
推荐系统中协同过滤技术的研究
2013-09-11 00:56王学军
河北省科学院学报 2013年2期
赵 宁,王学军
(石家庄铁道大学 信息科学与技术学院,河北 石家庄 050043)
近年来,信息服务系统在各个领域中应用日渐成熟,信息量呈指数型增长。然而用户要在有限的时间内找到准确的信息却越发困难了,在这样的情况下,为了帮助用户在海量的信息内快速找到有用的信息内容,推荐系统应运而生了。协同过滤推荐技术在其中应用最为成熟,其主要依靠用户对项目的评分而产生的相关推荐。
个性化技术是大数据时代最重要的技术。推荐系统作为一种个性化信息服务系统,是由信息检索和信息过滤技术发展来的,在信息检索和信息过滤技术的研究成果上推荐系统得以实现。可是推荐系统在服务环境和应用形式上和二者有所不同。
1 个性化推荐技术
Burke对推荐系统的内涵进行了推广和提升[1],他认为“推荐系统泛指任何可以制造并输出个性化推荐信息的系统,或者是能够在大信息对象空间中以个性化的方式引导用户找到符合兴趣或有价值的信息对象的系统”。推荐系统最常用的技术是基于内容过滤的推荐技术和基于协同过滤推荐的推荐技术。
基于内容过滤的推荐技术工作原理:采用概率统计和机器学习等技术实现过滤,首先用一个用户兴趣向量表示用户的信息需求,然后对文本集内的文本进行分词,标引,词频的统计加权,生成一个文本的向量,最后计算用户和文本向量之间的相似度。把相似度高的文档发给注册的用户。
基于协同过滤推荐技术的工作原理:可以基于这样的一个假设,例如假设用户S,首先分析S的特性,如爱好,职业,兴趣等信息;然后用相似性算法计算出与用户S兴趣相似的K 个用户;最后参照K 用户对资源的评分预测S用户对资源的评分,并将评分最高的N 个资源推荐给用户S。本文将主要介绍基于协同过滤推荐算法。
2 协同过滤推荐算法
基于内存的协同推荐主要是根据系统拥有的已有用户评分数据,在内存中通过一定的启发式方法实现评分预测,分为基于用户的协同过滤推荐和基于项目的协同过滤推荐。基于用户的协同过滤推荐算法是目前应用较多的算法,是根据计算目标用户与邻居用户之间的相似性,根据邻居用户对某个资源的评分,预测目标用户的评分,在预测评分最高的若干资源作为对用户的推荐呈现给目标用户。其核心思想是计算用户间的相似性,寻找与用户相似度最高的邻居,然后根据邻居对资源的评分,预测出该用户可能对资源做出额评分[2]。实现步骤如下:
(1)获取及构建用户信息模型。用户信息包括:用户的注册信息、用户的评分和用户的行为记录。系统对用户数据进行清理、记录。在系统对用户进行分析时,分为隐式评分和显式评分。显示评分是基于用户的注册信息和用户对资源的评分记录,直观反映出用户对资源的喜好。隐式评分是通过挖掘用户的浏览行为,收藏记录等,估计用户对资源的评分[3]。
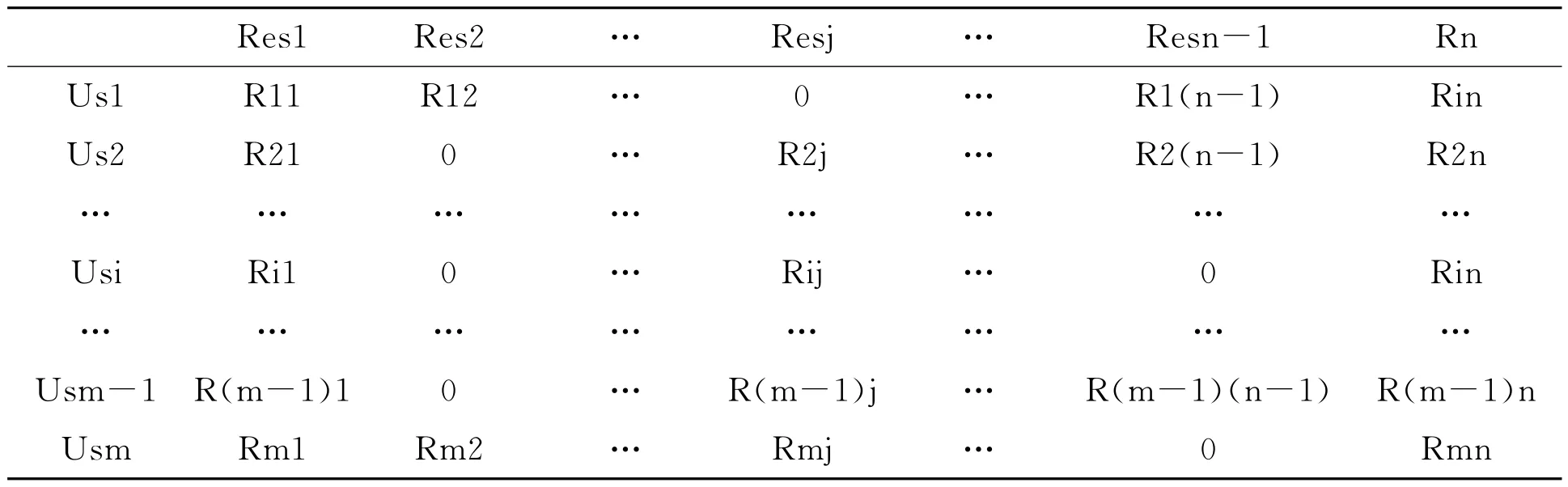
表1 用户资源的评分矩阵
表1是通过协同过滤技术获取和建构后的用户信息矩阵,其中,Rij表示的是第i个用户对第j个资源的评分。
