
基于组合预测模型的GDP统计数据质量评估研究
2013-03-15 00:23陈黎明
统计与决策 2013年8期
陈黎明,傅 珊
(湖南大学金融与统计学院,长沙 410079)
1 组合预测模型及数据质量评估方法
不同的预测方法根据相同的信息,往往会提供不同的结果,如果简单的将误差较大的一些方法舍弃掉,将会丢弃一些有用的信息,使得模型的精度不高。组合预测法是指通过建立一个组合预测模型,把多种预测方法所得到的预测结果进行综合。由于组合模型能够较大限度地利用各种预测样本信息,所以它比单项预测模型考虑问题更系统、更全面,因而能够有效地减少单个预测模型受随机因素的影响,可以提高预测的精确度和稳定性[1]。
1.1 单项预测模型
1.1.1 灰色预测模型

(1)残差检验
按预测模型计算X^(1)(i),并将X^(1)(i)累减生成X^(0)(i),然后计算原始序列X(0)(i)与X^(0)(i)的绝对误差序列Δ(0)(i)及相对误差序列Φ(i),一般而言,当绝对误差序列的数值波动较小且Φ(i)≤5%时,即可认为通过了残差检验。
(3)后验差检验

若所建模型不能通过残差检验,为了提高灰色预测模型的精度可建立残差GM(1,1)模型,用残差GM(1,1)模型的修正值加到原预测值上,以补偿原预测值。
1.1.2 回归组合模型
一般而言,反映社会经济现象的数据序列不平稳,往往呈现出一定的趋势或者周期性,可以建立非平稳的时间序列模型。观察GDP数据的时序图,发现GDP数据确实存在如上的性质。因而可以用以下模型来描述其变化:

其中f(t)表示GDPt随时间变化的均值,是序列的确定性趋势,可以用多项式、指数函数等来描述,ut为GDPt序列中剔除确定性趋势后的随机部分,可以看做是一个零均值的平稳过程,用ARMA模型来描述。在实践中对其通常有两种处理方法:一是直接建立ARMA模型;二是采用一种组合模型,根据序列GDPt的特点,选取合适的函数形式拟合确定性部分f(t),直到剩余序列ut可以用ARMA模型拟合。该方法即考虑了时间序列变动的确定性因素,又考虑了随机因素,具有良好的预测效果,本文采用这种处理方式。
1.1.3 双指数平滑
时间序列平滑预测法,主要通过事物自身的发展变化,借以预测事物的未来发展趋势。在没有发生重大的经济体制转变时,GDP的发展趋势可以延伸到未来,故采用时间序列来拟合GDP的发展趋势是合适的。指数平滑法是对时间序列由近及远采取逐步衰减的加权处理,当时间序列的变动具有线性趋势时,采用双指数平滑来消除滞后误差。预测步骤如下:
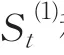
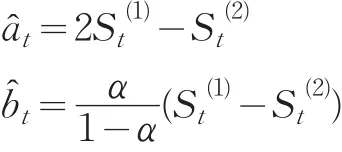
1.2 组合预测模型
权轶和张勇传(2005)系统分析了组合预测模型的权重确定方法,并对各种权重的模型预测精度进行了比较,证明最优组合综合模型的精度优于其中任何一个单一模型和其他的组合模型[2]。本文欲通过预测值代替“真值”进行数据质量评估,需尽量提高模型的预测精度,因此选择使精度达到最高的权重,构建基于误差绝对值和最小的组合预测模型。
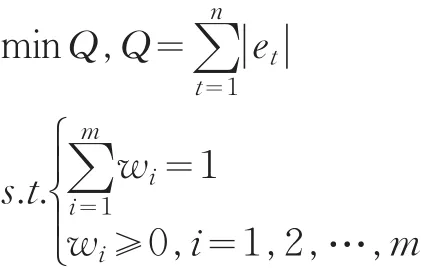
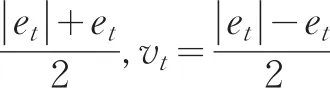

