
二进制本原BCH码的参数盲识别
2012-11-07 07:15:35王兰勋李丹芳汪洋
河北大学学报(自然科学版) 2012年4期
王兰勋,李丹芳,汪洋
(河北大学 电子信息工程学院,河北 保定 071002)
二进制本原BCH码的参数盲识别
王兰勋,李丹芳,汪洋
(河北大学 电子信息工程学院,河北 保定 071002)
针对BCH码的盲识别问题,提出一种基于欧几里德算法的最大公因式的识别方法.首先,根据循环移位码字求取最大公因式,得到最大公因式的系数矩阵.然后,分析最大公因式的次数分布规律确定码长,由系数矩阵求出生成多项式.该识别方法简单易行,无繁杂的矩阵运算.理论分析及仿真实验表明,无误码时使用较小的数据量就可有效识别;误码率为10-2,数据量足够时,识别效果仍然较好.
BCH码;欧几里德算法;最大公因式;盲识别
信道编码盲识别是一个全新的领域,其主要应用在信息对抗、协作通信以及自适应调制编码技术(AMC)等领域.据现在公开发表的文献来看,大部分文献集中在卷积码的盲识别上,较少研究线性分组码的盲识别.文献[1]建立了一种线性分组码的识别模型,是在无误码条件下的全盲识别,但其分析所需数据量会随码长估值的扩大急剧增大,导致其实用意义不大.文献[2]则对该方法做了一定的改进,大大减少了样本数据量,提高了实用性,并将其应用于工程实践中.文献[3]根据码重分布估计码长,进而通过矩阵化简得出生成矩阵,该算法对低码率二进制线性分组码有较好的识别效果.文献[4]在文献[3]的基础上先识别出码长,再根据码字与校验矩阵的校验关系识别出生成多项式.文献[5]用经典的BM算法求解循环码的盲识别模型,算法较复杂.文献[6]采用秩统计的方法识别出码长,再用统计的方法获取生成多项式的根,进而得到生成多项式,识别繁琐,计算量较大.文献[7]根据码根信息差熵识别码长,并采用码根统计的方法识别生成多项式,同样所需数据量较大.
本文针对本原BCH码的特殊性质,结合欧几里德算法,提出一种新的识别方法.该方法识别原理简单,并具有较好的容错性,经实验验证在无误码较少的数据量时可达到识别的目的,有误码数据量足够时,仍有较好的识别效果.
1 BCH码识别基础
定义1[8]给定任一有限域GF(q)及其扩域GF(qm),其中q是素数或素数的幂,m为某一正整数.若码元取自GF(q)上的一个循环码,它的生成多项式g(x)的根集合R中含有以下δ-1个连续根:

时,即则由g(x)生成的循环码称为q进制BCH码.通常取m0=1,如果生成多项式g(x)的根中,有一个GF(2m)中的本原域元素,则n=qm-1,当q=2时,称这种码长n=2m-1的BCH码为二进制本原BCH码.
二进制本原BCH码具有的性质:
1)循环性.循环性是指任一码组循环移位以后,仍为该码中的一个码组.
2)所有码多项式T(x)都是g(x)的倍式.可写成

本文所用欧几里德算法是用于搜寻二元域上的多项式c(x)和c′(x)的最大公因式d(x),即方程

如何找到d(x)是本文研究的重点.
定理1 设c(x)和c′(x)是二元域上的2个多项式,则有唯一的一对二元域上的多项式q(x)和r(x),具有下面的性质:

其中r(x)的次数小于c′(x)的次数,叫余式.
该定理也叫做欧几里德除法定理.其中q(x)就是除法中的商式,r(x)是c(x)除以c′(x)所剩的余式,定义(c(x),c′(x))为c(x)和c′(x)的最大公因式.经典的欧几里德算法即不断利用定理1作除法可得下列:
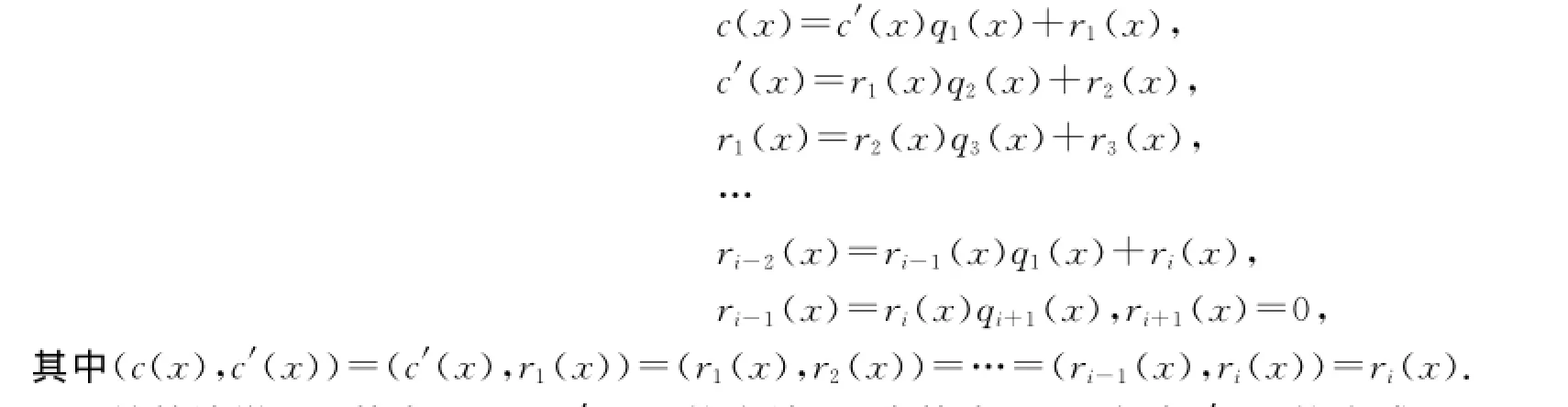
该算法说明了找出(c(x),c′(x))的方法,即先找出c(x)除以c′(x)的余式r1(x),再找出c′(x)除以r1(x)的余式r2(x),依此类推找出rj-1(x)与rj(x)的余式rj+1(x),直到余式为0.因为以上多项式均是二元域上的多项式,所以式中的运算均为模二运算.BCH码多项式的欧几里德算法可以用辗转相除的方法来实现[9].
当截获码流后,根据帧同步的信息很容易确定BCH码的起始点,所以本文的识别研究是在起始点已知的条件下进行的,这也是符合实际情况的.
2 识别方法
本文提出的识别方法是利用欧几里德算法计算循环移位前后2个码字多项式的最大公因式d(x).因为循环码的每个码字均是生成多项式的倍式,所以它们的最大公因式是生成多项式或生成多项式的倍式,由仿真实验分析得出码长n和生成多项式g(x).下面对该方法进行详细描述.
2.1 数学公式描述
BCH码的编码数学模型为

其中c(x)为码字多项式,m(x)为信息多项式,g(x)为生成多项式.实际应用中,c(x)为接收或截获的码流,在不知道任何编码参数的情况下通过识别方法获得g(x),进而得到该码流携带的信息m(x).
2.2 基于欧几里德算法的识别原理
因任一BCH码多项式c(x)都是g(x)的倍式,所以同一码组中2个BCH码多项式的最大公因式不是g(x)就是g(x)的倍式.而若假设c(x)是BCH码的一个码组,所以c(x)循环移位m次的结果c′(x)也必为该码中的一个码组.根据这一性质结合欧几里德算法计算出最大公因式d(x),进而通过数据分析得到g(x).
首先,截获一段BCH码码流,遍历m,对于二进制BCH码m通常取3到8.然后,由n=2m-1对码流分组,得到码字矩阵,将码字矩阵循环移位m次,运用文中介绍的欧几里德算法计算循环移位前后码字的最大公因式d(x),得到最大公因式的系数矩阵,进而求出d(x)的次数∂0(d(x)),用matlab仿真∂0(d(x))的分布图.若m选取正确,即n正确,d(x)的次数大部分大于某一数值,即次数阈值.这个阈值就是生成多项式的次数,因为最大公因式不是g(x)就是g(x)的倍式,所以大部分∂0(d(x))是大于或等于∂0(g(x))的;若m选取错误,d(x)的次数分布无此规律,大小不均.在m选取正确时,获取码长n,得到d(x)的系数矩阵,并记录次数阈值,以及该阈值对应的最大公因式,分解这个公因式,具有连续根的因子就是生成多项式g(x).至此,完成识别.
综上所述,二进制本原BCH码的识别流程如图1所示.

