
基于频繁闭项集的Web日志挖掘算法
2012-12-12 03:29秦东霞张栋梁吴文欢
周口师范学院学报 2012年2期
秦东霞,周 航,张栋梁,吴文欢
(周口师范学院计算机科学与技术学院,河南周口466001)
伴随着电脑技术和互联网技术的飞速发展,人们希望在互联网上找到自己需要的各种各样的信息。用户在网上的各种行为都保存在服务器中,如何发现这些行为中隐含的规则和关系,对改进网站及吸引更多用户有着重要的意义。Web日志数据挖掘技术是解决上述问题的一个有效办法。本文将关联规则引入到Web日志挖掘过程中,并通过频繁闭项集来压缩关联规则产生的数量,同时使用最小关联规则有效地避免了冗余规则的产生。实验证明该算法不仅能提高挖掘效率,并且不丢失任何信息。
1 Web日志挖掘
Web日志挖掘是指通过分析用户访问服务器时留下的访问记录,结合各种数据挖掘技术,得到包括网站运营和用户访问规律等信息,从而改进网站服务,提高用户满意度。
1.1 Web日志挖掘模型
提取Web日志中的隐含的信息需要经过数据预处理、模式发现和模式分析等阶段[1],图1显示了Web日志挖掘模型。
数据预处理是进行Web日志挖掘的前提步骤,它是针对具体的挖掘目的将Web日志文件转换为适合进行挖掘的数据文件的过程。预处理要经过数据清洗、用户识别、会话识别和路径补充等阶段,以保证数据的准确性和有效性[2]。
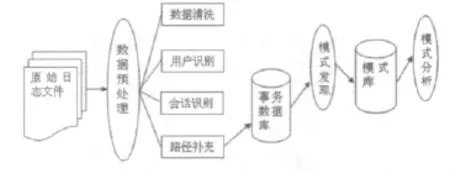
图1 Web日志挖掘模型
模式发现在Web日志挖掘中具有举足轻重的作用。该阶段通过相应的数据挖掘算法对预处理后的数据进行挖掘,提取其中有价值的信息。模式发现包括分类、聚类、关联规则、序列模式和统计分析等常用的方法和技术[3]。
模式分析是针对用户感兴趣的规则和模式进行进一步地分析,从而挖掘得到有价值的信息。
1.2 问题与解决方法
关联规则在数据挖掘中得到了广泛的应用,尤其在大量商业决策中。近年来页面关联规则挖掘可以提取用户访问页面间隐含的因果关系、简单关系和前后关系等,具有较好的商业前景。然而,现有的基于关联规则的Web日志挖掘算法往往产生大量的候选规则,这对规则的排序、修剪和查找都带来了许多不便,同时这些候选规则中存在大量不能为用户提供有价值信息的冗余规则。本文通过引入频繁闭项集和最小关联规则的相关概念,解决了如下三个问题:
1 )在一定程度上避免了大量候选规则的产生,从而降低了算法对内存空间的要求;
2 )在分析冗余规则产生原因的基础上,提出了使用最小关联规则减少冗余规则产生的对策;
3 )将频繁闭项集的概念应用到了Web日志挖掘中,使得频繁闭项集的应用得到进一步推广。
2 基于频繁闭项集的无冗余关联规则
2.1 基本概念
假设集合I={i1,i2,…,in}是一项目组,D= {t1,t2,…,tn}是一数据集。表1是一个示例数据集,一个事务可以用二元组
图2a)中给出了事务集和项目集之间的对应关系。以表1中给出的示例数据库为t(AC)=t(A)∩t(C)=126∩1356=16,i(135)=i(1)∩i(3)∩i(5)=ACDE∩CDE∩CE=CE。
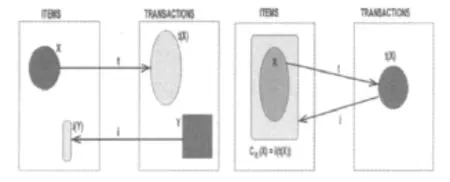
图2 a)事务集与项目集的对应关系; b)闭项集的表示
