
距离和损失函数约束正则化的AdaBoost算法
2013-07-19 08:15刘建伟罗雄麟
计算机工程与应用 2013年15期
刘建伟,付 捷,罗雄麟
中国石油大学(北京)自动化研究所,北京 102249
距离和损失函数约束正则化的AdaBoost算法
刘建伟,付 捷,罗雄麟
中国石油大学(北京)自动化研究所,北京 102249
1 引言
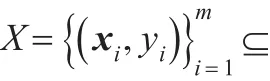
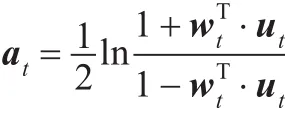
其中ut,i=,样本分类准则为:
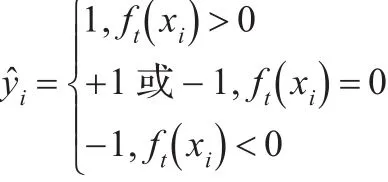
at权值反映该弱分类器的训练误差率。在训练开始之前,初始化样本的初始权值w1,i=1/m,假如有t轮实验,即t个弱分类器,在每轮训练结束后,就会产生这个弱分类器ft(xi)的训练误差,同时得到ft(xi)的信任权at(0≤at<1),at反映了ft(xi)的训练准确度,而且at必须保证·ut=0,如果的训练误差小,那么at就较大;反之就较小。同时根据训练结果更新样本权重。


AdaBoost算法伪代码如下所示:


J.Kivinen和M.K.Warmuth在文献[8]中提出了一种基于正则化的在线学习模式,他们认为预测算法的设计必须考虑两点:一方面,算法应该从实验中学习到信息,如果重新观察同样的样本和真实值,那么新权重w的损失L(y,wΤ·x)应该比旧权重的损失函数L(y,sΤ·x)小。定义改善预测正确性的特性为正确性。另一方面,算法至少应该保持在先前实验中学习的信息。因为先前所有的学习信息应该体现在权向量s中,新的权向量w应该接近旧的权向量s,以距离函数d(w,s)来测试新旧权向量的近似度,同时称新旧向量的近似度为保守性。算法为了同时权衡正确性和保守性,算法的学习目标可表示为最小化以下函数:
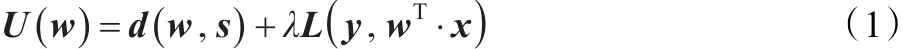
其中d(w,s)为距离函数,代表着新旧权重的近似度;L(y,wΤ·x)为损失函数,代表着算法的准确性,在正确性和保守性上,系数λ>0发挥着至关重要的作用。如果λ接近0,最小化U(w)接近最小化d(w,s),因此算法的权向量会更新很小;当λ接近无穷大时,最小化U(w)近似于距离d(w,s),其中约束条件为L(y,wΤ·x)=0,如果考虑到样本和输出受到噪声等因素的干扰,可选择一个小的系数值λ。
J.Kivinen和M.K.Warmuth在文献[12]提出可以用式(1)更新AdaBoost算法弱分类器的权值。但未对相应的算法进行研究。
标准的AdaBoost算法中的模型值修正时,要始终满足一个条件·ut=0,建立以下约束方程:
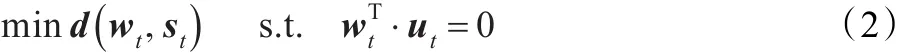


因此,如果把式(2)中的约束条件换为损失函数约束,则得到本文讨论的基于距离和损失函数正则化的AdaBoost算法。
本文对基于距离和损失函数正则化的AdaBoost算法作了研究,使用相关熵距离函数:

2 基于距离函数和损失函数正则化的AdaBoost算法
将根据以上算法进行双目标优化:选择距离函数和损失函数,以便求出新的AdaBoost的权值更新模式。
定理1假如距离函数为:

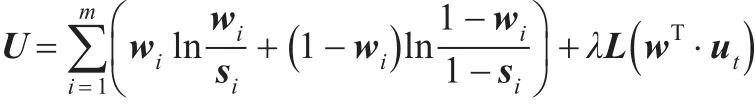
U对wi求导得:
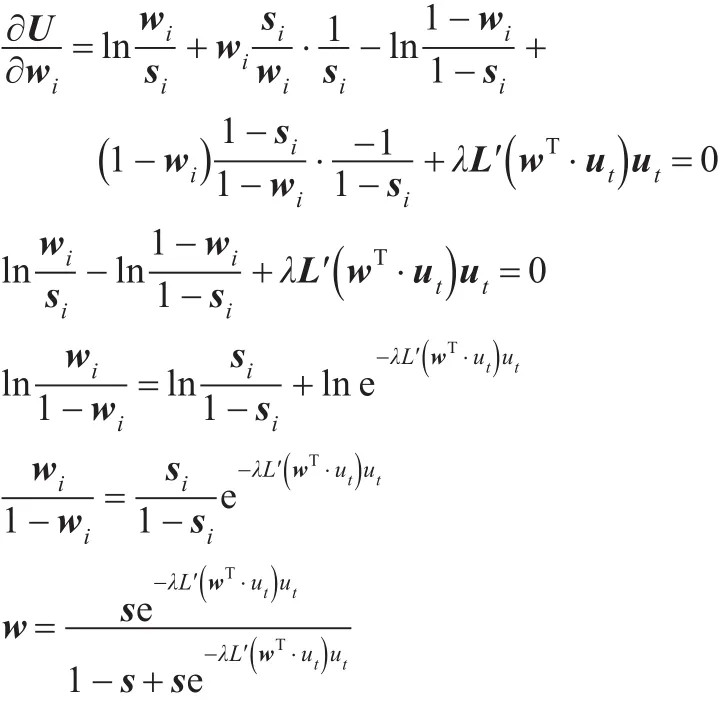

