
基于密度期望和有效性指标的K-均值算法
2013-07-20 02:34何云斌肖宇鹏万静李松
计算机工程与应用 2013年24期
何云斌,肖宇鹏,万静,李松
哈尔滨理工大学计算机科学与技术学院,哈尔滨 150080
基于密度期望和有效性指标的K-均值算法
何云斌,肖宇鹏,万静,李松
哈尔滨理工大学计算机科学与技术学院,哈尔滨 150080
1 引言
所谓聚类,就是根据事物的某些属性,将其划分为若干类,使得类内相似性尽量大,类间相似性尽量小。聚类是一种无监督分类方法,其对数据及分析人员的专业相关知识要求较少,因而其相关技术在统计、模式识别、机器学习和数据挖掘等诸多领域中都有极其广泛的应用前景[1]。通过适当的聚类,可以发现同类事物共同性质的特征型知识,以及不同类事物之间的差异型知识。为了对数据对象进行聚类,目前已经提出许多有效的聚类算法,例如基于层次的CURE[2]算法,基于划分的K-Means[3]算法,基于密度的DBSCAN[4]算法,基于网格的STING[5]算法,基于模型的COBWEB[6]算法等。
在诸多聚类算法中,K-均值聚类算法是使用最为广泛的算法之一。该算法对大型数据集的处理效率较高,特别是当簇群密集,簇间距离较大时,能得到较好的聚类效果。传统K-均值算法的初始聚类中心点是从数据集中随机产生的,因此在聚类过程中容易陷入局部最优解,并且聚类结果不稳定。针对上述缺点,文献[7]中Likas等人提出了全局K-均值算法,通过不断迭代的方式最终确定最佳初始聚类中心;文献[8]提出了基于可变阀值的初始聚类中点选取方法,选择较为分散的样本作为初始聚类中心,以增加找到全局最优解的可能性;文献[9]对最大最小距离算法进行了改进,选取到所有已初始化聚类中心距离最大的高密度点作为当前聚类中心;文献[10]引入特征选择和特征赋权思想,提出了基于密度的初始中心点选取算法和改进的特征赋权K-均值算法;文献[11]将免疫原理的选择操作机制引入遗传算法中,利用遗传算法全局寻优能力和K-均值算法的高效性,较好地解决了聚类中心优化的问题;文献[12]提出了一种改进人工蜂群算法与K-均值相结合的混合聚类方法,将蜂群算法全局寻优能力与局部寻优能力的优点与K-均值算法收敛速度快的优点相结合,克服了传统K-均值聚类算法稳定性差的缺点。此外,对于实际问题中聚类数目的适当选取也是获取高精度聚类结果的关键因素之一。但多数情况下,聚类数k无法预先确定。对于有效聚类数k值的选取,李永森,杨善林等[13]提出了距离代价函数,综合了类间距离与类内距离,并证明了当距离代价函数最小时,可得到最佳聚类数k;汪中等[14]学者在距离代价函数的基础上,提出了新的评价函数,即均衡化函数,以均衡化函数为准则自动生成有效聚类数目;文献[15]则利用二分思想递归分裂簇内相似度大于给定阀值的簇,合并簇间相似度小于给定阀值的簇,从而最终确定有效的聚类数;此外,诸如Silhouette[16]、Calinski-Harabasz[17]、In-Group Proportion[18]、Davies-Bouldin[19]、Dunn[19]等学界公认较为优秀的聚类有效性指标函数也常用于评价聚类结果,并根据评价的结果来确定最优的k值。
