
P MU在线分析系统计算平台技术研究
2013-01-16 08:33王英涛张传凯李旻古衡黄远超陈真丁理杰汤凡
电网与清洁能源 2013年6期
王英涛,张传凯,李旻,古衡,黄远超,陈真,丁理杰,汤凡
(1.国网电力科学研究院,北京 100192;2.四川电力科学研究院,四川 成都 610072)
近年来,基于PMU[1](Phasor Measurement Unit,相量测量单元)的在线应用技术成为电力系统的研发热点。PMU基于卫星同步时钟信号量测电力系统各个厂站的状态量,并通过网络将实时数据传送到调度中心主站,这使得电力系统实时监测、分析、控制成为可能。
笔者课题组于2012年开发了四川电网失步广域监控系统,基于PMU实时监测电网状态,对电网功角稳定进行计算分析,当电网发生振荡时,应用系统发出指令,解列电网失步断面,保证电网恢复稳定。
该系统接入的PMU能够覆盖电网主网,以一个典型区域电网为例,可以接入100台PMU;计算周期达到40 ms,整体延时不大于100 ms。这对软件实时性、硬件配置冗余性、通信技术提出了很高要求。
本文提出了软硬件设计方案,综合运用Linux实时内核技术,高可靠的双机热备集群技术,基于RDMA的高带宽、低延迟的通信技术,高性能MPI+GPU并行计算技术,满足了高实时性、高可靠性和高性能的需求。
1 平台架构设计
如图1所示,整个系统由2台通信服务器、3台计算服务器、2台监控服务器和4台监控子站组成,应用系统通过以太网和InfiniBand网络互联。
通信服务器通过以太网接收实时PMU数据,并将PMU数据通过高带宽、低延迟的InfiniBand网络传输给3台计算服务器进行实时并行计算,收集计算结果并将其发送给监控服务器,如果计算得出电网失步,则通信服务器将解列命令下发给监控子站,由子站对相应断面进行解列。

图1 系统设计框图Fig.1 System design diagram
1.1 双机热备高可靠集群技术
应用系统采用双机热备高可靠集群技术,2台通信服务器采用主-备方式(Active-Standby方式)设计。当主服务器故障时,备份服务器及时切换过去,自动接管主服务器的工作,实现对用户的不间断服务。双机热备工作机制提供了故障自动恢复能力。
Corosync和Pacemaker是Linux HA的实际执行标准。Corosync核对群集中所有的节点,确保其可用,Pacemaker负责群集中资源的位置。通过安装配置Corosync和Pacemaker,可以将2台通信服务器部署为高可用集群。具体实现过程为:
1)按照表1设置2台通信服务器的IP地址和主机名。
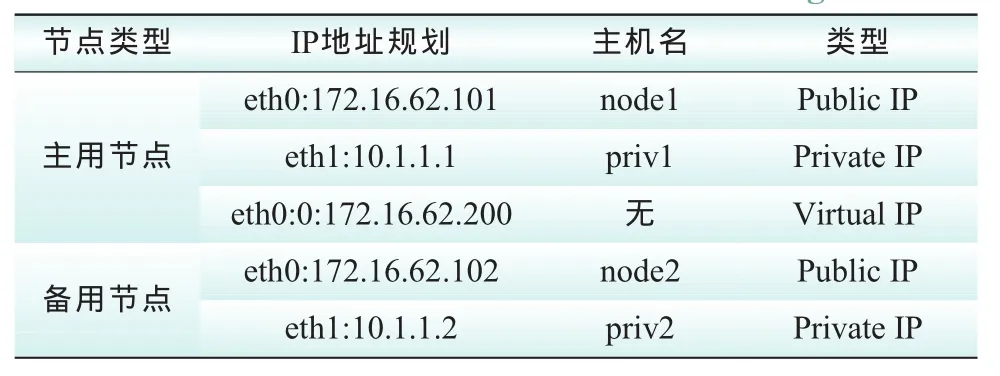
表1 IP地址及主机名设置Tab.1 IP address and host name settings
2)安装Corosync 1.4.3和Pacemaker 1.0.11。
3)设置2台通信服务器间的无密钥访问。
4)设置Corosync配置文件corosync.conf。
5)配置集群资源。
6)启动服务。
1.2 Linux实时内核
Linux内核2.4及以前版本,用户空间可以被抢占,但内核空间不能被抢占,因此实时性很差。2.6版本以后,大部分内核代码可以被抢占,但是由自旋锁保护的代码和中断处理函数不能被高优先级的内核线程抢占,Linux内核实时性有了一定的提高,可以达到几个ms的量级。由Ingo Molnar和Thomas Gleixner维护的内核补丁(CONFIG_PREEMPT_RT)进一步提高了Linux的实时性,达到了小于100 μs的程度。它所做的修改是:
1)通过rtmutexes的重新实现使内核里的锁源语(使用自旋锁)可被抢占。
2)以前被如spinlock_t和rwlock_t保护的临界区现在变得可以被抢占了。使用raw_spinloc_t创建不可抢占区域(在内核中)依旧是可能的(类似spinlock_t的相同API)。
3)为内核里的自旋锁和信号量实现优先级继承。
4)把中断处理器变为可被抢占的内核线程(RT-Preempt patch在内核线程上下文中处理软中断处理器)。
