
基于行为减法的视频异常检测研究
2012-11-14 11:05:32袁丽雁
电子测试 2012年4期
袁丽雁
(南京邮电大学 自动化学院 江苏南京)
0 引言
当今社会,视频摄像网络无处不在。摄像视频能提供良好的时空分辨率、长捕捉范围、宽视场、低延迟。因此,大规模的摄像网络可以提供普遍、宽领域的检测。目前,面对海量的视频监控数据,智能地处理视频序列是非常必要的。例如在视频监控、安全防护领域,银行、商店、停车场等处广泛应用的摄像机,通常只是在异常情况发生后,通过视频回放查找可疑人员,无法实时报警。若能对视频中人体行为自动进行识别,则可以在事件发生时就给出提示,避免损失产生。
如图1所示[1],传统的异常检测研究的算法,需要先进行目标提取、目标跟踪等,然后在检测阶段,通过行为建模和异常检测,那些不符合已建模型的事件即被认为是异常的。该类方法的不足之处是当背景环境条件很复杂时,目标提取和跟踪变得异常困难,且要对每个物体进行跟踪,相应的计算机内存量也大。因此,本文的方法就先进行行为建模和异常检测,在后续处理阶段,需要的话,再进行目标识别和跟踪等。这样一来,不但减少了所需要的计算机内存量,对目标的识别和跟踪的准确性也增大了。

图1 异常检测传统方法与改进方法比较
所列,一些方法采用了该种新的思路形式[2-3]。 但是这些方法都将每个像素点作为独立的单位进行处理,忽视了各像素点之间的时空相关性。而这些时空相关性在消除检测误差、提高检测精确度方面有着相当重要的作用。本文提出的方法,就很好地利用了视频帧中各像素点的时空相关性。取定每个像素点的时空共生矩阵,经选取的函数计算该矩阵中像素的共生值。通过与初始化阶段获取的每一个像素点的阈值进行比较,判断该点是否为异常。虽然该方法思路简单,但是其实验性能表现良好。
1 动态检测
我们采用的动态检测的方法是建立在灰度值视频帧序列基础上的,当为彩色视频时,在程序中首先将它转换为黑白图像。令为视频序列当中的一帧,每一帧的大小为k代表离散时间,。对于异常检测,需要进行的第一步便是视频动态特征提取。许多方法可以用来提取视频动态特征[4-5],本文中采取的方法是简单的背景减除法。该方法当背景变换不频繁,前景不复杂时效果良好。当然,也可以采用文献[4-5]中的动态特征提取的方法,但是这些方法都增加了计算复杂度。
背景减除法将视频中的当前图像与背景图像相减。背景图像的获取方式有许多种,我们采用直方图统计方法直接从检测视频中提取背景图片。图2(b)所示,就是高速公路监视视频上运用直方图统计方法获得的背景图片。

图2 基于直方图统计法提取的背景
当然,为消除不同时间段光线强度对背景的影响,可以采取以下方法简单地进行背景更新:

