
基于文件拆分和缓存预测的日志文件传输算法*
2013-06-01 11:00:27马赛牧王晶
电信工程技术与标准化 2013年8期
马赛牧王晶
(1 北京邮电大学网络与交换技术国家重点实验室,北京 100876; 2 东信北邮信息技术有限公司,北京 100191)
基于文件拆分和缓存预测的日志文件传输算法*
马赛牧1,2王晶1,2
(1 北京邮电大学网络与交换技术国家重点实验室,北京 100876; 2 东信北邮信息技术有限公司,北京 100191)
当今的云计算平台和大型网站在运行时都会产生大量的日志文件,这些日志文件一般都具有收集分析的价值,所以在日志文件的收集过程中就出现了大日志文件的传输问题。本文要解决的问题就是如何使日志文件能够快速的传输到接收端。为此本文在研究了当前已经有的大数据传输办法之后,针对日志文件提出了与传输协议无关的新算法:文件拆分和预测算法。该算法主要由两部分组成:首先对日志文件进行拆分,拆分成包含描述性信息的文件和包含数据的文件,消除了文件中的冗余信息;然后在传输过程中通过预测接收端缓存的数据来达到消除传输过程中的冗余信息的目的。经过实验检验,本文设计的算法能够将实际传输的数据量降低90%以上。
文件传输;fingerprint;消除冗余;云计算
各个互联网平台在正常工作时都会产生大量的运行日志,尤其是大型的开放云平台和电子商务网站,云平台的管理者一般都要收集备份这些日志以备监控平台运行情况,以及分析用户行为。大量的日志不仅占用很多存储空间,而且更重要的是在传输这些文件时非常的低效,很多平台和网站需要周期性的将日志文件通过网络传输备份到数据中心。在这个过程中,如何在现有带宽条件下提高数据传输效率就成为了一个需要解决的问题。
目前业内在大数据传输方面已经做了一些工作。Zohar等人[1]实现了一种数据接收端驱动的传输模式,接收端通过预测传输文件的下一段数据来减少网络上的数据传输量,文献[2]是在骨干网上通过选择传输路径来实现大文件的传输,主要适用于有多个存储转发节点的网络,通过对网络建模可以使用最大流[3]的算法来进行传输,文献[4]是通过检测网络缓存中数据的相似性来消除网络传输的冗余。
上述文献中的方法都更侧重所传输数据的通用性,在日志文件的传输方面,由于日志文件的特殊性,比如其日志文件格式相对统一固定,因此在使用上述文章中方法传输日志文件时,都拥有进一步优化的空间。文献[2]是在提高带宽利用率做出了贡献,但并不能减少传输量和消除传输冗余。文献[1]主要的使用场景是接收端已经拥有部分的数据,通过预测来避免发送方发送接收方已经拥有的数据,但是如果接收方并没有任何数据时,还是需要按照传统方式发送数据。文献[4]用于网络中的缓存节点,需要保证两个缓存节点都有相同的数据,而且对于每一个数据分组都需要一次确认是否已经存在的过程。
日志文件主要是起到一个记录的作用,记录系统运行情况,记录用户信息,因而这些文件一般都由两部分构成:描述性信息和数据,数据是日志文件中包含真实价值的信息,比如电信短信业务平台中,对一条发送成功的信息,日志记录下的它的短信ID、下发时间、接收号码等,描述性信息则是用来描述清楚这些数据代表的真实含义的解释信息,它对于产生日志的系统来说是无意义的,但是对于需要查阅日志的系统管理者却是很重要的。日志文件由机器自动生成,所以它其中的描述性信息通常都是事先设定好的内容固定的文字,这些文字随着时间的推移不断生成并被写入到文件中,这使得最后生成的日志文件中有很大一部分信息是重复不变的。这样的文件在进行传输时,为了提高传输效率,应该将文件拆分成描述信息文件和数据文件,对描述信息文件要进行压缩处理,消除其中的冗余信息。
本文在拆分日志文件时,采用文献[5]的方法将字符转化为数字,通过对数字的处理识别出文件中的描述性信息,然后将日志文件进行拆分,把数据部分提取出来,对剩下的描述性信息进行压缩处理,这样就可以最大限度的压缩日志文件的大小。同时在传输时采用预测的策略,对于文件接收方已经拥有的描述性信息不再传输,减少描述性信息在系统中的传输量。
