
基于主题的文档与代码间关联关系的提取研究
2013-07-11 09:35许冶冰
计算机工程与应用 2013年5期
许冶冰,刘 超
北京航空航天大学 计算机学院,北京 100191
基于主题的文档与代码间关联关系的提取研究
许冶冰,刘 超
北京航空航天大学 计算机学院,北京 100191
1 引言
软件由文档和程序源代码组成。文档中包含着丰富的专业领域知识,包括应用需求、软件设计等方面的要求。这些内容与相应的代码之间存在着不同程度的语义关联,比如某段代码是关于某项需求、某项设计的具体实现或与其实现相关。发现和维护代码与文档间的关联关系(也称可追踪链),对程序理解、需求跟踪、软件维护和复用等许多软件工程活动都能提供很大的帮助[1]。
文献[2]将建立软件文档和代码间可追踪链的方法按照其自动化程度分为三个等级:手动、半自动及全自动,并对这三类方法所花费的代价、各自的复杂度、方法的成熟度及所建立的关联关系的准确度进行了详细的说明和比较。信息检索(Information Retrieval,IR)是目前被广泛使用的一种全自动建立可追踪链的方法,即通过构建信息检索模型来发掘软件文档和代码间的关联关系[1,3-5],如概率模型、向量空间模型(VSM)和潜在语义索引模型(LSI)等。采用信息检索方法的基本思路是将软件文档和代码都作为一般的文本,把源代码作为检索条件,把软件文档作为检索库,进行相应的检索。
近年来,主题模型在自然语言处理中受到了越来越多的关注[6],很多研究者已尝试将主题模型应用到文本的分类、聚类、分割[7]等领域。Latent Dirichlet Allocation(LDA)模型作为主题模型的典型代表,已有学者使用它进行软件可追踪性方面的研究,并且指出LDA模型的性能比信息检索方法中的LSI模型更好[8]。
当前针对中文软件文档和代码间相关性分析的研究较少,且相关研究主要还是采用信息检索的方法,其分析效果有待提高。本文使用LDA模型来进行中文软件文档和代码的相关性分析,研究如何使用主题模型更好地提高软件及代码间语义相关性的提取效果。
2 软件特征分析
2.1 中文软件的混合语言空间
在本文中,中文软件是指其文档和代码中主要使用中文进行说明和定义的软件。在中文软件中,文档的主体是汉字;而代码则主要由英文单词或汉语拼音(或其缩写)书写而成。在中文文档中也会出现各种英文词汇、汉语拼音(或其缩写)等,用于说明领域概念对应的英文术语、标识软件的构成成分(如类名、方法名)等。这些词汇也会用于代码中,即作为命名各类标识符的基本词汇。在代码中,也会出现中文注释和各种中文字符串。因此,软件的中文文档和代码实际上是处于一种包含多种语言的混合型语言空间中。本文为了简化称谓,将该空间中包含的所有词或词组统称为词汇或单词,包括中英文词汇,汉语拼音组成的词汇,以及由字母数字组成的标识符等。
令软件S所处的语言空间为L。为简化问题,不妨将其看作是由汉字词汇组成的中文空间(记作H)和英文词汇(包括汉语拼音词、英文标识符等)组成的扩展的英文空间(记作E)共同构成的双语言空间,记作L。这样的空间可以用其所包含的词汇向量表示,记作:
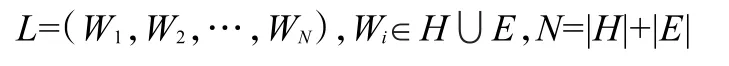
其中|H|和|E|分别表示H和E的规模,即词集中的词汇数量。
对于任何一个文档Di,称L(Di)=(w1,w2,…,wN)为其特征向量,其中wi为词Wi在文档Di中的权重,比如出现次数。同样,对代码Cj,称L(Cj)=(w1,w2,…,wN)为其特征向量,其中wi为词Wi在代码中的权重。
2.2 软件中文文档特征分析
(1)文档中存在数据词典
