
一种基于同义词的中文关键词提取方法
2013-08-16 12:42:06王永亮曹奇敏
服装学报 2013年5期
王永亮, 郭 巧, 曹奇敏
(北京理工大学自动化学院,北京100081)
关键词在文本处理的各个领域有着十分重要的作用[1-9]。在信息爆炸的今天,为了处理日益庞大的文本信息,国内外各个研究机构在自动文摘、信息检索、文本分类、文本聚类等领域展开了大量研究。但是这些研究都无一例外地要用到关键词抽取,可见关键词在自然语言处理尤其是文本处理中占据着十分重要的地位。
传统的关键词抽取是基于词袋(Bag of words)模型的,即忽略词序和语法、句法,将文档仅仅看作是词的集合,文档中每个词的出现都是独立的,不依赖于其他词是否出现。在中文文本尤其是中文新闻文本中,为了使文字表述更加生动、丰富,往往对一个语义概念使用多种表达方式进行表述,而这个语义概念往往就是作者想要表达的关键概念,体现在词层面上就是多词一义现象。同时,因为语言表达的灵活性,一词多义现象也普遍存在,甚至有时同一个词在不同语境下的词性都不尽相同。例如“打”这个词,在“打架”这个环境下词性属于动词,而在“一打啤酒”这个环境下词性为量词。基于词袋模型的关键词抽取技术无法分辨上述两个语言环境下的“打”字有何区别,而只是将其根据字面意思进行归并,采用这种模型抽取出的关键词往往并不是作者本意想表述的关键词。可见,多词一义和一词多义是汉语中的一个普遍现象,也是中文文本关键词提取的核心问题和难点。传统的词袋模型在处理上述的多义词和同义词问题上显得无能为力。
一词多义现象使得高维的文本空间更加稀疏,文中希望能将表达同一个意思的词语合并,来实现文本空间的降维。而多词一义现象则给自然语言的机器理解带来极大的困难,解决方法就是对多义词进行词义消歧(Word Sense Disambiguation,WSD)。将词义消歧定义为在给定上下文语境的条件下由机器自动、高效地确定多义词义项的技术[1]。文中利用《同义词词林扩展版》作为语义资源,将文本从词空间映射到语义空间,对具有相同语义的词进行并归,来解决多词一义问题。同时维护了一个二元(Bigram)词典,采用一阶隐马尔可夫模型对文本建模,解决多义词的词义消歧问题。
1 相关工作
国外对于关键词的研究起步较早,Turney[2]等设计了GenEx系统,将遗传算法和C4.5决策树机器学习方法用于关键词的提取。Witten等开发了系统KEA,它采用朴素贝叶斯模型对词语离散的特征值进行训练,获取模型的权值。
对于国内研究,经历了从单纯的统计模型到利用语义资源进行语义层面的提取两个阶段。程涛等[3]人提出一种基于《同义词词林》的关键词提取算法,该方法只是认为若该词在词林中的上下位词出现则该词比较重要,并没有进行多义词的消歧和同义词归并。方俊等[4]提出一种基于语义的关键词提取算法,但是该方法需要计算语义相关度,导致算法复杂性不能令人满意。
文中提出一种改进的中文关键词提取方法SKEA(Synonym Keyword Extraction Algorithm),针对中文文本出现的多词一义现象进行词语在语义空间的归并;对于多义词,则建立一阶隐马尔可夫模型进行词义消歧。同时对在原有KEA(Keyword Extraction Algorithm)方法的基础上改进了权重计算公式。
