
基于关系树的知识查询算法研究
2012-11-22 03:35洪宗祥李跃新
湖北大学学报(自然科学版) 2012年3期
洪宗祥,李跃新
(湖北大学数学与计算机科学学院,湖北 武汉 430062)
自1956年提出人工智能以来,广大的科研工作者对其进行了广泛而深入的研究,同时也取得了一定的成果,直到20世纪70年代“知识工程”概念的提出,可谓是人工智能领域发展的里程碑.随着专家系统的出现并且逐步商业化,知识工程的技术和理论也日益更新.到21世纪,知识自动获取,知识库系统的理论与技术和分布式知识库系统成为研究的主要内容[1],有关知识库中知识的表示存储以及推理查询成为国内外科研工作者研究的热点.自然语言查询问题更是其中重要组成部分.自然语言查询就是研究如何使计算机理解并生成人们日常所使用的语言,并对人给计算机提出的问题用自然语言进行反馈[2].本文中提出的在关系模型的语义网知识表示基础上,将其转换成关系树模型,对基于该模型提出一般直接知识的正向、逆向知识查询算法以及隐含知识查询算法.
1 自然语言查询问题描述
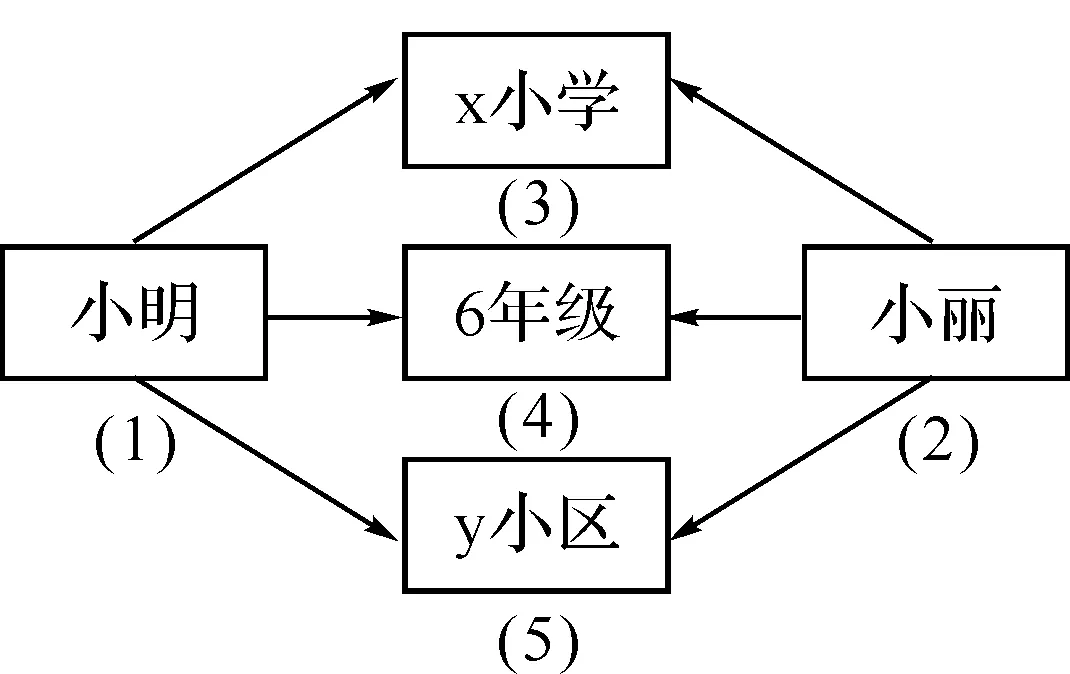
图1 语义网络
自然语言查询问题最初在搜索引擎方面比较突出,现阶段由于知识工程概念的推出,使得基于知识库系统的自然语言查询显得尤为重要.通常是用户在系统查询界面上输入自然语言,而系统在后台执行处理操作,进而把查询结果返回给用户的过程.后台处理的基本思想是:先对自然语言进行分词,预处理,然后进行语义分析,知识提取,模板匹配以及反馈结果等[3].其中,分词也是提取关键词的过程,因此大多数自然语言查询本质是关键词查询.本文中主要是对知识提取模块中知识查询算法进行研究.知识提取基本思想为:第一步:将知识库中的知识用语义网络表示(如图1),将语义网络中有向边的起始节点与终止节点的关系构成关系模型(如图2),将关系模型顺时针旋转90°得到关系树模型(如图3).第二步:在此关系树模型上进行查询,调用查询算法,返回查询知识与当前模板匹配.第三步:返回查询结果.其中,第二步是论文研究核心.下面简单说明上文中从语义网络到关系模型以及关系树的转换过程.
假设一段知识的事实描述如下.