本文首先提出了基于密度期望的初始聚类中心点选取方法。该方法消除了传统K-均值算法对初始聚类中心点选取的盲目性,并且有效地减少了聚类的迭代次数,同时还获得了更稳定的聚类结果。在上述基础上,本文还给出了一种基于密度期望和聚类有效性指标函数的K-均值优化算法。该算法对于不同的k值,首先使用基于密度期望的方法选取k个初始聚类中心点,其次对样本集进行聚类,最后通过聚类有效性指标分析每次聚类的结果,从而确定最佳有效聚类数。
2 传统K-均值聚类算法

式中,nj表示聚类子集Cj中样本的数量。
传统K-均值聚类算法基本思想:首先随机地从样本空间中选取k个初始聚类中心;通过式(1)计算对象间的距离,根据距离最小的原则,将每个对象分配给距离最近的初始代表点所在的聚类簇Cj;完成数据样本划分后,对每一个聚类簇计算簇中所有对象的平均值cj,并将其作为新的簇中心点;通过不断迭代对样本数据进行划分,直至划分的结果不再发生变化,即误差平方和准则函数E的值达到最优。误差平方和准则函数定义为:

式中,xi为空间的点,即数据对象,ci是簇Ci的平均值。E越大说明对象与聚类中心的距离越大,簇内的相似度越低;E越小说明簇内的相似度越高。
算法描述如下:

从算法的第一步可以看出,在聚类数目k值事先确定的情况下,初始中心点的选取是随机的。这就可能造成在同一类别中的样本被强行当做两个类的初始聚类中心,如图1中的红色样本数据,其中有两个黑色样本点被强行选做两个类的初始聚类中心。因此在图2中,最终使得聚类结果只能收敛于局部最优。故而,K-均值算法的聚类效果在很大程度上依赖于初始聚类中心的选择。
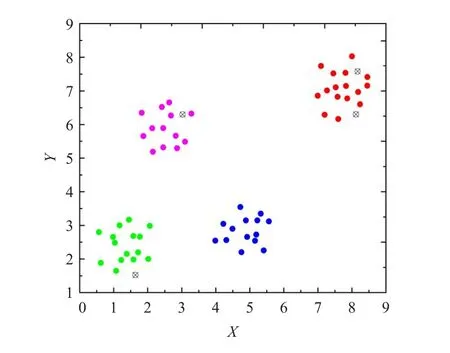
图1 初始中心点随机选取情况
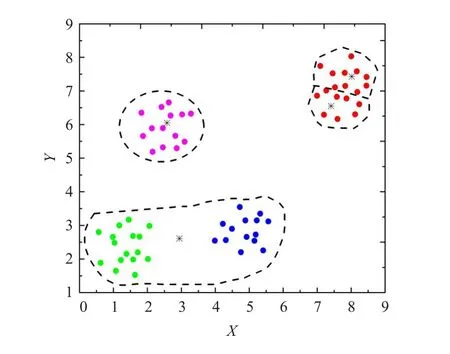
图2 聚类结果的局部最优
3 基于密度期望的初始中心点选取
对于传统的K-均值聚类算法,随机选取初始的聚类中心往往不能较好地反映数据的分布情况,因而得到的聚类结果往往也是局部最优的。通常希望所选取的初始聚类中心较为分散,但在一般的基于贪心算法的初始中心点搜索过程中,由于仅考虑距离因素,往往找到许多孤立点作为初始聚类中心点,不利于算法的聚类[15]。因此在选择聚类初始中心点时,如果同时考虑距离和密度两个因素,则可有效改善初始聚类中心点的选取效果。这里所提及的密度是指样本的密度,具有统计的性质,即对于待聚类样本中的某一对象,在其给定的邻域有效半径r中包含的样本数目,即为该样本点的密度。此外,期望所选取的最大样本密度应小于或等于聚类簇中样本的数量。因为这样的一组样本点在邻域有效半径r作用下,能较好地反映该聚类簇的分布情况。特别是对于每一个聚类簇中样本数量大致相当的情况下,如图3中所示,所选取的一组样本点,在半径r的邻域内包含了其所属聚类簇中样本的70%左右。因此可以看出该组样本点能有效地代表其所属聚类簇中的所有样本。因而在聚类数k已知的情况下,可以通过计算样本总数n和k值,进而得到每一个聚类簇中大致期望的样本平均个数,同时对其附加最大及最小期望系数,即为样本点密度范围的上、下限。随后从最大与最小密度期望之间选取相距最远的k个对象作为初始聚类中心。这样不仅能有效避免所选取的样本点过分密集,同时还屏蔽了异常数据对算法结果的影响。