图1 BCH码识别流程Fig.1 Recognition flow of BCH codes
3 仿真验证及分析
采用上述识别方法,分别在无误码和有误码的情况下进行实验仿真.本文以(15,5)的二进制本原BCH码为例.
3.1 无误码识别
在无误码的条件下,获取一定数据量的码流,遍历m=3~8,采用欧几里德算法计算BCH码字与循环移位m次的码字的最大公因式,如码字c=[010011011100001],向右循环移四位得c′=[000101001101110],通过辗转相除的方法实现欧几里德算法,得最大公因式d(x)=r6(x),如图2所示.用matlab编程实现欧几里德算法并仿真d(x)的次数分布,得图3和图4分别是当m=3和m=4时取100组码字进行实验的仿真图.由图3和图4比较可明显看出当m=3时,最大公因式的次数分布无规律性,在0,1,2,3,4,5均有分布;而m=4时,最大公因式的次数100%在10以上,且分布在10和11的居多,有明显的规律性,10即为次数阈值,则码长n=24-1=15.截取部分最大公因式的系数矩阵如图5所示,d(x)次数为从序列最右边第1个1数到最左边1所在的位置,从0开始计数.选取次数最小的最大公因式10100110111进行因式分解,取有连续根的因式,得,与题设相符,识别正确.

图2d(x)计算Fig.2d(x)algorithm

图3m=3时100组最大公因式的次数分布Fig.3 Times distribution of the greatest common factors of 100 groups whenm=3
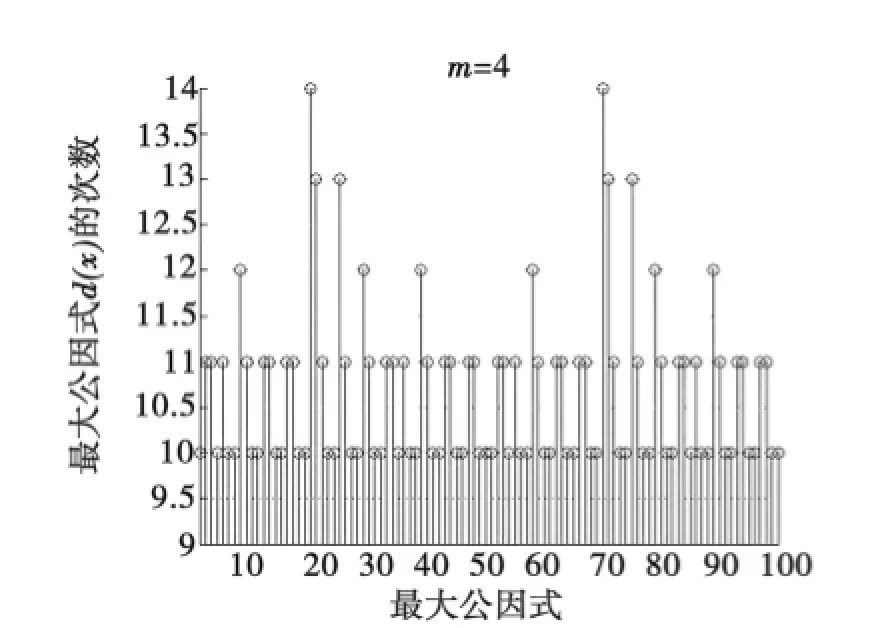
图4m=4时100组最大公因式的次数分布Fig.4 Times distribution of the greatest common factors of 100 groups whenm=4