5)把老的Linux计时器API变成分别的几个基本结构,有针对高精度内核计时器的还有一个是针对超时的,这使得用户空间的POSIX计时器具有高精度。
内核升级的具体做法为:
1)解压内核源代码linux-2.6.33.9.tar.bz2和补丁文件patch-2.6.33.9-rt31.bz2;进入到内核源码目录,给内核打补丁。
2)配置和编译内核。
3)将initrd-2.6.33.9-rt31.img、System.map-2.6.33.9-rt31和vmlinuz-2.6.33.9-rt31复制到/boot/目录下。
4)将实时内核驱动模块复制到/lib/modules目录下。
5)编辑/boot/grub/目录下的menu.lst文件,添加实时内核启动项。
1.3 RDMA高带宽通信技术
RDMA技术通过网络把资料直接传入计算机的内存中,消除了外部存储器复制和文本交换操作,腾出总线空间和CPU周期用于改进应用系统性能。RDMA工作过程如下:
1)当一个应用执行RDMA读或写请求时,不执行任何数据复制。在不需要任何内核内存参与的条件下,RDMA请求从运行在用户空间中的应用中发送到本地NIC(网卡)。
2)NIC读取缓冲的内容,并通过网络传送到远程NIC。
3)在网络上传输的RDMA信息包含目标虚拟地址、内存钥匙和数据本身。请求完成既可以完全在用户空间中处理,或者在应用一直睡眠到请求完成时的情况下通过内核内存处理。RDMA操作使应用可以从一个远程应用的内存中读数据或向这个内存写数据。
4)目标NIC确认内存钥匙,直接将数据写人应用缓存中。用于操作的远程虚拟内存地址包含在RDMA信息中。
零拷贝网络技术使NIC可以直接与应用内存相互传输数据,从而消除了在应用内存与内核内存之间复制数据的需要。内核内存旁路使应用无需执行内核内存调用就可向NIC发送命令。在不需要任何内核内存参与的条件下,RDMA请求从用户空间发送到本地NIC,并通过网络发送给远程NIC,这就减少了在处理网络传输流时内核内存空间与用户空间之间环境切换的次数。
1.4MPI及GPU计算技术
MPI(Massage Passing Interface,消息传递接口)[2]是消息传递函数库的标准规范,消息传递并行程序设计指用户必须通过显式地发送和接收消息,来实现处理机间的数据交换。在这种并行编程中,每个并行进程均有自己独立的地址空间,相互之间访问不能直接进行,必须通过显式的消息传递来实现。这种编程方式是大规模并行处理机(MPP)和机群(Cluster)采用的主要编程方式。MPI支持Fortran、C和C++语言。使用MPI技术构建的计算集群节点数在理论上不存在上限的限制,但在实际中我们要考虑增加计算节点所带来的硬件成本,空间占用等问题,另外,随着节点数的增多,MPI在通讯上的开销也越大。
CUDA是基于GPU[3]的并行计算架构,采用C语言进行程序开发,能够直接访问GPU硬件资源。在CUDA架构中,GPU线程以网格(Grid)的方式组织,而每个网格中又包含若干个线程块(Block),某些GPU的线程块支持高达1536个线程。同一线程块中的众多线程能够并行执行,能够通过共享存储器(Shared memory)和栅栏(Barrier)通信。同一网格内不同块之间存在不需要通信的粗粒度并行,而一个块内的线程之间又形成了允许通信的细粒度并行。
2 基于MPI+GPU的PMU在线应用
MPI+GPU多粒度混合编程模型,充分发挥集群节点间分布式存储和节点内共享存储的优势,节点间使用MPI进行通信,系统主体结构基于经典的主从模式,采用MPI进程-pthread线程-CUDA线程3个层次的并行架构,以及CPU/GPU协同计算并行架构[4]和策略来设计实现。
PMU在线应用系统由4个计算节点组成,每个计算节点由1个多核CPU和多个GPU设备组成。输入数据在主节点上载入,平均分配到从节点上,存储到相应的内存空间内,并根据各节点的可用资源将数据划分为多块。每个从节点分别接收主节点发送的数据并存储到内存中。根据检测到的可用GPU设备数,每个从节点上创建同样数目的线程来一对一控制各个GPU。各从节点上每个数据块再进一步划分为大小相等的块一一分配给各个线程,由每个线程逐道在CPU上预处理后传送到GPU上处理,道内的各数据窗分别由各CUDA线程并行处理。每个数据块偏移由每个线程内的相关道累加计算而得,结果返回到主节点上进行集中。在实现过程中,采用CPU/GPU协同计算以及线性插值走时的方式来进一步提高性能。