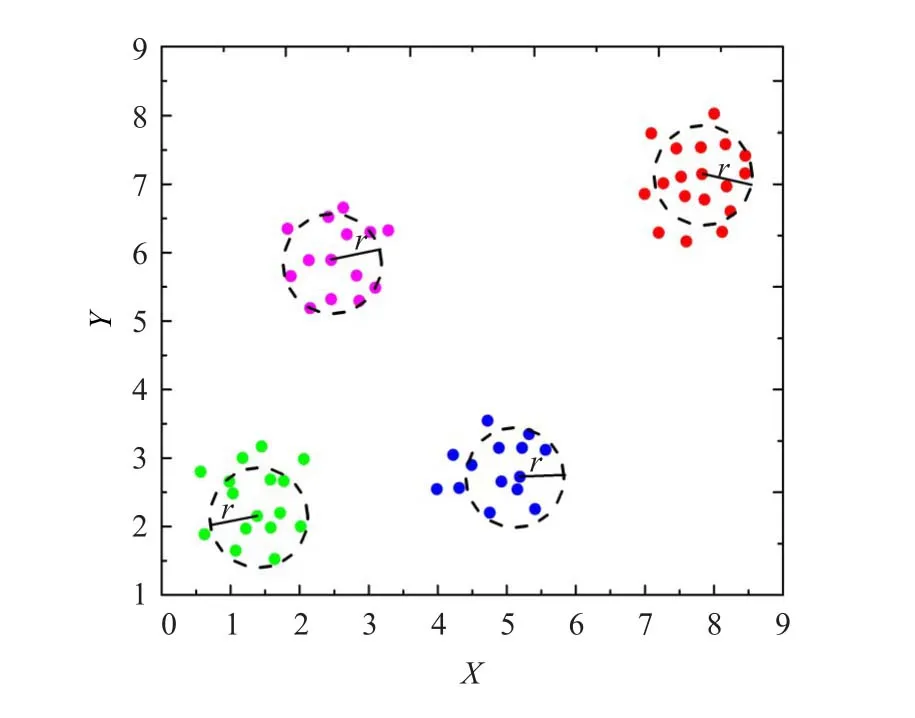
图3 邻域半径r下的样本密度
3.1 基本定义
已知样本数据集X={x1,x2,…,xn}为m维空间的n个对象。
定义1(样本密度)对于空间中任意样本xi和邻域有效半径r,以样本xi为中心,半径为r的区域中样本点个数称为样本xi基于距离r的密度,计为Density(xi),即
Density(xi)={p∈X|Dist(xi,p)≤r}(4)式中,r为邻域有效半径,Dist(xi,p)为数据集中任意两点的欧氏距离,其定义如2章中的式(1)。
定义2(邻域半径)邻域有效半径r定义为:
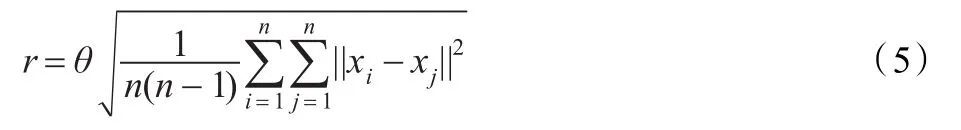
式中,θ为半径调节参数;n为样本个数;xi,xj为样本对象。
聚类对象的有效邻域半径r以n个样本的均方根距离为基础,这是由于样本的均方根距离能较好地反映样本的离散程度,通过调节参数θ来调节半径r的大小,使得半径r保持在一个合理的范围内。
定义3(密度期望)密度期望范围定义为:
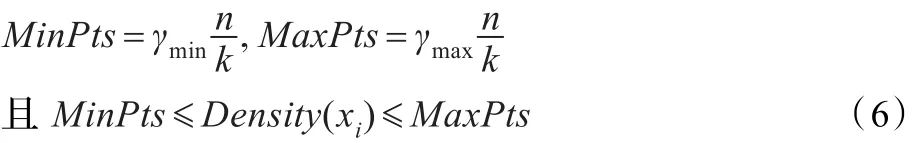
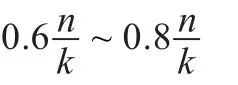
3.2 基于密度期望的初始中心点选取方法
设样本数据集X={x1,x2,…,xn}为m维空间的n个对象,现将对其聚成k类;集合D包含样本密度在密度期望区间范围内的样本点;集合U保存所选取的初始聚类中心。
算法的基本思想是:计算样本总数n和k值,得到每个类簇中大致期望的样本平均个数,并对其附加最大及最小期望系数,从而得到密度期望区间的上下限;其次计算数据集中所有样本的密度,将介于密度期望区间范围内的样本添加到集合D中;接着从集合D中选取密度最大的样本点d1作为第一个初始聚类中心点,并添加到集合U中,此时D=D-{d1},U=U∪{d1};然后不断从集合D中选取距集合U中所有样本平均距离最远的样本di,作为第i个初始聚类中心点添加到集合U中,有D=D-{di},U=U∪{di},直至集合U中的样本数等于k为止。最后,以集合U中的k个样本作为初始聚类中心,按照K-均值算法进行聚类分析。
算法描述:


算法中,选取处于密度期望范围内相距最远的k个对象作为初始聚类中心点,这些中心点能较好地反映数据的分布,使聚类结果具有较好的稳定性。但是有效邻域半径调节参数θ是未知的,是根据实验数据选取的,其数值的大小会对有效邻域半径r产生影响。这是因为r过大或者过小都会使聚类结果较差,故而要求有效邻域半径r的取值应能良好地反映样本在空间的分布情况。通常有效邻域半径调节参数θ是基于经验选取的,θ满足0<θ<1。
传统K-均值算法的时间复杂度为O(nkt),其中n是所有样本数目,k是聚类数目,t是迭代的次数[20]。在基于密度期望的改进K-均值算法中,计算样本密度时需要事先计算所有样本之间距离,其时间复杂度为O(n2),因此该算法的时间复杂度为O(n2+nkt),即O(n2)。
4 基于密度期望和聚类有效性指标函数的k值优化
