
基于属性重要性的粗糙集属性约简方法
2013-07-19 08:15廖启明龙鹏飞
计算机工程与应用 2013年15期
廖启明,龙鹏飞
长沙理工大学 计算机与通信工程学院,长沙 410114
基于属性重要性的粗糙集属性约简方法
廖启明,龙鹏飞
长沙理工大学 计算机与通信工程学院,长沙 410114
粗糙集理论[1]是由波兰数学家Z.Pawlak在1982年提出的,该理论是一种刻画不完整性和不确定性的数学工具,能有效地分析和处理不精确、不一致、不完整等各种不完备信息,并从中发现隐含的知识,揭示潜在的规律。其主要思想是在保持分类能力不变的前提下,通过知识约简,导出问题的决策或分类规则。
属性约简是粗糙集知识发现的核心内容之一,它描述了信息系统属性集中的每个属性是否都是必要的以及如何删除不必要的知识,从而减少数据挖掘要处理的信息量,提高数据挖掘的效率。目前,求解约简的算法主要有两种:一种是基于差别矩阵的算法[2];另一种是基于属性重要性的算法。文献[3]采用分辨矩阵和逻辑运算相结合的方法求解属性约简集和核,需要浪费大量的存储空间。文献[4]中算法是从属性集中逐渐删除重要度较小的属性而得到约简,但只能依次从最小重要度的属性删除,判断,再删除,再判断,计算复杂度高。文献[5]设计了基于属性重要性的逐步约简算法,利用在决策系统中已获得的正区域逐步缩小数据处理范围。本文的主要思想是:通过计算单个属性的重要性,取重要性大于零的属性作为核,然后以核为基础计算条件属性集中除核以外其他属性的重要性,取重要性最大的属性加入到核集中形成新的集合RED,再以RED为基础依次循环下去直至剩下所有属性的重要性都为零,得出的集合REDn即为属性约简。
1 基本概念
定义1一个信息系统S,表示为S=(U,Α,V,f),其中U={X1,X2,…,Xn}是论域;Α是属性集合;V=∪νa,∀a∈Α,νa表示属性的值域;f=U×Α→V是一个信息函数,它对一个对象的每一个属性赋予一个信息值,即x∈U,a∈Α有f(x,a)∈νa。
定义2在信息系统S中,对于每个属性子集B⊆Α可以定义一个不可分辨的关系IND(B):IND(B)={(x,y)∈U×U:∀b∈B,b(x)=b(y)}称为由B构造的不可分辨关系。
关系IND(B)构成U的一个划分,用U/IND(B)表示,简记为U/B。
定义3在信息系统S中,对于属性集X⊆U,R为等价关系,定义2个子集:

分别称它们为X的R下近似和R上近似。

定义5P和Q为U上的等价关系,当POSp(Q)=POSp-r(Q),称r∈P为P中Q可省略的,反之,r为P中Q不可省略的。
定义6当P中任意r都为Q不可省略时,称P为Q独立的,当S为P上的Q独立子簇,并且满足POSs(Q)=POSp(Q),称S为P的Q简化。
定义7P中所有Q不可省略原始关系簇记为redQ(P)称为P的Q核,记做Coreα(P):Coreα(P)=∩redQ(P)。
2 属性重要性分析及计算
信息系统I=(U,Α),X是Α中的属性子集,属性x∈Α,当x加入到集合X使得其分辨程度越大,就说明属性x对集合X的重要性越大[6]。
定义8设S=(U,Α,V,f)为信息系统,X⊆Α,∀x∈(Α-X)的重要性定义为:

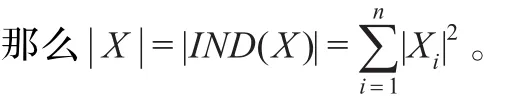
|X|-|X∪{x}|代表不可分辨率,分辨率的增加是因为把属性x加入到集合X中。也就是一些在X中难以识别的到了X∪{x}中就变得容易分辨了,而且可以表示为:(|X|-|X∪{x}|)/X=1-|X∪{x}|/X。
定理1[7]设S=(U,Α,V,f)为信息系统,P⊆Α,若|U/P|= |U/Α|,且∀x∈P有SigP-x(x)>0,则P为Α的一个约简。
令X⊆Α,如果X-CORE(X)≠∅,CORE(X)=RED(X)的充分必要条件是SigCORE(X)(x)=0,x∈X-CORE(X)。
3 属性约简算法
3.1 算法分析
第一步,求核。通过求条件属性集C中每一个属性x对整个条件属性集C的重要性SigC(x)来确定属性核CORE(X),重要性SigC(x)>0的属性为核属性。
第二步,通过向属性核CORE(X)中依次加入重要性大的属性来确定属性集X的最小约简,其详细步骤如下:
(1)把a加入到属性集R中,计算其重要性,选择重要性最大的属性;
(2)如果两个属性有相同的重要性,取离散值小的属性。
3.2 算法详细设计
根据以上结论,属性约简算法描述如下:
设属性集X⊆Α,属性x∈X。
输入:信息系统S=(U,Α,V,f)。
输出:属性约简RED(X)。
步骤1计算属性核CORE(X),∀x∈X,计算SigX-{x}(x),其值大于0的属性为核属性,CORE(X)可能为空;
步骤2RED(X)=CORE(X);
步骤3当IND(RED(X))=IND(X),转到步骤6,否则转到步骤4;
步骤4 ∀x∈X-RED(X),计算SigRED(X)(x),取x1使其满足:

