
新的文本分类特征选择方法研究
2013-07-11 09:36张玉芳熊忠阳
计算机工程与应用 2013年5期
张玉芳,王 勇,刘 明,熊忠阳
重庆大学 计算机学院,重庆 400044
新的文本分类特征选择方法研究
张玉芳,王 勇,刘 明,熊忠阳
重庆大学 计算机学院,重庆 400044
随着计算机技术和因特网的飞速发展,互联网上的电子文档急剧增加,文本分类成为组织和处理大量文档数据的关键技术。文本分类(Text Categorization)是指依据文本的内容,由计算机根据某种自动分类算法,把文本判分为预先定义好的类别[1],是信息存储、信息检索和信息推送等领域的重要课题。近年来,基于统计理论和机器学习的方法被应用到文本分类中来,取得了较好的效果,但在面向实际应用时文本分类技术仍存在许多挑战[2]。
文本分类可以大致分为数据预处理、文本特征表示、特征降维和训练分类模型4个阶段。在文本分类系统中,文本特征表示通常采用向量空间模型进行描述。然而原始向量空间的特征维数十分巨大,高维的特征集一方面造成文本表示的数据稀疏问题,另一方面也包含了很多噪音特征。这两个问题对文本分类的时间和精确度有着直接的影响,而且许多分类算法在计算上是无法处理这种高维特征向量的。有效的特征选择方法可以降低文本的特征向量维数,去除冗余特征,保留具有较强类别区分能力的特征,从而提高分类的精度和防止过拟合[3]。因此,寻求一种有效的特征选择方法,成为文本分类极为关键的环节。
1 常见的特征选择方法研究
特征选择对于文本分类的特征降维具有较优的效果[4],一直以来它都是文本分类领域研究的热点之一。常用的特征选择方法有文档频率(Document Frequency,DF)、互信息(Mutual Information,MI)、信息增益(Information Gain,IG)、期望交叉熵(Expected Cross Entropy,CE)、X2统计(Chi-square Statistic,CHI)和文本证据权(Weight of Evidence for Text,WET)等。它们是通过构造某种特征评价函数,来统计文本特征空间各维的特征值,将各个特征按其特征值排序,并根据设置的阈值选择出合适规模的特征子集,进而选取出对文本分类贡献较大的特征,以达到降低特征空间维数的目的。YANG Y等人在英文文本分类上的实验表明信息增益,期望交叉熵、CHI和文本证据权较好,而文档频率和互信息稍差[5]。QIU LIQING等人在中文文本分类上的实验表明CHI统计方法和信息增益方法的效果最好,文档频率的性能与它们大致相当,而互信息的性能最差[6]。熊忠阳等人提出CDF特征选择方法,并通过对比实验证明了其方法的有效性和优势[7]。
下面分别介绍几种文本分类中普遍认为较优的特征选择方法:
(1)信息增益(Information Gain,IG)。它表示了某一特征项的存在与否对类别预测的影响。公式如下:
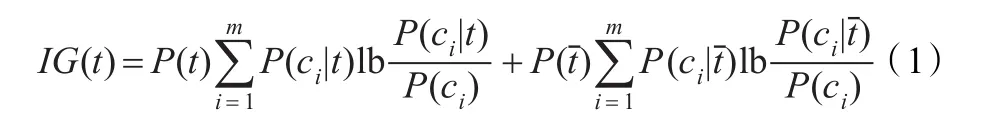
信息增益的不足之处在于它考虑了特征未出现的情况。虽然考虑某个特征不出现的情况也可能对判断文本类别有贡献,但实验表明,这种贡献往往小于其所带来的干扰[6]。
