
适用于AVS的高性能整像素运动估计硬件设计
2013-08-13 08:13:34吴燕秀王法翔
电子技术应用 2013年1期
吴燕秀,王法翔
(1.福州大学 物理与信息工程学院,福建 福州 350002;2.福建省集成电路中心,福建 福州 350002)
AVS整像素运动估计的搜索算法很多,其中全搜索块匹配算法因数据流规则匹配率高并且没有复杂的动态反馈和决策逻辑,最适合可变块大小运动估计,故本文选择全搜索块匹配算法。现有的全搜索块匹配算法运动估计硬件结构在面积及处理速度上已做了很多努力,如参考文献[2-5]提出的实现方案:参考文献[2]利用像素截断的方法,将像素低位截断,在保证图像信噪比降低不多的情况下大大减少了运算量;参考文献[3]提出了二维intra-Level SAD计算阵列的运动估计结构,在列方向上数据重用率可达到100%;参考文献[4]和[5]提出的结构能够实现100%的硬件处理器利用率,但是均存在I/O带宽大的缺点。本文根据AVS整像素运动估计的特点,采用二维内置SAD加法树计算阵列,通过合理安排片上存储,极大地降低了I/O带宽;运用了加1电路选择进位加法器,进一步缩小了结构面积,提高了处理速度,实现了适用于AVS的高性能整像素运动估计硬件设计。
1 AVS运动估计算法
1.1 可变块运动估计
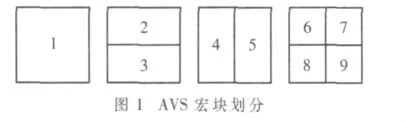
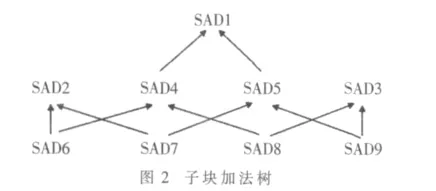
基于块的运动估计,即找到当前帧的块在参考帧中一定范围内最匹配的块所在的相对位置,这个相对位置称为运动矢量。AVS标准中规定将16×16的宏块进一步划分为 8×16、16×8、8×8 的子块,如图1 所示,这样能够提供更加精确的运动矢量预测。可变块运动估计需要对每个宏块的所有子块进行块匹配,即进行9次计算。本文采用如图2所示的加法树结构,所有的大块由小块简单相加即可,大大减少了计算量[4]。
1.2 匹配准则
运动估计需依据一定的判断准则,并在选定搜索算法所遍历的点中寻找最优的匹配点。在众多的匹配准则中,绝对误差和(SAD)的计算复杂度最低,利于硬件实现,故选择 SAD作为匹配准则。令(-p,p)表示搜索范围,C(a,b)表示当前帧在相对坐标(a,b)位置的像素值,S(a,b)表示参考帧在相对坐标为(a,b)处的像素值,则:

其中,M×N为子块大小,(m,n)表示参考块相对于当前块的偏移量,SAD(m,n)表示参考块在偏移量为(m,n)时与当前块的偏差值。而块匹配算法的结果为如下运动向量[5]:

对全搜索块匹配算法而言,搜索范围通常只支持到(-16,16)。对于更大的搜索范围,则适合快速算法实现。本文选择(-16,16)作为搜索窗大小,搜索块一共 47×47个像素。
2 AVS整像素运动估计硬件设计
2.1 像素截断
[2]可知,适当地对像素的低位数据进行截断,并不影响整个运动估计的结果。本文采用的方法并不是真正截断数据,而是利用“与门”将输入像素的低3位变为0,以减少运算量,降低功耗。
2.2 内置SAD加法树计算阵列