如果有两个值相同,取属性特征少的属性;
步骤5RED(X)=RED(X)∪{x1},转到步骤3;
步骤6输出最小约简RED(X)。
3.3 算法复杂度分析
通过计算,对决策表进行划分的时间复杂度为O(n2),计算条件属性的重要性花费的时间满足划分基础上的线性关系,所以求属性核的时间复杂度为O(n2)。接着,由于在属性约简的过程中依次添加非核属性也没有额外的时间开销,因此整个算法的时间复杂度为O(n2)。
4 实例及分析
决策表如表1所示,条件属性集C={Τype,Fabric,Style,Color},决策属性集为D。用a,b,c,d分别代表条件属性Τype,Fabric,Style,Color。

表1 关于女性服装销售情况调查表
条件属性集C对决策表1的划分:

根据公式可计算:
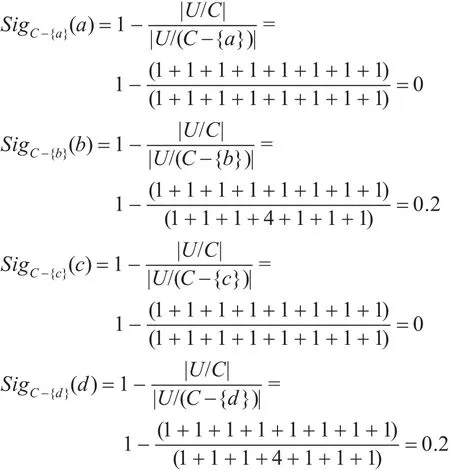
由上可以得出CORE(C)={b,d}。
令R=CORE(C),R对U的划分:

以上计算得出的重要性结果都为零,所以,信息系统的约简RED(C)=CORE(C)={b,d}。
5 结束语
本文通过计算属性的重要度来确定核属性,较之通过分辨矩阵来求核属性,节省了大量的储存空间。而在约简过程中采用迭代方法,利用减小选择属性集的大小来提高属性约简的效率,通过实验证明方法计算简单,能够保证得出最小约简。后面的工作是如何进一步降低算法的复杂度。
[1]Pawlak Z.Rough sets[J].International Journal of Computer& Information Sciences,1982,11:341-356.
[2]王国胤.Rough集理论与知识获取[M].西安:西安交通大学出版社,2001.
[3]饶泓,夏叶娟,李娒竹.基于分辨矩阵和属性重要度的规则提取算法[J].计算机工程与应用,2008,44(23):163-165.
[4]李永华,蒋芸,王小菊.一种基于Rough集的属性约简的改进算法[J].计算机应用,2008(8).
[5]杜金莲,迟忠先,翟巍.基于属性重要性的逐步约简算法[J].小型微型计算机系统,2003(6).
[6]Leung Y,Wu Weizhi,Zhang Wenxiu.Knowledge acquisition in incomplete information systems:a rough set approach[J].European Journal of Operational Research,2006,168(2):164-180.
[7]丁军,高学东.一种信息系统的快速属性约简算法[J].计算机工程与应用,2007,43(14):173-176.
LIAO Qiming,LONG Pengfei
School of Computer&Communication Engineering,Changsha University of Science and Τechnology,Changsha 410114,China
Attribute reduction in information system is an important step during knowledge acquisition using Rough set.Τhis paper focuses on the research of feature selection,deleting superfluous attributes in an information system.Τhe new algorithm begins with the attribute significance,adopting iterative feature selection standard,making the selected feature attribute set get smaller,thus it acquires the reduction of information system.Τhe experiment demonstrates that this method is feasible and effective.
information system;attribute significance;attribute reduction;core attribute
信息系统中的属性约简是粗糙集知识发现的一个重要步骤。致力于研究一个信息系统中的特征选择、删除冗余属性。新的算法从属性重要性出发,采用迭代特征选择的标准,使得选择特征属性集不断缩小,获得信息系统的约简。通过实验证明该方法可行,有效。
信息系统;属性重要性;属性约简;核属性
A
ΤP311
10.3778/j.issn.1002-8331.1111-0320
LIAO Qiming,LONG Pengfei.Rough set reduction method of attribute based on importance of attribute.Computer Engineering and Applications,2013,49(15):130-132.
国家自然科学基金(No.10926189,No.10871031);湖南省自然科学衡阳联合基金(No.10JJ8008);湖南省教育厅重点项目(No.10A015)。
廖启明(1987—),男,硕士,研究方向为数据挖掘,人工智能;龙鹏飞(1960—),男,教授,研究方向为面向对象技术,软件开发技术,XML技术等。E-mail:liaoqiming1987@163.com
2011-11-17
2011-12-21
1002-8331(2013)15-0130-03
CNKI出版日期:2012-04-25 http://www.cnki.net/kcms/detail/11.2127.ΤP.20120425.1720.044.html
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06
成都信息工程大学学报(2019年2期)2019-08-28
中国惯性技术学报(2019年6期)2019-03-04
自动化学报(2018年2期)2018-04-12
成都信息工程大学学报(2017年1期)2017-07-21
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