对于有效聚类数k值的选取,目前通常的做法是要预先确定其最佳搜索范围[kmin,kmax]的上、下限,而后在从中选取合适的数值作为最佳有效聚类数。其中对于最佳搜索范围下限kmin有,当kmin=1时,表明样本是均匀分布的,无明显特征差异。因此通常聚类数k最小为2,即kmin=2[21]。而对kmax的确定尚无明确的理论指导,其中Frey等人在文献[22]中提出了近邻传播聚类算法(Affinity Propagation clustering),简称AP算法,将该算法产生的聚类数作为聚类数搜索范围的上限kmax。此外,更多采用的是通过经验规则来确定聚类数搜索范围的上限kmax,即kmax≤n。于剑等在文献[23]中给出了确定kmax新方法,该方法证明了规则kmax≤n具有一定的理论依据,并在文献中验证了新方法的有效性。杨善林等[13]提出了运用距离代价函数确定最优的k值,同时还给出了k值最优解kopt及其上界kmax的条件,并证明了规则的合理性。
4.1 聚类有效性指标函数
当确定有效聚类数目k的搜索范围后,选择合适的聚类有效性指标是尤为关键的。聚类有效性指标主要有两类,即外部有效性指标和内部有效性指标。当原始数据划分是已知的情况下,外部有效性指标反映了聚类划分结果与原始数据划分之间的吻合度;内部有效性指标则是在原始数据划分未知的情况下评价聚类结果好坏的一个度量。因而对于有效聚类数目k的确定,可借助内部有效性指标来实现。通过对不同k值下聚类有效性指标的计算,将最优聚类结果所对应的聚类数目作为最佳聚类数,从而最终确定有效的k值。目前在常用的聚类有效性指标函数中Silhouette[17]指标以其较优良的性能及较低的计算复杂度,得到了广泛的应用。Silhouette指标是一种复合型指标,Silhouette指标定义如下:

假设样本xi属于簇Ci,a(xi)表示样本xi到Ci中其余样本的平均距离;b(xi)表示样本xi到其他每个类中样本的平均距离的最小值。即有:
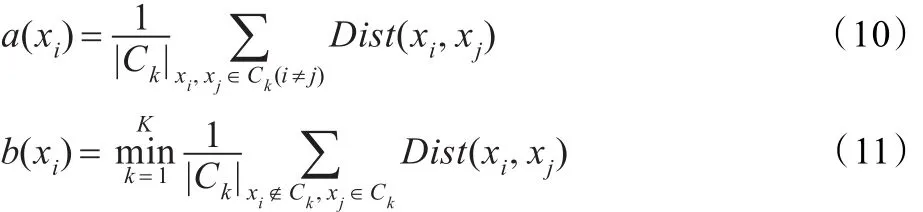
每个样本的Silhouette指标值介于[-1,1]的区间内,当Sil(xi)接近于1时,表明样本xi归到簇Ci是适合的;当Sil(xi)近似于0时,表明样本xi可能属于距离簇Ci最近的类簇中;当Sil(xi)近似于-1时,表明样本xi被错到类簇Ci中。因此,Silhouette指标既能反应出目标样本跟其所属簇内样本的相似程度,也能反应出目标样本跟其他簇中样本的不相似程度。同样的对于样本任何的一次划分,如果求出该划分结果中所有样本的Silhouette平均值,就能够了解到该划分的优劣。全部样本的Silhouette平均值定义如下:

式中,n表示样本数量。Silhouette平均值越大表示聚类结果质量越好,其最大值所对应的类数就是期望的最佳聚类数。结合调研资料和相关实验分析,认为Silhouette指标作为K-均值算法聚类结果评价指标是合适的。
4.2 基于密度期望和有效性指标函数的K-均值优化算法
基于密度期望和有效性指标函数的k值优化算法的基本思想是:首先确定最佳聚类数k的搜索范围[kmin,kmax],根据不同的k值,首先通过基于密度期望原则选取k个初始聚类中心点;其次使用传统的K-均值聚类算法聚类;计算每次聚类的有效性指标——Silhouette指标值;最后分析聚类结果,根据最大Silhouette平均值确定最优聚类数。容易分析得出基于密度期望和有效性指标函数的k值优化算法的复杂度为O(n2)。该算法的描述如下:

5 实验结果与分析
本文实验分为两部分,第一部分将传统K-均值算法与基于密度期望的改进K-均值算法进行比较,所采用的测试数据集是UCI中的Iris、Glass、Wine、Balance-scale 4组数据。第二部分是在基于密度期望的改进K-均值算法的基础上,采用聚类有效性Silhouette指标确定最佳聚类数的实验,所采用的人工数据集DataSet1,DataSet2。数据集描述如表1所示。

表1 实验数据
5.1 基于密度期望改进K-均值算法实验与分析
实验分别从类间距、类内距、正确率和迭代次数四个方面对比了改进的K-均值算法和传统的K-均值算法,并给出分析结果。将基于密度期望的改进K-均值算法中数据对象的密度期望系数锁定在0.7至0.9之间,即γmin=0.7,γmax=0.9;设定Iris数据集半径调节系数θ=0.4,Wine数据集半径调节系数θ=0.7,其余两个数据集的半径调节系数θ= 1;进行聚类分析并记录聚类结果。此外,运用传统K-均值算法对上述数据集进行10次独立聚类实验,记录每次实验结果,并求其结果的平均值与基于密度期望的改进K-均值算法所获得的结果进行比较。实验结果对比分析如表2所示。
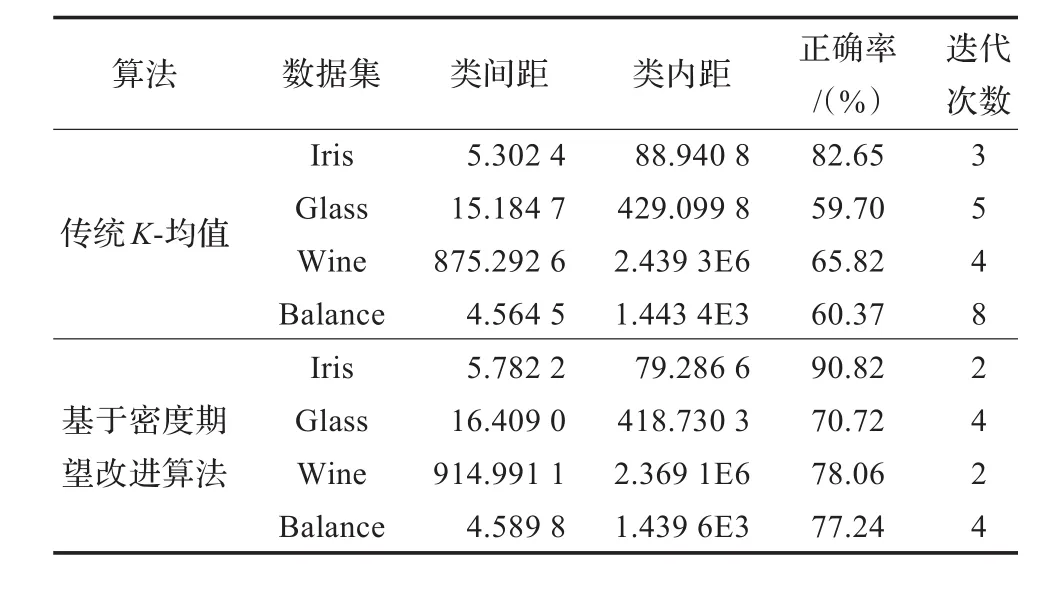
表2 新旧算法聚类性能实验对比
由本实验所得的结果可以看出,基于密度期望的改进K-均值算法的各项聚类评价指标均优于传统K-均值聚类算法。其中基于密度期望的改进K-均值算法的实验结果中类间距相对更大,类内距相对更小,实验结果的正确率要高于传统K-均值算法,而迭代次数也有所减少。这是因为基于密度期望的改进K-均值算法所选取的初始聚类中心点更加稳定,其选取结果基本符合数据的实际分布情况,从而帮助算法更加高效、快速地向最优逼近,最终提高了其聚类性能。
5.2 最佳聚类数确定的实验与分析
在基于密度期望的改进K-均值算法的基础上,采用聚类有效性Silhouette指标确定最佳聚类数,并将实验结果与随机确定初始聚类中心点的计算结果对比,考察两种不同方法对Silhouette指标的影响。实验采用人工生成的数据集DataSet1、DataSet2。此外,本实验还给出了两种初始中心点选取方法下聚类结果的直观对比。
根据样本数据总量确定DataSet1的聚类数搜索范围为[2,48];DataSet2的聚类数搜索范围为[2,62]。将基于密度期望的改进K-均值算法分别应用于数据集DataSet1、DataSet2中,其类数与Silhouette指标的关系如图4、图5所示。将随机确定初始聚类中心点的方法分别应用于数据集DataSet1,DataSet2中,其类数与Silhouette指标的关系图如图6、图7所示。表3给出了上述两种初始聚类中心选取方法下的最佳聚类数实验结果。结合表3分析可得:图4中数据集DataSet1最佳聚类数为3,其对应的Silhouette指标为0.792 8;在图5中,数据集DataSet2最佳聚类数为4,其对应的Silhouette指标取到最大的0.755 7。可以得出改进后的算法,依据Silhouette指标可以得到准确的聚类数目。然而图6中数据集DataSet1在随机初始中心点选取方法下,其最佳聚类数为4,其对应的Silhouette指标为0.780 1;图7中,数据集DataSet2的最佳聚类数为5,其对应的Silhouette指标取为0.677 9。均未得到正确的聚类数目。