从关注软件制品之间语义关联性的角度看,这种混合型语言空间增添了不同语言之间的翻译难题。但另一方面,在文档中同时给出一个概念或术语的中英文名称(词汇),也为建立语言间的映射(翻译)关系提供了重要的依据,为准确标识和构建中文文档和代码之间关联关系提供了必要的信息。依据统一、规范的文档撰写要求,文档中的数据词典是关于软件项目中使用的数据元素列表,并包含了对这些元素精确定义,以保证用户和开发人员对所有文档和代码(包括其所包含的输入、输出、存储、计算等)取得共同的理解。数据词典为建立不同语言空间之间的关联性提供了语言间互译的参照系,记作χ(H,E),其含义为:存在E′⊆E和H′⊆H,对于任意的e∈E′,h∈H′,
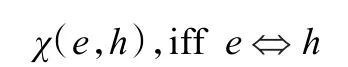
其中,“⇔”表示“可译作”。
事实上,该参照系的完整性和准确性正是评判软件文档质量(特别是可追踪性)的重要依据。
(2)软件文档之间存在依赖关系
软件文档的种类很多,如需求文档、设计文档、测试报告、用户手册等。这些文档之间存在着一种特殊的依赖关系。一般情况下,后产生的文档中所用的术语,其含义应与此前生成的文档中给出的定义保持一致,即可以进一步充实其内涵,但是不应导致歧义。
(3)软件文档具有半结构化的特征
规范的软件文档具有层次化的章节结构。各个章节中分别描述不同层次的内容,或称主题(Topic)。进一步讲,对于任何一个文档Di,都可以被划分为若干个文档段,记作
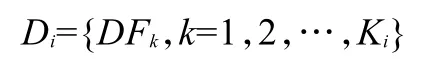
其中DFk是在同一个小节中的一段文本表述,称作文档段,Ki是Di中的文档段总数。与文档的章节结构相对应,这些文档段之间保持着相应的树形结构关系。
2.3 代码特征分析
软件代码中的标识符、常量值(如字符串)、注释,以及文件名和包名等成分为开发者理解程序的语义提供了重要的信息。标识符通常由一个或多个具有特定语义的中英文词(或其缩写)组成,因此,是建立代码与文档之间语义关联关系的重要依据。通过从这些成分中提取词汇,可以定义其在语言空间中的特征向量L(Cj)(见2.1节)。对于上述的代码Cj,它可以是一个代码文件,也可以是一个包或者类,本文中称为代码段。文档段和代码段都是一种文本,因此,统称为文本段。与文档的结构相似,代码的组织方式也具有树形结构,如包、类等。
当一个文档段和一个代码段中都出现同一个或同一组词汇时,意味着两者之间可能存在关联。然而,本文所关注的并不是这种直接的联系,而是试图寻找各个文档段和代码段的主题,并据此揭示彼此之间存在的更深层次的语义关联,即彼此是否都涉及到相同的主题。
2.4 主题
主题反映的是文本所表达的主要含义,其基本思想是:一个文本是由若干个主题随机混合形成的。一个文本通常需要讨论若干主题,而文本中出现的(若干个)特定词汇可以体现出所讨论的特定主题。在统计自然语言处理中,为文本主题建模的方法是视主题为词汇的概率分布,文本为这些主题的随机混合[7]。
3 LDA主题模型
本文中所涉及的模型主要包括:信息检索中的LSI模型和LDA主题模型。由于篇幅原因,关于LSI模型的详细介绍请参考文献[9]。
LDA主题模型是由Blei等人[10]于2003年提出的,它由概率潜在语义索引模型(probabilistic Latent Semantic Indexing,pLSI)发展而来。
3.1 模型介绍
图1是LDA模型的图模型表示[6]。假设有T个主题,D个文本,且第d个文本中含有Nd个词汇。在图1中,φt表示第t个主题的词汇概率分布,它服从Dirichlet分布;θd表示第d个文本的主题概率分布,它同样服从Dirichlet分布。φt和θd又作为多项式分布的参数分别用于生成单词和主题。wd,n和zd,n分别表示第d个文本中第n个词汇及其对应的主题。α和β是Dirichlet分布的参数,通常是固定值且为对称分布,因此用标量表示[6]。