节点0主要负责和PMU及监控服务器之间的数据通信,其他节点用来计算不同配置算法,如节点1进行电压稳定性计算,节点2进行功角稳定性计算,节点3进行设备安全计算,实现粗粒度并行,节点内针对某一类算法,如功角稳定计算,使用CUDA架构实现细粒度的数据并行和线程并行。各个节点的GPU计算完成后,通过MPI将计算结果汇总到通信服务器。基于MPI+GPU的混合并行计算程序流程图如图2所示。
CUDA有效结合了CPU+GPU编程,串行部分代码在CPU(Host)上运行,并行部分代码在GPU(Device)上运行。CUDA中并行执行的块称为Kernel,Kernel使用__global__限定符声明,表示该段代码在CPU上调用,在GPU上执行。使用__device__声明的代码从GPU上调用,在GPU上执行,使用__host__声明的代码从CPU上调用,在CPU上执行。以二维傅里叶变换的计算为例,测试GPU的加速性能,关键代码如下:
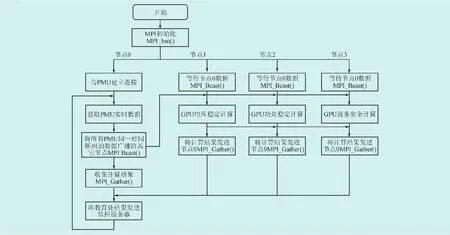
图2MPI+GPU并行计算程序流程图Fig.2 MPI+GPU parallel computing program flow chart
#include
#define NX 1024
#define NY 1024
cufftDoubleComplex*idata,*odata;
cudaMalloc((void**)&idata,sizeof(cufftDoubleComplex)*NX*NY);
cudaMalloc((void**)&odata,sizeof(cufftDoubleComplex)*NX*NY);
cufftHandle plan;
cufftPlan2d(&plan,NX,NY,CUFFT_Z2Z);
cufftExecZ2Z(plan,idata,odata,CUFFT_FORWARD);
cufftDestroy(plan);
cudaFree(idata);
cudaFree(odata);
系统性能在一典型异构 GPU集群上测试,每个节点由1个配置32GB内存的六核CPU,以及配置6GB显存的C2050型号的GPU组成。对于不同的规模和积分计算模式,在该平台上的测试结果表明,本文实现的系统的性能对于包含相同计算节点数、每个节点上6个线程并行计算的MPI版本,可以达到平均5~10倍的加速。
硬件测试平台为:CPU,2*INTEL XEON 5650;GPU,NVIDIA Tesla C2050。二维FFT在CPU和GPU上的运算时间如图3所示。

图3 二维FFT在CPU和GPU上的运行时间Fig.3 The run time of 2D FFT on CPU and GPU
从测试结果可以看出,随着计算量的增大,CPU运算时间大幅增加,GPU相对于CPU的运算加速比也在增加,在1024×1024情况下的加速比为58.40。
3 应用系统测试
笔者课题组开发的基于PMU的失步广域监控系统,在全数字仿真系统上[5]进行了测试。应用系统接收数据包括:同步相量数据(三相基波电压、三相基波电流及基波正序相量)、频率和开关量信号;发电机内电势和发电机功角。
每帧数据量:96路相量;16路模拟量;48路开关量;共422字节/帧。
省级电网:按20~60台PMU计算,数据流速为3.8~11.4 Mbp/s。
区域电网:按30~120台PMU计算,数据流速为5.7~22.8 Mbp/s。
全国电网:按1000~2000台PMU计算,数据流速为190~380 Mbp/s。
测试案例中,PMU量测范围覆盖华北-华中电网500 kV厂站共322个,量测点12985个,包括线路电压、电流相量、有功功率、无功功率、频率等状态量,实时数据刷新周期为40 ms。
经过测试,基于MPI+GPU的计算平台整组工作时间在40 ms以内。其中实时计算分析时间在10 ms以内,数据上行和命令下行的耗时在20~30 ms,系统的整体性能满足了广域控制的要求[6]。
4 结语