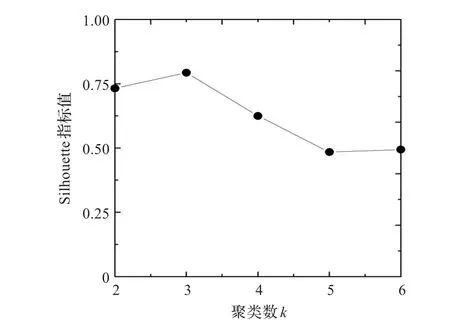
图4 基于密度期望的改进K-均值算法下DataSet1聚类数-Silhouette指标关系图

图6 基于传统K-均值算法下DataSet1聚类数-Silhouette指标关系图
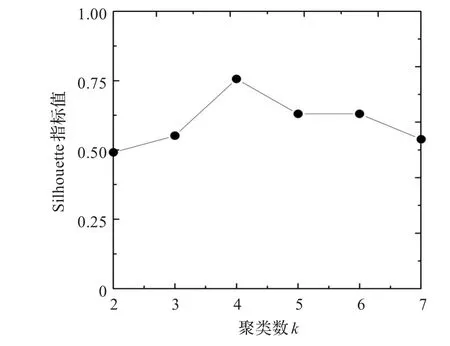
图5 基于密度期望的改进K-均值算法下DataSet2聚类数-Silhouette指标关系图

图7 基于传统K-均值算法下DataSet2聚类数-Silhouette指标关系图

表3 基于不同初始中心点选取方法得到的最佳聚类数
此外,采用基于密度期望的初始中心点选取方法,所得到的两个人工数据集的聚类效果分别如图8,图9所示。结果表明采用基于密度期望的改进K-均值算法能得到最佳聚类效果。表4给出了两种方法下的聚类准确率和迭代次数。可以看出在对于类内紧凑,类间远离的聚类结构时,基于密度期望的K-均值改进算法得到的聚类结果是唯一确定且正确合理的。而采用随机方法确定初始聚类中心点得到的聚类效果往往欠佳。

图8 数据集DataSet1的聚类效果图

图9 数据集DataSet2的聚类效果图

表4 基于不同初始中心点选取方法得到的聚类准确率和迭代次数
实验结果表明:基于密度期望的初始中心点的选取方法结合聚类有效性指标Silhouette指标能够得到正确的最佳聚类数。而基于随机初始中心点选取方法则很难得到正确的最佳聚类数。
6 结束语
传统K-均值聚类算法在聚类数目k已知的情况下,通过随机选取k个样本作为初始聚类中心,聚类结果受初始聚类中心影响较大,容易陷入局部最优。提出将样本对象的密度锁定在一个合理的期望范围内,从中选取k个相距最远的对象作为初始中心点。能有效地降低初始中心点的敏感性。实验表明,基于密度期望的初始中心点的选取方法能获得较为稳定且高质量的聚类效果。此外,结合本文提出的基于密度期望的初始中心点选取方法,通过聚类有效性Silhouette指标分析聚类结果,从而确定最佳聚类数,可有效改善K值无法预先确定的缺点。实验分析结果验证了所提出方案的可行性。该方案及实验结果对K-均值聚类算法的进一步研究,具有一定的理论和实践参考价值。
[1]张志兵.空间数据挖掘及其相关问题研究[M].武汉:华中科技大学出版社,2011:20-21.
[2]Guha S,Rastogir,Shmk.Cure:an efficient clustering algorithm for large databases[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data.New York:ACM Press,1998:73-84.