这种处理方式使传输独立于底层的协议,可以适用于任何传输系统之中。
本文在第1章介绍了数据传输方面已经进行的相关工作成果,在第2章介绍了本文所介绍的算法的核心思想,包括文件拆分算法和传输过程中的冗余消除算法,第3章就算法进行了实际运行测验,将测验结果汇聚成表格,并对实验结果进行了分析,第4章对本文进行了总结,并阐述了不足之处和未来可能的工作重点。
1 相关工作
在大文件传输方面,现在已经有了比较多的研究成果,文献[1]实现了一种数据接收端驱动的传输模式,接收端通过预测传输文件的下一段数据来减少网络上的数据传输量。
文献[2]是在骨干网上通过选择传输路径来实现大文件的传输,主要适用于有多个存储转发节点的网络,通过对网络建模可以使用最大流[3]的算法来进行传输。
文献[4]是通过检测网络缓存中数据的相似性来消除网络传输的冗余,它利用了文献[5]中的方法来处理数据信息。
文献[6][7]研究了实时传输中的冗余问题,这些文章所采用的方法都是对传输的过程进行了冗余消除,但是对于待传输的数据并没有进行预先的处理,这就使得它们的冗余检测和消除都无法完全彻底的消除冗余。
2 文件拆分和预测算法
各类平台和网站在运行时都会生成大量的运行日志,其中都包含着珍贵的信息需要进行备份以便处理分析,在这个过程中不可避免的要面对传输这些大文件的问题。目前对于大数据的传输已经有了一些工作,文献[4] [1]都对于传输中冗余的数据进行了消除工作。
本文主要研究日志文件的传输效率问题,算法设计主要包括两部分,第一部分是文件拆分算法,用来将要传输的文件进行拆分,拆分成数据文件和描述性信息文件,第二部分是传输过程中的冗余消除算法,目的是消除传输过程中的冗余,确保链路上传输尽可能少的数据。
2.1 文件拆分算法
日志文件是系统在运行时自动生成的用来描述系统工作状态或记录用户使用系统情况的说明性文件,日志文件一般由数据和描述性信息构成,其中数据是日志文件记录的目标信息,而为了使文件便于管理人员查阅和分析,文件中就必须要包含描述性信息,这些信息主要用来解释说明日志中数据的含义。因为文件是由系统自动生成,所以文件中会包含大量重复的描述性信息,我们称之为冗余信息。对文件的压缩主要目的是将文件中这些冗余信息都抽取出来压缩成一个没有冗余信息的描述文件,然后将原日志文件剩下部分组成数据文件,将传输的文件压缩成数据文件和描述文件,从而也减少了传输量并且消除传输冗余。
为了找到日志文件中重复出现的冗余描述性信息,我们需要检索整个日志文件并准确的发现哪些字符串是我们要找到冗余内容。直接基于文件内容的查找会涉及大量字符串的操作,这将使问题复杂化,并分散我们对文件压缩的注意力,因此我们使用fingerprints来对文件进行一次预处理。
2.2 Fingerprints
Fingerprint是一个可以代表一段字符串的整数,它是通过对所要代表的字符串计算得到的,一个优秀的计算方式计算得到的fingerprint应该是可以唯一的标识一段字符串。而fingerprints就是一个fingerprint的集合,这个集合代表了一组字符串,它把字符串问题转化成了整数问题,运用同样的办法,日志文件也可以被转换成一个整数集合,这样就能够绕开所有的字符串处理问题,运用相对简单的数字查找方式完成字符串处理工作。
Rabin提出利用“fingerprints”处理文件来防止文件被随意篡改[8]。为了得到一个能够标识整个文件的fingerprints集合,需要对文件中每一行的每一个β长度的字符串都获取到它的fingerprint。
用t1t2… tβ来表示一段字符串,则这段字符串的第一个β位长度的子字符串的fingerprint为:

其中,p和M为常数,这样在计算Fi时就可以使用:

p一般选择素数,而M选择2的n次幂(n为正整数),为了快速计算,可以计算出所有ASCII码中字符的t×pβ的值并存储在一个表中,这样计算Fi只需要一次加法运算、一次减法运算还有一次乘法运算。
2.2.1 查找冗余信息
利用fingerprint就可以将日志文件转化成整数的集合,对于要压缩的日志文件file_log,读取文件中每一段βbit度的子字符串按照。利用上述公式(1)计算出它的fingerprint,这个fingerprint即代表了这段字符串。例如对t1t2… tβtβ+1于这样一个字符串,按照每β个字符串计算一个fingerprint,会生成两个fingerprint整数:F1和F2,其中F1代表了字符串t1t2… tβ,而F_2代表了字符串t2… tβtβ+1。这样file_ log文件中的一段字符串t1t2… tγ就能够被表示成一个数列F1,F2,…,Fα,我们规定如果γ<β则在计算时在tγ后面补0。一段字符串t1t2…tγ在日志文件如果是冗余信息,则数列F1,F2,…,Fα也会被多次生成,我们把字符串t1t2…tγ叫做冗余句子,把冗余句子对应数列F1,F2,…,Fα叫做冗余数列。
这样就把查找file_log文件中冗余句子的问题转化为数列中查找每个数字出现频率的问题了。我们利用文献[9]中统计常见搭配的办法来通过统计找到冗余信息。例如短信开放平台在接收到一条短信之后,可能对产生这样的日志:
Platform receives a short message from 139aaaabbbb to 10086 at 2013-01-01-01:02:03,message id is 2cadd3e1f70643bd8b7af60825c51573.
如果短信开放平台每天接收到大量的这种短信时,就会产生同样多的这样的日志记录。在这种记录中,很明显“Platform receives a short message from to at, message id is.”这样的描述性信息是会重复出现的,也就是冗余信息。而2cadd3e1f70643bd8b7af 60825c51573、139aaaabbbb、10086、2013-01-01-01:02:03则是有价值的数据。冗余信息中的单词的搭配是比较固定的,只是词汇以固定的格式反复出现,而数据和描述性信息的搭配则是不固定的,在日志文件中,搭配出现的次数也不多。在对上面的日志例句进行分析时,我们定义一个搭配窗口来识别描述性信息,搭配窗口内的一个词的左右有4个词,把窗口中每个词对都作为候选的搭配对,如图1所示。然后在整个日志文件中通过计算搭配对出现的频率,就可以知道哪些是描述性信息了。

图1 查找文件中的描述性信息
计算频率是一个基本的数据结构问题,可以有多种解决方法,本文利用哈希表进行处理。
下面是查找冗余信息的伪代码。
Translation(){
while(run){
str = readFileLine();
fingerPrints = getFingerPrinters(str);
//fingerPrints同时也携带表示其在文中位置的指针
putInHashMap(fingerPrints);
}
}
Statistic(){
fingerPrint = getFromHashMap();
if(fingerPrint在HashMap中出现超过两次){
//将这些相同的fingerPrint合并,包括他们的指针newFingerPrint = merge(fingerPrint);
putInStatisticHashMap(newFingerPrint);
}
}
Compress(){
//得到一组fingerPrint的集合fingerPrints fingerPrints = getFromStatisticHashMap();if(fingerPrints是代表一段字符串的数列){
//这段字符串是冗余信息
putInRedundantHashMap(fingerPrints , 指针信息);