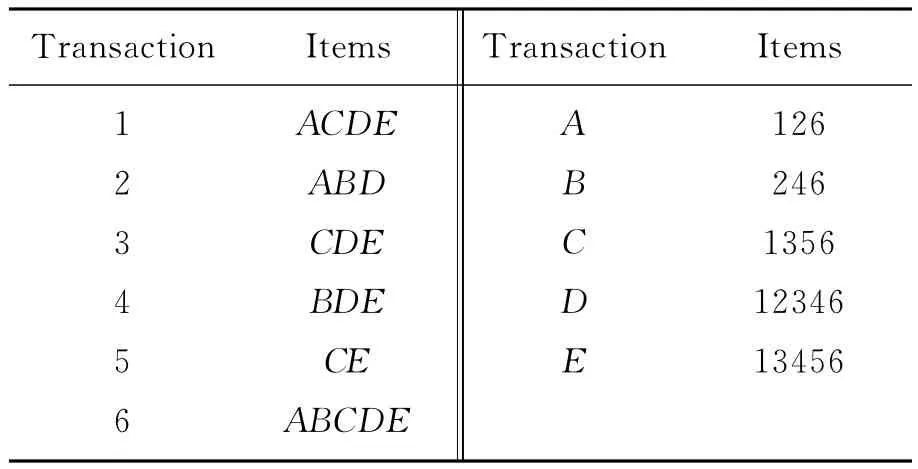
表1 示例数据库
定义1 项目集I中,有项集X⊆I存在,X是闭项集当且仅当c(X)=i(t(X))=X。如图2b)所示
定理1[5]对于项集D中的任一项集X,项集X的支持度sup(X)与其闭项集c(X)的支持度sup(c(X))相同,也即σ(X)=σ(cit(X))。
定理2[6]对于任一项集X,有X⊆i(t(X))。对任意标志集Y,有Y⊆t(i(Y))。
以示例数据库为例,CD⊆i(t(CD))= i(2456)=CD,AC⊆i(t(AC))=i(16)=ACDE。
以上两个定理表明,由频繁闭项集可以推导出频繁项集,同时频繁闭项集的数量更少,尤其对密集数据集而言。最坏的情况是频繁闭项集的数量与频繁项集的数量相等[7]。
定义2[6]如果存在项集X满足以下两个条件:
1 )sup(X)≥a(a表示用户规定的最小支持度阈值),
2 )不存在项集Y⊆I∧X⊂Y∧sup(X)= sup(Y),
则称项集X为频繁闭项集(Closed Frequent Itemset)。频繁闭项集也可称作闭频繁项集。
定义3[6]D为事务集,从其中挖掘得到的频繁闭项集的集合记作C,那么频繁闭项集格L= (C,≤),其中“≤”表示这些频繁闭项集的偏序关系。由表1示例数据库产生的频繁闭项集格结构如图3所示。
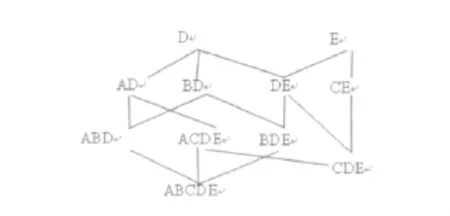
图3 示例数据得到的频繁闭项集格
在集合C中,如果存在频繁闭项集X和Y满足下面两个条件:
1 )X⊂Y,
2 )不存在Z使得X⊂Z⊂Y,
那么Y是X的直接闭超集。建立频繁闭项集格结构就是建立节点X和其直接频繁闭超集之间的链接,因为节点X的子节点就是其直接闭超集。通过这种格结构的建立可以快速地产生最小关联规则,从而得到所有的关联规则[7]。
2.2 基于闭项集的关联规则
自1999年Pasquier等提出闭项集的相关理论以后,闭项集解决了全项集出现的一些问题,不断得到广泛的应用。众所周知,闭项集是全项集的子集,更是全项集的无损表示。在挖掘关联规则的过程中,用频繁闭项集代替频繁项集可以使得挖掘得到的规则数量更小,而且不会损失任何信息。通过频繁闭项集可以诱导推出所有的频繁项集,同时通过挖掘频繁闭项集得到的关联规则可以推导出所有的关联规则[6]。
挖掘频繁闭项集的经典算法有A-close,Closet和Closet+[7],以及高效快速挖掘频繁闭项集的CHARM算法[8]等。CHARM-L算法是一个能高效挖掘产生频繁闭项集并构建其格结构的算法,它是CHARM算法的进一步应用。
2.3 无冗余的关联规则
通过挖掘频繁闭项集得到的关联规则中同样包含支持度和置信度相同的冗余规则。文献[6]提出了最小关联规则的概念,通过此理论的引入,可以得到无冗余的关联规则。
最小关联规则是指这些规则有一些与其支持度和置信度相同的规则,通过在最小关联规则的前件或者后件添加相应的项可以推导出这些冗余的规则。
性质1[6,9]关联R:X⇒Y是置信度为100%的规则,当且仅当t(X)⊆t(Y)。
性质1说明置信度为100%的规则是那些从超集推导到子集的规则,又由项集的支持度sup(X)与其闭项集的支持度sup(c(X))相等,他们能提取出相同的关联规则。
