
基于云计算的中文分词研究
2012-12-26 06:44许云峰张立全
河北科技大学学报 2012年3期
张 妍,许云峰,张立全
(1.河北科技大学信息科学与工程学院,河北石家庄 050018;2.中国铁通集团有限公司河北分公司,河北石家庄 050000)
基于云计算的中文分词研究
张 妍1,许云峰1,张立全2
(1.河北科技大学信息科学与工程学院,河北石家庄 050018;2.中国铁通集团有限公司河北分公司,河北石家庄 050000)
通过搭建Hadoop平台,将MapReduce编程思想应用到中文分词的处理过程中,使中文分词技术在云计算环境中实现。研究可以在保证原来分词准确率的基础上,显著提高中文分词的处理速度。
中文分词;云计算;Hadoop;MapReduce
中文分词就是将中文连续的字序列按照一定的规则重新组合成词序列的过程。中文分词是进行中文信息检索和数据挖掘的基础,已经广泛应用到相关领域,如机器翻译(MT)、语音合成、自动分类、自动摘要、自动校对等。现有的中文分词算法可分为3大类:基于字符串匹配的分词方法;基于理解的分词方法和基于统计的分词方法。目前已经成熟的中文分词项目有:SCWS,FudanNLP,ICTCLAS,HTTPCWS,CC-CEDICT,IKAnalyzer,Paoding,MMSEG4J等。其中ICTCLAS是中国最早开发的中文分词开发包,IKAnalyzer,Paoding,MMSEG4J是用Java语言开发的中文分词开发包。
采用IKAnalyzer中文分词开发包,通过搭建基于Hadoop的云计算平台,将MapReduce编程思想应用到中文分词的处理过程中,在保证原来分词准确率的基础上,提高了中文分词的处理速度。
1 系统架构
笔者将系统架构在2台Dell R410服务器之上,每台服务器分别部署Vmware vSphere Hypervisor,并安装4个FreeBSD操作系统,在每个FreeBSD系统上部署安装Hadoop 0.2,在Hadoop平台上实现中文分词算法,单台服务器系统架构图见图1。
文中的分布式文件系统采用HDFS,HDFS的架构建立在8个节点组成的集群上,每个节点上都运行FreeBSD UNIX系统,并且配置了Hadoop环境。HDFS采用了主从(Master/Slave)架构,一个集群有一个Master和多个Slave,前者称为名字节点(NameNode),后者称为数据节点(DataN-ode)[1]。一个文件被分割成若干Block存储在一组Data-Node上。NameNode负责打开、关闭和重命名文件及目录,同时建立Block与DataNode之间的映射。DataNode负责响应客户的读/写需求,同时在NameNode的指挥下实现Block的建立、删除以及复制。
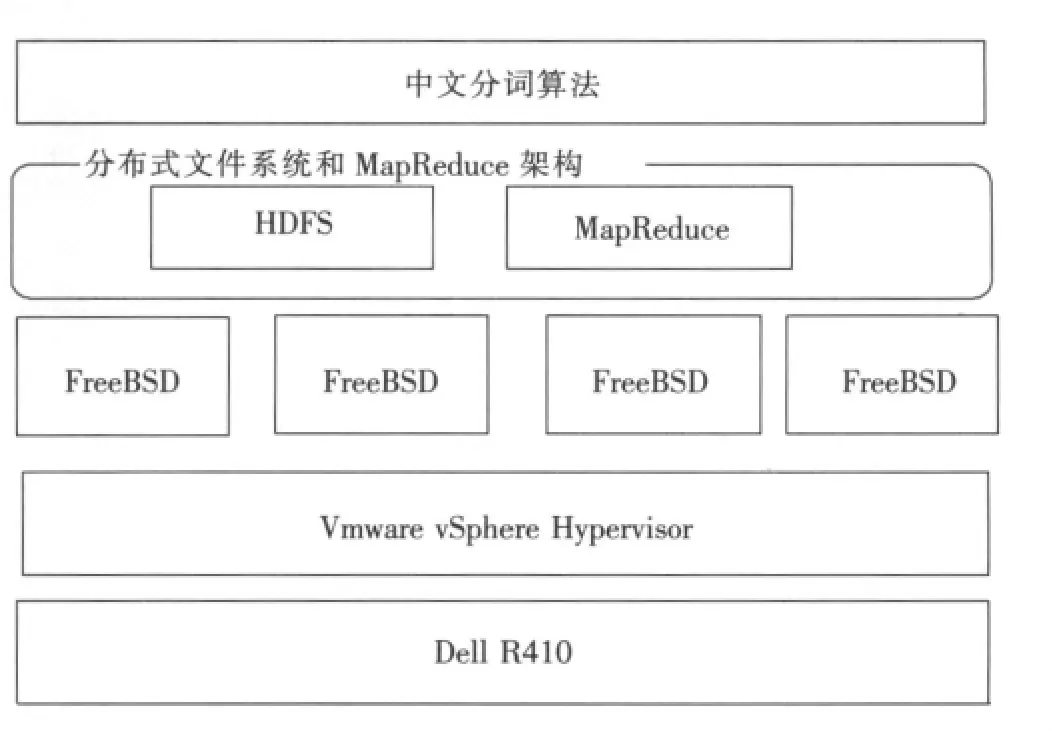
图1 系统架构图Fig.1 System deployment diagram
MapReduce是一种编程模型,用于大规模数据集的并行运算[2]。将单机运行的中文分词算法应用到这种MapReduce编程模型中。由于Hadoop环境主要支持Java程序运行,因此选用IKAnaly-zer这个开源的Java中文分词工具包,将其分发到Hadoop的各个节点中去。IKAnalyzer是一个开源的、基于Java语言开发的轻量级的中文分词工具包,从2006-12推出1.0版开始,IKAnalyzer已经推出了3个版本。最初它是以开源项目Luence为应用主体,结合词典分词和文法分析算法的中文分词组件,新版本的IKAnalyzer 3.0则发展为面向Java的公用分词组件。
2 关键技术
2.1 中文分词的MapReduce流程