}
}
如上面的伪代码所示,Translation()将日志文件中的所有字符串通过计算转成了fingerprint数字,每个β长度的字符串利用公式(1)生成一个整数F。同时,为了能够找到数字对应的字符串在日志文件中的位置,对每一个F还要携带一个指针指向对应字符串在文件中的位置。Statistic()按照字符串的顺序排列所有生成的fingerprint,然后统计所有fingerprint重复的次数,记录下重复次数大于2的fingerprint。在完成统计工作后,哈希表中已经存放着所有代表冗余句子的fingerprint以及它所携带的指针。在很多情况下,冗余句子的长度大于计算fingerprint所用的字符串长度,所以在统计fingerprint时不能只计算单个的fingerprint,而是要记录下代表这种长冗余句子的fingerprint数列,这也就是Compress()的主要工作,Compress()主要根据fingerprint所携带的指针来判断哪些fingerprint是连续的,然后将它们合并,连同其指针信息一起保存到RedundantHashMap哈希表中,这样就可以找到每一个代表长冗余句子的数列。
在经过了上述步骤之后,RedundantHashMap哈希表中保存的就是所有代表日志文件中冗余句子的数列,以及这些冗余句子在日志文件中所在的位置。
2.2.2 消除冗余信息
经过查找冗余信息的处理,在哈希表中保存着记录日志文件file_log冗余信息的数据,消除冗余信息主要是根据这些数据将日志文件file_log拆分成两个新的文件:存放描述性信息的文件file_description和存放数据的文件file_data。
生成的新文件file_description中存放的是冗余句子,这些句子通常都是描述性信息。为了标记这些句子在原日志文件中的位置,每一个冗余句子还要携带指向其在原文件file_log中所有出现位置的指针集合{location_Id};日志文件file_log去除掉所有冗余句子的剩余内容记录在file_data中。
拆分的伪码如下所示。
Split (){
fingerPrints = getRedundantHashMap ();
//根据fingerPrints携带的指针将中的冗余信息抽取出来
//写入到file_description中的,同时将指针信息也写入进去;
file_description = abstractFile(file_log, fingerPrints);
//将剩下的数据写入到file_data文件中;
file_data = createDataFile(file_log, fingerPrints);
}
2.3 传输过程中的冗余消除
在理想的情况下,被传输的日志文件应该只包含有数据部分,这样传输数据的信息量才是100%,但在实际中显然是无法达到这个目标的,所以就应该使数据部分在传输总量中占得比重尽可能的大。
这样就需要减少描述性信息文件file_description在传输总量中所占的比重,为此我们采用预测的方式减少file_description文件中的数据量。
因为描述信息是机器重复生成的,并不会随着时间而发生改变,所以文件的接收端通常已经拥有相当充足的描述性信息,对于这些已经存在于接收端的部分,发送端不会进行传输。由于file_description文件中的描述信息是通过fingerprint查找得到的,所以发送端依然可以利用fingerprint进行预测。
在生成file_description文件之后,描述性信息的fingerprints都保存在哈希表之中,发送端在传输文件之前,首先将哈希表中描述性信息的fingerprints生成文件file_description_fingerprints发送给接收端,接收端会对接收到的fingerprints与自己缓存中的描述性信息的fingerprints进行对比,将没有缓存的fingerprints发回给发送方,而对已经有缓存的fingerprints不再回应。需要说明的是,为了减少网络开销,发送端并不需要发送全部的fingerprints,而只是选择一些有代表性的fingerprints生成文件并发送给接收端。
