
云数据库体系架构研究分析
2013-09-11 00:57刘桂兰王书海
河北省科学院学报 2013年2期
刘桂兰,王书海
(石家庄铁道大学 信息科学与技术学院,河北 石家庄 050043)
互联网已经成为当今人们生活中不可或缺的一部分。一方面,随着Web2.0的流行以及云计算技术的发展,超大规模和高并发的社交网站迅速兴起[1],人们对互联网的需求远不局限于网页信息的浏览,而是通过浏览器获取各种各样的服务。另一方面,互联网数据中心的研究报告显示,在未来几年中,企业对于结构化以及非结构化的数据存储需求会每年都会增长,但对非结构化数据需求增长幅度相对较大。同时,在数据库知识网站DB-Engines最新一期的数据库产品流行度排名中,位于前10名的大部分是基于关系数据模型的数据库,以及少部分的非关系数据模型数据库,但从整体来看,Relational DBMS处于下降的趋势,而对非关系数据模型的数据库的需求越来越多。
面对数据的海量存储以及需求的动态变化,传统关系型数据库已经显得力不从心。为了满足互联网发展以及互联网用户对数据海量存储的需求,Amazon、Google、Microsoft等公司相继对云数据库管理系统进行了深入研究,并生产了自己企业的云数据库。具有代表性的云数据库有Amazon的simpleDB、Google的BigTable以及yahoo的PNUTS等。
1 云数据库概述
通俗的理解,云数据库就是部署在云计算[2]环境中,并利用云计算的特性来提升自身的服务质量,满足用户新需求的数据库。云数据库是随着SaaS(Software as a service;软件即服务)应用的兴起而发展起来的一种云计算技术,它在数据库的存储能力方面有了很大的提高,并在一定程度上消除了对软件、硬件以及人员的重复配置,让软硬件的升级变得更加方便,与此同时也虚拟化了很多后端的功能[3]。与传统的关系数据库相比,云数据库具有显著的优势[1,3]:海量性、种类多样性、动态可扩展性、高可用性、较低的使用代价、易用性、大规模并行处理等。
2 云数据库系统体系架构
云数据库的系统体系架构多种多样,本文主要介绍采用键/值数据模型和关系数据模型的系统体系架构以及可扩展分布式关系型系统体系架构[3,4,5]。
2.1 HBase体系架构
HBase(Hadoop Database),是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase是谷歌Bigtable的开源实现,其采用的架构和Bigtable类似[3]。如图1所示。
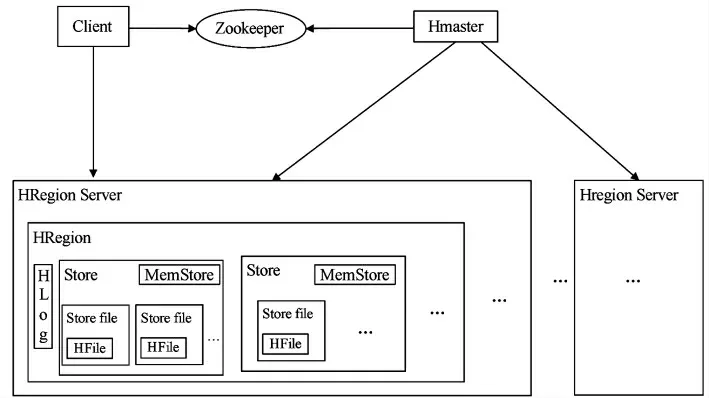
图1 Hbase的体系架构
HBase体系架构中主要包括5部分,分别为:Client,Zookeeper,Hmaster,HRegionServer和Store,具体功能如下[3]:
(1)Client:为用户访问数据库提供了接口。
(2)Zookeeper:主要用于存储数据库模式和所有HRegion的地址,并实时监控HRegion-Server的状态。
(3)HMaster:主要为每个HRegionServer分配其要维护的HRegion 群组,实现负载均衡,HBase中仅有一 个Master server。
(4)HRegionServer:每个HRegionServer主要用于管理多个HRegion,确保其能为Client提供服务,并及 时向HMaster提供自己的运行状况信息。
(5)Store:主要用于实现数据库的存储功能,其由两部分组成:MemStore和StoreFiles。更新数据首先会存储到MemStore中,并当MemStore数据存储满了之后再将数据存储到StoreFile中,其中StoreFile存放在分布式文件系统的HFile中。
2.2 SQL Azure体系架构
