
基于语料库的《论语》二译本对比研究
2013-08-01 12:37:44张黎黎黄永新
河北开放大学学报 2013年2期
张黎黎, 黄永新
(石家庄铁路职业技术学院,河北 石家庄 050061)
基于语料库的《论语》二译本对比研究
张黎黎, 黄永新
(石家庄铁路职业技术学院,河北 石家庄 050061)
基于自建的《论语》中英文平行语料库,利用语料库技术将《论语》两个英译本在词汇和句子层面进行了数据统计和量化分析。结果发现二译本的译语特征明显,同时又体现出各自独有的特点。对我国传统典籍英译的启示为:短词短句可以降低文本阅读难度,利于争取更大的读者群;意译或阐释策略易于读者接受并理解译文;在上述基础上考虑最大限度地保留原文特征,以达到弘扬中国文化的目的。
语料库;《论语》;数据;译本分析
一、引言
近年来,随着文化全球化趋势的不断深化,典籍英译研究日益引起国内汉学界和翻译界研究者的重视和关注。但是,中国传统文化典籍的翻译还存在很多遗憾:我国约有3.5万种古典书籍,但至今翻译成外文的只有千分之二左右;代表中国文化精髓的《论语》作为中国传统文化典籍中对外翻译版本最多的一部(50余种),国家汉办至今没有正式公布官方译本。综上,现有的《论语》译本很多,但能满足时代需求的却少之又少;另外,现有研究的对象和视角相对较窄,在广度和深度方面还远远不够。
本研究采用的两个《论语》英译本(刘殿爵译本、辜鸿铭译本)在历史上具有一定的代表性。其中,刘殿爵是西方最受尊敬的中国哲学翻译大师,其《论语》译本为畅销不衰的“企鹅经典”;辜鸿铭是第一个独立用英文翻译《论语》等儒家经典的中国人,在国外拥有广泛读者且影响很大,其译作在西方颇为畅销。本研究采用语料库手段,重视宏观语言特征的考察,希望为《论语》英译研究提供一个全新的视角。
二、研究方法
研究采用的语料库为自制的《论语》二译本平行语料库。经扫描仪扫描、OCR字体识别、文本清洁、语句对齐等一系列工作,最终达到平行语料库检索软件CUC_ParaConc对检索语料的格式要求。该语料库共包含646句对。研究选用的语料库工具包括AntConc、CUC_ParaConc、Readability Analyzer及分词软件等。在借鉴前人经验的基础上,本研究将从标准化类符/形符比、词汇密度、高词频词长分布、平均句长、语篇可读性等方面探讨《论语》两个英译本的语言特征。
三、研究结果分析
1.类符/形符比
类符/形符比值的高低与文本的词汇丰富程度和多样性成正比。但文本越长,功能词的重复次数就越多,类符/形符比就越低。因此通常使用标准化类符/形符比来考察词汇密度。借助语料库工具AntConc及Readability Analyzer 1.0可分别获取《论语》二译本中词汇的基本数据(见表1)。从词汇数量来看,辜译较多,从而文本的显化特征较明显;从标准化类符/形符比看,刘译稍高,说明在文字数量等同的情况下,刘译的词汇丰富度较高,阅读难度较大。但这一比值统计的类符包括实意词和功能词,过度修饰的语篇由于功能词过多也可能造成标准化类符/形符比的数值升高,但这并不意味着语篇信息量的增加,下面我们通过其他方式继续进行考察。

表1 《论语》二译本词句统计
2.词汇密度
另外一种词汇密度的统计方法为实词与总词数比值的百分比。实词包括名词、实义动词、形容词和副词。Laviosa曾证实英语译语的词汇密度为52.87%,英语源语的词汇密度为54.95%,并得出结论:译语具有词汇密度较低的特点。经词性标注及分类统计后,我们得出刘译和辜译的词汇密度分别为48.99%和49.24%。二译本的词汇密度都低于Laviosa统计出的译语词汇密度值,表明这两部《论语》译本具有明显的翻译文本的语言特征,词汇丰富程度均低于一般译语文本,从而总体阅读难度较低。相比较而言,刘译词汇密度值稍低于辜译,从而阅读难度低于辜译。这与标准化类符/形符比的考察结果相悖。
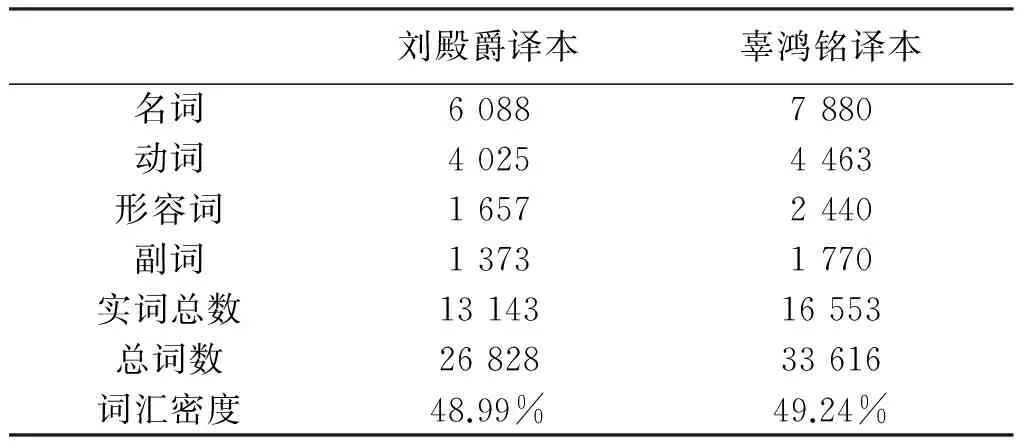
表2 两个语料库的词汇密度比较
3.高频词
通过语料库工具AntConc中的词表(Wordlist)功能,可以获得加载语料库的词汇频率,并以降序进行排列。通过观察高频词表可以分析译本的风格及特点。为使分析简单易行,本文仅观察高于1%的词汇使用情况(表3)。从表中可以直观地看出二译本的高频词大多为功能词,且基本相同,只不过排序略有差异,说明二译本的句式结构基本一致。同时,也可以看出在表述“子”这一概念时,刘译本惯用The Master,而辜译本惯用Confucius;在表述“曰”这一概念时,刘译本惯用“said”,而辜译本没有明显的惯用词。从高于1%的词汇总量上看,刘译为29.85%,辜译为30.28%,说明两个译本的高频词使用比例都很高,词汇的重复次数较多,阅读难度较低,再一次印证了Laviosa关于译语使用较多高频词的观点。