发送方收到接收方对于预测的回应之后就可以知道哪些描述性信息已经不再需要发送。
图2说明了每次预测的流程。

图2 预测的流程图
2.4 文件的拆解和合并
为了文件能在接收端顺利合并,在文件拆分时在file_description中同时保存了指针。每一条描述性信息的指针指向其在file_data文件中的位置,在接收端进行文件合并时,将描述性信息填入指向的文件中位置即可。
在消除传输过程中的冗余时,对于接收端已经有的描述性信息会依然保存它的指针信息,在接收端接收完成后,用接收端缓存的描述性信息和指针信息来回填file_data文件。
3 实验
为了验证算法的有效性,我们使用EBUPT公司移动云平台运行时产生的日志文件进行测试,测试使用的计算机CPU为Intel(R) Core(TM)2 Duo CPU E7500 @2.93 GHz,内存为1236 MB,测试的步骤如下:首先测试文件拆分算法对于日志文件冗余的处理程度以及对于文件的压缩程度;然后测试文件传输时冗余消除的程度,因为对于file_description文件中在接收端已经缓存部分已经不再需要传输,所以要测试实际传输的数据量。
3.1 测试文件拆分算法
分别选取大小为2 MB、16 MB、80 MB的日志文件进行处理,进行拆分后的详细情况如表1所示。
从表1可以看出,文件拆分算法不仅将原来的日志文件进行了拆分,还大大压缩了文件的大小,其中file_ description文件的大小远大于file_data文件,这是因为我们选取的日志是移动云平台记录客户端与平台连接情况的日志,日志中有效数据的含量相对很少。原文件大小为2.07 MB和80.4 MB的文件其大小比例为1:38.84,而其对应的file_description文件的大小分别为204 KB和250 KB,大小比为1:1.23,这说明80.4 MB的文件中有很大的冗余信息,而拆分成file_ description之后,冗余信息都被表示文中位置信息的指针所代替。
3.2 测试文件传输时的冗余消除
在传输文件的时候,还需要进一步消除传输冗余,为此需要计算出file_description的fingerprints并记录到文件file_description_ fingerprints中,将file_description_ fingerprints先发送到接收端进行比对,接收端将需要发送的文件部分的指针信息发送回来,发送端在根据此反馈信息发送消息。
所以,此处主要测试在这种前期的预测中数据的发送量。依然选取测试文件拆分算法时的日志样本,测试显示出了最佳预测结果和最坏预测结果:在最佳预测的情况下,file_description文件中的数据在接收端都已经有缓存,接收端只会给发送端发送消息体为空的应答消息;在最坏预测的情况下,file_description文件中的数据在接收端没有任何缓存,接收端会把需要发送的文件部分的指针信息发送回给发送端。最佳和最坏情况下预测耗用的数据传输量如表2和表3所示。在表4中,在最佳预测的情况之下,原本表1中拆分后文件只需要更少的数据就能够成功发送,例如204.21 KB的文件只需要33.21 KB就可以成功发送,预测使传输量减少到16.26%。只有在最坏情况之下,如表5所示,file_description文件才需要全部发送出去,这种情况下预测将使传输量大于没有预测时的传输量。
表4和表5测试数据表示的是在预测的最佳情况和最坏情况下总共发送的数据量,包括前期预测时的数据量、预测后实际发送的file_description大小以及file_ data的大小。