(2)χ2统计量(Chi-square Statistic,CHI)。它度量了特征t和文档类别c之间的相关程度。公式如下:
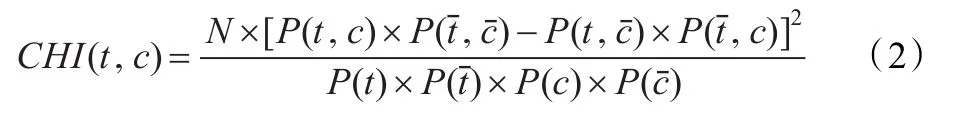
它的不足在于考虑了特征与类别的负相关,可能会选择到在指定类中出现频率较低而普遍存在于其他类的特征,这种特征对分类的贡献不大,应该删除。此外CHI方法是基于卡方分布。如果特征和类别间的这种分布假设被打破,那么该方法倾向于选择低频特征[8]。
(3)文本证据权(WET)。文本证据权比较了在给定某特征的类别出现的条件概率和原类别出现的概率之间的差别。公式如下:

文本证据权倾向于选择与类别强相关的特征,它放大了这类特征对分类的作用,增强了各个特征之间的区分度。
(4)CDF方法[7]。该方法综合考虑特征项的类间集中度、类内分散度和类内平均频度三项指标提出来。公式如下:
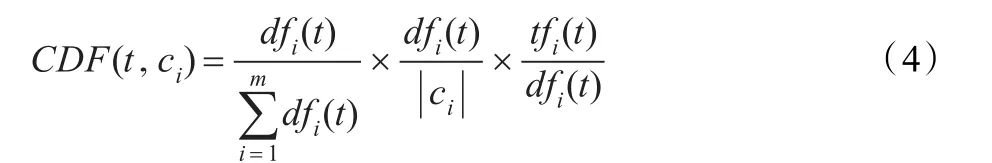
CDF特征选择方法的优点在于:只考虑了特征与文本类别正相关的情况,避免了负相关情况所带来的干扰;类间集中度和类内分散度考虑了特征与类别之间分布的关系;类内平均频度考虑了特征的频度,避免了现有部分特征提取方法倾向于选择稀有特征的问题;计算复杂度小。
2 CR特征选择方法
本文将数据集分为正类和负类,当前类别命名为正类,数据集中当前类别以外的其他类别命名为负类,所有的信息元素如表1所示。
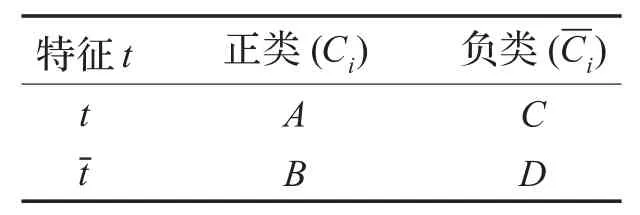
表1 数据集中的信息元素
Ci表示正类,表示负类,负类里面包含了整个数据集中除Ci类别以外的所有类别的文档;A表示正类中包含特征词t的文档频;B表示正类中不包含特征词t的文档频;C表示负类中包含特征词的文档频;D表示负类中不包含特征词t的文档频[9]。
该方法基于以下四条假设:(1)如果特征词在正类的大部分文档中出现,即在正类中分布的越均匀,那么该特征词就具有较强的类别区分能力,越能代表正类;(2)如果包含特征词的文档在正负类间(即整个数据集中)越分散,那么该特征词就具有较小的类别区分能力,更趋向于代表负类而非正类;(3)如果正类的大多数文档均包含特征词,且负类的大多数文档也均包含该特征词,这样的特征词对于正类来说具有较小的类别区分能力,本文把这样的特征叫作鉴别性特征;(4)从词频的角度出发,如果特征词在正类中平均出现的次数越多,而在负类中出现的平均次数越少,那么该特征越能代表正类。
构造基于以上四种假设的评估函数来衡量特征与类别的相关性,得到本文方法的最终公式,表示如下:
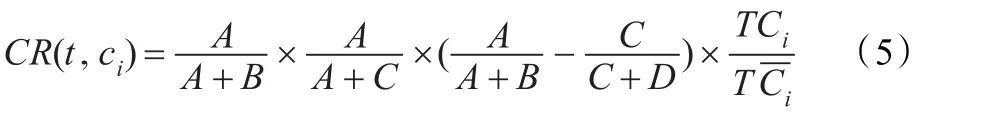
(1)公式的第一部分用正类中包含特征t的文档频在整个正类所有文档中所占比例A/(A+B)来衡量特征项的类别代表能力,该值越大,表示特征t的正类代表能力越强。
(2)公式的第二部分用正类中包含特征t的文档频在整个数据集中包含特征t的文档频的比例A/(A+C)来衡量特征词的类别区分能力,该值越大,表明其类别区分能力越强,越能代表正类。
(3)公式的第三部分A/(A+B)-C/(C+D)表示特征的鉴别能力,值越大,该特征的鉴别性就越强,就越能代表正类。