图5 前20组最大公因式的系数矩阵Fig.5 Top 20 coefficient matrix of the greatest common factors
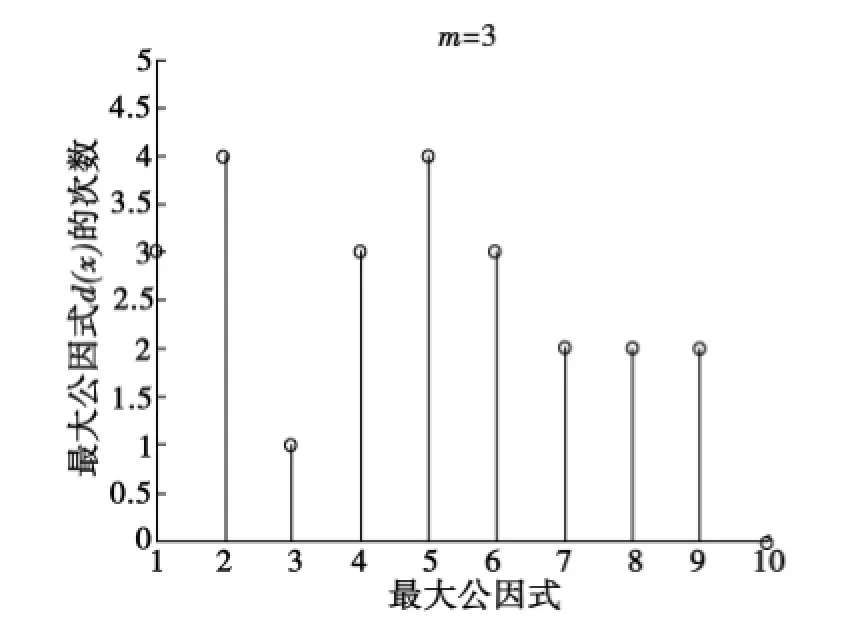
图6m=3时10组最大公因式的次数分布Fig.6 Times distribution of the greatest common factors of 10 groups whenm=3
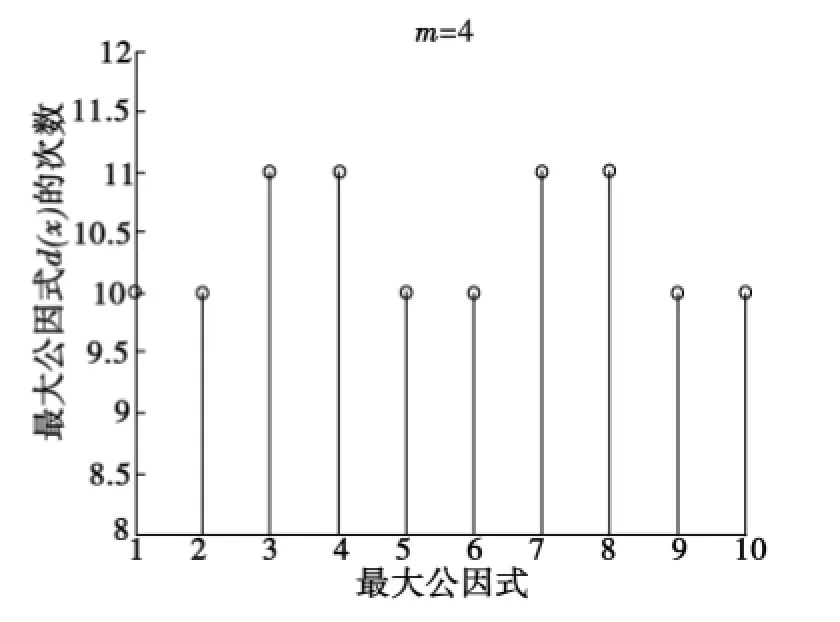
图7m=4时10组最大公因式的次数分布Fig.7 Times distribution of the greatest common factors of 10 groups whenm=4
取10组码字仿真验证,图6和图7分别为m=3和m=4时最大公因式的次数分布图.由图6和图7比较,用同样的方法分析,也可看出m=4时最大公因式的次数分布均在10以上,取次数为10的最大公因式也可求出g(x);而m=3时次数在0,1,2,3,4均有分布,不满足规律性.所以在较少的数据量时本文的识别方法也有效.
3.2 有误码识别
信道误码率分别为1×10-3和1×10-2时,取100个码组的数据量.遍历m=3~8进行仿真,得m=4时公因式的次数分布分别为图8和图9(m=3,5,6,7,8略).
由图8可见,在误码率为1×10-3时最大公因式的次数98%均在10以上,且大部分分布在10和11,通过d(x)的系数矩阵取出次数为10的最大公因式,经验证其因子有连续根,为所求生成多项式;由图9可见,在误码率为1×10-2时最大公因式的次数81%均在10以上,且大部分分布在10和11,同样的方法得到生成多项式.若取出的10次多项式不能分解出有连续根的因子,则进行多次选取,保证识别的正确率,所以在较高的误码率下该识别方法可达到正确识别的目的.

图8m=4,pe=1×10-3时100组最大公因式的次数分布Fig.8 Times distribution of the greatest common factors of 100 groups of whenm=4 whenpe=1×10-3
对比无误码和有误码的识别仿真图,根据理论分析可知,在无误码的条件下,当m选取正确时,移位前后所求最大公因式的次数均大于等于生成多项式的次数;当选取的m对应最大公因式次数为零时说明移位前后码字互素,不满足BCH码的性质,与码长n直接相关的参数m选取的不正确,舍弃该m值.这一结论简化了无误码条件下的BCH码的盲识别;在有误码时,则需根据最大公因式的次数分布规律,分析是否存在次数阈值来判断该m值选取的正确性,若存在次数阈值,m选取正确,反之,不正确.