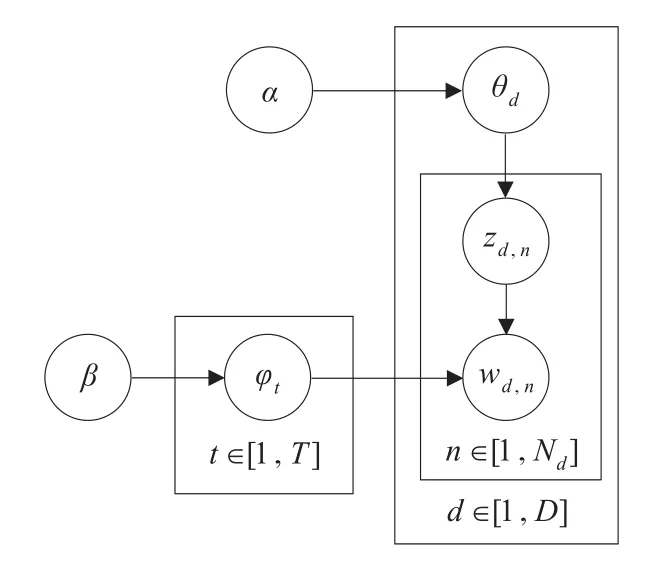
图1 LDA图模型
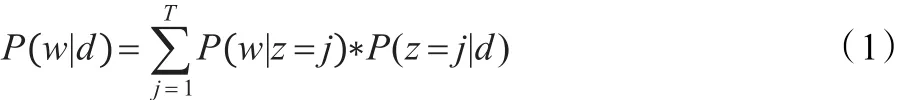
根据LDA模型,在主题总数为T的情况下,文本d中出现某个词汇w的概率可表示为:其中,z是主题变量,P(w|z=j)表示词汇w属于主题j的概率,P(z=j|d)表示主题j属于文本d的概率。
3.2 参数估计
LDA模型有两个参数需要推断:(1)“文本-主题”分布θ;(2)“主题-词汇”分布φ。
常用的参数估计方法有变分贝叶斯推断(Variational Bayesian Inference)[10]、期望传播(Expectation-Propagation)和Collapsed Gibbs Sampling等。
本文选择Gibbs采样方法,其基本思想是,通过对每个单词w的主题z进行采样来确定每个单词所属的主题,这样一来θd和φt的值可以在统计频次后计算出来。由此,问题转换为计算单词序列下主题序列的条件概率,然后进行主题序列的采样,计算公式为:

其中,w表示所有文本中的单词构成的单词向量,z是其对应的主题向量。
Gibbs采用是马尔可夫链蒙特卡洛方法(MCMC)的特例,每次对联合分布的一个分量进行采样,同时保持其他分量不变。推导后获得如下的最终采样公式[6]:
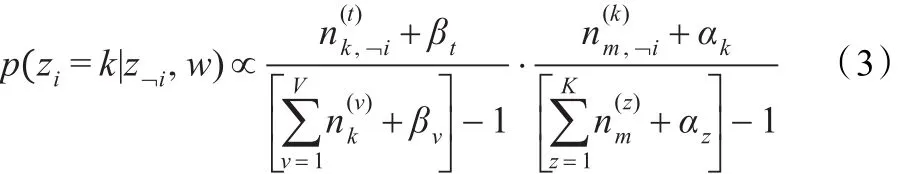
其中,假设wi=t,zi表示第i个单词对应的主题变量,﹁i表示剔除其中的第i项,表示k主题中出现词汇v的次数,βv是词汇v的Dirichlet先验,表示文本m中出现主题z的次数,αz是主题z的Dirichlet先验。
在公式(3)的基础上,通过下式获得对参数的估计:
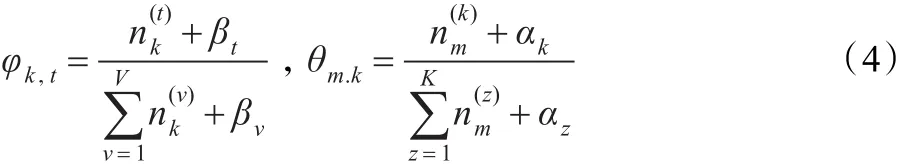
其中,φk,t表示主题k中词汇t的概率,θm.k表示文本m中主题k的概率。
Gibbs所采样的算法使用了期望最大化(EM)思想,算法的详细描述请参考文献[7]。
本文使用Xuan-Hieu Phan和Cam-Tu Nguyen(http:// gibbslda.sourceforge.net/)用Java语言实现的JGibbLDA程序进行与LDA模型相关的分析。
4 关联关系提取流程
本文使用LDA模型进行关联关系提取的流程主要分为三个部分:(1)预处理;(2)LDA执行与相似度计算;(3)结果处理。具体如图2所示。
4.1 预处理
预处理阶段的输入包括中文软件文档及代码两部分。
对于软件文档,首先需要根据文档的章节结构进行分割,将其切分成若干个文档段,保证每个文档段仅属于同一个章节,并保证各文档段的大小近似相等。这样分割一方面有助于聚焦每个文档段的主题,另一方面在一定程度上消除由文档长度差异所导致的相似度计算误差,同时提高关联关系定位的精确度。其次,从中文软件文档中提取词汇时需要进行中文分词的操作,本文使用Lucene的je-analysis组件进行中文分词。随后,对分词后得到的词汇集合需要进行停用词的过滤,滤除掉无意思的词汇,如代词(你、我、他等)、助词(的、得、地等)等。如果中文文档中存在英文词汇,则需要根据词典将其翻译为中文。词典包括通用词典和上述语言间互译参照系χ(H,E)。在进行翻译时优先考虑χ(H,E)。
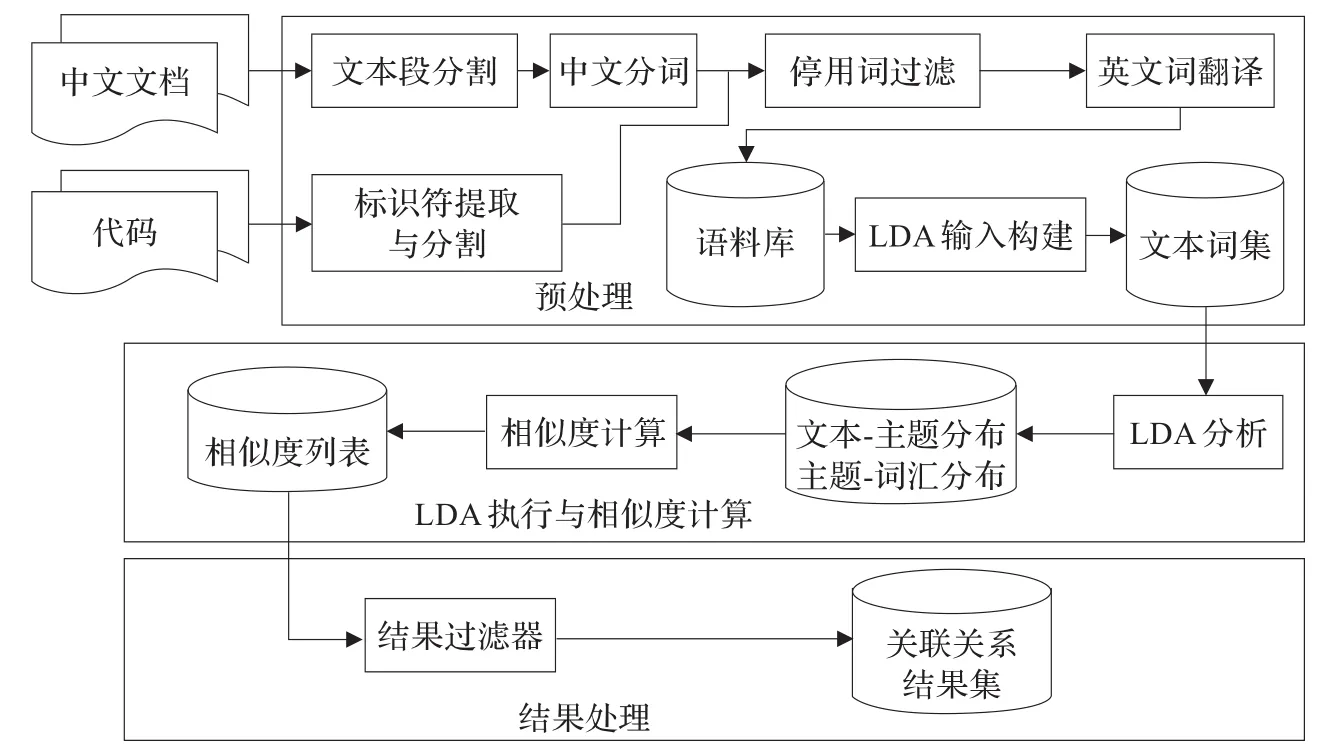
图2 LDA模型处理流程图