中文分词的MapReduce流程图见图2,具体步骤如下。

图2 中文分词的MapReduce流程图Fig.2 MapReduce flow diagram for Chinese word segmentation
1)JobClient向Hadoop分布系统、文件系统HDFS依次上传3个文件:job.jar,job.split和job.xml。job.jar里面包含了执行此任务需要的各种类,包括Mapper,Reducer等实现;job.split包括文件分块的相关信息,比如数据分多少个块,块的大小(默认64MB)等;job.xml是对作业配置的描述,包括Mapper,Combiner,Reducer的类型、输入、输出格式的类型等。这3个文件实际上是完成了向JobTracker提交中文分词任务,并且将用户提交的大文件分成若干数据块,数据块大小由FileInputFormat的setMaxInputSplitSize和 setMinInputSplitSize来设置。
2)JobTracker负责向TaskTracker指派映射任务和规约任务。
3)被指派执行映射任务的JobTracker创建Task实例来读取要进行中文分词的分块文件,处理成原始的〈Key,Value〉键值对,其中Key为每一行文本相对于分块文件头的偏移,Value为分块文件的每一行文本,然后定义一个IKTokenizer对象并实例化,再取出每个分词作为Key,计数器变量one作为Value。
4)Map中生成的〈Key,Value〉数据序列被保存到对应的TaskTracker所在节点的磁盘里,TaskTracker将这些数据序列的存放位置发送给JobTracker。JobTracker再将此信息发送给执行规约任务的TaskTracker。
5)执行规约任务的TaskTracker根据JobTracker发送来的数据序列位置信息从各个节点读取数据序列,并执行中文分词汇总任务。
6)执行规约任务的TaskTracker最后将汇总结果写入HDFS。
2.2 中文分词组件的分发
中文分词MapReduce化的关键是中文分词组件在云计算环境里的分发[3]。中文分词组件的分发,目前有4种方式。
1)将第三方jar包放在集群中每个节点$HADOOP_HOME/lib目录下或者JDK的ext目录下,其中$HADOOP_HOME为Hadoop的根目录。在FreeBSD下可以通过编写shell脚本,用scp或者rcp命令来实现,但是这种做法依赖操作系统,可移植性不强。
2)将所有的jar包解压缩,然后把它和源程序的类文件打包到一个jar包中。这种方法可以用Eclipse的Export功能轻松实现,因此,笔者推荐用此方法。
3)用.(file,conf)或者.(archive,conf),其中路径是HDFS上的一个路径,不要用HDFS://等类似的路径,而要用相对路径。
4)将第三方jar包和源程序类文件打包到一个jar包中,设置manifest.mf的classpath值为jar包所在的路径,这个路径必须是相对应当前jar包的路径。该方法主要借鉴了在提交作业到Hadoop中时,Hadoop寻找classpath的方式来解决。
笔者通过实验测试比较发现,以上4种中文分词组件的分发方法中,只有第2种方法所需的手工输入较少。因此笔者采用第2种方式对IKAnalyzer组件进行分发。
3 中文分词速度实验数据分析
3.1 实验环境
实验用硬件环境和操作系统:Dell R410服务器2台,每台分别部署Vmware vSphere Hypervisor。在每台服务器上,分别安装4个FreeBSD操作系统。在每个FreeBSD系统上面部署安装Hadoop 0.2。Dell R410的硬件配置:CPU为Intel Xeon E5504 2GHz,主频为4GB内存。
