
MUMF-支持单多播公平服务的调度策略
2012-11-06 11:39扈红超郭云飞陈庶樵伊鹏
通信学报 2012年1期
扈红超,郭云飞,陈庶樵,伊鹏
(国家数字交换系统工程技术研究中心,河南 郑州 450002)
1 引言
以应用和服务为特征的网络承载网的发展使得网络业务呈现多元化的发展趋势,视频点播、VoIP等为特征的多媒体及相关技术(如 P2P)成为了下一代互联网(NGI, next generation internet)和三网融合下网络业务的典型特征之一。多媒体业务的重要特征是具有多播性,相对于单播业务<源s-目的d>一对一的传输,多播业务存在多个目的,这一特征要求网络核心交换节点能够支持多播交换,从而提高网络传输效率和吞吐量[1,2]。就现有交换机制而言,输出排队(OQ,output queuing)交换结构交换和存储单元都需工作于N倍线路速率,构建大容量交换系统时不具备良好的扩展性;输入排队(IQ, input queuing)交换结构需要集中式的调度[3],构建大容量交换系统时存在瓶颈。近年来随着微电子技术的进步,在交换单元内部集成一定容量的缓存成为了现实,基于带缓存交叉开关构建的联合输入交叉节点排队(CICQ, combined input-crosspoint queuing)交换结构备受关注[4]。CICQ通过在每个交叉点集成了一定的缓存将N×N的交换结构分割为N个N×1和N个1×N的子结构,并将输入、输出的带宽冲突隔离开来,使分布式调度成为了现实。目前基于 CICQ构建的调度机制集中在提供高吞吐量[5~11]、模拟 OQ[12~14]和性能保障[15~17]和多播交换[18~20]方面。
在 CICQ交换结构的多播研究方面,文献[18]分析了(K,Na)- c omplex 多播流量模型下CICQ的吞吐量,指出当加速比S有限时吞吐量随交换结构规模N→∞大幅下降;在均匀“可允许”到达下,当 S > 1 和交叉点缓存容量时交换系统是稳定的,为更好地理解CICQ多播交换机制奠定了基础。单多播轮询调度 (MURS, multicast and unicast round robin scheduling) 策略[20]根据轮询优先级的不同可细分为单播优先(MURS_uf)、多播优先(MURS_mf)和混合轮询(MURS_mix)算法。同IQ结构相比较,MURS大幅提升了交换系统的时延和吞吐量性能。基于输出的共享交叉点缓存O-SMCB (output-based shared-memory crosspoint- buffered)调度机制[21],在“可允许”均匀和“对角”多播流量到达下,O-SMCB可在节省50%的缓存条件下提供接近100%的吞吐量性能。