小明和小丽是x小学6年级学生,他俩是y小区的邻居.
则转换过程如下:
其中,Start _Node_ Table 和End _Node _Table 定义如下:
Start _Node _Table(NodeID, NodeName, EndNodePointer)
End_ Node_ Table(NodeID, NodeName, NodeRelation)
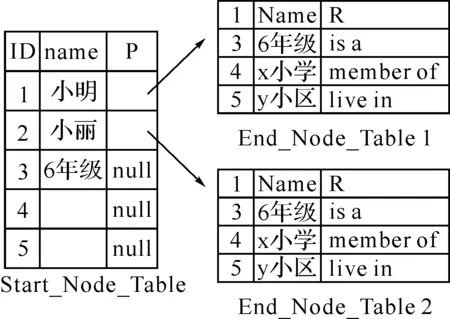
图2 关系模型
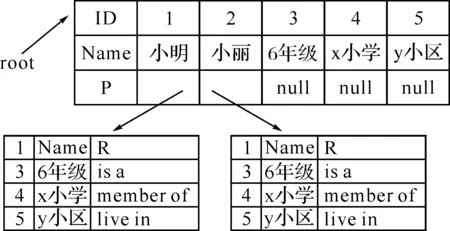
图3 关系树模型
Start_Node_Table描述了语义网络中有向边的起始节点,其属性分别为NodeID节点ID, NodeName节点名称,EndNodePointer为指向End_ Node_ Table的指针;End_Node_Table描述了语义网中有向边的终止节点,其属性分别为NodeID有向边终止节点ID, NodeName节点名称,NodeRelation为起始节点和终止节点之间的联系(包括is a, member of,live in 等).
2 查询算法描述
2.1句型模板匹配算法论文将知识库知识节点构建词典,词典中按照词性分类建表如名词表,疑问词表等,列举常见句型构成句型模板表.用户的查询从语义上分为两类:第一,求知性查询,即用户的目的是从知识库系统中获取未来知识,常用的句型如:“什么是人工智能?”,“网络协议是什么”等,第二,求证性查询,即用户已具备某些相关领域的知识,其目的是通过知识库系统对这些知识进行求证或补充,常用的句型是“计算机系统是由硬件系统和软件系统组成的吗?”等[4].句型模板的采集采用概念-属性模型:概念用C表示,如有多个概念用C1,C2,C3…表示,属性用A表示,多个属性用A1,A2,A3…表示,用A.V表示属性A的内容,用点记号表示属性A的隶属度,如概念C的属性A为C.A,其内容为C.A.V,因此查询最终归结为概念查询,概念关系查询以及概念间关联查询等,部分模板如下[5]:
<句型1>::C1,C2的属性A1,A2是什么?(查询概念的属性)
<句型2>::C的描述是什么?(查询概念的描述)
<句型3>::C和C1的关系?(查询概念间关联)
为方便论述,设Tm为最大分词阈值,T为相似度阈值,Ts为匹配成功的阈值,Wd为匹配程度,句型模板匹配算法(SM)伪代码如下:
SM算法如下:
Step1:利用模糊集方法为每一个词组i设定一个相似度阈值T;
Step2:从自然语言句首进行最大匹配分词,根据词典结构,在当前汉字开头的字串进行查找,测算当前匹配字串的相似度Ti,分词阈值为Tmi,若Tmi≤Tm且Ti≥T,则分词匹配成功;否则,调用多级相似词库,在最佳近似匹配条件下得出认为匹配的字串;
Step3:将句型的结构信息转化成查询的语义信息,利用模糊集方法与模板进行匹配,若Md≧Ts,则认定当前句型与匹配模板匹配成功,否则转向Step2.