3.2 实验数据分析
文中分别用5,6,7,8个节点的云计算环境,对18 103个中文文本进行中文分词和词频统计,时间依次为532,449,396,412s。可见随着节点的增加,运行相同应用程序的时间线性减少。但是到8个节点的时候,运行时间有所加长。当把这18 103个文件预处理成为一个69.4MB的文件后,在5,6,7,8个节点的云计算环境中,处理时间分别为115,112,110,108s。此时分词处理速度在8个节点时为69.4/108=0.643 MB/s。节点和运行时间的关系见图3。根据IKAnalyzer开发方的官方数据,其单机的最快速度是83万字/s(1 600KB/s)。处理数量巨大的小文件并不是MapReduce的长项,因此将输入的中文文件预处理成一个比64MB大的文件是相当有必要的,而且文件越大,MapReduce越能发挥威力。因此将大文件加大到702.8 MB,此时在8个节点上的运行时间为145s,分词速度为702.8/145=4.265MB/s,那么本文的处理速度已经是单机处理速度的4 265/1 600=2.67倍。可见,基于Hadoop的云平台可以大幅度提高中文分词和词频统计的效率。
4 结 论
在云环境下实现中文分词算法,可以大幅度提高中文分词的处理速度,在2台Dell R410服务器上搭建8节点的基于Hadoop云平台上,可以将分词速度提高到单机的2.67倍,并且随着节点数的增加中文分词处理速度呈线性增加。由此可见,基于云计算技术的中文分词算法可以加快中文信息处理的速度,并且可以突破各种中文信息处理应用领域的瓶颈。
[1] 何忠育,王 勇,王 瑛,等.基于分布式计算的网络舆情分析系统的设计[J].警察技术(Police Technology),2010(3):14-22.
[2] 李应安.基于MapReduce的聚类算法的并行化研究[D].广州:中山大学,2010.
[3] 许云峰,张 研,赵铁军.基于云计算的商业情报采集系统[J].河北科技大学学报(Journal of Hebei University of Science and Technology),2012,33(2):161-165.
Research in to Chinese word segmentation based on cloud computing
ZHANG Yan1,XU Yun-feng1,ZHANG Li-quan2
(1.College of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang Hebei 050018,China;2.Hebei Branch,China Tietong(Group)Company Limited,Shijiazhuang Hebei 050000,China)
In this paper,the MapReduce programming ideas are applied to Chinese word segmentation processing in Hadoop platform to apply Chinese word segmentation in the cloud computing environment.The research could effectively improve Chinese word segmentation processing speed on the basis of ensuring the accuracy of word segmentation.