当前基于CICQ构建的多播调度策略主要集中在如何提高系统的吞吐量和时延性能,尚无工作着眼于单多播混合调度的公平性问题。本文在这一方面进行了探索,提出支持单多播混合公平性的理想调度——(MUMF, mixed uni-and multicast fair scheduling) 模型,MUMF调度算法采用基于时间戳(timestamp)的调度机制,通过输入调度和交叉点调度确保单多播流的公平性。针对其复杂度过高,提出了改进调度算法 MUMF。MUMF调度算法每个输入、输出可独立进行变长分组交换,无需加速便可为流提供时延和公平性保障。本文剩余章节安排如下:第2部分是相关工作;第3部分详细阐述了MUMF和MUMF交换机制;第4部分对MUMF调度算法的性能进行仿真评估;第5部分是结束语。
2 相关工作
现有公平服务调度策略的研究主要集中在如何在共享输出链路的单播竞争流之间提供公平服务,具体而言,若K条流 F = { f1, f2, … ,fK}共享输出带宽为 R的链路 L,流 fk的预约带宽为 rk,且调度器 s根据 r为每条流 f计算权重kkwk表征其归一化需求带宽,即。设Wk,s(t1, t2)为调度器 s下[t1, t2) 间隔内流 fk获得的服务量,理想的公平服务调度器 s满足然而,受硬件处理器处理机制和分组处理系统特性的限制,实际调度系统无法达到这一目标。最坏服务公平指数(WFI,worst-case fairness index)[22]和比例服务公平指数(PFI, proportional fairness index)[23]是衡量实际交换系统调度器公平性的重要指标。用 fik表示到达交换系统输入端口i的第k条多播流,目的输出端口集合为 oik,预约带宽为rik,Wikj,s(t1, t2)表示[t1, t2)内调度策略s下输出端口 j ∈oik为流fik提供的服务量,理想公平多播调度器满足)。若
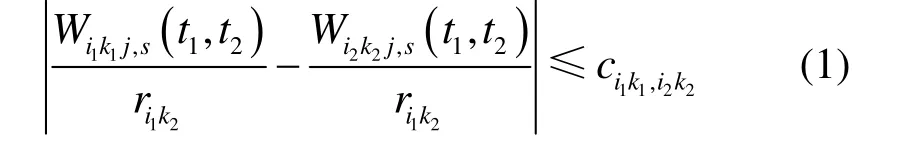
则称交换系统在调度策略 s下能够为多播流提供PFI公平性。
由于受Crossbar输入和输出带宽竞争的双重约束,基于共享链路的调度策略无法直接应用到基于虚拟输出排队的 IQ或者 CICQ交换结构中。MFS(multicast fair scheduling)[24]为每个输入端口分配一份额计数器 ci记录该端口获得的调度份额,并为每个分组分配一到达时间戳,同时分两级对多播进行调度:首先输入端口选择具有最小虚拟时间戳的流 k : min Vik(t)作为该端口的候选流,其中,Vik(t)为端口i第k条流的虚拟时间;其次,选择输入端口i:进行调度,其中,Bik为端口i第k条流的预约带宽。MFS能够在高负载下提供良好的公平性。CMF(credit based multicast fair schedul-ing)[25]依据预约带宽 rij(t)为每个输入、输出对计算一可用份额 cij(t)和累计调度差额 Aij(t)。在Request阶段选择 Aij(t) > 0 和具有最小到达时间的分组,而Grant阶段选择具有最大 Aij(t)的分组。CMF将多播分组复制为单播分组并采用逼近GPS的调度策略,获得了较低的相对时延和公平性。