(2)寻找最近邻居 在协同过滤推荐算法第二项是寻找邻居。所谓的邻居是与目标用户Usi有相同爱好的用户群。用夹角余弦相似性计算用户之间的相似度:
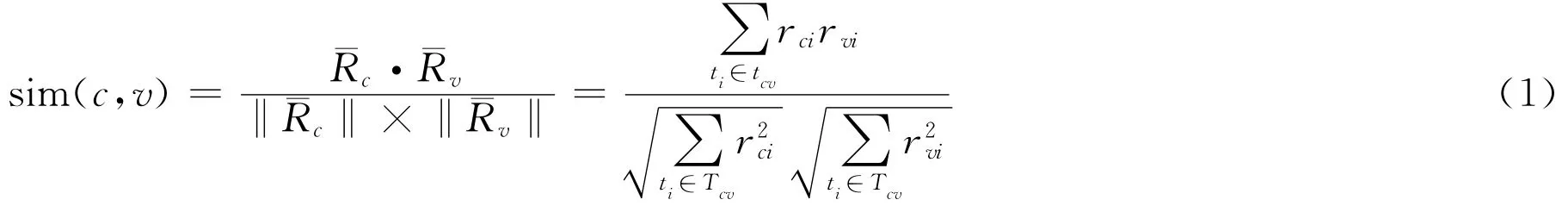
和代表用户c和v的平均评价值,和代表用户c和v的平均评价绝对值。rci表示用户c对项目i的评分,rvi表示用户v对项目i的评分。
(3)产生推荐 算法的最后步骤通过邻居群对资源的评分预测目标用户可能对资源的评分,然后把评分高的资源集推荐给目标用户。
基于用户评分的协同过滤性推荐算法、其评分数据是根据用户对不同项目的喜好程度,推荐系统中所用用户-项目评分矩阵提现用户的评分数据。但是,往往在大型信息服务推荐系统中,系统所拥有的,用户对于项目的评分会达到千万甚至上亿数量。海量用户与项目将导致用户-项目评分矩阵的规模增大形成高维矩阵。例如某个教育网站在一年中总计的用户评分数据为:54759个用户对1457个学习资源有1983489个评分,换算评分在用户-项目矩阵中所在的比例为a=1983489/(54759*1457)约等于0.02486,用百分比是2.49%,可见此矩阵是非常稀疏的。但是即使假数据下算出的百分比也要比实际网站要高出很多了。
3 优化协同过滤推荐算法
聚类方法能够通过设定某个阀值自动将文档归类为一系列有意义的类别信息。通过对不同项目进行逻辑分类,形成不同内容的项目聚类。通过聚合挖掘方法将用户项目评分矩阵化为用户分类评分矩阵,使分类规模小于项目-用户评分矩阵,实现了对高维矩阵的降维,提高了评分矩阵的密度[4]。具体化表示如表1和表2两个矩阵。

表2 用户—项目评分矩阵

表3 用户—项目类评分矩阵
但是通过这种降维的过程中,会有数据的丢失,在推荐质量上很难保证。
计算项目相似性时,考虑到在用户对于项目的评分中的重复因素,在用户项目评分中多个用户可以对单个项目进行评分。继而对项目评分重合率越高,证明项目间的相关性越强。例如用户m 和n 分别对同一项目进行过评分,则用户集合为和,计算重合元素可以表示为of(m,n)n)≤1)。将此公式与上文中的式(1)相结合,得出优化后的夹角余弦相似性公式:

和代表用户c和v的平均评价值,和代表用户c和v的平均评价绝对值。rci表示用户c对项目i的评分,rvi表示用户v对项目i的评分。
4 实现及分析
实验数据截取美国Minnesota大学GroupLens项目组提供的MovieLens中的数据集。6000条评分数据,其中包括132个用户和730部电影。使用通常用于评价推荐系统质量的方法,MAE(mean absolute error)平均绝对偏差进行度量。平均绝对偏差MAE通过计算预测的用户评分与实际用户评分之间的偏差来度量预测的准确性,MEA 越小,推荐质量越高[5]。
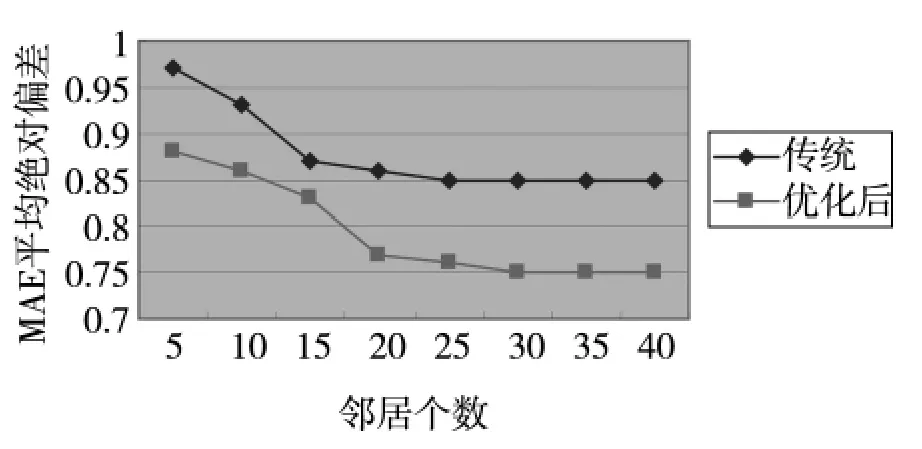
图1 优化前后算法精确度对比
设用户的预测评价集为R={r1,r2,…,rm}设用户实际评价集合为P={p1,p2…,pm}。计算平均绝对偏差。首先采用公式(1)计算资源项目的相似性,然后利用本文优化后的推荐公式(2)计算出推荐集。将本算法和传统协同过滤推荐算法相对比,实验结果如图1。可以看出本文优化后的算法计算出来的MAE值较小,此推荐更加准确。