2.2一般直接知识查询算法关系树并非树,而是结合邻接表和关系表两种存储结构,其上查询必将具有两种存储结构且兼容树型结构特点.上层为邻接表结构,下层为关系表.假设语义网络中有N个节点,每个节点建立索引号ID.一般直接知识就是能在关系树模型中查询到相应关键字的事实描述的知识,基于此查询分为两种:正向知识查询和逆向知识查询,正向即从上到下依次可查询且从自然语言提炼的关键词有终止节点,如查询过程中关键词无终止节点且需要回溯称为逆向查询,算法选取语言为C++[6],查询算法如下:
typedef struct Arcnode
{int Id; //节点ID号
char Name; //节点名称 IofoType *p,*root; //终止节点指针,根指针
}Arcnode;
void ForwardDKQ(kT &G)
{ inti,j,k,Nodenum,count1=1,count2=1,*b;
int ID[Nodenum];//定义节点Id号数组
cin>>Id>>Nodenum; //输入待查询节点Id及节点数
for(i=1;i<=G.Nodenum;++i)
cin>>ID[i];//输入所有节点Id号
while(Id!=ID[j]&&j<=Nodenum)
{++j; ++p;count1++;}//查询邻接表
if(j>=Nodenum) return false;
else cin>>Id;b=p;
while(Id! =ID[k]&&k<=Nodenum)
{++k;++b;count2++; }//查询关系表
cout< < }//正向直接知识查询算法 void BackwardDKQ(KT &G) {inti,j,ID[Nodenum],j=0,count=0; int *p[],*q; for(i=1;i<=G.Nodenum;i++) cin>>ID[i]; //输入所有节点Id号 cin>>Id>>Nodenum; //输入待查询节点Id p[0]=root; while(j<=Nodenum) {j++; if(p[j]=null) cout< while(Id!= (p[j].Id)&&k<=Nodenum) {++k; ++q; count1++;}//查询关系表 count2++; }//查询邻接表 Cout< < }//逆向直接知识查询算法 图4 “学生”词汇概念树 2.3隐含知识查询算法知识库中直接知识可以通过上述算法查询,但有的知识是隐含的不能直接查询可得,这样的知识称为隐含知识.知识库中隐含知识大致可分为两类:一类是知识库特值词汇知识,例如:“学生”一词,通常在数据库中没有“学生”这个抽象词汇,取而代之的是“小学生”,“中学生”,“大学生”等具体的词汇.另一类是知识库相关操作词汇知识,是由知识之间相关性引起的.例如:“实收入”一词,是收入减去成本所得,但在知识库中通常不会有这样的词汇(易产生数据冗余).因此,隐含知识的共性就是“抽象性”,具体解决方法为抽象化具体,即将隐含知识转化为直接知识.针对隐含知识的特殊性,采用概念树表示隐含知识(如图4). 如图4所示,将学生具体为小学生,中学生,大学生等具体词汇,因此隐含知识查询算法前步操作是转换,后步操作是直接知识查询,算法如下: Step1:将自然语言分词后查询是否有隐含词汇,若有转Step2;若没有,采用直接知识查询算法查询; Step2:查询隐含知识的概念图,表示出具体词汇以及之间的关系,查看文法规则库; Step3:输出查询结果,与当前模板匹配,将结果反馈给用户. 2.4算法分析在此主要针对正向直接知识查询算法进行分析.正向直接知识查询算法,大致思想为:通过层次遍历查询方式从上到下进行查询,返回关键词以及之间的联系.如:用户提问小明的地址是y小区吗?结果返回:小明live in y小区,后续步骤就是模板匹配,反馈给用户查询结果,该算法有效地解决了直接知识的查询.算法的复杂度为O(n2),是多项式级的,当n较大时,查询时间较长,因此在算法优化方面是今后研究的重点. 在关系模型的基础上提出了关系树模型,并基于关系树提出了正向、逆向直接知识查询算法以及隐含知识查询算法,该算法有效地解决了基于知识库中知识查询问题.由于篇幅有限,论文中存在如只列举出少量常用句型模板,句型模板匹配算法及隐含查询算法用伪代码表示,关系树模型本身的一些缺陷以及查询算法为多项式级等问题,为知识查询提出更加强大的优化算法将是今后研究的重点,并已考虑将并行计算的思想引入进来解决相关问题. [1] Dimitris N,Chorafas.Knowledge engineering[M].NewYork:Van Nostrand Reinhold, 1990. [2] 金聪,戴上平,郭京蕾,等.人工智能教程[M].北京:清华大学出版社,2007. [3] 熊冬明.汉语自动分词和中文人名识别技术研究[D].合肥:合肥工业大学,2006. [4] 唐素勤,李波,许永敏.基于句型模板的智能问答系统[J].广西师范大学学报.2007,25(2):5-8. [5] 刘军.基于短消息的知识查询系统[D].长沙:中南大学,2006. [6] 严蔚敏,陈文博.数据结构及应用算法教程[M].北京:清华大学出版社,2008.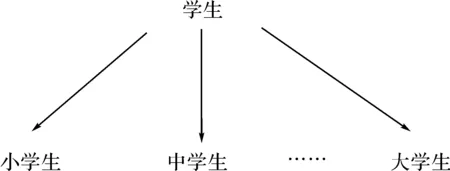
3 结论
猜你喜欢
校园英语·月末(2021年13期)2021-03-15疯狂英语·爱英语(2019年5期)2019-09-10智富时代(2019年6期)2019-07-24智富时代(2019年6期)2019-07-24制造技术与机床(2019年6期)2019-06-25中国交通信息化(2016年9期)2016-06-06高中生学习·高二版(2016年7期)2016-05-14图书馆研究(2015年5期)2015-12-07阅读与作文(英语高中版)(2013年5期)2013-05-28外语学刊(2011年3期)2011-01-22