由于 IQ结构集中式的调度机制无法构建大规模交换系统,导致MFS和CMF在实际应用中受到限制。此外,CICQ结构还受到交叉点队列的竞争约束,因而MFS和CMF也无法直接应用到CICQ结构中,然而它们为CICQ混合公平调度策略的设计提供了重要思路。另外,虽然针对单播调度公平性的研究成果相对较丰,然而多播分组具有多个可选目的输出端口,必须采用适用于多播的公平调度策略和公平性评价基准,且采用扇出分割和不分隔的调度策略对性能有较大影响,因而适用于单播的公平调度策略也无法直接应用到混合调度中。下面首先介绍MUMF调度策略。
3 MUMF混合调度策略
3.1 交换系统模型
图1给出了NN×规模的支持单多播混合调度的CICQ交换系统总体结构。为解决分组的队头阻塞(HOLB, head of line blocking)问题,采用虚拟输出队列(VOQ, virtual output queuing)排队机制,为单/多播分组分别维护了独立的单/多播虚拟输出队列{U VQij}和{M VQim}。对于单播分组,采用N个虚拟输出队列可完全避免队头阻塞;对于多播分组,理论上需要在每个输入端口i维护2N- N -1个MVQim队列。为此,必须通过设计有效的分组入队机制(QM, queuing mechanism)降低多复制端口的队头阻塞,在每个输入端口维护 M (M <2N-N-1)个MVQim队列;经输入复制后进入Crossbar的多播分组仅存在单一输出端口,因而仅需在每个交叉点维护一交叉点单/多播虚拟输出队列。为防止UXBij( M XBij)溢出,为每个 U XBij(M XBij)维护一流控状态信号 siuj ( simj)。假定到达各输入的分组定长,标记为cell。以线路速率R传输一个cell的时间称为一个时隙(slot)。
3.2 理想调度模型
要实现单多播混合调度的短时公平性必须为输入端口i的所有多播流{fm}分别维护独立的虚ik拟多播输出队列并采用变长分组交换机制以逼近GPS系统。参考图 1,则此时多播缓存队列数目M = K,其中,K为端口i多播流数,因而队列缓存维护复杂度为 O (K )。最新研究成果表明,虽然internet骨干网络同时存在的流可达几十万甚至上百万,然而同时处于活动状态的流仅为上万条[26]。用rikm表示到达输入端口i的第k条多播流的预约带宽,则去往输出j的多播流的汇聚预约带宽和输入端口 i的多播流汇聚预约带宽分别为去往输出端口j的单播和多播业务流的累积预约带宽为。对累积预约带宽 r (t)进行归ij一化可得
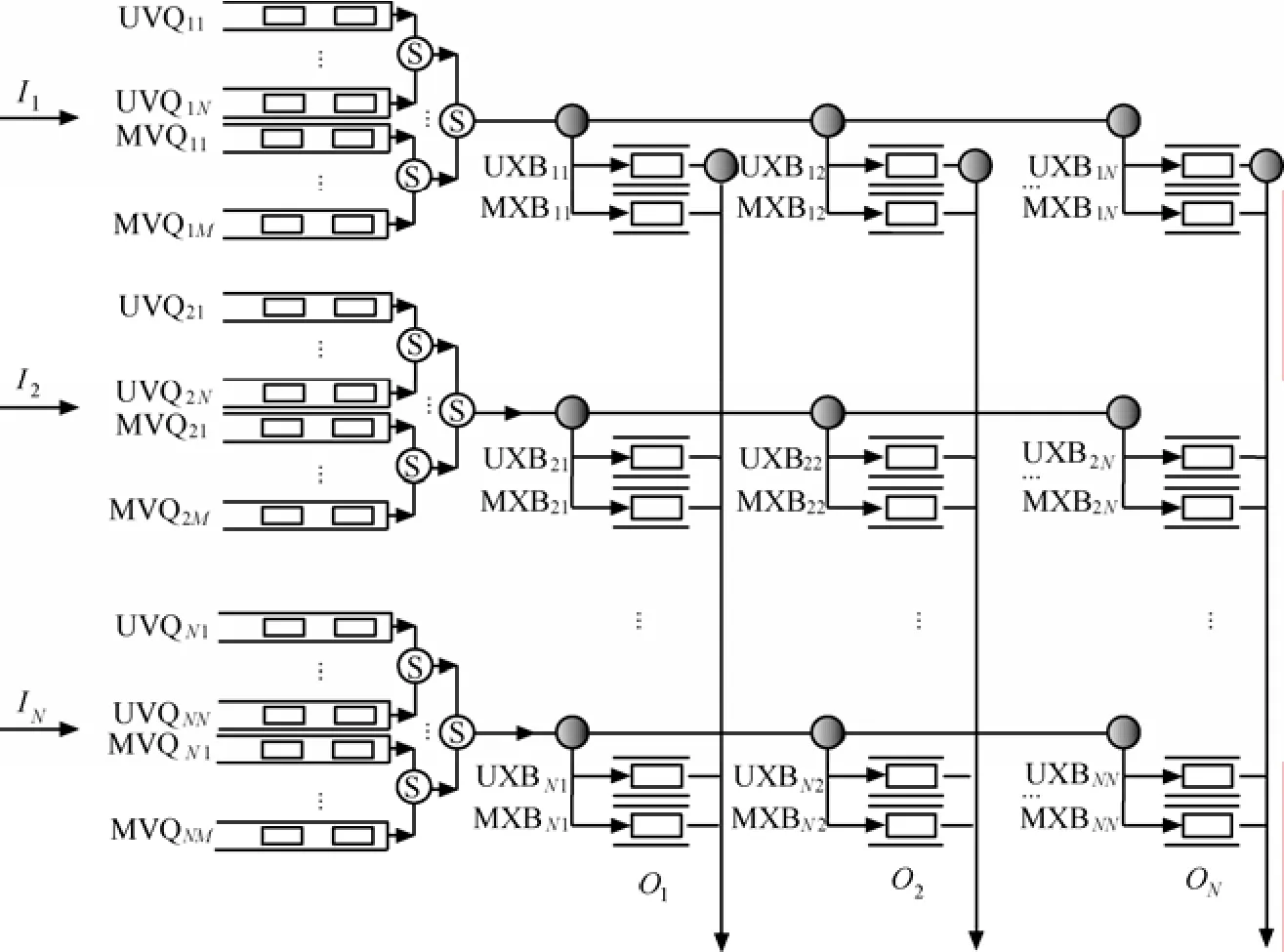
图1 MUMF交换系统总体结构