2 SKEA算法
2.1 算法概述
KEA是一种用来提取文本文档关键词的算法,目前版本是KEA 4.0。KEA采用朴素贝叶斯模型的机器学习算法来提取文档中的关键词。文中利用《同义词词林扩展版》等语义资源对KEA进行改进,同时调整了权重的计算方法,提出一种SKEA方法。SKEA候选词的特征主要从以下几个方面考虑:
1)SF×IDF公式:传统的SF×IDF公式中统计词频和词在所有文档中出现的次数。现在利用同义词对含有相同语义的词合并,改进后的公式SF×IDF,其中 SF(Synonym Frequency)代表同义词词频:
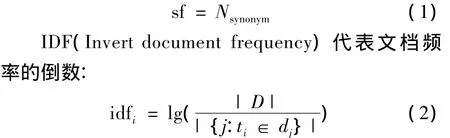
式(2)中|D|表示语料库中的文件总数,|{j:ti∈dj}|表示包含ti的文件数目,如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用公式:
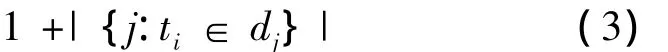
2)位置信息:对于文档Di,对其分词后得到词的集合:
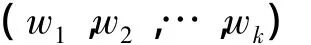
定义词wi的相对位置:

式中,lj为词wj的长度,L为文章的总长度。因为开始和结束位置的词往往更可能是关键词,所以有经验公式(5)确定位置权重:

同时,标题中出现的词比内容中的词更重要,可以赋予比正文中的词更大的权重。
3)利用词性信息:关键词往往是名词或者动词,所以在文档预处理阶段,需要维护一个停用词字典,将介词、副词等从文档中过滤掉。同时认为人名、地名、机构名等具有比一般名词或者动词更强的表述能力,应该相应地提高权重。
依据以上几点,基于SKEA的权重计算公式如下所示:
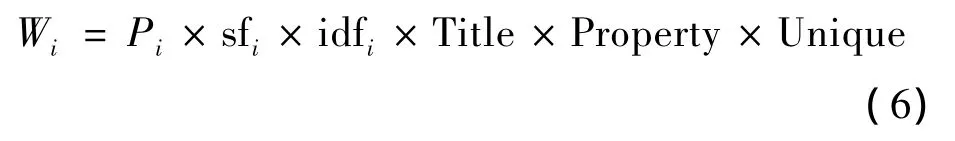
式中,Title,Property,Unique 分别为标题权重、词性权重和特殊权重(人名地名等信息)。
文中的SKEA方法先根据以上几种特征方式计算文本中每一个词的权重,然后根据《同义词词林扩展版》和一阶隐马尔可夫模型将文本由词转换为语义代码的表示模式,实现文本的降维。然后在语义空间下将文本的语义表示按合并后的权重递减排列,排名靠前的为关键语义。此时,按预先设定好的关键词个数,取排名序列前N个语义,作为关键语义。最后对每个语义,选出组成该语义各个词中分权重最大的词,来代表这个语义,即做了一个语义空间到词空间的反变换。系统框图如图1所示。
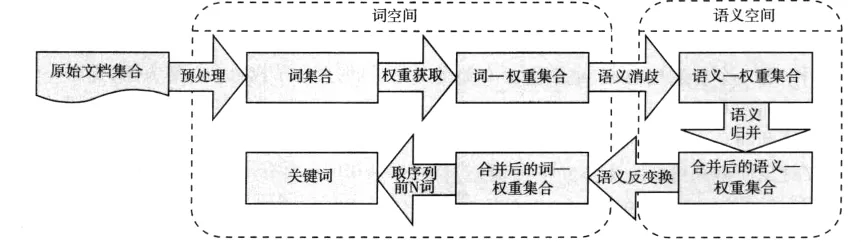
图1 SKEA方法系统Fig.1 Block diagram of SKEA
2.2 《同义词词林扩展版》汉语词表