性质2[6,9]假设规则Ri:X⇒X是置信度为100%的关联规则,其中Ri是集合R=(R1,R2,…, Rn)中的一员。若I1=c(X∪X),I2=c(X),则关联规则I1⇒I2是该集合中置信度为100%的最小关联规则,且其他所有的规则都是冗余的,并且都等价于规则I1⇒I2。
性质3[6,9]假设规则Ri:X⇒X是置信度小于100%的关联规则,其中Ri是集合R=(R1, R2,…,Rn)中的一员。若I1=c(X),I2=c(X∪X),则关联规则I1⇒I2是该集合中置信度小于100%的最小关联规则,且其他所有的规则都是冗余的,并且都等价于规则I1⇒I2。
2.4 挖掘基于闭项集的无冗余关联规则
若希望在挖掘得到频繁闭项集并产生其关联规则的同时,提取无冗余的关联规则,可通过建立规则的前件和后件之间的父子关系,也就是格结构来完成。Charm-L算法[10]是在Charm算法的基础上快速建立此格结构。本文将使用Charm-L算法来建立Web日志之间的格结构,同时引入最小关联规则的概念挖掘得到无冗余的关联规则。
3 算法性能评价及应用
以上通过实例和相关概念阐述了最小关联规则在挖掘关联规则过程中的优势,接下来将使用相关算法来进行实验对比。本实验是在一台CPU主频为2.00GHz,内存为2GB的Window 7操作系统中进行的,实验数据来自于ftp://ftp.ics.uci。 edu/pub/machineLearning-databases/。本文主要做了两个对比实验,一个是在稠密数据集和稀疏数据集中挖掘所有关联规则和最小关联规则所用时间的对比,如图4。

图4 生成关联规则平均时间
另外一个是针对相同的数据集,挖掘得到的所有关联规则和最小关联规则的数量对比,如表2。
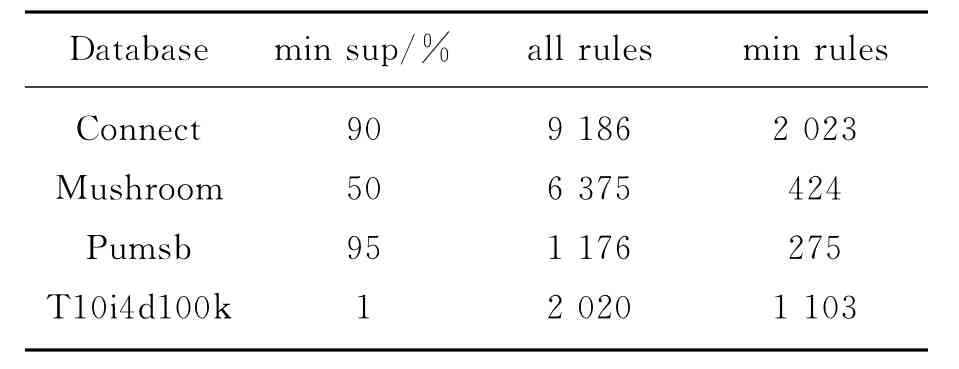
表2 关联规则数量
由图4和表2可以明显看出,无论对稀疏数据集还是稠密数据集,挖掘最小关联规则的时间总是比较短,而且挖掘得到的规则数量要小得多。
下面将其算法应用到具体的Web日志数据中。以周口师范学院校园网Web日志数据为实验对象,经过预处理后的数据对这些数据进行转换,具体处理过程参考文献[7],这里不再赘述。然后使用Charm-L算法进行挖掘,最后得到频繁闭项集及其格结构。挖掘过程中选取最小支持度为5%,最小置信度为10%,本实验共得到23条最小关联规则。接着对这些规则进行分析,去除用户点击产生的无意义的频繁规则,挖掘得到的有价值模式4条,如表3所示,其中输出的结果按照支持度从小到大排列。
下面,具体分析挖掘出的这几条关联规则的使用价值:
1 )规则1显示5%的用户通过校园网来查看校历,这表明学校校历放在了不显眼的位置。因此,网站管理者可以通过此条信息调整一下校历的相关网页的位置。
2 )规则2中6%的用户访问学校的精品课堂,但我们发现学校的精品课堂相关网页有时候打不开。

表3 挖掘得到的有价值的关联规则
3 )规则3表明用户使用招生网站中的搜索功能比较多,表明该页面中网站的信息分类功能做的不太完善。
4 )从规则4可以得知9%的用户同时访问了“校园简介”和“校园风光”,然而我们却发现在“校园简介”这一页面中并无“校园风光”的相关链接,用户要返回到学校主页才能点击查看校园风光。因此,根据这条信息的提示,建议网站管理者在“校园简介”这一页面中加入“校园风光”的相关链接。