且 ωij(t )满足

为了便于描述,首先给出本文用到的以下相关术语和缩略语,如表1所示。

表1 相关符号定义
定义 1 积压队列(backlogged queue)称时刻 t> 0 ,并称t时刻为积压流,记t时刻积压流集合为 Bij(t )。
定义 2 事件(event)称分组到达/离去调度器 s为一次事件,用e表示,第n次事件 en发生的时刻用 tn表示,可见在 [tn, tn+1)的时间间隔内汇聚流 fij的积压流 Bij(t )不变化。

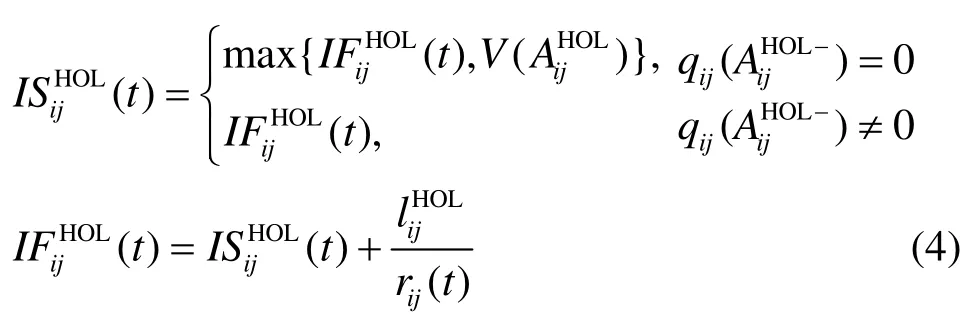

可见,最坏情况下 I Si需从 N个队头分组中选N给定时,其复杂度 O ( lo g N )为较小常量值。当输出 j确定后, I Si再从流集合 fij中选择一单播或多带宽,到达输入i、去往输出j的流归一化汇聚带宽为,则单多播的虚拟时间V′(t)计算为或者多播流)队首分组的虚拟开始时间。令t时刻

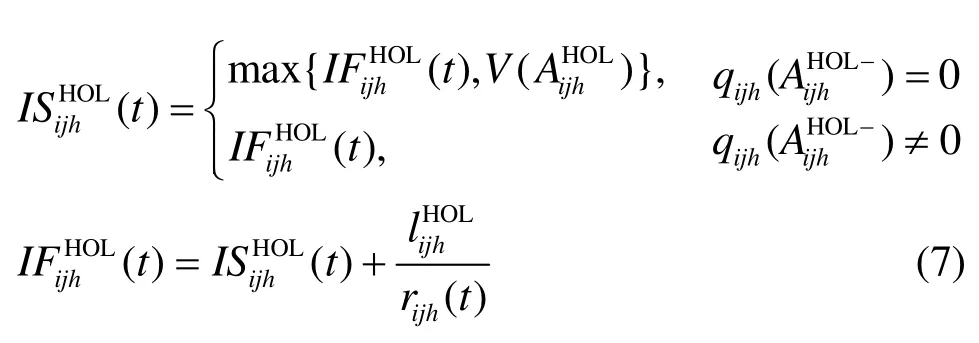
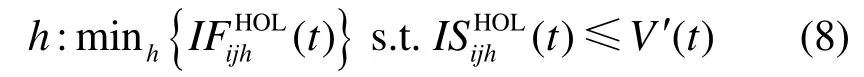
其中, qijh(t)为时刻 t流 fijh对应虚拟输出队列系统虚拟时间V′(t)且具有最小虚拟完成时间叉点队列 U XBij( M X Bij)。可见,I Si采用了层次化调度策略确保单多播混合调度的公平性和去往不同输出端口分组的公平性。