哈尔滨工程大学(简称“哈工大”)的《同义词词林扩展版》是哈工大信息检索研究室对《同义词词林》原版进行罕用词剔除、新词扩充之后的一部汉语大词表,包含77 343条词语。其按照树状的层次结构把所有收录的词条组织在一起,把词汇分成大、中、小3类,大类有12个,中类有97个,小类有1 400个。每个小类里都有很多词,这些词又根据词义的远近和相关性分成若干个词群(段落)。每个段落中的词语又进一步分成若干个行,同一行的词语要么词义相同(有的词义十分接近),要么词义有很强的相关性。小类中的段落可以看作第4级的分类,段落中的行可以看作第5级的分类。这样,词典《同义词词林》就具备了5层结构[3],如表1所示。

表1 词典结构示例Tab.1 Examples of dictionary structure
以哈工大《同义词词林扩展版》为基础,建立了Access中的数据库Cilin.mdb。将其5层结构代码取前3层,即1 400个语义代码总数。针对每个代码对应的同义词词组,将其拆分,最终将拆分的词组成词—代码对,并顺序标号形成词典数据库。
2.3 词义消歧
一词多义是一个普遍存在的现象,汉语中多义词的出现频率在0.40左右[5]。由于文中采用《同义词词林扩展版》作为语义资源,但是该词典存在一词多义问题,即一个词可能存在多个语义编码词群中。所以需要对这些多义词进行语义消歧,确定该词在文中的唯一语义。
对词语进行词义消歧需要获取待消歧词语的上下文信息。基于语料库的统计方法通过计算给定文本中词汇语义在多义词上下文中的概率权重,选择具有最大概率权重的语义作为最佳结果输出。文中采用一阶隐马尔可夫模型对文本建模[1],并维护一个二元(Bigram)词典来实现词义消歧。
2.3.1 隐马尔可夫模型 隐马尔可夫模型(Hidden Markov Model,HMM)是一种在自然语言处理领域中被广泛应用的统计模型。HMM实际上是一个有限状态机,系统的状态是不可观测的,但是到达一个状态时,可以记录一个观测,这个观测是该状态的一个概率函数。它可以被描述成一个五元组HMM=〈S,V,A,B,Π〉,有如下定义:
1)N是模型状态个数,S是模型中的状态。则有状态集合:S={S1,S2,S3,…,SN},在文中模型中,定义状态为《同义词词林扩展版》中的小类(3级分类),则有 N=1 400。
2)M表示每个状态上对应的可能观测值的个数,V表示每个状态的观测值,有观测值集合:V={v1,v2,v3,…,vM}在文中模型中,观测值就是文本中的词。
3)状态转移概率矩阵A=[aij],其中
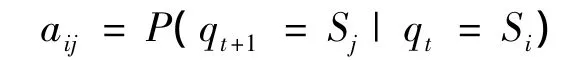
在文中模型中,A是一个1 400×1 400的稀疏矩阵。
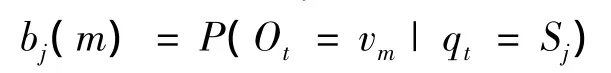
4)观测概率B=[bj(m)],其中在文中模型中bj(k)表示在Sj语义下,t时刻出现词wk的概率,称其为发射概率。
5)初始状态概率Π =[πi],其中
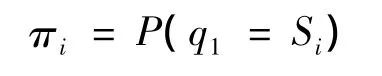
在文中模型中指的是文本第一个词出现语义Si的概率。
在确定模型参数后,词义消歧就转化为从一定观测值序列的所有可能状态中,选取概率最大的作为最终的状态序列问题。可以采用Viterbi算法,即由动态规划的方法来寻找出现概率最大的隐藏状态序列。
2.3.2 词义消歧 针对《同义词词林扩展版》的5层结构编码,取前3层共计1 400个词义编码项组成的集合来组成语义空间S,即