对于代码(以Java为例),将每个源程序文件作为一个代码段,是一个类的定义体。首先,从代码中提取出类名、方法名、属性名等标识符以及注释信息等文本成分。对于标识符,按照特定的分隔符(如下划线“_”)和驼峰标记的特点对标识符进行分割。对于注释信息,则使用与文档类似的方法进行分词。然后,对从代码中提取的词集进行停用词过滤和英文词翻译,处理方法与软件文档类似。
经过上述对文档和代码的分别处理,获得了多个文档段(由原始文档切分得到)和代码段,统称为文本段{DFi,i= 1,2,…,M},M为文本段总数。每个文本段用从它里面提取出的一组词汇表示,便可得到如下形式的文本词集:
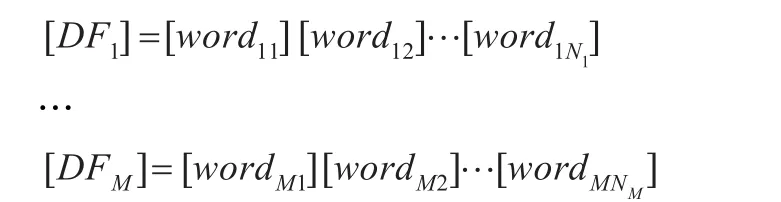
该文本词集中每一行对应一个文本段,每行的内容是该文本段中所包含的词的列表。
4.2 LDA执行与相似度计算
LDA执行与相似度计算阶段的输入是预处理阶段输出的文本词集。本文使用Xuan-Hieu Phan和Cam-Tu Nguyen (http://gibbslda.sourceforge.net/)提供的JGibbLDA程序对文本词集进行处理,原理如第3章所述,其参数估计方法采用Gibbs采样。
LDA分析所需提供的参数包括:α和β的初始值、主题数目、Gibbs采样的迭代次数、保存采样结果的间隔、与主题最相关词的个数等。JGibbLDA程序的输出包括5种文件:(1)LDA模型的输入参数;(2)主题-词汇分布;(3)文本-主题分布;(4)每个文本段中词汇与主题的对应;(5)与每个主题最相关词的列表,词的个数由输入参数决定。
本文利用JGibbLDA程序输出的主题-词汇分布、文本-主题分布等信息来进行代码和文档的相似度计算,具体的计算方法参见本文第5章。经计算获得代码段与文档段之间的相似度列表。
4.3 结果处理
结果处理阶段的输入是LDA执行与相似度计算阶段输出的文档段与代码段之间的相似度列表,列表元素按相似度数值降序排列。由于所分析的文档段、代码段个数一般较多,导致相似度列表的规模较大,为了便于分析和理解,需要按照一定的方法对列表元素进行过滤。常用的过滤方法有以下两种:
(1)Cut-Point法[1,3]:按照相似度的大小提取前k个最相关的关联。如,设k=5,则提取与该代码段最相关的前5个文档段。
(2)阈值法[3]:按照给定的阈值t进行关联关系的提取。如,设t=60%,则将所有相似度大于60%的文档段提取出来。
本文采用Cut-Point方法进行相似度列表的过滤操作。
5 关联关系分析方法
本文使用主题模型进行文档和代码相关性分析的主要目的是通过文档段和代码段所包含的词集发掘其更抽象层次的含义(主题信息),从一个更深入或更综合的角度去分析文档段和代码段之间的语义关联关系。其直观含义是,假定(1)各文档段准确地描述了相应代码段所实现的目标、功能或算法;(2)各代码段中的实现均符合相应的文档段中的说明,且对其实现的目标、功能和算法等亦有清楚准确的注释;(3)这些文档和代码中所涉及的相关概念、术语都是统一和规范的,所有标识符的命名均基于这些概念和术语;那么,存在关联的代码段和文档段将含有相同或相关的主题信息,反之,如果代码段和文档段之间不含有相关的主题信息,则说明它们之间不存在基于主题的语义关联关系。
下面将描述本文如何使用基于LDA方法挖掘出的主题信息来进行相似度的分析。
5.1 主题词分析方法
该方法与使用信息检索模型的方法相似,也是基于词汇进行分析,但这两种方法在选取词汇的策略上有所不同。信息检索模型(VSM、LSI等),主要是基于词频进行词汇的选取,通常采用名为TF-IDF的方法来计算词的权重。这种方法考虑了词频(TF)以及逆文档频率(IDF)的共同影响。