3.3 MUMF交换机制
MUMF交换机制由分组入队机制(QM)、输入端口调度(IS)器和交叉点调度(CS)器构成,其中QM调度机制将到达的多播分组根据目的端口进行映射和入队。下面详细描述各模块。
3.3.1 入队策略(QM)
用 Q (⋅)表示分组入队策略, Q (⋅)可描述为:给定分组c及其目的端口集合,确定c的入队队列{U VQij} 或{M VQim}, 其中为目的端口数。单播分组(U = 1)由于采用虚拟输出队列可完全避免分组的队头阻塞,因而即分组入队到UVQiop。对于多播分组,若分组序列1{ p0, p1,… ,pn,…}的输出端口数为U(U≥ 2 ),则理论上需要在每个输入端口维护 CUN个 M VQim队列;而对于给定最大输出端口数 Umax的分组序列{ p0, p1,… ,pn,…},要完全避免队头阻塞问题,理论上需要在每个输入端口维护个MVQim队列,实现起来过于复杂。为此必须设计有效入队机制降低队头阻塞概率,本文采用最小覆盖调度(MCD, minimum cover dispatching)算法。RN的求和向量,称向量序列为的一个覆盖,xj= 0 或者1,若满足:

其中,“⊕”为异或算子。可以看出,N维求和向量是自身的一个覆盖。最小均衡覆盖。

首先假设输入端口i维护的 M VQim队列数目为M, MCD算法工作过程如下。
2) 根据新到达分组p的目的端口集合 Op将其表达成分组标识向量其中xj=1,若 j ∈Op,否则xj=0。
3) 将分组 p按照如下规则入队到第 mo个多播虚拟输出队列 M VQimo:
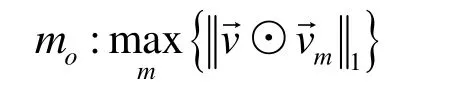

确保不同输出端口间流的公平性,I Si为汇聚流 fij,按照式(13)计算调度更新份额 σij( t ):

在每次调度时, I Si首先更新累积调度份额:端口j的多播队头分组集合,记依据队头分组集合索引结果为。 I Si输入调度过程如算法1所示。
算法1 MUMF输入调度过程
ISi调度过程


记 I Si选择分组为p,}。若p为单播则根据目的端口传输到交叉点队列 U XBij,更新;否则,根据扇出集合 op复制到并更新
3.3.3 交叉点调度(CS)
MUMF交叉点调度根据单播累积份额 Wiju(t)、Wij(t)和多播累积份额 Wijm(t)、Wij(t)从集合 X Bj选择交叉点队列。同理记输出j对应的交叉点调度器为 C Sj。记输出端口 j对应的单播累积份额多播累积份额降序排列后对应的索引,为对降序排列后队长, limj(t)为t时刻多播交叉队列的队长。调度器ISi首先根据 Wju(t)和 Wjm(t)确定单多播流调度的公平性,再根据 φ ′和 φ ′确定各输入端口间的公平性,如算法2所示。
算法2 MUMF交叉点调度过程
CSj调度过程