[3]Mac Q J.Some methods for classification and analysis of multivariate observations[C]//Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability.USA:University of California Press,1967:281-297.
[4]Ester M,Hans P K,Sander J,et a1.A density based algorithm for discovering clusters in large spatial databases with noise[C]// Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining(KDD-96),Portland,1996:226-231.
[5]Wang W,Yang J,Muntz R.Sting:a statistical information grid approach to spatial data mining[C]//Proceedings of the 23rd IEEE International Conference on Very Large Data Bases,Athens,1997:186-195.
[6]Kohonen T.Self organized formation of topologically correct feature maps[J].Biological Cybernetics,1982,43(1):59-69.
[7]Likas A,Ulassis M,Uerbeek J.The global k-means clustering algorithm[J].Pattern Recognition,2003,36(2):451-461.
[8]刘一鸣,张化祥.可变阈值的K-means初始中心选择方法[J].计算机工程与应用,2011,47(32):56-58.
[9]熊忠阳,陈若田,张玉芳.一种有效的K-means聚类中心初始化方法[J].计算机应用研究,2011,28(11):4188-4190.
[10]任江涛,施潇潇,孙靖昊,等.一种改进的基于特征赋权的K均值聚类算法[J].计算机科学,2006,33(7):186-187.
[11]徐家宁,张立文,徐素莉,等.改进遗传算法的K-均值聚类算法研究[J].微计算机应用,2010,31(4):11-15.
[12]毕晓君,宫汝江.一种结合人工蜂群和K的值的混合聚类算法[J].计算机应用研究,2012,29(6):2040-2046.
[13]杨善林,李永森,胡笑旋,等.K-means算法中的k值优化问题研究[J].系统工程理沦与实践,2006(2):97-101.
[14]汪中,刘贵全,陈恩红.一种优化初始中心点的K-means算法[J].模式识别与人工智能,2009,22(2):299-304.
[15]张中平,王爱杰,柴旭光.简单有效的确定聚类数目算法[J].计算机工程与应用,2009,45(15):166-168.
