖掘的信息中抽取出6种字段信息:文件名Name、文件格式Format、创建日期 Date、创建者 Person、位置 Location和版本Version。存储的格式应当适合长期保存并且易于处理,具备简单性、易于存取和易于扩展等优点。出于上述考虑,存储的格式定义为:(1)存储的源文件由若干条元数据构成。(2)元数据记录了若干条信息,并且按照顺序追加方式依次存放每条元数据。(3)元数据的字段之间用换行符'�07'(不可显示的 ASCII码)分隔开,元数据之间用' '(换行符)分隔开,例如 Name'�07'Format'�07'Date'�07'Person'�07'Location'�07'Version' '。采用这种格式保存信息,容错性好,即使是数据被损坏,也是局部性的,不会扩散并导致其他数据无法存取。按照上述格式,将文件存储到HDFS中。
2.2.3 基于Map-Reduce进行数据处理
对输入的数据按照上述方法进行分割,预先将其中之一关键字设定为Key值,从海量数据产生的源头开始,建立不同的节点,来读取并存储不同应用软件的数据,这些节点存储着最原始的数据。然后通过HDFS中唯一的Namenode对数据进行分块,建立数据块文件系统并将分块后的数据存储在Datanodes中,使得数据可以进行分布式存储。Map-Reduce数据处理的步骤如下:(1)从6个字段中选择若干个需要检索排序的字段作为Key,可以选择若干个字段作为复合键[1]。(2)进行Map处理,对数据进行分片,Map处理得到(Key,Value),其格式为<a,b:c:d>。其中a是前4个字段,b是字段频度,c和d是后2个字段。(3)利用Map-Reduce内嵌的排序和分区功能,由系统按照复合键自动完成排序。(4)在Reduce阶段,把频度值b从复合键中拆出,与c、d重新合并为最终的Value,得到的(Key,Value)格式为 <a,b:c:d>,这样就得到了按照检索字段和频度值排序的检索结果,基于Map-Reduce的数据处理过程如图3所示。具体的实例化算法如算法1和2描述。
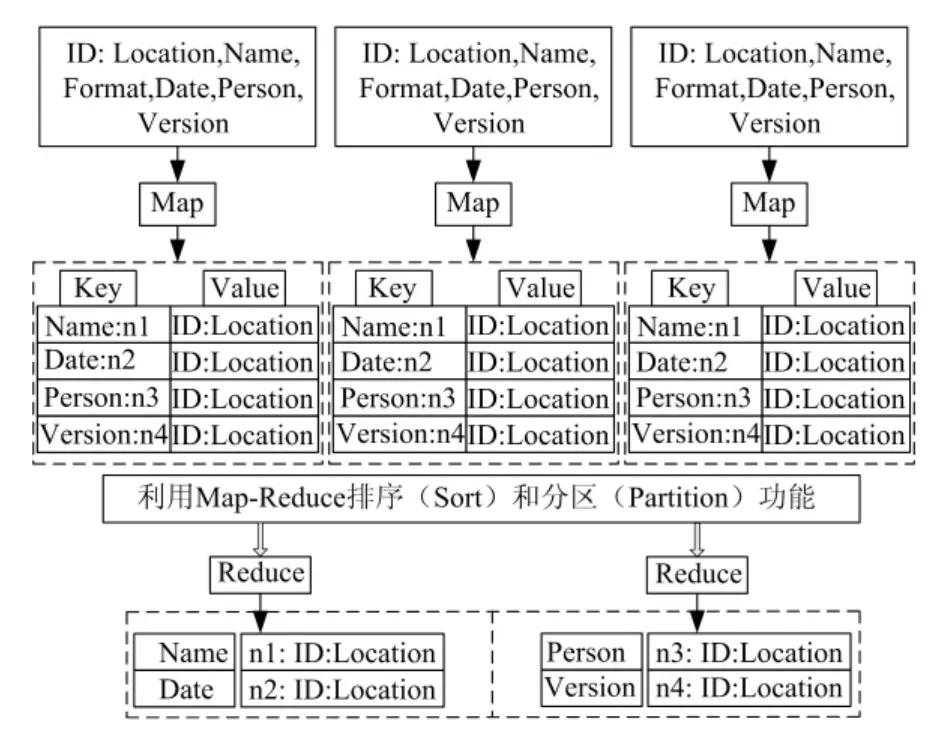
图3 基于Map-Reduce的数据处理过程

2.2.4 K-NN搜索算法的并行化处理实现
由于在挖掘和搜索海量数据过程中,若采用原始算法,则效率不高。若把原始算法和并行处理的Map-Reduce过程相结合,效率会有所提高。本文对基于K-NN搜索算法的数据处理过程进行并行化改进,输入数据Key是数据文件的ID,输入数据Value是训练样本的内容,每个样本集包含数据集的5条字段值,而中间结果的Key值定义成标识,Value值是相似的字段值和目标字段值的结合。在Reduce函数中,Key表示是标识信息,Value是预测的字段值。并行K-NN算法Map-Reduce化的伪代码如算法3和4描述。


3 性能分析
采用基于Hadoop的海量数据处理模型具有如下几个优点:(1)数据的高效处理。采用Hadoop分布式处理,并且融合了采用并行化K-NN搜索算法,数据在不同的节点上进行实时处理,支持各个文件数据块的并行访问,使得数据处理速度得到提高。(2)系统存储性能易于扩展。根据负载规模增删Hadoop数据节点,实现透明扩展,为海量数据提供良好伸缩性的存储空间,而且Hadoop的分布式存储是将廉价的计算机建立成集群,其成本相对低廉。(3)对文件数据进行了分块和复制,并且定义了数据的存储格式。把数据划分为若干个数据块,有利于对数据内容的查找和定位,同时数据块复制后分布存储在不同节点,可以提高系统的可靠性和容灾性,而且可以并行访问分布在不同节点上的相同复制后的数据,改善了访问性能。
4 结束语
本文将Hadoop框架引入到航空制造业的海量数据处理之中,提供了一种新颖、实用的海量数据处理方法。利用Map-Reduce对海量数据进行了分类、划分处理,并且所采用的并行化K-NN搜索算法能有效地解决数据搜索算法的效率低的问题。本文为海量数据处理提供了Hadoop框架和算法实例,为今后的软件架构和程序编写提供了指导。下一步深入研究的方向是构建硬件环境即分布式机器群,并将Hadoop框架和算法植入到该机器群中,进行相关海量数据处理实验。