(4)公式的第四部分用特征项在正-类中出现的平-均词频TCi和在负类中出现的平均词频TCi的比值TCi/TCi来衡量特征的类别的相关性,该值越大表明特征t与正类的相关性越强。
为了在全局特征空间中衡量特征t对分类的贡献,可以按公式(6)计算特征t的分值:

CR特征选择方法的算法如下:
(1)对训练语料库中的文档进行分词、去停用词。
(2)计算每个特征t和类别C的CR(t,ci)。
(3)计算每个类别特征t的分值CRmax(t)。
(4)按照CR值降序排列,选择前M个作为特征空间,其中,M为特征空间的维数。
CR算法的时间复杂度和空间复杂度均为O(V×M)。其中,V表示训练语料经过分词后得到的特征数量,M为特征空间的维数。而V又是由数据集的大小决定的,即文档集越多,V值越大,计算的时间复杂度就越高,因此CR算法时间复杂度与文档集数目成正比;M参数是人为设定的。
由于CR方法的公式构造是基于以上几个比值的,每一部分都可以用条件概率表示,比如A/(A+B)这个指标的每一部分分别除以总的文档数N,就表示成了正类中包含特征t的条件概率,其他三个指标也可以用相同的方法进行表示。因此,本文将该方法命名为综合概率比(Composite Ratio,CR)
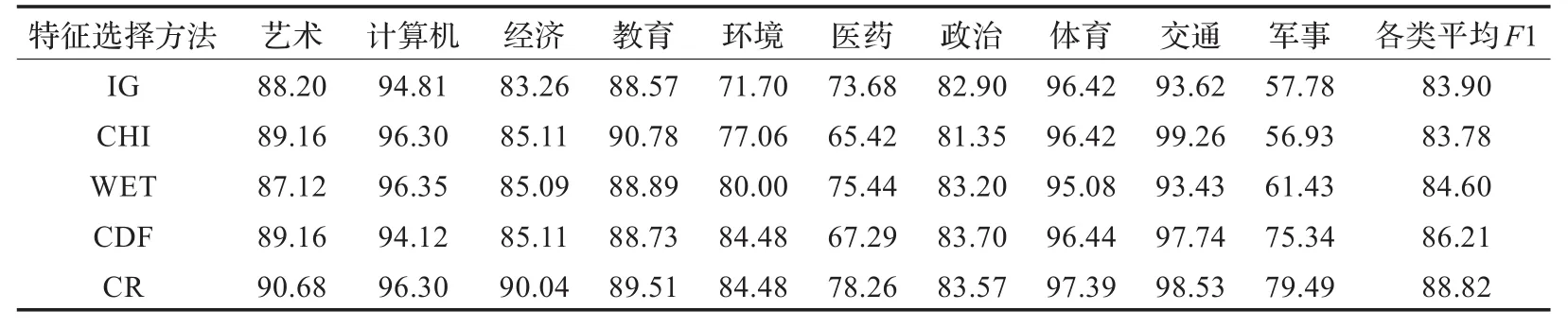
表3 不同特征选择方法取得的分类结果 (%)
3 实验及其分析
3.1 数据集及实验设置
本文所采用的语料库来自复旦大学计算机信息与技术系国际数据库中心自然语言处理小组。该数据集是中文文本分类领域具有代表性并被普遍认可和采用的数据集,不失一般性的同时,比较适合本文提出的基于四条假设的CR方法可行性的验证。文中抽取了10个类别的文档,包括计算机、环境、交通、教育、经济、军事、体育、医药、艺术、政治等,其中1 834篇文档作为训练集,914篇作为测试集。各个类中,训练文档和测试文档的比例在2∶1左右。
实验主要包括三个部分:(1)KNN算法中K值的确定;(2)在维度为1 000维时,将本文的CR方法与传统较好的信息增益(IG)、CHI和文本证据权(WET)以及CDF方法进行实验对比,来验证本文方法的有效性;(3)分别在不同维度下进行CR方法的对比实验,来验证CR方法在不同维度下的分类性能及复杂度。
3.2 KNN算法及其K值的确定
K-最近邻算法(K-Nearest Neighbor,KNN),是基于实例的学习方法,其实现也是基于向量空间模型的。在训练过程中,KNN只是简单地将所有训练样本表示成向量空间上的权重向量并保存。分类时,首先将待分类文本表示成向量空间上的权重向量;然后,将该向量与保存的所有训练样本的权重向量进行计算,计算该文本与每一个样本间的相似度,记录相似度最高的前K个样本;最后,根据这K个最“邻近”的样本的类别属性裁定该文本的类别属性[7]。
KNN算法中K值的选定目前仍没有很好的方法,一般都是先定一个初始值,根据实验测试的结果来调整确定K值。本文先设定特征提取方法为CHI,通过一组实验确定K值,实验结果的好坏用准确率(Accuracy)来衡量。准确率的定义如下所示:

K取不同值的情况下,分类器的总体准确率Accuracy结果如表2所示。