通常,ρ的取值范围在 0.001~0.01 之间。
经过二值化操作后,动态特征提取结果是对应每一帧,产生了动态标签,1代表该像素点是前景,0代表该像素点是背景,如图2(c)所示。相较于静态事件,异常事件的发生往往是动态的,因此,我们往往忽略静态像素点,而更加关注于动态像素点,后续的动态监测正是建立在该动态标签基础上的。
2 异常检测
异常检测方法先用训练视频建立正常事件模型[6],训练视频被认为不包含异常事件,然后在检测阶段建立检测视频的事件模型,计算这些模型与正常事件模型的偏差值,当偏差值的绝对值大于阈值时,即认为该事件是异常的。正常事件建模时所采用的特征值,既可以有物体位置、速度等独立特征,又可以有与其他物体的相对位置、与背景环境的相互关系等。基于这种分类方法,视频异常事件的检测方法就可以分为3个等级了[7]:点异常检测,序列异常检测,共生异常检测。我们提出的方法就是建在第3种分类方法上的。
2.1 共生模型
设想如下情景:在高速公路上有一辆汽车在行驶,当汽车在地点A出现之后,过了一段时间,该汽车也一定会在B地点出现。这时,可以说,A、B两处发生的事件是相关的,只是经过了一段时间的延迟。通过观察现实世界,不难发现,物理世界中发生的事件在一定程度上都是彼此相关的[8],这就启发我们在进行视频异常事件检测时提供了一个很好的设计思路。
如图3所示,我们规定时刻t的帧中像素点的时空关系模型是以s= (→,t)为矩形底面中心点的Ms,该模型中Q<Q0,R<R0,T<<T0,T0代表的是视频长度。假设有个像素点,τ(t-T,t),要是r和s两者都是活跃的,即运动标签Xs=1并且Xr=1,我们就说这两个像素点是共生的。这样一来,对于Ms中的每一个像素点r≠s,都可以判定该像素点与s是不是共生的。
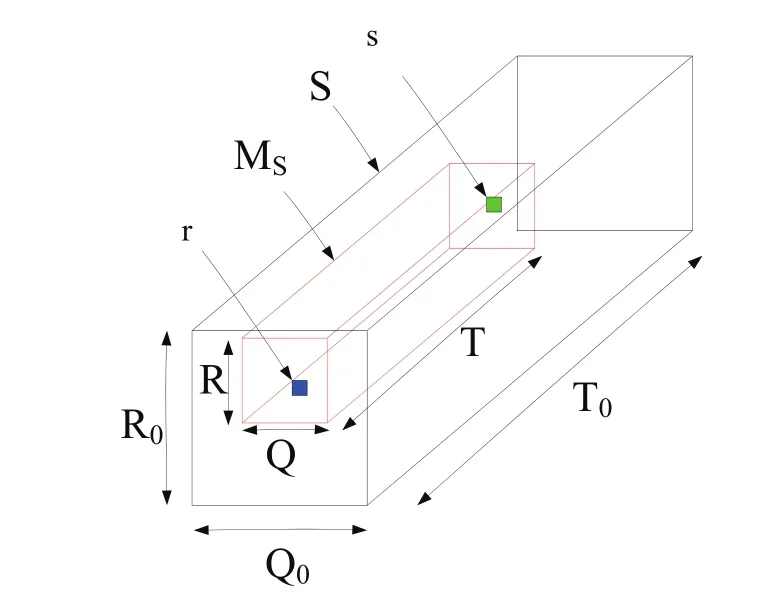
图3 三维像素点时空模型
2.2 事件模型
共生模型是基于两个像素点的,我们的事件模型就是建立在该共生模型上的。事件模型:我们感兴趣的是为每个像素点建立正常事件概率模型PN(Os) :

N代表Ms中像素点的个数,这样就能保证我们的事件概率PN(Os)取值范围在[0, 1]之间。参数αrs代表系数,可以简单地令它为常数,也可以是s点和r点之间的欧式距离,或是其他形式。采用何种方式对于我们的事件模型来说并无不同,只是提高了事件异常检测的性能。δ(Xr,Xs)当且仅当Xs=1,Xr=1。分析该模型,可以得出当Xs=0,PN(Os),这样就简化了我们建立的事件模型,当视频帧中存在大量静态像素点时,可以大大加快运算速度。
2.3 阈值比较
我们的阈值建立在正常事件概率模型基础上,每个像素点的阈值并不是常量,而是可以根据具体的检测环境的不同而自动改变。简单的说,就是在系统训练阶段,利用被认为是不包含任何异常事件的训练视频,计算各像素点阈值:

T1是训练视频长度。
确认了阈值之后,在检测阶段,若:

则我们认为该点异常,动态标签保持不变,否则令动态标签Xs=0。
3 实验结果
在实验仿真环节,选定T为10个视频帧长度,R,Q为30个像素点。采用Forward-backward MHI[9]方法,对检测到的异常物体进行简单定位与确认。介于检测视频只包含车辆,预先可以知道车辆大小的平均体积,所以当异常团块体积大小不足平均体积一半时,则认为该异常不成立。实验结果如图3所示。


图3 异常检测和结果确认
比较图3(b)和图3(c)可以发现。对应于3(c)中右上角处异常检测阶段产生的噪声,通过物体定位,应用简单的原理,即可以进行很好的确认,排除干扰。
4 结论
提出了一种直接在像素点级别上进行视频异常检测的无监督机器学习方法。与传统的视频异常检测方法相比,该方法不需要先对目标进行标签、识别、归类和跟踪,因此,需要的计算量和内存消耗较少,实时性良好。该算法充分考虑到了物理世界中事件发生的时空相关性,不是针对某一种场景,而是可以根据训练阶段的不同视频,应用到不同的环境和异常事件检测当中。
在以后的研究工作中,我们可以在物体定位的基础上,只对有异常行为的物体进行跟踪分析。现阶段,采用的视频是单摄像头视频,下一阶段,对多摄像头视频的研究也是一个重点方向。
参考文献
[1]Venkatesh Saligrama,Janusz Konrad,Pierre-Marc Jodoin.Video Anomaly Identification-A statistical approach[J].IEEE Signal Processing magzine, SEP.2010.
[2]A. Adam, E. Rivlin, I. Shimshoni,D. Reinitz.Robust realtimeunusual event detection using multiple fixed-location monitors[J].IEEE PAMI,2008,30(3):555-560.
[3]P.-M. Jodoin, J.Konrad,V. Saligrama.Modeling backgroundactivity for behavior subtraction[J].In proc. of IEEE ICDSC, 2008.
[4]J.McHugh,J.Konrad,V.Saligrama,P.-M.Jodoin.Foreground-adaptivebackground subtraction[J]. IEEE Signal Process.Lett.,2009,16(5):390-393.
[5]A.Elgammal,R.Duraiswami,D.Harwood,L.Davis.Background and foreground modeling using nonparametric kernel density for visual surveillance[J].Proc IEEE, 2002,90(7):1151-1163.
[6]Christoffer Brax,Lars Niklasson,Martin Smedberg.Finding behavioural anomalies in public areas using video surveillance data[R].Information Fusion,2008 11th International Conference on June 30 2008-July 3 2008:1-8.
[7]Fan Jiang, Junsong Yuan, Sotirios A. Tsaftaris,Aggelos K. Katsaggelos. Anomaly video event detection using spatiotemporal context[J].Computer Vision and Image Understanding115 (2011) :323-333.
[8]Y.Benezeth,P.-M.Jodoin,V.Saligrama,and C.Rosenberger.Abnormal events detection based on spatio-temporal co-occurrences[J].in Proc.IEEE Conf.Computer Vision Pattern Recognition,2009:2458-2465.
[9]Zhanzheng Yin,Robert Collins.Moving Object Localization in Thermal Imagery by Forwardbackward MHI[J].in Computer Vision and Pattern Recognition Workshop, 17-22 June 2006:133-133.
E-mail:yuanliyan123@163.com
猜你喜欢
四川党的建设(2022年8期)2022-04-28 21:29:35
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
小学生作文(低年级适用)(2020年10期)2020-11-10 09:12:12
中国建筑装饰装修(2020年6期)2020-07-10 09:41:16
福建基础教育研究(2019年2期)2019-09-10 07:22:44
福建基础教育研究(2019年2期)2019-05-28 08:39:49
作文大王·低年级(2018年10期)2018-12-06 06:22:44
电脑知识与技术(2018年35期)2018-02-27 13:29:44
自动化学报(2017年11期)2017-04-04 02:52:44
小猕猴智力画刊(2016年5期)2016-05-14 09:21:39