[1]刘鹏,黄宜华,陈卫卫.实战Hadoop:开启通向云计算的捷径[M].北京:电子工业出版社,2011:15-20.
[2]怀特.Hadoop权威指南[M].周敏奇,曾大聃,周傲英,译.北京:清华大学出版社,2011:20-40.
[3]Dean J,Ghemawat S.Mapreduce:simplified data processing on large cluster[C]//Brewer E,Chen P.Proc.of OSDI.California:USENIX,2004:137 -150.
[4]何元.基于云计算的海量数据挖掘分类算法研究[D].成都:电子科技大学,2011:75-79.
Research on Mass Data Processing Oriented to Aircraft Manufacturing Industry
WU Heng,WANG Dongbo
(Northwestern Polytechnical University,Shannxi,Xi'an,710072,China)
In order to provide a new model of mass data processing for aircraft manufacturing industry,it proposes a model of mass data processing for aircraft manufacturing industry based on Hadoop software platform,introduces the HDFS and the Map-Reduce programming model,analyzes the demand of mass data processing for aircraft manufacturing industry,introduces a kind of data processing model.This system can divide the data format into several major fields,mine the data from sharding deeply and firstly according to the data format,store the extracted data in HDFS in the format of key-value and the defined storage format,sort and partition the storage data in the method of Map-Reduce.Lastly,it illustrates a parallel data mining algorithm based K -NN,and analyzes the expansibility,instantaneity and quick processing of this kind of mass data processing model.
Aircraft Manufacturing Industry;Mass Data;Hadoop;Model of Data Processing;Key-value;Algorithm
TP399
A
2095-509X(2013)04-0028-04
10.3969/j.issn.2095 -509X.2013.04.007
2012-10-29
吴恒(1988—),男,陕西西安人,西北工业大学硕士研究生,主要研究方向为信息化。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
江苏科技信息(2022年16期)2022-07-17
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
当代陕西(2019年14期)2019-08-26
中学数学杂志(初中版)(2016年5期)2016-11-01
中国惯性技术学报(2015年1期)2015-12-19
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
测绘科学与工程(2014年2期)2014-02-27