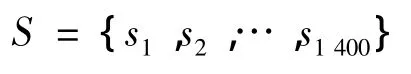
在Access数据库中建立《同义词词林》字典,并通过查字典的方法获得候选词wi在语义空间的状态集合,定义上述查字典过程为
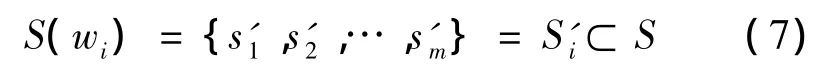
式(7)中,对于m=0,即未登录词,给定特殊的编码符号。对m=1,即非多义词,则无需进行词义消歧。而对m >1,即多义词,则通过上述的一阶隐马尔可夫模型进行词义消歧。
定义消歧过程为
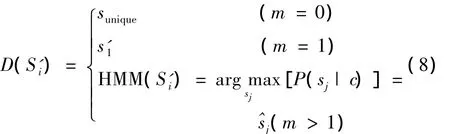
式(8)中,c表示wi所处上下文的语境为根据一阶隐马尔可夫消歧后确定的唯一语义,sunique为未登录词给定的特殊语义项。将wi逐一按照上述过程进行语义转换,最终得到一个文档在语义空间的映射集合Sfinal。
至此,词义消歧结束,得到一个文档从词空间到语义空间的唯一转换。
2.4 语义归并
上述的一阶隐马尔可夫模型解决了词义消歧问题,同时为语义归并打下了基础。对于文档在语义空间的集合Sfinal,同时将其对应的权重和词关联起来,得到三维数组集合:
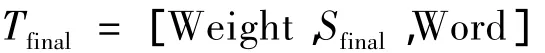
对相同语义编码的项进行合并,得到一个Sfinal的子集Smean:
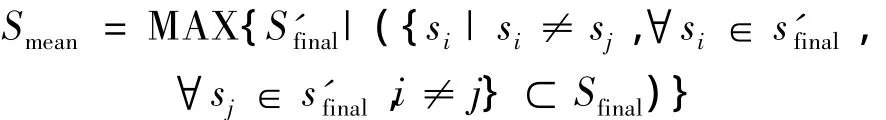
同时得到一个合并后的三维数组:
对于∀si∈Smean,有式(9)来更新Weight(si):
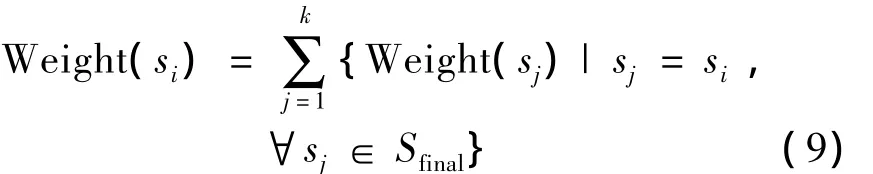
合并后的项的权重就是合并前各分项权重之和,此时对于Tmean,按Weight递减进行排序,排名靠前的就是关键语义。
此时得到的只是词在语义空间的描述,而并非所认知的关键词,这就需要做一个语义空间到词空间的反变换。在合并同语义项之后,对于∀si∈Smean,可以得到一个Word的子集Word':
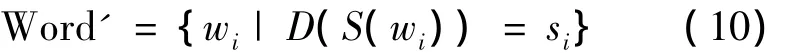
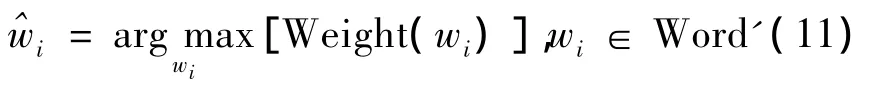
此时按Weight递减进行排序,就可以得到文本的按权重大小顺序排列的关键词。
3 实验结果及分析
3.1 单文本实验结果与分析
为了比较SKEA方法和KEA方法在中文关键词抽取方面的优劣,选取一篇有代表性的文章进行对比实验。针对所选文本,分别采用SKEA方法和KEA方法抽取关键词,同时选取权重排序最大的10个词作为实验结果。实验结果如表2所示。
分析表2中数据可知,SKEA方法和KEA方法抽取的关键词中有9个都是一样的。而KEA方法因为没有进行同义词合并,把“工会”和“总工会”两个词都当作了关键词,带来冗余。而SKEA方法则合并了这两个词,作为一个关键词。显然采用SKEA方法进行词义合并后抽取的关键词更加准确一些。
3.2 分领域实验结果
为了测试SKEA方法在不同文本领域的性能,从搜狗实验室文本分类语料库中选取军事、体育、政治、艺术这4个大类,每个大类选取50篇共计200篇文章作为测试集;并通过相应领域的专家抽取每篇文章的10个关键词,与KEA方法进行比较。