SQL Azure[6]是一种基于云计算的关系型数据库服务,基础架构类似于SQL Server 2008,但它与SQL Server 2008有所不同,其在内部包含了很多虚拟服务器,可以根据需求的动态变化而改变参与计算的虚拟机数量。SQL Azure以关系模型存储数据,并且每台虚拟机都安装了数据库管理系统。一般情况下,一个完整的数据库会被存储到多台虚拟机中。每台虚拟机的结构相同,都包括SQL Azure Fabric,管理服务,若干数据库实例,管理服务主要用于实现数据同步,这就避免了因为更新操作而导致的每台虚拟机中数据的不同,从而保证了数据的高可用性。同时,虚拟机通过SQL Azure Fabric和管理服务之间互相交换信息,从而监控整体服务的状态。如图2所示。
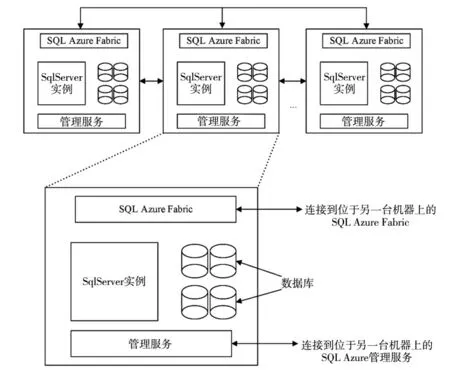
图2 SQL Azure的体系架构
2.3 可扩展分布式关系型系统体系架构
可扩展分布式关系型系统是在非关系型数据库存储系统[7]基础上提出来的,并借鉴了RDBMS数据模型的高效性和NoSQL数据库的高可用性,其体系架构如图3所示。图中实线箭头用于表示组件间数据的传输功能;虚线箭头用于表示组件间对信号的控制功能。系统服务组件主要包括五种,分为别:RS(主服务,主要用于维护系统最底层的元数据),US(更新服务,主要用于执行系统的更新操作),CS(主干服务,主要用于存储用于查询的静态数据),MS(合并服务,主要用于处理查询请求时数据的合并相关操作),client(客户端,主要为用户操作数据库提供接口)[5]。
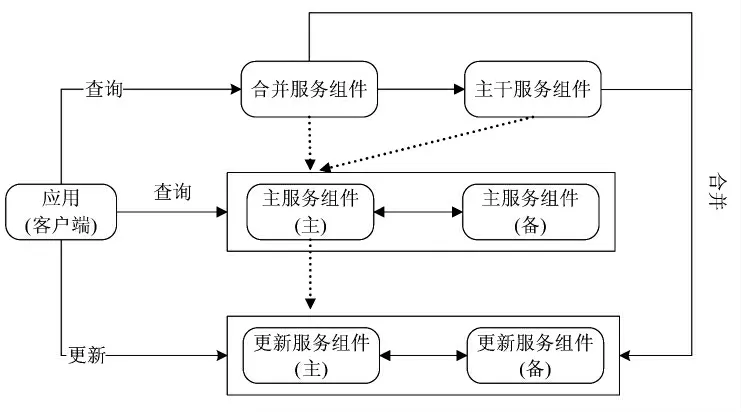
图3 可扩展分布式关系型系统体系架构
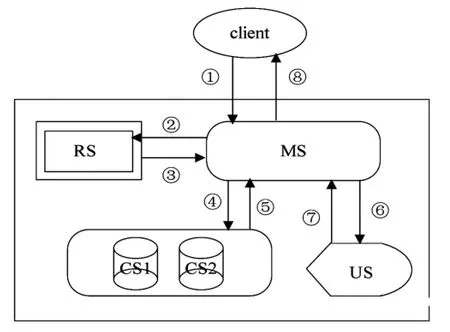
图4 数据查询流程
客户端查询流程,如图4所示。
(1)首先客户端向处理合并操作的合并服务组件发送查询请求;
(2)合并服务组件接到请求后首先向主服务发送定位请求,获取相应数据所在服务器的位置;
(3)主服务组件RS根据合并服务的请求获取相应的定位信息并返回给合并服务组件;
(4)合并服务组件根据返回的定位信息首先向存储静态数据的主干服务组件CS发送查询请求;
(5)主干服务组件CS根据请求返回满足条件的静态数据;
(6)合并服务组件然后根据从主服务返回的定位信息向存储动态数据的更新服务组件发起动态查询请求;
(7)更新服务组件根据请求向合并服务组件返回满足需求的动态数据;
(8)合并服务组件将(5)和(7)返回的数据进行处理并将最终结果返回给客户端。
2.4 云数据库体系架构的探索
HBase体系架构采用键/值数据模型,解决了传统关系数据库只能存储关系型数据的瓶颈,其不仅可以存储结构化数据,同时也可以存储半结构化以及非结构化数据,并可以通过Zookeeper实时监控系统运行状态,保证交叉操作数据的正确性。SQL Azure体系架构采用关系数据模型,可以使用与人们所熟悉的SQL Server相同的方式来使用,在扩展性、可用性等方面相对传统数据库来说具有很好的改进,并可以通过管理服务实现数据间的同步。可扩展分布式关系型系统体系架构既具有关系数据库的便携性同时又增加了NoSQL 的可扩展性,提出了一种全新的数据读写、合并以及存储流程。三者在实现方式上有所不同,但他们的基本目的是一致的,都是尽可能保证系统的高可用性以及高效性,三者具有相对的优势,但如果将其优点进行融合,各自发挥各自的优势,便可带来新的体验。下面介绍一种在三者基础上提出的云数据库体系架构。
该体系架构融合了Hbase、SQL Azure、可扩展分布式关系型系统体系架构三者的优点,将用户的操作分为更新操作和查询操作两种。首先客户端通过访问端口进行操作,如果是查询操作并且客户端存储了相应的分区映射图,直接到指定的HregionServer读取数据,如果未存储相应的分区映射图则首先通过Hmaster_select获取相应的分区映射图之后再到指定的HregionServer读取数据。因为不需要执行更新操作,Store中只有存储数据的Storefile。如果用户执行的是更新操作,则首先经过Zookeeper检查一下相应的HRegionServer的状态,若可用则连接到相应的HregionServer,否则Hmaster_update会根据负载均衡分配可用的HregionServer,并将数据首先放到MemStore中,在适当的时机自动更新到Storefile中。另外,每一个Hregion Server中包含一个管理服务,并且管理服务间相互连接,从而实现数据的同步。如图5所示。