表3 高频词汇表(高于1%)
4.词长分布
就平均词长来看,刘译和辜译分别为4.17和4.34(见表1),说明刘译使用的词汇较简单,一定程度上阅读难度较低。进一步观察发现(见表4),二译本中6个字母和7个字母的单词所占比例最大,均介于15%-16%之间。其他按百分比从大到小排列依次为5个字母单词(14%-15%),4个字母单词(12%-15%),8个字母单词(11%-12%),9个字母单词(8%-10%)。二译本4-9个字母的单词总量占各自译本总词数的百分比分别为79.33%和79.53%,二者相近且总值接近80%,说明《论语》二译本主要采用4-9个字母的单词,书面语特征明显。相比较而言,刘译使用的1-5个字母的单词比例高于辜译,而8-10及≥11个字母的单词比例则低于辜译,进一步表明刘译用词较短,全文浅显易懂;而辜译用词较长,全文阅读难度较大。这与词汇密度的考察结果一致。

表4 《论语》二译本主要词长分布
5.平均句长
Laviosa曾对英语译语和英语源语语料库进行统计,得出英语译语和英语源语的平均句长分别为24.1和15.6个单词,总结出译语的平均句长明显高于源语的结论。表1显示,刘译的句子数量为1 675句,而辜译为1 663句;刘译的平均句长为15.86个单词,而辜译为20.20个单词。说明二者对原文翻译和阐释时使用的句子数量相当。刘译受原文语言简练的影响明显,多用直译策略,句式简短,语言的明晰化程度不高,更多地保留了孔子的思想,但原文主旨不易被读者理解、接受;而辜译较接近译语的特点,多结合上下文意译原著,句子较长,显化特征明显,通过增添修饰语、解释等手段明确原文的隐含意义,原文主旨易于被读者理解、接受,但译文忠实性和准确性有所缺失。
6.语篇可读性
语篇可读性是对文章难易程度的衡量,能在宏观上发现翻译文本是否存在简化趋势。Flesch Reading Ease(弗莱士易读度)是反映文本可读性信息的一种常用统计方法,其计算根据是句子的字数和句子中含的音节数等,数值在0到100之间,数目越大,文章越容易读。对于大多数英语原创文本而言,该易读度数值介于60至70之间。本研究采用可读性分析软件Readability Analyzer 1.0统计得出刘译和辜译的Flesch Reading Ease数值分别为72.12和64.86。说明刘译的阅读难度稍低于一般英语原创文本,而辜译与一般英语原创文本几乎相当。总的来说,二译本的简化特征不明显。当然,这些可读性信息主要是根据句子的长度及句子的音节数统计的,与阅读难度相关的还有对语篇内容的熟悉程度和深层、表层的理解等。
四、结束语
从词汇密度来看,《论语》二译本具有明显的译语特征,用词丰富度均低于英语源语,高频词比例都很高;同时发现两个译本体现出各自独有的特点:刘译多用短词和短句、词汇丰富度稍低、Flesch Reading Ease值较高,总体阅读难度较低,多用直译策略,原文特征保留较好,但译文不易被接受;辜译多用长词和长句、用词丰富较高、Flesch Reading Ease值较低,总体阅读难度较高,多用意译策略,译文显化程度高,易于读者理解,但原文中的中国文化特征有所缺失。上述研究结果对我国传统文化典籍英译的启示为:多用短词短句,以降低文本阅读难度,从而争取更大的读者群;采用意译或阐释策略利于读者接受并理解译文;在上述基础上考虑最大限度地保留原文特征,以达到弘扬中国文化的目的。
[1]Baker, Mona. Corpora in translation studies: an overview and some suggestions for future research[J].Target, 1995,(2).
[2]Baker, Mona. Towards a Methodology for Investigating the Style of a Literary Translator [J].Target. 2000,(2).
[3]Laviosa, Sara. Core patterns of lexical use in a comparable corpus of English narrative prose [J].Meta, 1998,(4).