可见,MUMF交叉点调度首先选择至当前时刻t单多播业务已获得的服务和预约服务之间的差额(Wju(t)和 Wjm(t))中的较大者对应的业务类型(说明该类业务类型与预约带宽之间的差距更大),然后再从对应业务类型中选取具有最大累积份额(Wiju(t)或 Wijm(t))的单/多播分组。
4 仿真实验
本节从时延、带宽分配的公平性和吞吐量3个方面对 MUMF算法的性能进行仿真评估。实验采用 C++开发的交换系统性能仿真评估系统(SPES,switching performance evaluation system)[27]。SPES仿真实验环境配置如下:交换结构的规模为16×16;输入、输出端口的带宽归一化为1;流量到达过程采用贝努利(Bernoulli)和突发(burst) 2种业务源[27];流量分布模型采用均匀业务流分布模型。用λi标识输入端口i的流量到达强度,且∀i , j,λi= λj, 单 多 播 业 务 比 例 分 别 为 α 和β(α + β=1)。假设每个单播分组具有相同的扇出分割数Φ,本文仅研究“可允许”到达过程,即
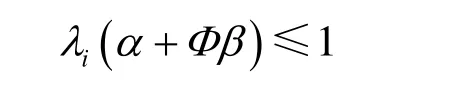
记λ= λi(α+ Φβ),用λij表示到达输入端口i、去往输出端口j的流量速率,则对于均匀流量到达分布:,且单播和多播混合下的到达速率和为

4.1 时延性能
本节分2种情形分析MUMF调度算法的时延性能:情形1),单多播流量混合下MUMF调度算法的时延性能,设置扇出端口为 4,单多播流量比例4αβ=,改变λ使其从0.1~1.0之间变化考察单多播分组平均时延大小;情形2),单多播业务混合条件下MUMF调度算法的时延性能,设置扇出端口为4,考察在不同单多播流量比例αβ下,改变λ使其从0.1~1.0之间变化考察单多播分组平均时延大小。
图2给出了情形1)流量到达下MUMF调度算法的时延性能仿真结果。可以看出,与MURS_mix相比较MUMF调度算法的性能更优。图3给出了情形2)流量到达下,多播比例分别为10%、20%和30%时MUMF调度算法的平均时延性能。可见,随着多播流量比例的增加,单多播分组的平均时延不断增大,这是由于多播流量增加相应增大了队头分组阻塞的概率。
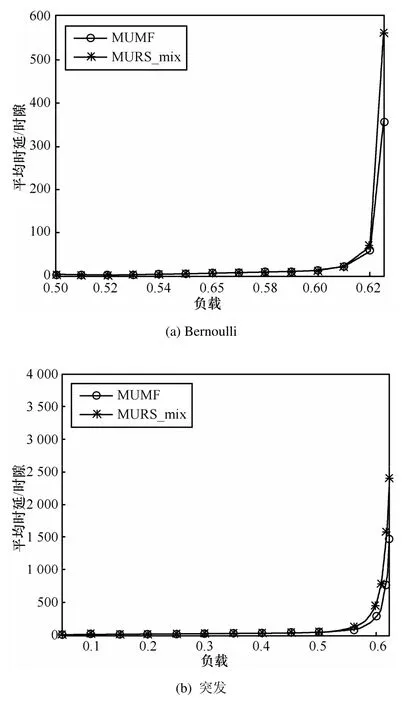
图2 情形1)混合流量到达下分组的平均时延性能

图3 情形2)混合流量到达下分组的平均时延性能
4.2 公平性能
公平性能评估采用Bernoulli和突发2种流量模型,为了便于分析,采用4×4规模的交换结构,设置每个多播分组的扇出端口数为 4,即每个多播分组产生4个输出端口。分2种情形进行评估:

情形2),单多播比例αβ=1,预约带宽


首先考察情形1)流量到达下MUMF调度算法的公平性能仿真结果,如图4所示。图4分别给出了 Bernoulli和突发业务源下各输入端口获得输出端口1的调度带宽,其中, Wiju(Wijm
)分别表示输入端口 i接受输出端口 j提供的实际单播(多播)服务量。可以看出,无论是在Bernoulli还是突发业务流量到达下,各输入端口多播均获得正比于预约带宽的实际带宽。
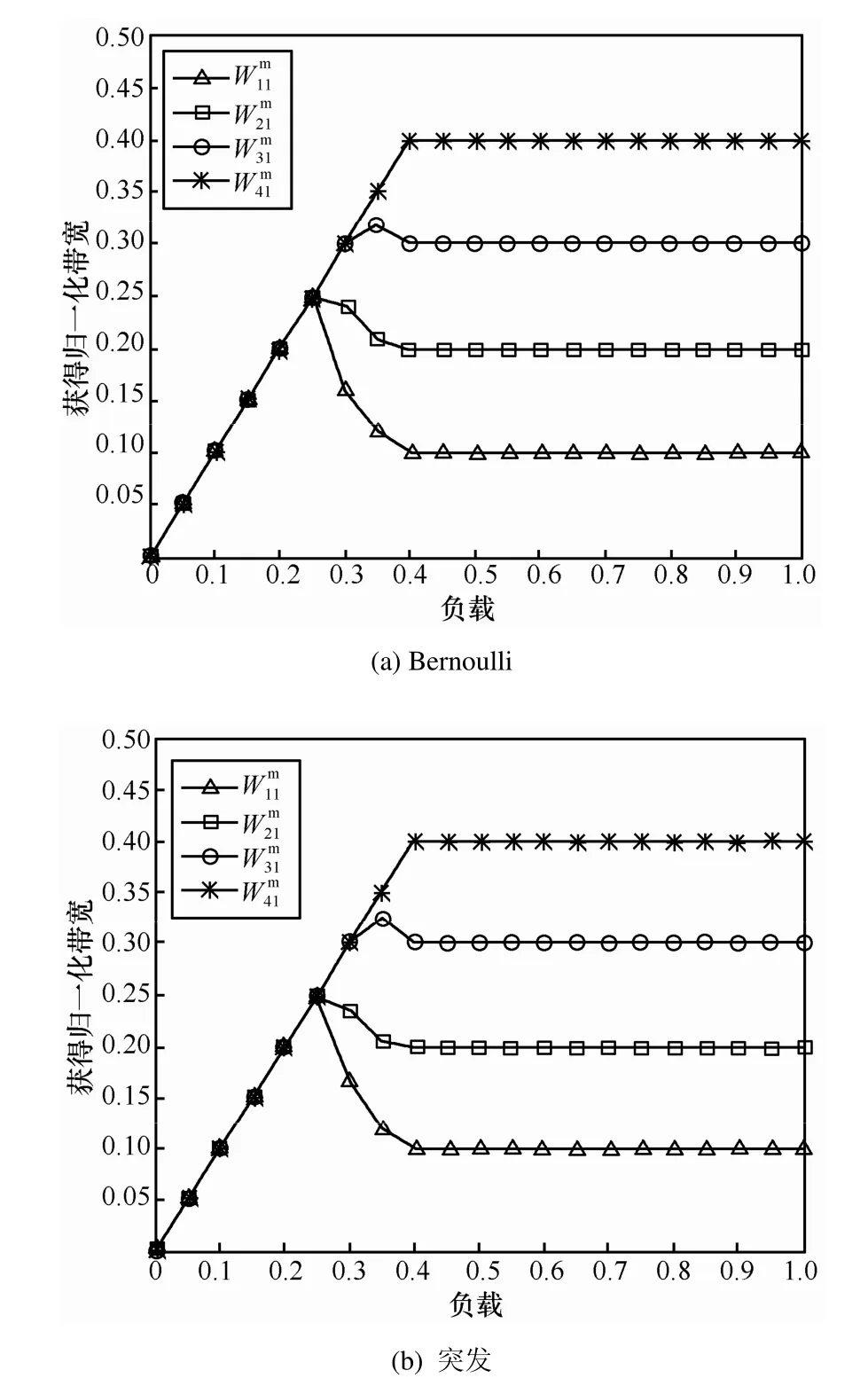
图4 情形1)Bernoulli业务源下公平性能仿真结果
其次,考察情形2)下MUMF调度算法的公平性能仿真结果,由于篇幅限制这里仅给出Bernoulli业务流到达下仿真结果,如图5所示。图5分别为Bernoulli单多播公平性能仿真结果,同样考察各输入端口获得输出端口1的实际带宽。对于单播业务,由于其预约带宽总和为 0.5,而到达输出端口 1的单播流量总和为 0.5,因而所有单播分组都被调度输出。
由于输出端口1为所有的多播分组预留了0.5的预约带宽,且在负载为0.125时达到饱和负载,因而从0.125开始各多播流受到带宽公平性限制,最终稳定到预约带宽大小。