图9m=4,pe=1×10-2时100组最大公因式的次数分布Fig.9 Times distribution of the greatest common factors of 100 groups ofmwhenpe=1×10-2
4 结论
本文对二进制本原BCH码参数盲识别提出了一种方法,该方法是基于欧几里德算法,求取最大公因式系数矩阵,并分析最大公因式的次数分布规律,进而识别出本原BCH码的码长和生成多项式.此盲识别算法,识别原理简单易行,避免了繁杂的矩阵运算,识别过程简单.仿真实验结果表明,在无误码时用较少的数据量就可达到识别的目的,在误码率为pe=1×10-2时也具有较好的识别效果.
[1] 薛国庆.卷积码的盲识别研究[D].合肥:中国科学技术大学,2009.
XUE Guoqing.Blind identification of convolutional codes[D].Hefei:University of Science and Technology of China,2009.
[2] 陈金杰,杨俊安.无线数传信号编码盲识别与解码技术研究[J].电子测量与仪器学报,2011,25(10):905-910.
CHEN Jinjie,YANG Junan.Research on blind recognition for wireless digital transmission signals encoding and decoding technology[J].Journal of Electronic Measurement and Instrument,2011,25(10):905-910.
[3] 昝俊军,李艳斌.低码率二进制线性分组码的盲识别[J].无线电工程,2009,39(1):19-24.
ZAN Junjun,LI Yanbin.Blind recognition of low code rate binary linear block codes[J].Radio Engineering,2009,39(1):19-24.
[4] 闫郁翰.循环码的盲识别[J].电子科技,2011,24(3):112-114.
YAN Yuhan.Blind recognition method for the cyclic code[J].Electronic Science and Technology,2011,24(3):112-114.
[5] 刘菁.卷积码和循环码识别技术研究[D].西安:西安电子科技大学,2010.
LIU Jing.Research on recognition technology for convolutional codes and cyclic codes[D].Xi'an:Xidian University,2010.
[6] 闻年成,杨晓静.采用秩统计和码根特征的二进制循环码盲识别方法[J].电子信息对抗技术,2010,25(6):26-29.
WEN Niancheng,YANG Xiaojing.Blind recognition of cyclic codes based on rank statistic and codes roots characteristic[J].E-lectronic Information Warfare Technology,2010,25(6):26-29.
[7] 杨晓静,闻年成.基于码根信息差熵和码根统计BCH码识别方法[J].探测与控制学报,2010,32(3):69-73.
YANG Xiaojing,WEN Niancheng.Recognition method of BCH codes based on roots information dispersion entropy and roots statistic[J].Journal of Detection,2010,32(3):69-73.
[8] 王新梅.纠错码-原理与方法[M].西安:西安电子科技大学出版社,2002.
WANG Xinmei.Error correcting code-principles and methods[M].Xi'an:Xidian University Press,2002.
[9] 戚林,郝士琦,王磊,等.一种RS码快速盲识别方法[J].电路与系统学报,2011,16(2):70-76.
QI Lin,HAO Shiqi,WANG Lei,et al.A fast blind recognition method of RS codes[J].Journal of Circuits and Systems,2011,16(2):70-76.
(责任编辑:孟素兰)
Blind recognition of binary primitive BCH codes parameters
WANG Lan-xun,LI Dan-fang,WANG Yang
(College of Electronic and Informational Engineering,Hebei University,Baoding 071002,China)
A recognition method based on Euclidean algorithm is proposed to solve the problem of the blind recognition of BCH code.First,according to the cycle shifting code,a greatest common factor is achieved and many common factors constitute a coefficient matrix.Moreover,the times distribution of the greatest common factors were analyzed and the code length was obtained and polynomial generated by coefficient matrix.The recognition method is simple,and the fussy calculation of matrices is avoided.Both theoretical analysis and simulation results show that using fewer data can recognize effectively in no error and the recognition has better performance in BER.
BCH code;Euclidean algorithm;the greatest common factor;blind recognition
TN911.22
A
1000-1565(2012)04-0416-05
2012-01-10
河北省自然科学基金资助项目(F2009000224)
王兰勋(1956-),男,河北安平人,河北大学副教授,主要从事数字通信与信息编码方面研究.E-mail:wanglanxun@yahoo.com.cn
猜你喜欢
合肥工业大学学报(自然科学版)(2023年10期)2023-10-31 13:47:36
系统工程与电子技术(2022年2期)2022-02-23 07:49:16
数学年刊A辑(中文版)(2019年4期)2019-12-16 09:09:18
人大建设(2017年8期)2018-01-22 02:04:31
山东理工大学学报(自然科学版)(2018年2期)2018-01-16 03:32:21
中华诗词(2017年10期)2017-04-18 11:55:24
大众电视(蓝天下)(2016年8期)2017-01-15 13:38:52
黑龙江生态工程职业学院学报(2013年1期)2013-12-30 07:49:00
山东理工大学学报(自然科学版)(2013年5期)2013-12-18 06:58:42
佳木斯大学学报(自然科学版)(2012年5期)2012-09-27 14:26:14