(1)利用LDA分析得到的“文本-主题”分布及“主题-词汇”分布,计算出“文本-词汇”分布。
例如,有D个文本,T个主题,W个词汇,则“文本-主题”分布是一个D×T的矩阵A,“主题-词汇”分布是一个T×W的矩阵B。两个矩阵相乘便可得到一个D×W的矩阵C,这个矩阵C所对应的就是“文本-词汇”分布。其中,矩阵C的每一行对应一个文本段d,每一列对应一个词汇w。矩阵C内第i行第j列的值Cij代表第j个词在第i个文本中的分布概率pij。
(2)由步骤1中得到的“文本-词汇”分布,可以得到一个词汇w在一个文本段d中的分布概率P( ) w|d,然后利用公式(5)计算词汇w在文本段d中的香农信息[11]:
I(w)=-N(w)ln P(w|d) (5)其中,N(w)是词汇w在文本d中出现的频数。香农信息值越大,说明词汇在该文本段中的价值越大。由于P(w|d)≤1,所以I(w)与P(w|d)成反比,而与N(w)成正比,表明只有那些仅在少数文本段中高频次出现的词才是最有价值(即最有可能代表文本段主题)的词。因此,可选择香农信息值较大的前k个词汇来代表该文本段的主题,将这些词汇称为文本段的主题词。
经过上述两步后,不但获得了文本段的主题词,还得到了主题词在文本段中的权值(香农信息值)。所有文本段的主题词构成一个主题词集合,利用它可以构建出新的“文本-词汇”矩阵M,这个矩阵M中的每一行对应一个文本段,每一列对应主题词集合中的一个主题词,其中第i行第j列的元素Mij是第j个主题词在第i个文本段中的香农信息值。获得矩阵M后,可以采用与VSM模型或LSI模型相同的方法进行相似度的计算。
本文采用与LSI模型相同的方法,先对M进行奇异值分解操作,对降维后得到的矩阵M1使用信息检索中最常用的余弦公式计算文档段和代码段间的相似度:
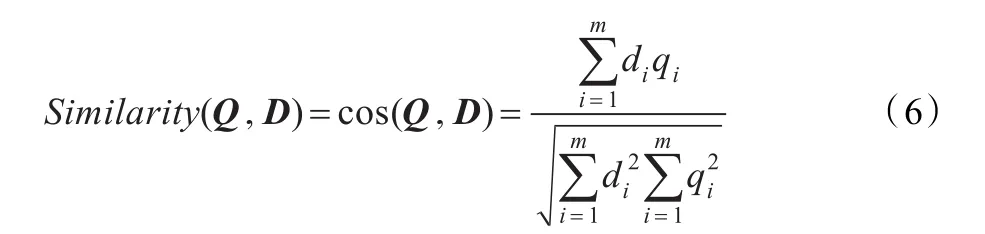
其中,Q=(q1,q2,…,qm)表示某代码段向量,D=(d1,d2,…,dm)表示某文档段向量。
5.2 预处理阶段的改进策略
根据软件文档和代码的特点,同时为了提高工具的分析效果,本文在预处理阶段采取如下的改进措施:
(1)数据词典的识别和提取:数据词典与软件项目有很强的相关性,合理地使用数据词典能够提高对英文词汇的翻译效率。为此,从文档中提取数据词典,构建支持语言间互译的基本参照系,记作χ1(H,E)。
(2)文本描述的采集:为了对代码中的英文词汇进行与文档更相关的翻译,当数据词典中没有包含可用的英文词汇时,则首先尝试从软件文档中查找其对应的中文翻译,失败后再查询通用词典。为此,本文在分析软件文档时,预先在数据库中建立了一个扩展的中英文术语描述参照表,记作χ2(H,E),将文档中出现的英文词汇作为该表的主键,将文本段中包含该英文词汇的中文语句内容作为值保存在表中。采用这种做法是利用在文档中标注中英文对应词汇的习惯作法,即对于文档中的英文词汇,如果存在对应的中文翻译,则该中文翻译一般位于该英文词汇所在的句子中。将邻近范围限制在一句话之内,这样做一方面考虑到上述现象在同一句话的范围内出现的概率较高,另一方面也降低了分析的复杂性。
(3)通用同义词词库的构建,记作χ0(H,E),为中英文翻译提供基础支持。
综上所述,英文词汇的翻译流程如图3所示。
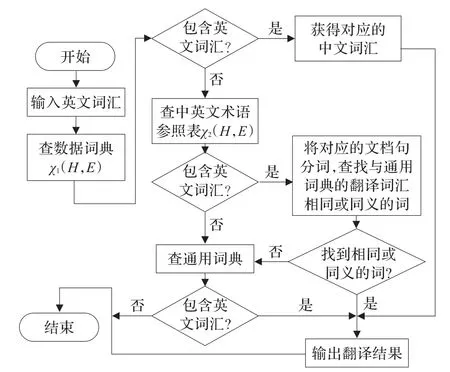
图3 英文词汇翻译流程图
