
基于表情符号和情感词的文本情感分析模型
2013-09-11 00:56贾珊珊邸书灵范通让
河北省科学院学报 2013年2期
贾珊珊,邸书灵,范通让
(石家庄铁道大学 信息科学与技术学院,河北 石家庄 050043)
随着Web 2.0技术的蓬勃发展,互联网更加强调用户的主体地位。社交网络中产生了大量对于某一事件、产品或观点的评论信息,从这些评论信息中获取人们的情感色彩和情感倾向性是观察者越来越关心的话题。依靠计算机快速获取和整理相关评论信息的情感分析技术也就更加重要(本文中情感分析均指文本情感分析)。在网络交流的时代,单纯的文字已经不能完全满足人们互相交流表达情感的欲望,越来越多的人在交流的过程中开始使用表情符号。表情符号中不仅包含代表一定事物但却没有情感倾向的符号,如:、、、等,也包含代表消极情感的一些表情符号,如:、、等,同时包含代表积极情感的表情符号,如、、等,其中后两种表情符号更具有研究价值。
1 文本倾向性分析方法
目前国内外对于情感倾向性分析的研究大部分都是基于文本信息的。文本情感倾向性研究主要分为两大类:
(1)基于语义的文本倾向性分析方法。该方法是通过分析Web文本内容中对某人、某事件或某观点的看法或评论,来判断其情感倾向性。朱嫣岚等人[1]提出了基于语义相似度和基于语义相关场的两种词汇语义倾向性计算方法。杨江等人[2]提出了一种基于浅层篇章结构的评论文分析方法,该方法有效地排除了与主题无关的主观性信息,准确性提高。
(2)基于机器学习的传统文本分类技术。Pang等人[3]使用朴素贝叶斯、最大熵及支持向量机(SVM)等方法进行文本倾向性研究,比较了这几种方法的分类效果,其中SVM 分类准确率最高达到了80%。徐琳宏等人[4]选取褒贬倾向性比较强烈的词作为特征值,构造了一个SVM 褒贬两类分类器来进行文本倾向性分析。
上述对于文本的情感倾向性研究中,第一步是进行预处理,去掉表情符号等停用词,然而,微博等社交网络中,人们更热衷于使用表情符号来表达情感,过去仅仅考虑情感词来计算情感值,本文提出了一种同时考虑表情符号和情感词的文本情感值计算方法。
2 相关工作
2.1 情感研究现状
互联网用户从过去单纯的“读”网页,开始向“写”网页,由过去被动的接受互联网中的信息向主动创造互联网信息迈进。因此,互联网(尤其是微博、论坛等)上产生了大量用户对于人物、事件、观点等的评价信息,吸引了越来越多的研究者对于这些信息的研究。
对社交网络中情感的研究主要分为三类:一是通过分析网络中大量的信息,来获得人们日常生活的一些规律。Scott A.Golder等人[5]通过分析大量的推文,研究了人们的积极情绪和消极情绪随季节、昼长等因素的变化规律,但没有考虑环境、压力、职业等因素的影响。二是分析突发事件或政治、社会、经济、文化等领域的一些事件与公众心情之间的关系。文献[6]中分析了2008.8.1-2008.12.20期间的推文,讨论了美国总统选举、感恩节等一些重大事件对于公众心情的影响。三是分析社交网络中信息对于一些重大事件的影响。刘鹏飞等人[7]讨论了在上海地铁追尾事故中,公关通过微博等社交媒体及时报道该事件进展并诚恳的道歉,借助网络的力量杜绝了谣言的产生,该做法受到网友的好评。
2.2 表情符号的研究