随着广域监测技术[7-8]的发展,越来越多的PMU接入系统中,笔者及课题组根据四川电网失步广域监控的技术需求,提出了在线计算分析平台的架构体系,包括MPI+GPU的混合式高速并行计算方案,该方案充分考虑了系统在实时性及可扩展性方面的需求。
为验证在线计算平台的实时性,基于实时仿真技术构建了以四川电网为实例的测试系统。仿真系统模拟各种严重故障,以与现场PMU/WAMS相似的通信特性给广域控制系统发送相量数据、接受紧急控制信号。试验证明,在线计算平台满足了PMU大量数据、在线分析的需求。
目前该技术正在现场安装、应用,这将有力提高大电网运行的安全稳定性。
[1] 张文涛,邱宇峰,郑旭军,等.GPS及其在电力系统中的应用[J].电网技术,1996,20(5):38-40.ZHANG Wen-tao,QIU Yu-feng,ZHENG Xu-jun.GPS and its application in power system[J].Power System Technology,1996,20(5):38-40.
[2]MICHAEL J,QUINN.MPI与OpenMP并行程序设计[M].北京:清华大学出版社,2004.
[3]JASON SANDERS,EDWARD KANDROT.CUDA by Example:An Introduction to General-Purpose GPU Programming[M].清华大学出版社,2010.
[4]BENEDICT R,GASTER,LEE HOWES,et al,Dana Schaa.OpenCL异构计算[M].清华大学出版社,2012.
[5] 李战鹰,张建设.南方电网失步解列特性RTDS仿真试验研究[J].南方电网技术,2008,2(1):31-35.LI Zhan-ying,ZHANG Jian-she.RTDS simulation study on the performance of out-of-step splitting systems in China southern power grid[J].Southern Power System Technology.2008,2(1):31-35(in Chinese).
[6]汤涌,王英涛.大电网安全分析、预警及控制系统研制系列报告[R].北京:中国电力科学研究院,2011.
[7]党杰,董明齐.基于WAMS录波数据的华中电网低频振荡事件仿真复现分析[J].电力科学与工程,2012,28(4):19-23.DANG Jie,DONG Ming-qi.Central China grid low frequency oscillation simulation recurrence analysis based on WAMS measured data[J].Electric Power Science and Engineering,2012,28(4):19-23(in Chinese).
[8] 常勇,吴靖,王超.基于广域信号的区域间低频振荡监视[J].电网与清洁能源,2011,27(5):16-21.CHANG Yong,WU Jing,WANG Chao.Monitoring of interarea oscillation based on wide area measurement signal,power system and clean energy,2011,27(5):16-21(in Chinese)
猜你喜欢
计算机系统应用(2022年5期)2022-06-27
今日农业(2021年9期)2021-07-28
军民两用技术与产品(2021年10期)2021-03-16
成都信息工程大学学报(2018年4期)2019-01-23
信息安全研究(2018年12期)2018-12-29
中国交通信息化(2018年12期)2018-03-21
北京航空航天大学学报(2017年12期)2017-04-23
电子技术与软件工程(2016年22期)2016-12-26
航天返回与遥感(2014年1期)2014-07-31
铁路通信信号工程技术(2014年5期)2014-02-28