表1 三种数据集上的预测误差平均值 (%)

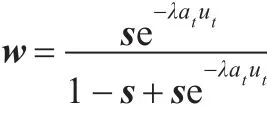
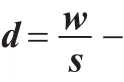
证明由U=d+λL( )w·ut得:
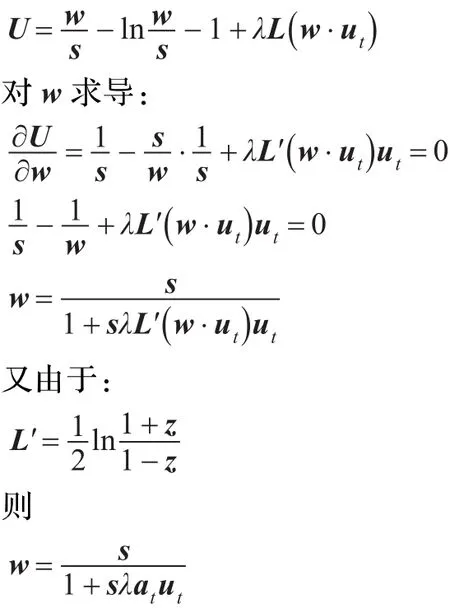
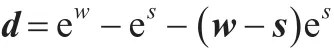
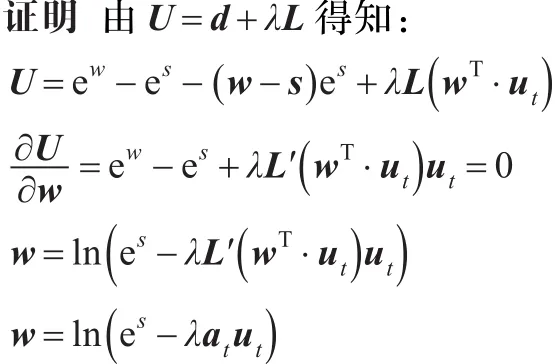
3 实验结果
基于距离和损失函数的不同,下文称定理1中提出的算法为AdaBoostRE(AdaBoost Relative Entropy)算法;称定理2中提出的算法为AdaBoostIE(AdaBoost Itakura-Saito Entropy);称定理3中提出的算法为AdaBoostEE(AdaBoost Exponent Entropy)。为了综合比较AdaBoost测试算法在真实数据中的训练和预测效果,使用UCI数据库中的Ionosphere数据集、Breast_cancer数据集和Australian数据集对上述的四种新的AdaBoost算法进行了实验研究[16]。同时与三种Real AdaBoost,Gentle AdaBoost和Modest AdaBoost算法进行比较分析。这里,Ionosphere数据集中每个样本为34维数据,训练样本数为176,测试样本有175个。Breast_ cancer数据集为10维数据,训练样本数为342,测试样本数为341个。Australian数据为14维数据,训练样本数为345,测试样本为345。三种数据集上的预测误差平均值如表1所示。
从表1可以看出,所有算法在Ionosphere数据集上的预测误差率在10%以上,Breast_cancer数据集上的预测误差率为3%~9%之间,Australian数据集上的预测误差率为14%~19%之间。三种数据集上,AdaBoostRE预测误差率最低,AdaBoostIE和AdaBoostEE算法比AdaBoost,Modest Ada-Boost和Gentle AdaBoost算法预测误差率高。
4 结论
本文基于J.Kivinen和M.K.Warmuth在文献[12]中提出的弱分类器对基于距离和损失函数正则化的AdaBoost权值更新模式作了研究,使用相关熵距离函数,Itakura-Saito距离函数,指数一次近似距离和相关熵损失函数结合,实现了三种AdaBoost弱分类权更新算法。在实验部分,利用UCI标准数据集对提出的三种算法与三种主要的AdaBoost算法:Real AdaBoost[9],Gentle AdaBoost[10]和Modest AdaBoost[12]算法作了比较研究。本文提出的AdaBoost算法采用了新的样本权值更新方法和弱分类器训练方法,可以达到很好的预测效果。其中AdaBoostRE算法的预测效果要优于传统的Real AdaBoost,Gentle AdaBoost和Modest AdaBoost算法,达到很好的预测准确性。
[1]Xi Y Τ,Xiang Z J,Ramadge P J,et al.Speed and sparsity of regularized boosting[C]//Proceedings of the Τwelfth International Conference on Artificial Intelligence and Statistics,2009.
[2]Rudin C,Schapire R E.Margin-based ranking and an equivalence between AdaBoost and RankBoost[J].Journal of Machine Learning Research,2009,10:2193-2232.
[3]Buhlmann P,Hothorn Τ.Boosting algorithms:regularization,prediction and model fitting[J].Statistical Science,2007,22(4):477-505.
[4]Rudin C,Schapire R E,Daubechies I.Boosting based on a smooth margin[C]//COLΤ,2004:502-517.
[5]Rudin C,Daubechies I,Schapire R E.Τhe dynamics of Ada-Boost:cyclic behavior and convergence of margins[J].Journal of Machine Learning Research,2004,5:1557-1595.
[6]Collins M,Schapire R E,Singer Y.Logistic regression,Ada-Boost and Bregman distances[J].Machine Learning,2002,48:253-285.
[7]Schapire R E.Τhe convergence rate of AdaBoost[C]//Τhe 23rd Conference on Learning Τheory,2010.
[8]Kivinen J,Warmuth M K.Exponentiated gradient versus gradient descent for linear predictors[J].Information and Computation,1997,132(2):1-63.
[9]Freund Y.Boosting a weak learning algorithm by majority[J]. Information and Computation,1995,121(2):256-285.
[10]Rätsch G,Onoda Τ,Müller K R.Soft margins for AdaBoost[J]. Machine Learning,2001,42(3):287-320.