观察表2可以发现,在K值为13时,分类系统的总体准确率最高,达到最佳效果,故本文实验中K值均取13。通过此实验也在此验证了KNN算法中K值对于分类结果会产生一定的影响,K值过大或者过小都将对分类算法的分类结果产生负面的影响。

表2 在不同K值情况下的分类效果
3.3 多种方法的对比实验
维度M为1 000时,将CR方法和其他几种特征选择方法进行对比实验,实验结果如表3、表4所示。
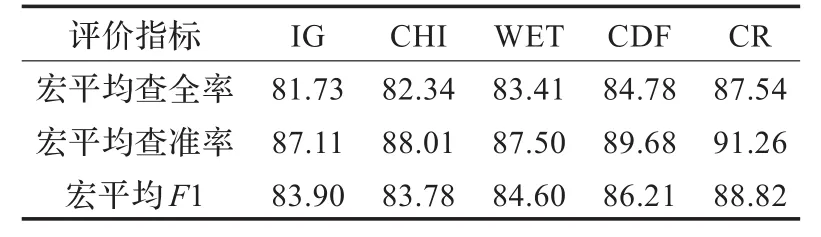
表4 不同特征选择方法的宏平均实验结果比较 (%)
分析以上实验结果发现,综合效果CR方法的最佳,CDF其次,IG最差,本文的CR方法比传统的特征选择方法均有一个明显的提升,效果比CDF方法在经济、医药、军事这三个类别也有一个大幅度的提升。分析原因,CR方法综合考虑特征在正类和负类中的分布,而CDF方法更倾向于选择那些在类别中分布均匀的特征,会忽略一些在正类中平均出现次数不多但在负类中很少出现的这些特征项,但是这类特征往往具有较强的类别区分能力;IG方法考虑了特征不出现的情况,而这种贡献往往小于其所带来的干扰;CHI方法会选择到在指定类中出现频率较低而普遍存在于其他类的特征,这种特征对分类的贡献不大,应该删除;WET倾向于选择与类别强相关的特征,它放大了这类特征对分类的作用,也是忽略了在正类中出现相对不多但在其他类别中很少出现的特征项。
3.4 CR方法在不同维度下的实验对比
为了进一步验证CR方法的性能,本文分别在不同维度下进行实验,综合比较不同维度下的宏平均R、宏平均P、宏平均F1和微平均F1,实验结果如表5所示。同时也列出了CR方法在不同维度下特征选择阶段的耗时,如表6所示。
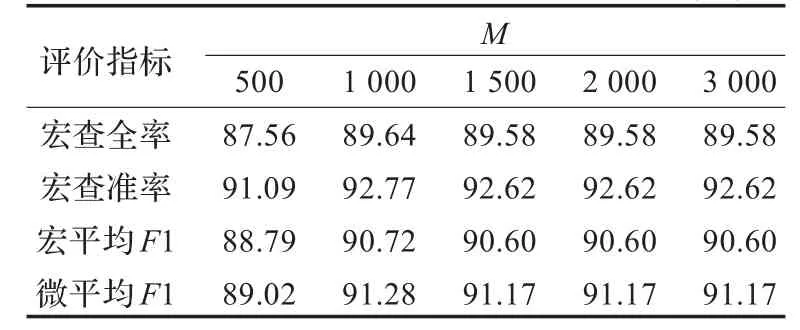
表5 不同维度下CR方法的宏平均比较(%)

表6 不同维度M时CR方法特征选择耗时
观察表5,发现CR方法在维度为500的时候,分类效果相对较低;维度为1 000时分类效果有明显的提升;当维度达到1 500时较1 000维分类效果有微小的降低,但在1 500以后各种评价指标均达到一个相对稳定的值。 这一结果也证明了特征选择维度M的取值也对分类效果有一定的影响。
观察表6,可以看出CR方法在不同维度值M时,特征选择阶段的耗时是随着M的增大耗时大幅度增长。这也足以说明,CR方法的时间复杂度跟特征选择维度M有关,随着M值的增大,时间复杂度也增大。
4 结语
本文通过分析常见的特征选择方法的优缺点,把文本集分成正类和负类,综合考虑特征项在正类和负类中的分布,结合四种衡量特征类别区分能力的指标,构造了CR特征选择方法。经过文本分类系统的实验验证,CR方法的效果要明显优于其他特征选择方法。数据集的不平衡问题已成为文本分类所面临的一大难题,特征选择也是提高不平衡数据集中文本分类效果的重要途径[10]。本文的CR方法在平衡数据集上表现出了较好的性能,不平衡数据集上表现如何,还有待进一步的实验验证。同时,如何在这四项指标中寻找一个平衡点,用一种更为合理的函数表现形式来表达,使该方法的效果达到更优,将是下一步的主要工作。
[1]旺建华.中文文本分类技术研究[D].长春:吉林大学计算机科学与技术学院,2007.