表2 单文本实验结果Tab.2 Experiment result of single document
定义准确率为
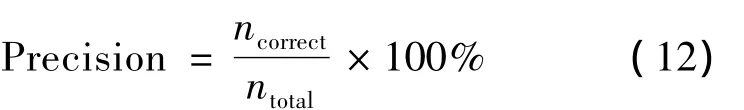
同时采用外部评测方法,分别用SKEA和KEA方法提取25个关键词作为文章的特征向量进行文本分类。分类器采用支持向量机(SVM)分类器,核函数采用线性核,参数为默认参数,使用交叉检验得到分类准确率。
3.3 分领域实验结果分析
1)由表3可知,在艺术、军事、政治等领域,SKEA准确率明显好于KEA方法。而体育领域由于《同义词词林》定义同义词的问题,例如某篇关于体操的报道中,提到了高低杠、平衡木等项目名称,而《同义词词林》则将这些同一体育项目的词都定义为同义词/近义词,此时出现了过合并现象。而这些过合并导致SKEA方法和KEA方法在体育大类的表现基本差不多甚至略有不如。
由于军事政治领域中的专有名词出现较多。文中采用中国科学院ICTCLAS方法,能准确识别文章中出现未登录专有名词,诸如人名、地名、国家名、机构名等。本方法给予这些专有名词较大的权重,使其比较容易成为关键词。实验结果证明这个方法行之有效,在军事和政治两个领域的准确率高于体育和艺术领域。
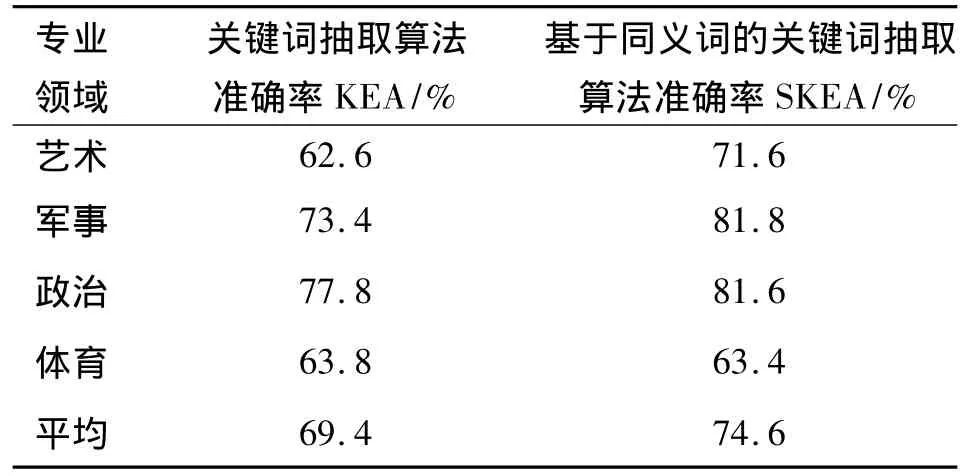
表3 提取10个关键词时内部评测实验结果Tab.3 Experimental results in the extraction of 10 keywords
2)由表4可知,采用SKEA方法对文本进行特征选择后SVM分类器的分类效果好于KEA方法。这是因为SKEA解决了一词多义和多词一义的问题,使得所选出的作为关键词的特征向量对于文章类别的表述能力更强,即分类效果更好。从表4中可以看出,SKEA+SVM方法平均准确率比KEA+SVM方法高2.6%。
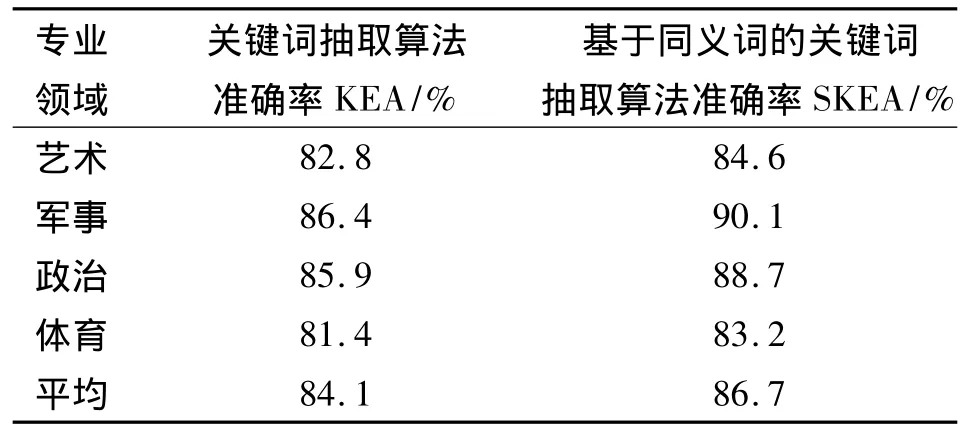
表4 提取25个关键词时外部评测实验结果Tab.4 Experimental results in the extraction of 25 keywords
4 结语
针对KEA方法进行改进,提出一种SKEA方法。使用哈工大《同义词词林扩展版》作为语义资源,将文档从词空间映射到语义空间。针对汉语中的一词多义和多词一义现象,建立了一阶隐马尔可夫模型对多义词进行消歧,而后对映射到语义空间的文档进行语义合并;对合并后的语义代码按权重排序,最后做语义空间到词空间的反变换来获取关键词序列。实验结果证明内部评测中SKEA方法比KEA方法平均准确率高出5.2%,外部评测高出2.6%,效果满意。
由于文中词义消歧模型采用的是基于一阶隐马尔可夫模型,但是一个多义词的词义并不只有前一个词确定,而是由该词所在的整句话的非噪声词确定的。采用更准确的模型来提高词义消歧精度是下一步研究的主要内容。
[1]丁江伟,刘挺,卢志茂,等.隐马尔可夫模型和贝叶斯模型词义消歧对比研究[C]//全国第七届计算语言学联合学术会议论文集.北京:清华大学出版社,2003:214-220.