运用本文提出的上述方法,研制的一个软件文档与代码追踪性分析工具,称作QESTA(SoftwareQuality-Software Tracibility Analyzer for documentation and code with LDA)。目前,该工具要求数据词典符合如下的基本格式:(1)数据词典以表格形式定义;(2)表的第一列是中文词汇,第二列是与中文词汇对应的英文词汇。同时,采用哈工大信息检索研究中心语言技术平台中的同义词词林资源[12],建立了一个同义词数据库,用于改进对同义词、多义词的处理,在翻译时将同义词统一为一个词。
6 实验及结果分析
本文使用本课题组为某单位研制的一个实用工具(简称CRATES)作为实验对象。CRATES用于支持其嵌入式软件产品系列的构件化产品线开发方法。CRATES含有15 000行左右的Java代码,124个类文件以及200多页的各类文档。针对CRATES,本文进行了两个实验。
实验一的目的是为了确定LDA主题模型相关参数的取值,供后续实验使用。
在实验二中,本文按文档种类的不同,使用LDA模型和LSI模型对CRATES进行了分析,对比其效果,从而验证LDA主题模型与常规的信息检索模型相比在检索能力和检索精确度上的改进程度。
6.1 实验一
使用LDA主题模型时,需要设定3个参数的值:(1)α;(2)β;(3)主题数目T。根据经验[7],一般令α=50/T,β=0.01。因此,本实验的重点是确定主题数目T的取值。
依据文献[13]中的定理1,首先计算出不同主题数目下主题之间的平均相似度,由此得出主题间平均相似度的变化曲线,用曲线的最低点的T值作为模型最优化的主题数目T0。
在实验中,先对CRATES项目进行预处理,得到其对应的“文本-词项”矩阵。经LDA分析后,得到用于计算主题之间平均相似度的“主题-词汇”分布。该分布中的一行对应一个主题向量,对任意的两个主题向量Zi和Zj,使用公式(6)计算它们之间的夹角余弦值cos(Zi,Zj),即为两者的相似度。则根据文献[13]中的如下公式(7),可以得到主题数目为T时的主题之间的平均相似度avg_cos(T)。
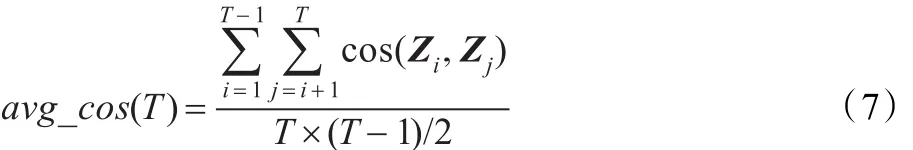
本实验中,LDA模型的主题数目T的取值范围为[50,400],其中每隔25取一次值。按照不同的迭代次数(500和1 000)进行了两次实验,实验结果如图4所示。
从图4中可以看出,当主题数目T为225时,平均相似度曲线达到最低点。根据文献[13]的结论,当主题间平均相似度达到最小时,对应的模型达到最佳性能。因此,后续实验的主题数目T设定为225。
6.2 实验二
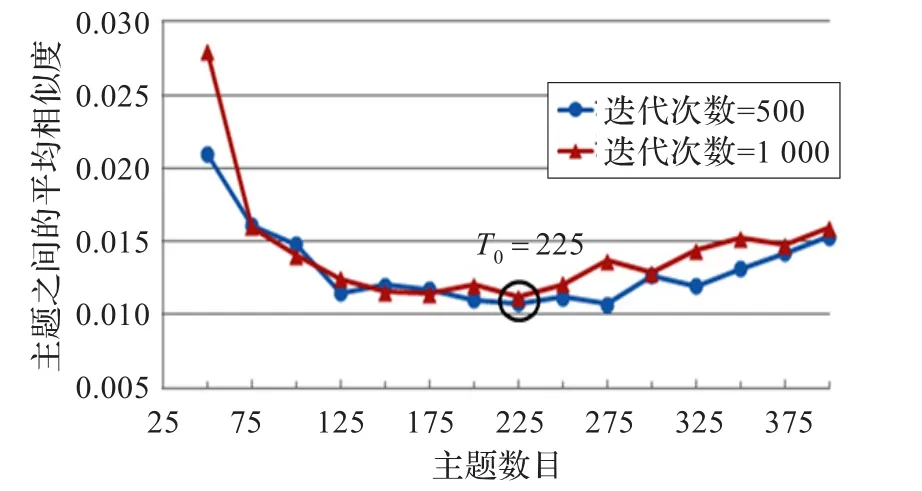
图4 平均相似度曲线
本实验使用两种方法对CRATES项目进行了分析,包括:(1)LDA主题词分析方法(简称主题词方法);(2)基于LSI模型的分析方法(简称LSI方法)。方法2用来与方法1进行对比。
CRATES项目相对较小,缺少单独的需求文档和设计文档。本实验从其研制文档中抽取出19页作为需求文档,抽取61页作为设计文档,并将全部的代码文件作为代码。表1展示了该项目的规模及处理后的情况。经过预处理后,得到27个需求文档段、257个设计文档段和124个代码段。将需求文档、设计文档分别与代码进行相似度计算,可以得到27×124规模的需求-代码相似度计算结果及257× 124规模的设计-代码相似度计算结果。从这两类结果中分别抽取相似度排在前500的关联关系作为样本空间。对设计-代码相似度计算结果,人工分析其样本空间中500个关联关系的正确性,发现其中包含122个正确的关联关系,它们涉及40个代码段和64个设计文档段。对需求-代码相似度计算结果,样本空间的500个关联关系中有63个正确,它们涉及32个代码段和20个需求文档段。在此基础上,本文使用查全率(Recall)和查准率(Precision)[1]来衡量主题词分析方法与LSI方法的分析效果。