[16]Thalamuthu A,Mukhopadhyay I,Zheng X,et al.Evaluation and comparison of gene clustering methods in microarray analysis[J].Bioinformatics,2006,22(19):2405-2412.
[17]Dudoit S,Fridlyand J.A prediction-based resampling method for estimating the number of clusters in a dataset[J].Genome Biology,2002,3(7):1-21.
[18]Kapp A V,Tibshirani R.Are clusters found in one dataset present in another dataset?[J].Biostatistics,2007,8(1):9-31.
[19]Halkidi M,Batistakis Y,Vazirgiannis M.On clustering validation techniques[J].Journal of Intelligent Information Systems,2001,17(2):107-145.
[20]孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
[21]周世兵,徐振源,唐旭清.新的K-均值算法最佳聚类数确定方法[J].计算机工程与应用,2010,46(16):27-31.
[22]Frcy B J,Dueck D.Clustering by passing message between data points[J].Science,2007,315(5814):972-976.
[23]于剑,程乾生.模糊聚类方法中的最佳聚类数的搜索范围[J].中国科学:E辑,2002,32(2):274-280.
HE Yunbin,XIAO Yupeng,WAN Jing,LI Song
School of Computer Science and Technology,Harbin University of Science and Technology,Harbin 150080,China
The traditionalK-means clustering algorithm must be given in advance the number of clustersk,but in the actual cases,kis difficult to establish;in addition,traditionalK-means clustering algorithm is sensitive to initialization and easily falls into local optimum.In view of this,this paper presents an improvedK-means algorithm based on expectation of density and Silhouette validity index.The algorithm chooses the furthest mutual distanceksample objects as the initial centers,which belong to the expectation of density region.The experimental result shows that the improvedK-means algorithm has not only the weak dependence on initial data,but also fast convergence and high clustering quality.Meanwhile,the new algorithm can automatically analyze the clustering quality in differentkvalues and determine the optimal number of clusters by selecting the Silhouette validity index.The experiment and analysis demonstrate the feasibility and effectiveness of the proposed algorithm.
K-means clustering;initial clustering centers;expectation of density;optimization ofk
传统K-均值聚类算法虽然收敛速度快,但存在聚类数k无法预先确定,并且算法对初始中心点敏感的缺点。针对上述缺点,提出了基于密度期望和聚类有效性Silhouette指标的K-均值优化算法。给出了基于密度期望的初始中心点选取方案,将处于密度期望区间内相距最远的k个样本作为初始聚类中心。该方案可有效降低K-均值算法对初始中心点的依赖,从而获得较高的聚类质量。在此基础上,可进一步通过选择合适的聚类有效性指标Silhouette指标分析不同k值下的每次聚类结果,确定最佳聚类数,则可有效改善k值无法预先确定的缺点。实验及分析结果验证了所提出方案的可行性和有效性。
K-均值聚类;初始聚类中心点;期望密度;k值优化
A
TP18
10.3778/j.issn.1002-8331.1307-0079
HE Yunbin,XIAO Yupeng,WAN Jing,et al.Improved K-means algorithm based on expectation of density and clustering validity index.Computer Engineering and Applications,2013,49(24):105-111.
黑龙江省自然科学基金(No.F201134);黑龙江省教育厅科学技术研究项目(No.12531120)。
何云斌(1972—),男,博士,教授,研究生导师,主要研究方向:数据库理论与应用、时空数据库、嵌入式系统;肖宇鹏(1986-),男,硕士研究生,主要研究方向:空间数据挖掘;万静(1972—),女,博士,教授,硕导,主要研究方向:数据库理论及应用;李松(1977—),男,博士,副教授,主要研究方向:空间数据库理论及应用。E-mail:hybha@163.com
2013-07-08
2013-08-27
1002-8331(2013)24-0105-07
CNKI出版日期:2013-10-11http://www.cnki.net/kcms/detail/11.2127.TP.20131011.1653.002.html
猜你喜欢
电脑报(2020年12期)2020-06-30
电脑报(2019年4期)2019-09-10
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
少儿美术·书法版(2016年1期)2016-02-06
大众摄影(2015年9期)2015-09-06
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
电子设计工程(2015年6期)2015-02-27
数学年刊A辑(中文版)(2014年4期)2014-10-30