Chinese word segmentation;cloud computing;Hadoop;MapReduce
TP391.1
A
1008-1542(2012)03-0266-04
2011-11-10;责任编辑:陈书欣
河北省科技支撑计划项目(10213588)
张 妍(1980-),女,河北石家庄人,讲师,硕士,主要从事网络安全、神经网络和计算机应用方面的研究。
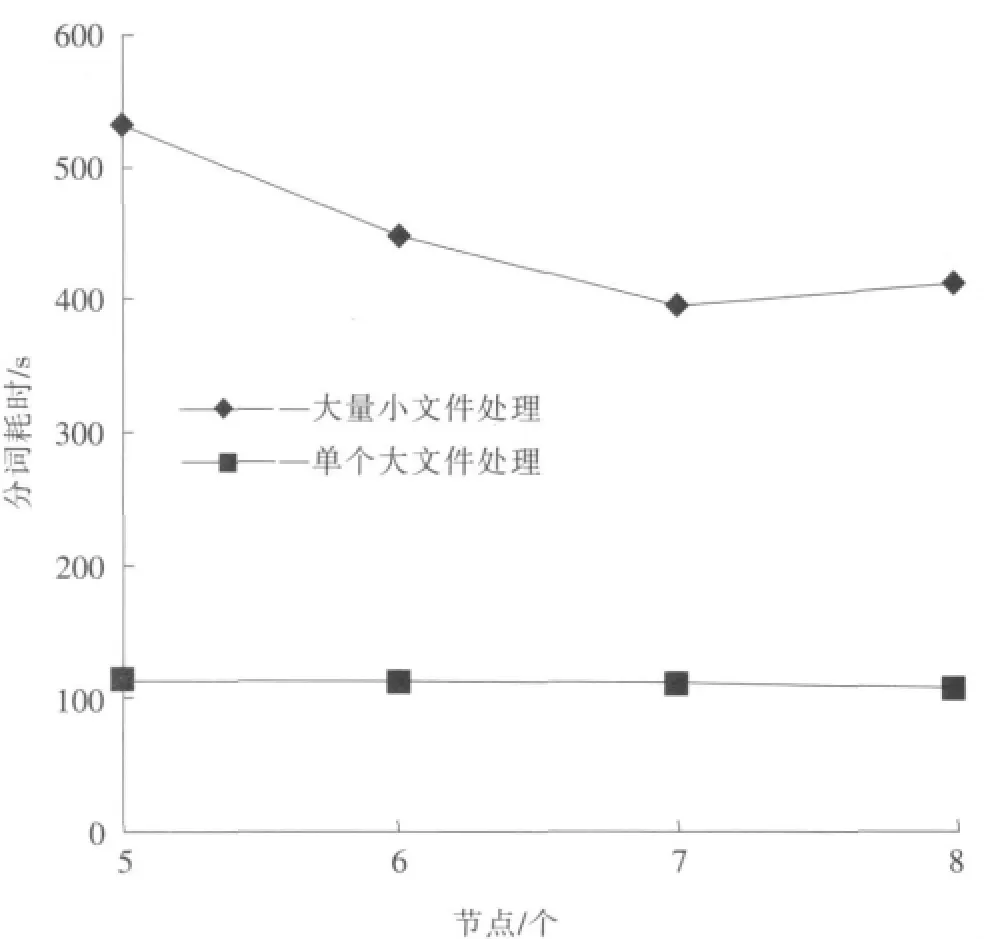
图3 节点和运行时间的关系图Fig.3 Node and run-time diagram
猜你喜欢
河北农机(2022年7期)2022-10-11
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
伙伴(2018年1期)2018-05-14
东方艺术·国画(2016年3期)2017-02-08
老同志之友(2016年5期)2016-05-14
外语学刊(2011年3期)2011-01-22