表1 CRATES规模概述
在实验中,LDA模型的参数设置如下:主题数目T= 225,α=0.22(50/T),β=0.01,采样迭代次数niter=1 000,每迭代100次保存一次采样结果。
表2总结了用Cut-Point方法对两类文档与代码的相关性分析结果进行筛选后的情况,其中C-P为Cut-Point值,Sum1表示设计文档和代码关联链提取总数量,LDA1表示使用主题词方法分析设计文档与代码的相似度,LSI1表示使用LSI方法分析设计文档与代码的相似度,Corr指当前方法提取出的正确链接数,Reca指查全率,Prec指查准率,Sum2、LDA2、LSI2的含义与Sum1、LDA1、LSI1相似,它们用于需求文档和代码的相似度分析。C-P值从1取到6,即从代码段与(需求或设计)文档段的相似度列表中,分别截取与每个代码段最相关的前1~6个(需求或设计)文档段。图5是使用表2中数据绘制而成的比较图,从图中可以看出:
(1)对于设计文档与代码:从查全率看,主题词方法效果较好,查全率最低为28%、最高为80%,比LSI方法高出约2%到5%。从查准率看,主题词方法的效果仍然较好,其查准率最低为40%、最高为85%,比LSI方法高出约1%到7%。
(2)对于需求文档与代码:除了C-P为2的情况外,主题词方法的查全率、查准率均好于LSI方法,其中查全率高出约1%到16%、查准率高出约3%到7%。但两种方法的查准率均较低(约20%到40%)。
(3)总体上讲,设计文档和代码分析得到的查全、查准率相对于需求文档和代码分析得到的查全、查准率而言均较高。
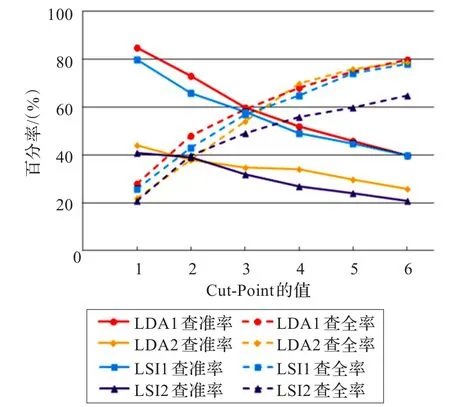
图5 结果比较图
主题词方法效果较好的原因在于,它从主题角度出发对代码和文档进行分析,使用主题模型分析得到的“文本-主题”分布和“主题-词汇”分布来挖掘文本段的主题词,据此分析出文本段间潜在的主题层面的关联。与LSI相比,这种方法更加关注各文本段中与其主题高度相关的一组词,从而排除了大量“次要”甚至于“无关”词汇的干扰。因此,能够比停留在词汇层面的信息检索模型获得更多的正确的关联关系。另外,由于设计文档比需求文档更具体、详细且贴近代码实现,因此设计文档与代码的关联性更强(样本空间中正确的关联关系数目更多)且更易被发现(查全、查准率较高)。
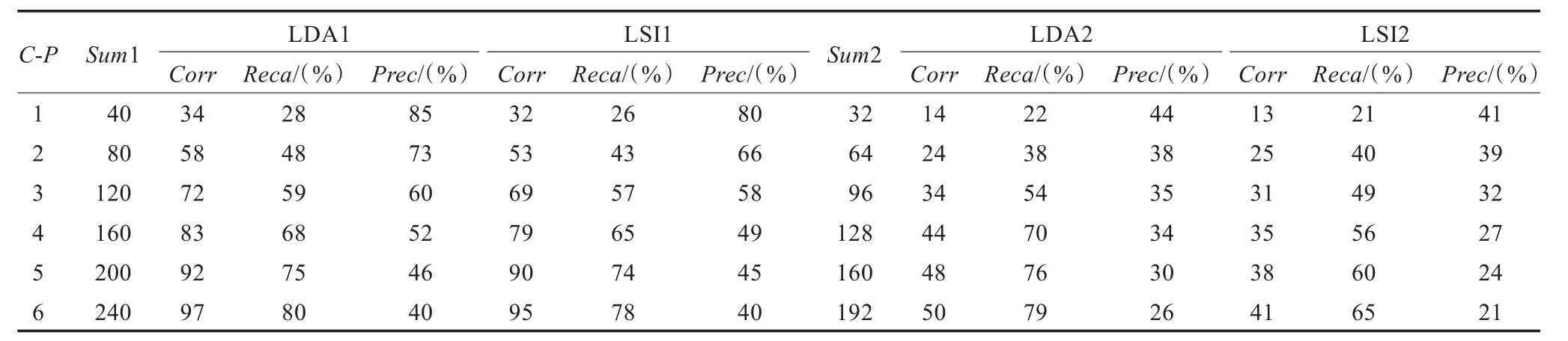
表2 实验结果
7 总结与展望
本文基于LDA主题模型,提出了一种提取中文软件文档与代码之间关联关系的方法,并实现了相应的原型工具QESTA。实验表明,本文提出的主题词分析方法与传统的信息检索LSI模型方法相比,不论对需求文档还是设计文档,在查全率与查准率上均有2%到5%的提高。可见,从主题角度出发去分析和提取中文软件文档与代码之间的关联关系是可行的,并且能够获得比原有的信息检索模型方法更好的效果。
这项研究工作还处于起步阶段。代码中标识符的提取以及英文词汇的合理翻译,主题信息发掘方法的改进,包括各种参数的优化选择等,以及基于文档和代码间的相关性分析和检查其相互之间的可追踪性问题等潜在应用是后续研究的重点。
[1]Antoniol G,Canfora G,Casazza G,et al.Recovering traceability links between code and documentation[J].IEEE Transactions on Software Engineering,2002,28(10):970-983.