由表6可以看出,在最好和最坏的情况下,本文所使用的算法策略都减少了文件的实际发送量,在最佳预测情况下可以比原文件少发送99.83%的数据,在最坏预测情况下也可以少发送99.15%的数据。

表1 文件拆分后大小

表2 文件预测在最佳情况下传输数据量
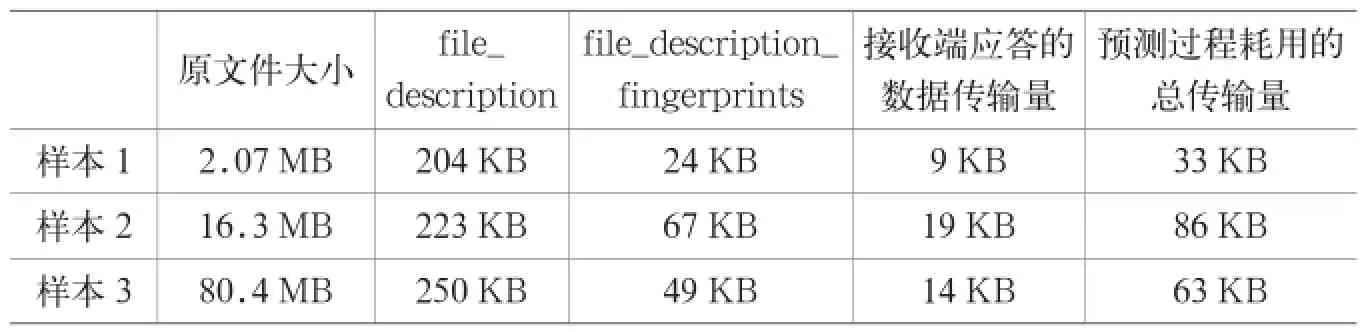
表3 文件预测在最坏情况下传输数据量

表4 最佳预测情况下系统数据总传输量及预测收益

表5 最坏预测情况下系统数据总传输量及预测收益

表6 本文采用的算法策略对消除冗余的效果
4 总结
本文旨在解决大数据传输领域的日志文件传输问题,通过对日志文件的收集和分析,我们发现日志一般由两种数据构成,一种是真实的数据,还有一部分是对数据进行解释描述作用的描述性信息,而描述性信息通常是内容固定且有冗余的,基于此理论,本文提出一种传输策略,一共有4个步骤:首先对文件进行拆分,拆分成包含描述性信息的file_description文件和包含数据的file_data文件,这个过程中消除了file_description文件中的冗余信息;接着与接收端通信确定哪些数据在接收端已经有缓存;然后将接收端已经缓存的信息从待发送的文件中去除;最后将消除了冗余的文件发送出去。
为了查找文件中的冗余信息,本文采用了文献[5]提到的办法将文件中每一个子字符串通过计算用一个整数来替代,将字符串操作转化为对整数的操作,再通过哈希表完成了冗余信息的查找。
在传输阶段,发送端通过预测的方式减少冗余信息,具体做法是发送端对拆分后生成的file_description文件计算出它的fingerprints,接着对这些fingerprints生成一个文件file_description_fingerprints并把它发送给文件接收端,接收端通过与自己缓存的file_description文件进行分析比对,向发送端做出应答,发送端通过分析应答后决定实际发送的file_description内容。
通过实验,可以看到通过文件的拆分算法,能够让文件大小减少90%以上,通过传输前的预测,能够让实际传输的数据量小于拆分后的文件大小。相对于直接发送原日志文件,本文采取的一系列策略能够让数据传输量减少到10%左右,或者更低。
本文的后续工作主要是更精确的找到冗余信息,目前的方式是通过判断fingerprints是否重复出现,这种方式生成的file_description文件虽然很大程度消除了冗余信息,但是会在file_description文件中又出现新的冗余,这应该在下一步的工作当中得到解决。
参考文献
[1] Zohar E, Cidon I, Mokryn O. The power of prediction: cloud bandwidth and cost reduction[A]. Proc of SIGCOMM[C]. 11,2011,volume 41 issue 4, pages 86-97.
[2] Laoutaris N, Sirivianos M, Yang X Y, Rodriguez P. Inter-datacenter bulk transfers with NetStitcher[A]. Proc of SIGCOMM[C]. 11, 2011,volume 41 issue 4,pages 74-85.
[3] Cormen T H, Leiserson C E, Rivest R L, Stein C. Introduction to Algorithms[M]. MIT Press’01
[4] Spring N T. Wetherall D. A protocol-independent technique for eliminating redundant network traffic[A]. Proc of SIGCOMM[C]. 00,2000, volume 30, 87-95.