[2]Turney P.Learning to extract keyphrases from text[R].Technical Report ERB-1057.National Research Council,Institute for Information Technology,1999.http://wenku.baidu.com/5ala70ebb8f67clcfad6b8f0.html
[3]程涛,施水才,王霞,等.基于同义词词林的中文文本主题词提取[J].广西师范大学学报:自然科学版,2007,25(2):145-148.CHENG Tao,SHI Shui-cai,WANG Xia,et al.Chinese keywords extraction the Chinese based on CILIN[J].Journal of Guangxi Normal University:Natural Science Edition,2007,25(2):145-148.(in Chinese)
[4]方俊,郭雷,王晓东.基于语义的关键词提取算法[J].计算机科学,2008,35(6):148-154.FANG Jun,GUO Lei,WANG Xiao-dong.Semantically improved automatic keyphrase extractionp[J].Computer Science,2008,35(6):148-154.(in Chinese)
[5]鲁松,白倾,黄雄,等.基于向量空间模型的有导词义消歧[J].计算机研究与发展,2001,38(6):663-667.LU Song,BAI Qing,HUANG Xiong,et al.Supervised word sense disambiguation based on vector space model[J].Journal of Computer Research and Development,2001,38(6):663-667.(in Chinese)
[6]李鹏,王斌,石志伟,等.Tag-TextRank:一种基于 Tag的网页关键词抽取方法[J].计算机研究与发展,2012,49(11):2345-2354.LI Peng,WAGN Bin,SHI Zhi-wei,et al.Tag-TextRank:a webpage keyword extraction method based on tags[J].Journal of Computer Research and Development,2012,49(11):2345-2354.(in Chinese)
[7]柯逍,李绍滋,曹冬林.基于相关视觉关键词的图像自动标注方法研究[J].计算机研究与发展,2012,49(4):846-855.KE Xiao,LI Shao-zi,CAO Dong-lin.Automatic image annotation based on relevant visual keywords[J].Journal of Computer Research and Development,2012,49(4):846-855.(in Chinese)
[8]杨洁,季铎,蔡东风.基于联合权重的多文档关键词抽取技术[J].中文信息学报,2008,22(6):75-79.YANG Jie,JI Duo,CAI Dong-feng.Keywords extraction in multi-document based on united weight technology[J].Journal of Chinese Information Processing,2008,22(6):75-79.(in Chinese)
[9]WAN Xiao-jun,YANG Jian-wu,XIAO Jian-guo.Towards an iterative reinforcement approach for simultaneous document summarization and keyword extraction[C]//Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics.Stroudsburg:ACL,2007:552-559.
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
西夏研究(2020年1期)2020-04-01 11:54:26
开放教育研究(2020年2期)2020-03-31 01:54:14
新高考(英语进阶)(2018年3期)2018-05-14 07:38:00
电脑与电信(2018年12期)2018-03-23 02:37:20
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
语言与翻译(2014年3期)2014-07-12 10:31:59
中文信息学报(2012年4期)2012-06-29 06:29:14