[2]苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,17(9):1848-1860.
[3]Yang Y,Liu X.A re-examination of text categorization methods[C]//Proceedings of 22nd Annual InternationalACM SI-GIR Conference on Research and Development in Information Retrieval.New York:ACM,1999:42-49.
[4]Novovicova J,Malik A.Information theoretic feature selection algorithms for text classification[C]//Proceedings of IEEE International Joint Conference on Neural Networks. Washington:IEEE Computer Society,2005:3272-3277.
[5]Yang Y,Pedersen J Q.A comparative study on feature selection in text categorization[C]//Proceedings of the 14th International Conference on Machine Learning.Nashville:Morgan Kaufmann Publishers,1997:412-420.
[6]Qiu Liqing,Zhao Ruyi,Zhou Gang,et a1.An extensive empirical study of feature selection for text categorization[C]// Proceedingsofthe 7th IEEE/ACIS InternationalConference on Computer and Information Science.Washington,DC:IEEE Computer Society,2008:312-315.
[7]熊忠阳,蒋健,张玉芳.新的CDF文本分类特征提取方法[J].计算机应用,2009,29(7):1755-1757.
[8]申红,吕宝粮,内山将夫,等.文本分类的特征提取方法比较与改进[J].计算机仿真,2006,23(3):222-225.
[9]Lan M,Tan C L,Su J,et al.Supervised and traditional term weighting methods for automatic text categorization[J].IEEE Trans on Pattern Anal and Machine Intel,2009,31(4):721-735.
[10]Wasikowski M,Chen Xuewen.Combating the small sample class imbalance problem using feature selection[J].IEEE Trans on Knowledge and Data Engineering,2010,22(10):1388-1400.
ZHANG Yufang,WANG Yong,LIU Ming,XIONG Zhongyang
College of Computer,Chongqing University,Chongqing 400044,China
Feature reduction is an important part in text categorization.On the basis of existing approaches of feature selection, considering the distribution property of feature between the positive class and negative class,combining four measure indicators for feature with categories distinguishing ability,a new approach named Composite Ratio(CR)for feature selection is proposed. Experiment using K-Nearest Neighbor(KNN)algorithm to examine the effectiveness of CR,the result shows that approach has better performance in dimension reduction.
feature reduction;text categorization;feature selection;Composite Ratio(CR);K-Nearest Neighbor(KNN)algorithm
特征降维是文本分类过程中的一个重要环节。在现有特征选择方法的基础上,综合考虑特征词在正类和负类中的分布性质,综合四种衡量特征类别区分能力的指标,提出了一个新的特征选择方法,即综合比率(CR)方法。实验采用K-最近邻分类算法(KNN)来考查CR方法的有效性,实验结果表明该方法能够取得比现有特征选择方法更优的降维效果。
特征降维;文本分类;特征选择;综合比率;K-最近邻分类算法
A
TP391
10.3778/j.issn.1002-8331.1107-0512
ZHANG Yufang,WANG Yong,LIU Ming,et al.New feature selection approach for text categorization.Computer Engineering and Applications,2013,49(5):132-135.
重庆市科委自然科学基金计划资助项目(No.2007BB2372);中央高校研究生创新基金(No.CDJXS11180013)。
张玉芳(1965—),女,教授,主要研究方向:数据挖掘、网络入侵检测、并行计算;王勇(1986—),男,硕士研究生,主要研究方向:文本分类、自然语言处理;刘明(1986—),男,研究生,主要研究方向:数据挖掘、推荐系统;熊忠阳(1962—),男,博导,主要研究方向:数据挖掘与应用、网格技术、并行计算。E-mail:zonewm@cqu.edu.cn
2011-07-25
2011-09-13
1002-8331(2013)05-0132-04
CNKI出版日期:2011-11-14 http://www.cnki.net/kcms/detail/11.2127.TP.20111114.0939.022.html
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电子制作(2017年23期)2017-02-02
信息安全研究(2016年4期)2016-12-01
西北工业大学学报(2015年4期)2016-01-19
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
振动工程学报(2014年4期)2014-03-01