大部分对于文本的情感分析中仅仅考虑情感词对文本倾向性的贡献,但是,在社交媒体中用户也常常使用表情符号表达一定的情感,通过表情符号能够从中读出一定的情感。年轻用户更热衷于使用表情符号,与越熟悉亲近的人交流时,使用表情符号的概率越大。同时,表情符号的使用在一定程度上为整个文本增添了幽默感和亲切感,并能够消除一词多义等词语带来的歧义,更具有可读性。表情符号可以出现在文本的开头、中间和结尾任意位置。一般在以下三种情况下使用表情符号:一是当现有文字不能准确的表达出自己的情感时,人们往往借助表情符号,如“今天天气怎么这样”中,最后这个抓狂表情符号的使用表现出作者愤怒之情,但在社交媒体尤其是微博中,人们更倾向于使用表情符号来表达类似的心情。二是用来再次强调文本中的情感,如“今天玩得很开心”。三是对文本中具有讽刺、嘲讽等词语作补充,用来消除文本中的歧义,如“我喜欢我的生活”。
3 表情符号分类
目前,大部分对于情感分析的研究在提取具有情感倾向性的词语时只关注情感词,往往忽视对具有情感倾向的表情符号的研究。本文将新浪微博中84个默认常用表情进行了情感分类,并赋予各类情感分值,便于文本情感分析模型中表情符号的情感值计算。
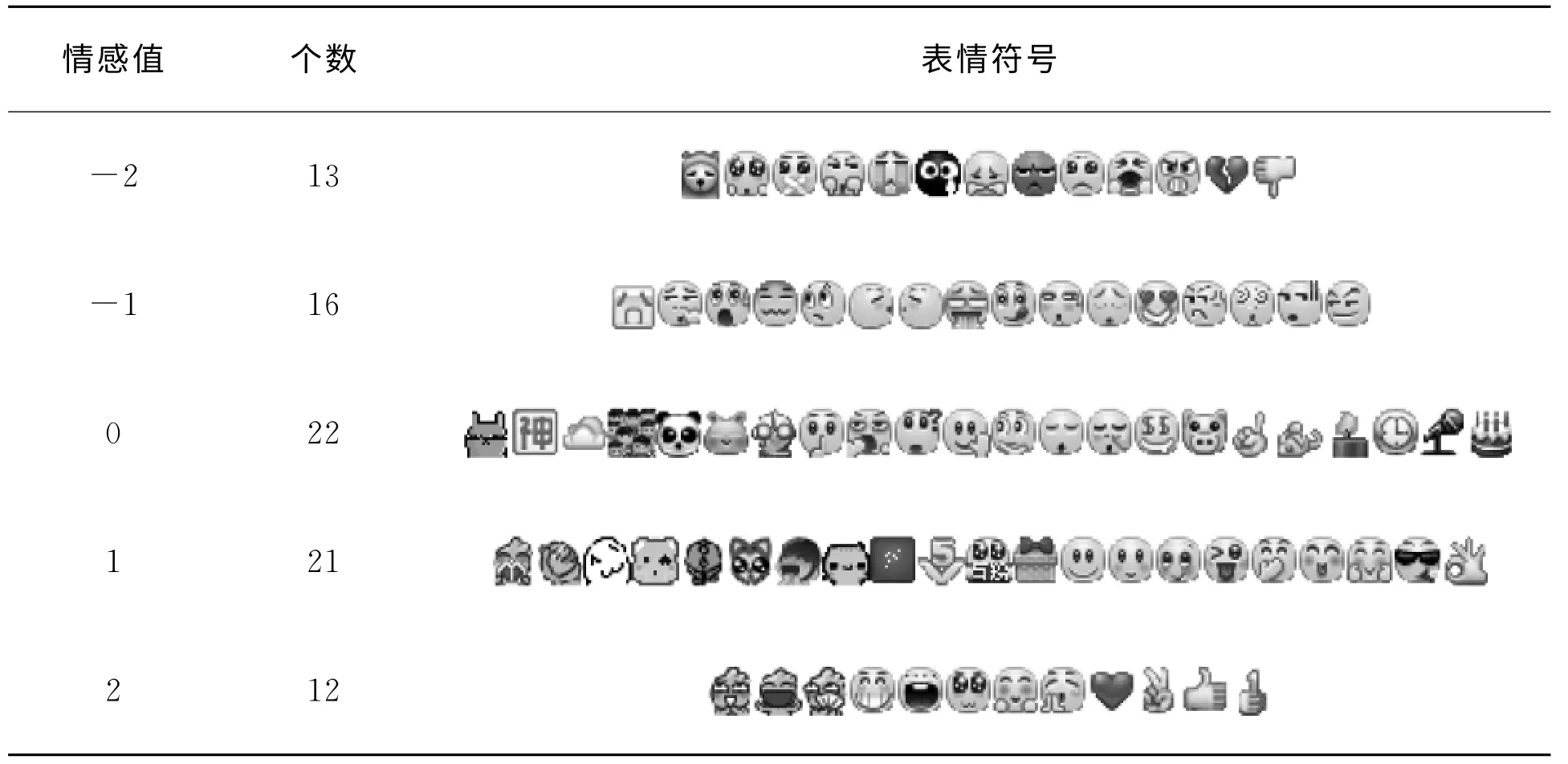
表1 表情符号分类
将新浪微博中84个默认常用表情进行分类,并赋予每类表情情感值,情感值范围取[-2,2]间整数。其中正值代表积极情绪,负值代表消极情绪,0代表中性词,其中像、等表情符号不同语境的情感极性不同,将这类表情归为中性类。情感值的绝对值越大,表明情感极性越强,如表1所示。
对表情符号分类后,提出了一个同时考虑表情符号和情感值的情感分析模型,并可通过设置一定的阈值,来对偏激的情感进行实时监控。
4 基于表情符号和情感词的文本情感分析
4.1 文本情感分析模型
在文本情感分析时,考虑表情符号和情感词的共同作用,笔者提出了一个情感分析模型,如图1所示。
(1)文本预处理模块
文本预处理模块是对要分析的文档进行断句、分词和去停用词(包括标点、数字等一些无意义的词,其中不包含表情符号)等操作。此模块为提取所需信息做准备。
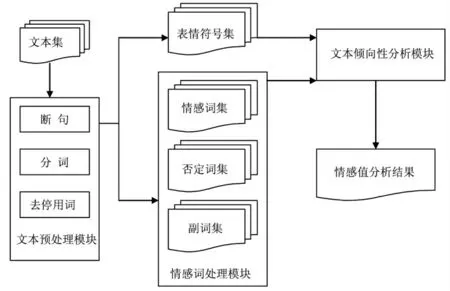
图1 基于表情符号和情感词的情感分析模型
(2)情感词处理模块
情感分析模块是分析情感词集、否定词集和副词集间的关系。首先判断所提取的情感词集与否定词集间的关系,若否定词集中某词与情感词集中某一情感词相关,则用相反意义的词汇替换该情感词。同时判断副词集中是否有副词与该情感词相关,若相关,改变其情感词倾向性强度。
(3)文本倾向性分析模块
文本倾向性分析模块是整个文本情感分析模块的核心模块。它包括表情符号集的情感倾向性和情感词处理模块的情感倾向性两部分。这两部分的情感倾向性累加和即是整个文本的情感倾向性。
4.2 文本情感值计算步骤
本文中对于情感值的计算模型是综合考虑情感词和表情符号两个因素的。每个文本情感值的计算步骤如下:
(1)对帖子T 进行预处理,断句、分词并去掉包含标点、数字等一些无意义的停用词,但不去掉文本中的表情符号;
(2)按顺序依次提取每个句子中的情感词M、表情符号O、否定词N 和程度副词C;
(3)对情感词,查看句子中是否有否定词与之匹配,若不匹配,不改变情感词;若匹配,当否定词个数为2a+1个,用相反意义的词汇替代,若否定个数为2a,情感词不变;
(4)判断副词与情感词是否相关,若不相关,直接计算其情感数值,若相关,则将所修饰的句子的褒贬义强度A 按文献[7]中的级差别增加,计算其倾向性数值;