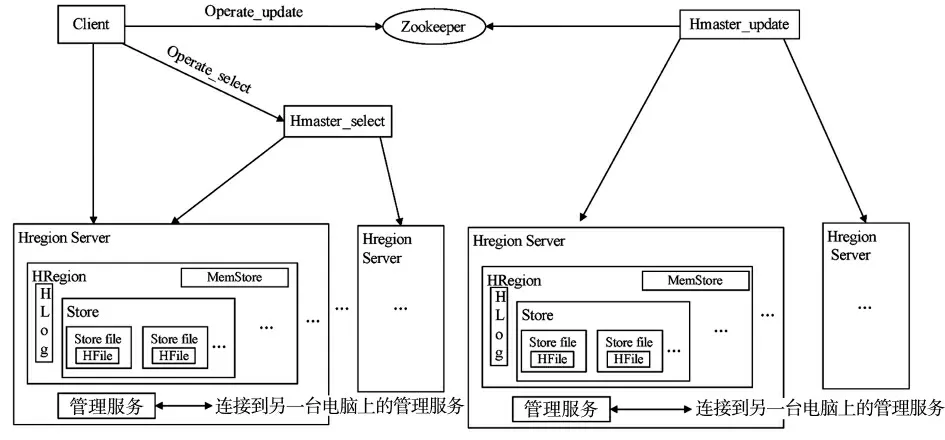
图5 云数据库体系架构探索示意图
该体系架构与Hbase体系架构相比,采用了其监控的模式,不同的是每一个体系中含有两个Hmaster,分别为Hmaster_select和Hmaster_update,二者都可以管理HRegionServer的负载均衡,调整Region的分布,区别在于前者主要用于管理用户对Table的查询操作,后者主要用于管理用户对Table的增加、删除、修改操作。与SQL Azure体系架构相比,采用了其利用管理服务实现数据同步的功能。与可扩展分布式关系型系统体系架构相比,主要采用了其查询和更新操作相分离的思想,这样执行不同的操作目的性强,在一定程度上节省了时间。
3 结论及展望
随着信息量的增加,计算机所要处理的数据呈指数级别的增长,传统的关系型数据库已经不能满足用户的需求。云数据库为解决该问题提供了一种可行的解决方案,日益受到业界和学术界的普遍关注。云数据库的出现必定会带来一场巨大的变革[2],诸如:数据存储的变革、极大的改变企业管理数据的方式、催生新一代的数据库技术、数据库市场份额面临重新分配、浏览器模式的改变、影响了DBA 的工作量以及开发者的访问方式等。
就目前阶段而言,虽然已经出现了一些云数据库产品,其体系结构不尽相同,但总体目标都是尽可能保证数据的高效性、高可用性等云数据库特有的特性。但这些系统暂时并未完全实现云数据库相对传统数据库所有的优势,让这些系统能完全满足用户不断发展的需求仍需人们的共同努力。
[1]史英杰,孟小峰.云数据库管理系统中查询技术研究综述[J].Chinese Journal of Computers,2013,36(2).
[2]Chen K,Zheng WM.Cloud computing.System instances and current research.Journal of oftware,S2009,20(5):1337-1348(in Chinese with English abstract).http://www.jos.org.cn/1000-9825/3493.htm [doi:10.3724/SP.J.1001.2009.03493].
[3]林子雨,赖永炫,林琛,邹权.云数据库研究[J].Journal of Software,2012,23(5).
[4]王献美,吴迪冲,朱泽飞,李仁旺.可扩展分布式关系型云数据库方案[J].华中科技大学学报(自然科学版),2012,40(1).
[5]The architecture of Hbase.http://hbase.apache.org/book.html#architecture.
[6]The architecture of SQL Azure.http://zh.wikipedia.org/wiki/SQL_Azure.
[7]Bond B C,Corbett JC Furman JJ.Megastore:providing scalable highly available storage for interactive services,CIDR’11:223-234[R].Asilomar:CIDR2011.
猜你喜欢
能源工程(2022年2期)2022-05-23
重型机械(2020年2期)2020-07-24
装备制造技术(2019年12期)2019-12-25
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
雷达与对抗(2015年3期)2015-12-09
太阳能(2015年11期)2015-04-10
电力需求侧管理(2014年3期)2014-03-20
自动化博览(2014年12期)2014-02-28