[5] Manber U. Finding similar files in a large file system[A]. Proc of the USENIX winter Technical Conference, 1994, 1-10.
[6] Gupta A, Akella A, Seshan S, Shenker S, Wang J. Understanding and Exploiting Network Traffic Redundancy[R]. Univ of Wisconsin-Madison, Technical Report 1592, April 2007.
[7] Zink M, Suh K, Gu Y, Kurose J. Watch G. cache local:YouTube network traffic at a campus network -measurements and implications[A]. Proc of MMCN[C], 2008.
[8] Rabin M O. fingerprinting by Random Polynomials[R]. Center for Research in Computing Technology, Harvard University, Technical Report TR-15-81, 1981.
[9] Christopher D. Manning, Hinrich Schütze, Foundations of Statistical Natural Language Processing[M]. MIT Press’99.
News
欧胜全新Ez2软件解决方案可为移动设备免提和视频通话提供超凡的扬声器品质
欧胜微电子有限公司日前宣布:将最新的软件解决方案Ez2 grouptalk和Ez2 facetalk引入其Ez2软件功能集。这些软件是专为配合诸如WM5110高清晰度音频中枢等欧胜现有的硬件平台而设计,以极大地改善智能手机、平板电脑、个人电脑和电视机等设备在进行移动免提通话、网络电话和视频通话时的扬声器质量,并面向日益增长的移动办公会议电话市场。
欧胜的Ez2 grouptalk提供了一种可在智能手机和平板电脑上实现的卓越的免提扬声器电话通话体验,这种体验以前只能在桌面会议电话设备中实现。无论是一对一话音通话还是多人话音通话,Ez2 grouptalk软件可确保在免提通话模式下,在离设备远达5m的范围内的发言在远端听起来都同样清晰,同时他们的声音将能够被清晰地捕获。在多人话音通话的情况下,比如说一次电话会议中,由于带有声学回音消除、噪声抑制和声学增益控制,可以在通话中的任何时刻帮助跟踪最强的发言人声音,而不必担心外部环境噪声,从而带来高品质、清晰的对话。
Journal file transmission algorithm based file splitting and buffer memory prediction
MA Sai-mu1,2, WANG Jing1,2
(1 State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications, Beijing 100876, China; 2 EBUPT Information Technology Co., Ltd., Beijing 100083, China)
As networks and transmission are becoming increasingly important for computational science, we are working on proposing a journal fi le transmission algorithm. This new algorithm focusing on optimizing the performance of journal file transmission is independent of transport protocols. Our approach includes two components: the file splitting and buffer memory prediction. The file splitting performs fi le compression and redundancy elimination, and the buffer memory prediction avoids transferring the redundant data. Experimental results verify that the journal fi le transmission algorithm can effectively eliminate the redundancy in the journal fi le and reduce the amount of data transmission by 9.0%.
fi le transmission; fi ngerprint; redundancy elimination; cloud computing
TP393
A
1008-5599(2013)08-0071-08
2013-07-16
国家973计划项目(No. 2013CB329100, 2013CB329102);国家自然科学基金(No. 61271019, 61101119, 61121001, 61072057,60902051);长江学者和创新团队发展计划资助(No. IRT1049)。
猜你喜欢
汽车实用技术(2022年5期)2022-04-02 09:36:22
外语学刊(2021年1期)2021-11-04 08:08:28
石家庄铁路职业技术学院学报(2021年1期)2021-06-09 06:06:38
新能源科技(2021年6期)2021-04-02 22:43:34
科学技术创新(2021年7期)2021-03-23 06:37:42
考试周刊(2016年90期)2016-12-01 19:39:34
中国科技信息(2015年23期)2015-11-07 08:26:06
燕山大学学报(2014年1期)2014-03-11 15:28:11
武汉理工大学学报(社会科学版)(2013年5期)2013-04-29 18:29:43
武汉理工大学学报(社会科学版)(2013年5期)2013-04-29 18:29:43