[4]安乐哲.自我的圆成:中西互镜下的古典儒学与道家[M].彭国翔,编译.石家庄:河北人民出版社,2006.
[5]黄中习.文化典籍英译与苏州大学翻译方向研究生教学[J].上海翻译,2007,(1).
[6]王勇.20年来的《论语》英译研究[J].求索,2006,(5).
[7]杨平.中西文化交流视域下的《论语》英译研究[M].北京:光明日报出版社,2011.
Corpus-based Comparative Analysis of Two English Versions ofTheAnalects
ZHANG Lili, HUANG Yongxin
(Shijiazhuang Institute of Railway Technology, Shijiazhuang, Hebei 050041, China)
Based on the self-built parallel corpus ofTheAnalects, the paper gives data statistics and quantitative analysis of two English versions ofTheAnalectsin levels of words and sentences by using corpus technologies. The result shows that two English versions have apparent features of translated language and their respective characteristics at the same time. The enlightenments to translating Chinese traditional classics into English are as follows. Firstly, it is better to use short words and sentences to reduce the reading difficulty so as to win more readers. Secondly, it is recommended to adopt strategies of free translation and interpretation to facilitate readers’ understanding and attract their reading of translated text. Thirdly, on the above bases, it is necessary to take into consideration of keeping features of original texts as much as possible to achieve the purpose of carrying forward the Chinese culture.
corpus;TheAnalects; data; analysis of English version
2013-01-10
2012年度河北省社会科学发展研究课题《基于语料库的文化转向视阈下〈论语〉英译研究》(201204068)
张黎黎(1981-),女,河北正定人,文学硕士,讲师,主要从事英美文学、外语教学研究。
I046
A
1008-469X(2013)02-0057-03
猜你喜欢
天府新论(2022年3期)2022-05-04 03:40:24
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
西夏研究(2019年1期)2019-03-12 00:58:16
疯狂英语(双语世界)(2017年4期)2017-04-28 09:10:28
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
西藏研究(2016年2期)2016-06-05 11:31:13
科技视界(2015年35期)2016-01-04 09:37:11
语言与翻译(2015年4期)2015-07-18 11:07:45
当代外语研究(2010年3期)2010-03-20 14:36:38
外语学刊(2010年2期)2010-01-22 03:31:10