4 结束语
本文分析了Web日志挖掘模型以及目前Web日志挖掘中出现的规则数量多,存在冗余规则等问题,并提出了运用频繁闭项集挖掘关联规则减少规则数量的思想。本算法同时引入最小关联规则的概念挖掘无冗余的关联规则,最后以周口师范学院校园网Web日志为挖掘对象,验证算法的可行性和实用性。实验证明了算法的有效性,也为日后该算法的推广提供了有力的依据。
[1]Cooley R,Mobasher B,Srivastava J.Web mining Information and pattern discovery on the world wide web [C]//In proceedings of the 9th IEEE International Conference on Tools with Arifical Intelligence (ICTAT97),1997:558-567.
[2]周增国,庞有军.Cookie技术在Web日志挖掘预处理中的应用[J].大连大学学报,2006,27(2):59-62.
[3]王继成,潘金贵,张福炎.Web文本挖掘技术研究[J].计算机研究与发展,2000,37(5):513-520.
[4]陈安,陈宁,周龙骧.数据挖掘技术及应用[M].北京:科学出版社,2006.
[5]朱玉全,宋余庆.频繁闭项目集挖掘算法的研究[J].计算机研究与发展,2007,11(7):1177-1183.
[6]Zaki M J.Generating Non-Redundant Association Rules[C]//Proc.of the 6th ACM SIGKDD Intl'Conf. on Knowledge Discovery and Data Mining,2000:34-43.
[7]Raymond Kosala,Hendrik Blockeel.Web Mining Research:A Survey[J].ACM SIGKDD Explorations, 2000,2:1-15.
[8]秦东霞.基于频繁闭项集的关联分类算法[D].重庆:重庆大学计算机学院,2009.
[9]闫英春.基于闭频繁项集的Web日志挖掘[D].成都:电子科技大学,2010.
[10]Zaki MJ,Hsiao C J.Efficient Algorithms for Mining Closed Itemsets and Their Lattice structure[J].IEEE Transactions on Knowledge and Data Engineering, 2005,17(4):462-478.
猜你喜欢
计算机工程与应用(2022年15期)2022-08-09
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
思维与智慧·上半月(2018年10期)2018-11-30
计算机与数字工程(2018年10期)2018-10-23
思维与智慧·上半月(2018年9期)2018-09-22
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