要实现高性能全搜索可变块运动估计的硬件结构,需要满足资源利用率高、PE个数少、I/O带宽低等条件。本文采用参考文献[3]提出的在计算阵列中内置加法树的方法。计算阵列由 8×8个处理单元(PE)及二维加法树组成,如图3所示。采用二维阵列结构提高了硬件资源的利用率;将当前像素储存在阵列寄存器中,不需要反复读入当前像素,PE个数由宏块大小决定,不随着搜索窗大小变化而变化;参考像素存储在移位寄存器组中,每个移位寄存器存储9个像素值,配合蛇形移动的数据传输方式,如图4所示,参考块数据输入经过初始的8个移动周期后,寄存器组中正好存放着一个参考块的像素值,之后的每次移动,寄存器组中的数据只需更新一行新的数据,而有7行数据是与上一个参考块共享的,这样能实现列方向100%的数据重用率,有效地减少了I/O带宽。整个设计结构有4个这样的计算阵列,只需在开始计算时等待25个周期,以后的每个周期计算阵列都将输出整个8×8块的SAD值,保证了数据读入过程中的时钟不被浪费。

2.3 进位选择加法器
通过上文介绍的结构可知,每个计算阵列需要使用大量的加法器。当计算小块SAD值时,不仅需要得到当前像素和一个参考像素的差的绝对值,而且需要累加整个块的绝对差值;当计算大块SAD值时,又需要将小块SAD值进行累加。大量的加法器严重影响计算阵列的面积和处理速度,故本设计对加法器进行了改进。目前已有设计选择使用超前进位流水线加法器,其处理速度虽然提高了很多,但是大量并行处理占用了比普通加法器更多的资源。由于进位选择加法器比普通加法器处理速度快,占用的资源比超前进位加法器少,所以本设计选择进位选择加法器。
传统的进位选择加法器使用两个相同的行波法加法器计算高位的值,两个行波法加法器分别假设进位为0和1并同时进行计算,等待正确的进位到来时,再选择正确的结果输出。这样虽然可以缩短等待时间,但是占用面积较大。本文采用加1电路的选择进位加法器,如图5所示。高位加法器以固定进位为0进行计算。若正确进位为0,则加1电路不必进行计算,直接输出结果;若正确的进位为1,则将此结果加1,得到进位为1的结果。加1电路如图6所示,其中CS表示低位进位。如此,计算阵列的面积和功耗将会降低很多,处理速度也较快。

2.4 存储器设计
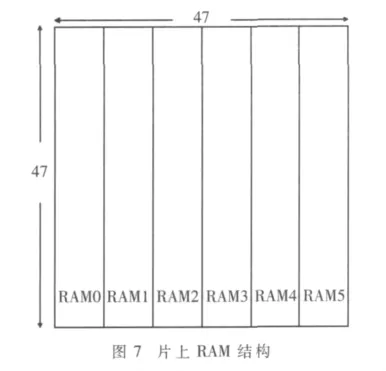
由于当前像素直接存放在阵列寄存器中,所以不需要设计缓冲器。考虑到参考块一共有47×47个像素,且每个周期需要配合计算阵列蛇形输入数据,因此采用片上RAM来缓存参考数据。将参考块分为6个区域,每个区域大小为8×47个像素,用RAM0~RAM5来标识,如图7所示。设计使用双端口RAM,利用奇偶地址,让32 bit双端口RAM相当于64 bit单端口RAM。由于相邻宏块的搜索区域重叠部分占整个搜索块的三分之二,按照本文的存储器设计,当进行下一个宏块的运动估计时,不需要更新整个参考块的数据,只需更新其中两个区域的数据即可,进一步减少了存储带宽,提高了数据的重用率。
各处理水稻各部位镉/砷含量见表3。施加零价铁未对稻米镉含量产生明显影响;施加腐殖质、复合调理剂则明显地降低了水稻各部位镉的含量。与对照相比,施加腐殖质和复合调理剂后,早稻稻米镉含量分别下降14.3%和35.5%;晚稻稻米中镉含量分别下降33.3%和57.4%,差异显著(P<0.05)。施加复合调理剂,早稻稻米镉含量达到食品安全国家标准(GB 2762—2012)。
3 仿真和结构分析
本文提出了一种适用于AVS的高性能整像素运动估计硬件设计,使用了Verilog HDL语言进行RTL级描述,用AVS软件RM52j的 C程序产生测试码流,应用了Modelsim 6.5c仿真平台进行了逻辑功能的仿真验证。采用 Synopsys的 Design Compiler在 SMIC 0.18 μm CMOS 工艺库下综合,在最大频率为250 MHz时,门数为102 K(未包括存储器面积)。表1给出了运动估计硬件设计性能分析,这表明本文所设计的结构具有高性能、低带宽的优势。表2将本文提出的结构与其他几种运动估计结构进行了比较,其中引用了效率E作为一个重要的比较参数,E为结构每秒处理的搜索点数和实际面积的比值,具体公式见参考文献[5]。通过比较可以看出,本设计与参考文献[5]的设计均可实现对高清图像的实时处理,但本设计的最快时钟频率提升了25%,面积减小了36.2%,效率提高了98%。