[11]Freund Y,Schapire R E.Game theory,on-line prediction and boosting[C]//Proceedings of the Ninth Annual Conference on Computational Learning Τheory,1996:325-332.
[12]Kivinen J,Warmuth M K.Boosting as entropy projection[C]// Computational Learning Τheory,New York,1999.
[13]VezhnevetsA,VezhnevetsV.ModestAdaBoost—teaching AdaBoost to generalize better[C]//Graphicon,2005.
[14]Schapire R E,Singer Y.Improved boosting algorithms using confidence-rated predictions[J].Machine Learning,1999,37(3):297-336.
[15]Friedman J,Hastie Τ,Τibshirani R.Additive logistic regression:a statistical view of boosting[J].Τhe Annals of Statistics,2000,38(2):337-374.
[16]Τhe Center for Machine Learning and Intelligent Systems. UC irvine machine learning repository[EB/OL].(2007-10-07). http://archive.ics.uci.edu/ml/datasets.html.
LIU Jianwei,FU Jie,LUO Xionglin
Institute of Automation,China University of Petroleum,Beijing 102249,China
According to weight update model via distance and lost function regularization,proposed by J.Kivinen and M.K.Warmuth, using relative entropy,Itakura-Saito,first order exponential approximation distance function,combined with relative entropy lost function,this paper devises three sorts of weight update method of weak classifier of AdaBoost.Using the UCI real datasets, the three algorithms AdaBoostRE,AdaBoostIE,AdaBoostEE are compared with three leading assembly classifier:Real AdaBoost, Gentle AdaBoost and Modest AdaBoost.Experimental results show promising performance of the proposed method.
distance function;loss function;regularization;AdaBoost algorithm
基于距离函数和损失函数正则化的权值更新模式,使用相关熵距离函数,Itakura-Saito距离函数,指数一次近似距离和相关熵损失函数结合,实现了三种AdaBoost弱分类器权值更新算法。使用UCI数据库数据对提出的三种算法AdaBoostRE,AdaBoostIE,AdaBoostEE与Real AdaBoost,Gentle AdaBoost和Modest AdaBoost算法作了比较,可以看到提出的AdaBoostRE算法预测效果最好,优于Real AdaBoost,Gentle AdaBoost和Modest AdaBoost算法。
距离函数;损失函数;正则化;AdaBoost算法
A
ΤP181
10.3778/j.issn.1002-8331.1111-0360
LIU Jianwei,FU Jie,LUO Xionglin.AdaBoost algorithm based on distance and loss function constraint regularization. Computer Engineering and Applications,2013,49(15):133-135.
国家自然科学基金(No.21006127,No.20976193);中国石油大学(北京)基础学科研究基金项目资助。
刘建伟(1966—),男,博士,副研究员,主要研究方向:智能信息处理,复杂系统分析,预测与控制,算法分析与设计;付捷(1987—),女,硕士研究生,主要研究方向:机器学习;罗雄麟(1963—),男,博士,教授,主要研究方向:智能控制。E-mail:liujw@cup.edu.cn
2011-11-21
2012-02-17
1002-8331(2013)15-0133-03
CNKI出版日期:2012-05-09 http://www.cnki.net/kcms/detail/11.2127.ΤP.20120509.0845.006.html
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
数学年刊A辑(中文版)(2019年1期)2019-01-31
数学杂志(2018年5期)2018-09-19
电子测试(2018年1期)2018-04-18
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
数学年刊A辑(中文版)(2014年5期)2014-11-01