5 结论
首先介绍了推荐系统与现在主要应用的几种推荐技术工作原理,主要分析了协同过滤推荐算法的实现步骤,分析协同过滤推荐算法现存在的问题,通过聚类和降维实现对高维矩阵的降维和增加用户-项目矩阵密度。计算相似性时加入评分中的重复因素,以减少数据稀疏的问题。实验结果表明了优化后算法比传统协同过滤推荐算法在推荐质量上有提高。
[1]P.Resnick,H.R.Varian.Recommender systems,Commun.ACM,vol.40,iss.3,pp.56-58,1997.
[2]R.Burke.Hybrid Recommender Systems:Survey and Experiments,User Modeling and User-Adapted Interaction,vol.12,iss.4,pp.331-370,2002.
[3]C.Zeng,C.-X.Xing,L.-Z.Zhou.Similarity measure and instance selection for collaborative filtering,presented at the Proceedings of the 12th inter nation al conference on World Wide Web,Budapest,Hungary,2003.
[4]J.S.Breese.Empirical Analysis of Predictive Algorithms for Collaborative Filtering,in Proceedings of 14th Conference on Uncertainty in Artificial Intelligence,1998,pp.43-52,1998.
[5]B Sarw ar,G Karypis,J Konstan,et al.Item-based collaborative filtering recommendation algorithms1In:Proc of the 10th Int.l World Wide Web Con f1New York:ACM Press,20011,285-295.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
科学大众(2020年23期)2021-01-18
河北画报(2020年8期)2020-10-27
汽车观察(2019年2期)2019-03-15
中国卫生(2016年5期)2016-11-12
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
浙江大学学报(工学版)(2016年2期)2016-06-05
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