[2]Spanoudakis G,Zisman A.Software traceability:a roadmap. handbook of software engineering and knowledge engineering[M].Singapore:World Scientific Publishing,2005:395-428.
[3]Marcus A,Maletic J I.Recovering documentation-to-sourcecode traceability links using latent semantic indexing[C]//Proceedings 25th International Conference on Software Engineering(ICSE'03).USA:[s.n.],2003:125-135.
[4]赖冠辉.代码与文档间关联关系的提取方法研究和改进[D].北京:北京航空航天大学,2009.
[5]韩晓东,王晓博,刘超.中文文档与源代码间关联关系提取方法的研究[J].合肥工业大学学报:自然科学版,2010,33(2):188-192.
[6]徐戈,王厚峰.自然语言处理中主题模型的发展[J].计算机学报,2011,34(8):1423-1436.
[7]石晶,胡明,石鑫,等.基于LDA模型的文本分割[J].计算机学报,2008,31(10):1865-1873.
[8]Asuncion H,Asuncion A,Taylor R.Software traceability with topic modeling[C]//Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering(ICSE'10). Cape Town,South Africa:[s.n.],2010:95-104.
[9]Deerwester S C,Dumais S T,Landauer T K,et al.Indexing by latent semantic analysis[J].Journal of the American Society for Information Science,1990,41(6):391-407.
[10]Blei D,Ng A,Jordan M.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[11]Li H,Yamanishi K.Topic analysis using a finite mixture model[J].Information Processing and Management,2003,39 (4):521-541.
[12]Che Wanxiang,Li Zhenghua,Liu Ting.LTP:a Chinese language technology platform[C]//Proceedings of the 23rd International Conference on Computational Linguistics:Demonstrations(COLING'10).Beijing,China:[s.n.],2010:13-16.
[13]曹娟,张勇东,李锦涛,等.一种基于密度的自适应最优LDA模型选择方法[J].计算机学报,2008,31(10):1780-1787.
XU Yebing,LIU Chao
School of Computer Science and Engineering,Beihang University,Beijing 100191,China
In order to establish traceability between Chinese documentations and source codes more effectively,this paper proposes one method based on LDA model.It names the topic word-based Traceability Retrieval Method(TRM)in which the topic words are extracted according to Shannon information.Experimental result shows that,compared with the LSI method,the topic word method can increase the recall and precision from 2%to 5%.
traceability recovery;topic model;Latent Dirichlet Allocation(LDA);reverse engineering
软件文档及其程序代码之间的关联性或可追踪性分析是软件分析、理解的重要基础。探讨了软件的中文文档和程序代码中蕴含的主题及其相关性。针对软件文档的章节结构和词汇空间,以及程序代码结构、标识符命名空间、注释风格等方面的特点,在LDA模型的基础上提出了一种基于主题词的软件中文文档与代码间关联关系的分析方法。该方法依据词汇的香农信息提取文本段的主题词。实验结果表明,主题词分析方法与LSI模型分析方法相比在查全率和查准率上均有2%到5%的提高。
可追踪链;主题模型;隐含狄利克雷分配(LDA);逆向工程
A
TP311.5
10.3778/j.issn.1002-8331.1208-0521
XU Yebing,LIU Chao.Research on retrieval methods for traceability between Chinese documentation and source code based on LDA.Computer Engineering and Applications,2013,49(5):70-76.
许冶冰(1987—),男,硕士,主要研究领域为软件工程、信息检索;刘超(1958—),男,教授,博士生导师,主要研究领域为软件工程、软件测试。E-mail:xyb0618@126.com
2012-09-07
2012-10-16
1002-8331(2013)05-0070-07
CNKI出版日期:2012-10-31 http://www.cnki.net/kcms/detail/11.2127.TP.20121031.1000.019.html
分析方法旨在基于LDA模型分析获得主题相关信息,据此计算出能代表文本主题的词汇,使用这些词汇来构成文本的词集。具体过程如下:
◎网络、通信、安全◎
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
信息安全研究(2016年4期)2016-12-01
西北工业大学学报(2015年1期)2015-02-22
西北工业大学学报(2015年1期)2015-02-22