该线性规划问题有m+2n个未知量和n+1个约束条件,可以利用单纯行法进行线性问题的最优解求解[3]。
1.3 数据质量的评估
在估计出具体的评估模型之后,对数据质量评估方法的选择,本文从检验异常值角度分析预测误差,找出离群值的思想,利用Grubbs准则和Dxion准则检验模型预测相对误差的异常值,进行数据质量评估。值得注意的是,异常值讨论的前提是观测样本主体(除个别离群值外的大部分样本值)均来自同一正态总体或近似正态总体,因此,需要事先对观测样本进行正态性检验。
(1)Grubbs准则
对于服从正态分布的n个相对误差数据P1,P2,P3,…Pn,按从小到大排序,计算检验统计量Gn=P(n)-Pˉ/s,G1=Pˉ-P(1)/s,其中P(n)和P(1)分别为排序后的最大值和最小值,Pˉ和S分别是样本均值和样本标准差。在双侧情形下,给定显著性水平α,若Gn≥G(α,n),Gn>G1,则认为P(n)为异常值;若G1≥G(α,n),G1>Gn,则认为P(1)为异常值。其中G(α,n)是检验统计量的临界值,可通过查表得到。
(2)Dxion准则
对于服从正态分布的n个相对误差数据P1,P2,P3,…Pn,按从小到大排序,得到顺序统计量P(1)≤P(2)≤…≤P(n)。检验统计量根据样本量n以及可疑数值的位置和个数来选取,具体由表1给出:

表1 Dixon检验统计量
在双侧情形下,给定显著性水平α,查Dixon临界值表对应n的临界值D(α,n).若D>D',D>D(α,n),则可判断P(n)为异常值;若D'>D,D'>D(α,n),则可判断P(1)为异常值;否则,判断数据没有异常值。数学证明,在一组数据只有一个异常值时,Grubbs准则优于Dxion准则,当数据存在一个以上异常值时,Dxion准则要优于Grubbs准则[4]。
2 组合预测模型对我国GDP数据准确性检验的实证分析
2.1 数据的选取
我国统计部门于1985年才建立GDP核算制度,此后的GDP数据相对之前的数据更可靠。此外,本文是将样本集即作为训练集又作为评估集,需要假定样本集的数据基本可信,因此选择1985~2010年间的GDP数据作为样本进行分析,为了剔除价格因素的影响,将其统一换算成1985年的不变价GDP。
2.2 单项预测模型的建立
2.2.1 灰色预测模型
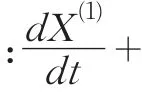

所建模型不能直接用于预测,需进行灰色预测检验,检验结果如表2所示:

表2 灰色预测检验
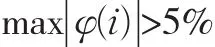


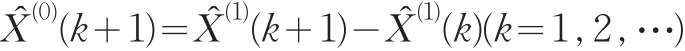
2.2.2 回归组合模型
(1)对GDP序列确定性趋势的模拟
对GDP绘制散点图,通过图形可以看出GDP数据呈现曲线上升的趋势,为非平稳时间序列。可以考虑选择二次曲线模型或者指数模型来拟合GDP的趋势增长,经过实践,发现指数模型的预测效果较好,因此,选择拟合指数模型。
指数模型GDPt=aebt+εt可以通过数据的对数变换化为直线回归模型,使分析更为直观和简便,因此对上式两边取对数得到线性回归模型:lnGDPt=lna+bt+μt,其中t为趋势项(t=1,2,…,26),采用最小二乘法估计得到如下模型:
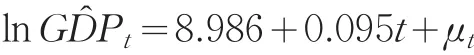
其中,可决系数为0.998,F统计量为9768.744,对应的P值为0.000,在5%的显著性水平下,回归方程和回归系数都很显著。然而模型的DW值较低,只有0.437,模型可能存在自相关。因此,对残差序列进行LM检验,得到LM检验统计量为20.413,相伴概率为0.000088,在5%显著性水平下,拒绝原假设,即认为模型的残差序列存在二阶自相关,考虑对残差序列μt建立ARMA模型。
(2)对模型残差序列μt的模拟
在建立ARMA模型之前先对序列μt进行平稳性检验,在5%的显著性水平下,根据AIC准则选取阶数,对残差序列进行包括常数项和趋势项的ADF检验,得到ADF统计量为-3.658,相伴概率为0.047,小于0.05,拒绝原假设,判定残差序列平稳,可以建立ARMA模型。通过观察μt的自相关与偏自相关图,发现自相关拖尾,偏自相关二阶截尾,初步判定μt存在二阶自相关,可拟合AR(2),结果如下:

通过该模型残差序列的自相关和偏自相关分析图,发现其自相关系数和偏自相关系数都落入了2倍标准差之内,Q统计量的相伴概率都大于0.05,可认为残差序列为白噪声序列,说明AR(2)模型的拟合效果较好。
(3)最终回归组合模型
将模型随机误差项μt的滞后项μt-1、μt-2引入原模型,在Eviews软件中对原回归方程重新做整体性估计,得到回归组合模型为:

模型调整后的可决系数为0.999,F值为11892.62,对应的P值为0.000,模型显著。为验证模型残差是否还存在自相关,对模型残差进行LM检验,在5%的显著性水平下,LM检验统计量为1.112,相伴概率为0.292,大于0.05,说明残差序列已不存在自相关,模型拟合效果较好。
2.2.3 双指数平滑
由上文可知,GDP序列呈指数形式增长,其对数序列线性增长,为了描述这一特征,将其对数序列进行双指数平滑,得到平滑预测值,然后取其反对数,即可得我国GDP的预测值。运行Eviews软件,采用使误差平方和达到最小的准则对平滑参数进行估计,得到平滑参数α=0.999,残差平方和为0.015,预测效果较好。
2.3 组合预测模型
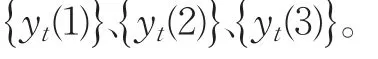
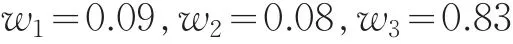
则组合预测模型为:

为检验组合预测模型的有效性,对所建的三个单项预测模型和组合预测模型进行精度比较,评价指标选用平均相对绝对误差MAPE,计算结果如表3:

表3 模型预测精度评价结果
由表3可知,组合预测模型的MAPE最小,预测精度最高,利用该模型对我国1985~2010年间的GDP数据进行预测所得的预测值更接近“真值”,数据质量评估的可靠性更高。
2.4 数据质量评估

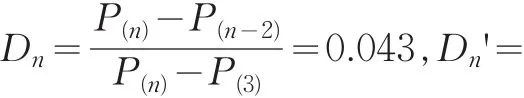
3 结论与评价
从异常值的角度进行数据质量评估,需结合异常值产生的背景进行分析。虽然1989年的GDP数据是异常值,但其异常与其所处的特殊时代背景有关,1988年中国发生了严重的通货膨胀,与上年相比,零售商品价格上升了18.5%,居民消费价格上升了18.8%。全国各地发生了抢购商品潮。政府从1988年的第四季度起实行严厉的“治理整顿”,利用各种手段紧缩投资和货币投放,使得价格的上升速度迅速下降。但是严厉的紧缩也引起了经济增长速度的迅速下滑,1989年和1990年GDP分别只增长了4.1%和3.8%。这是改革开放以来最慢的增长率。1989年间的GDP数据低于其他年份的数据是可以理解的,但是并不能确定1989年GDP数据的异常是否就是由客观原因造成的,因此不能直接判断其准确性,需要进一步研究,只能认为1985~2010年间的GDP数据基本上都是准确的。
利用统计模型对数据质量进行评估,基本思想是用模型的预测值充当“真值”,然后检验预测值与评估数据的差异是否显著,若差异显著,则数据存在异常值,如果异常值不是客观原因(如外部冲击、体制变革等)造成的,即可认为是数据本身的准确性问题。然而根据历史数据得到的预测值和真实值之间存在一定的差异,要得到更准确的结论,需要采用预测效果更好的模型进行预测,尽可能地缩小这个差异。组合预测模型能将各种不同类型的单项预测模型兼收并蓄,集中更多的经济信息与预测技术,减少预测系统误差,显著改进预测效果。可见,相比单项预测模型,运用组合预测模型对数据的准确性进行检验效果会更好。本文以我国1985~2010年间GDP数据的准确性为例进行实证分析,依据考察指标的特点构建了灰色预测模型、回归组合模型和双指数平滑模型三个单项预测模型,然后根据组合预测模型的基本思想,将三个单项预测模型的预测值进行加权组合得到组合预测模型。通过对比各个单项预测模型和组合预测模型的预测精度发现,组合预测模型确实优于单项预测模型,所得的预测值更接近“真值”,更适合于数据的准确性检验。可见,组合预测模型在统计数据的准确性检验中确实存在较高的实用价值,值得进一步研究。
[1]徐国祥.统计预测和决策[M].上海:上海财经大学出版社,2009.
[2]权轶,张勇传.组合预测方法中的权重算法及应用[J].科技创业月刊,2006(5).
[3]农吉夫,金农,谭福锦,主毅.最优组合预测的短期气候预报建模研究[J].数学的实践与认识,2008,38(8).
[4]王华,金勇进.统计数据准确性评估:方法分类及适用性分析[J].统计研究,2009,26(1).
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
电子产品世界(2021年6期)2021-02-10
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
黄河之声(2018年14期)2018-09-20
中国惯性技术学报(2015年1期)2015-12-19
共产党员(辽宁)(2015年24期)2015-10-18
浙江共产党员(2015年11期)2015-05-23