表1 运动估计硬件设计性能分析
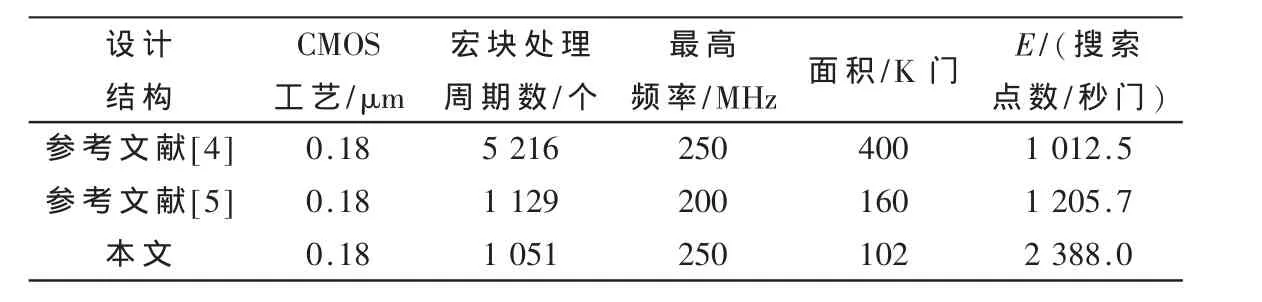
表2 几种运动估计结构综合结果比较
本文针对AVS视频标准,提出了一种适用于AVS的高性能整像素运动估计硬件设计。采用二维内置SAD加法树计算阵列,通过合理的安排片上存储,优化了加法器设计,大大提高了结构的性能。实验结果表明,本设计电路规模为102 K门,处理一个宏块只需要1 051个时钟周期,能够以2 388.0搜索点数/秒门的效率对高清图像进行运动估计。与同类设计相比,本设计具有电路规模小、处理速度快、I/O带宽低等优势。另外,本设计还可以作为IP核嵌入到特定的处理器中,对AVS高清视频进行实时处理。
参考文献
[1]GB/T20090.2-2006.信息技术先进音视频编码第二部分:视频[S].2006.
[2]He Zhongli,LIOU M I.Reducing hardware complexity of motion estimation algorithms using truncated pixels[C].Proceedings of IEEE International Symposium on Circuits and Systems,1997,4:2809-2812.
[3]CHEN C Y,CHIEN S Y,HUANG Y W,et al.Analysis and architecture design of variable block-size motion estimation for H.264/AVC[J].IEEE Transactions on Circuits and Systems,2006,53(3):578-593.
[4]Deng Lei,Xie Xiaodong,Gao Wen.A real-time full architecture for AVS motion estimation[J].IEEE Transactions on Consumer Electronics,2007,53(4):1744-1751.
[5]Cao Wei,Hou Hui,Tong Jiarong,et al.A high-performance
reconfigurable VLSI architecture for VBSME in H.264[J].IEEE Transactions on Consumer Electronics,2008,53(4):1338-1345.
猜你喜欢
宁波大学学报(理工版)(2022年6期)2022-12-01 01:03:44
智富时代(2019年2期)2019-04-18 07:44:42
电子设计工程(2018年18期)2018-10-09 03:00:14
电子世界(2018年1期)2018-01-26 04:58:08
光学精密工程(2016年2期)2016-11-07 09:02:32
老同志之友(2016年5期)2016-05-14 07:10:19
电子设计工程(2015年24期)2015-08-26 06:39:42
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:36
杭州电子科技大学学报(自然科学版)(2011年5期)2011-09-04 06:09:24
电视技术(2011年11期)2011-03-15 01:22:42