(5)所有句子计算完后,每条句子情感值累加和即为整个文本的情感值。
其中,可以对文本的情感值设定一定的阈值,便于对偏激情感进行在线实时监控。
由于表情符号相对于情感词更加能够体现出情感倾向,本文中将情感词的权重α 取为0.4,表情符号的权 重β取为0.6,则整个文本的情感值S计算公式如式(1)和(2):

其中m、n分别为句中情感词与表情符号的个数;t为文本中的句数;a为0、1、2、3等自然数;Ai是第i条句子中程度副词的强度。
5 结束语
在信息化网络时代,通过对网络中文本的分析得出公众对于人、事件、观点的态度和评价显得尤为重要。本文提出了一个情感分析模型,在计算文本情感值时加入了表情符号,并给出了文本情感值计算的详细步骤。分析微博等社交网络中文本的情感倾向性时,该方法的文本情感值的计算结果相对于只考虑情感词的情感值计算方法会更准确。
[1]朱嫣岚,闵锦,周雅倩,等.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20.
[2]杨江,侯敏,王宁.基于浅层篇章结构的评论文倾向性分析[J].中文信息学报,2011,25(002):83-88.
[3]Pang B,Lee L.Seeing stars:Exploiting class relationships for sentiment categorization with respect to rating scales[C]//Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics.Association for Computational Linguistics,2005:115-124.
[4]徐琳宏,林鸿飞,杨志豪.基于语义理解的文本倾向性识别机制[J].中文信息学报,2007,21(1):96-100.
[5]Golder S A,Macy M W.Diurnal and seasonal mood vary with work,sleep,and daylength across diverse cultures[J].Science,2011,333(6051):1878-1881.
[6]Zhao J,Dong L,Wu J,et al.MoodLens:an emoticon-based sentiment analysis system for Chinese tweets[C]//Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2012:1528-1531.
[7]刘鹏飞,周培源.2011年网络舆情走势与社会舆论格局[EB/OL][D].
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
消费电子(2022年6期)2022-08-25
有色金属(矿山部分)(2021年4期)2021-08-30
疯狂英语·新阅版(2020年11期)2020-12-21
中国医学装备(2016年6期)2016-12-01
大作文(2016年7期)2016-05-14
新闻研究导刊(2015年17期)2015-12-25
燕山大学学报(2015年4期)2015-12-25
Coco薇(2015年10期)2015-10-19
语言与翻译(2015年4期)2015-07-18