4.3 吞吐量性能
采用Bernoulli业务源进行吞吐量评估,多播扇出端口数为4,单多播流量比例4αβ=,改变λ使其从0.1至1.0之间变化。图6给出了Bernoulli到达下 MUMF调度算法的吞吐量性能仿真结果。可以看出,MUMF调度算法的吞吐量随到达强度的增加而增加,最后达到接近100%的吞吐量。
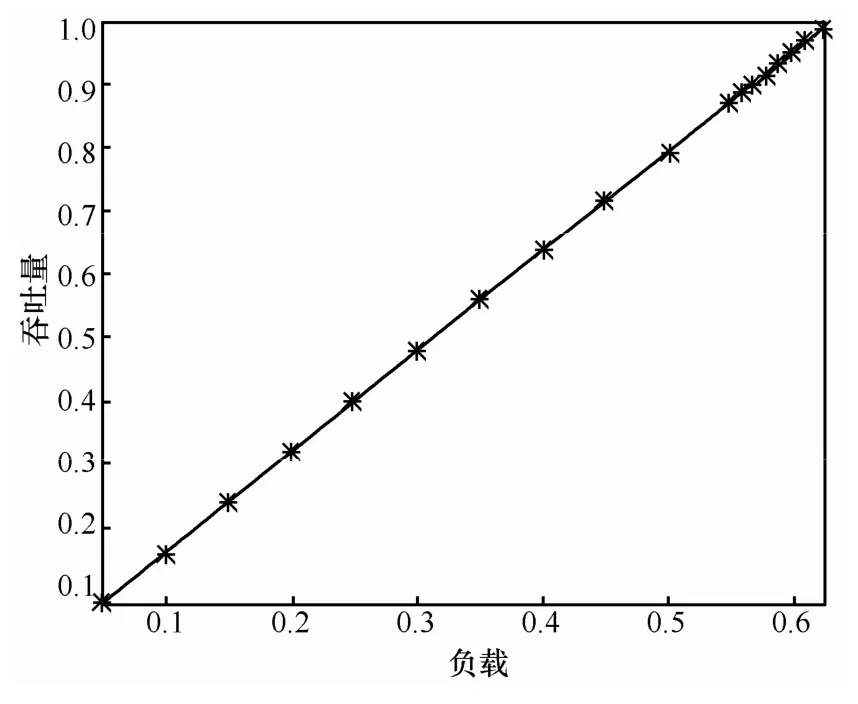
图6 Bernoulli业务源下MUMF调度算法的吞吐量性能仿真结果
4.4 QM入队机制
本节通过设定不同的输出端口队列数评估入队机制QM的性能,QM入队性能采用交换系统的平均时延进行衡量,并设定3种不同情形对QM的性能进行评估:①每个输入端口维护4个多播虚拟输出队列;②每个输入端口维护8个多播虚拟输出队列;③每个输入端口维护 16个多播虚拟输出队列。采用Bernoulli流量到达过程,多播扇出端口数为4,单多播流量比例4αβ=,改变λ使其从0.1~1.0间变化。图7给出了Bernoulli均匀流量到达下 MUMF调度算法的时延性能。可以看出,随着多播队列数目的不断增加 MUMF的时延性能不断改善,然而改善幅度变小。
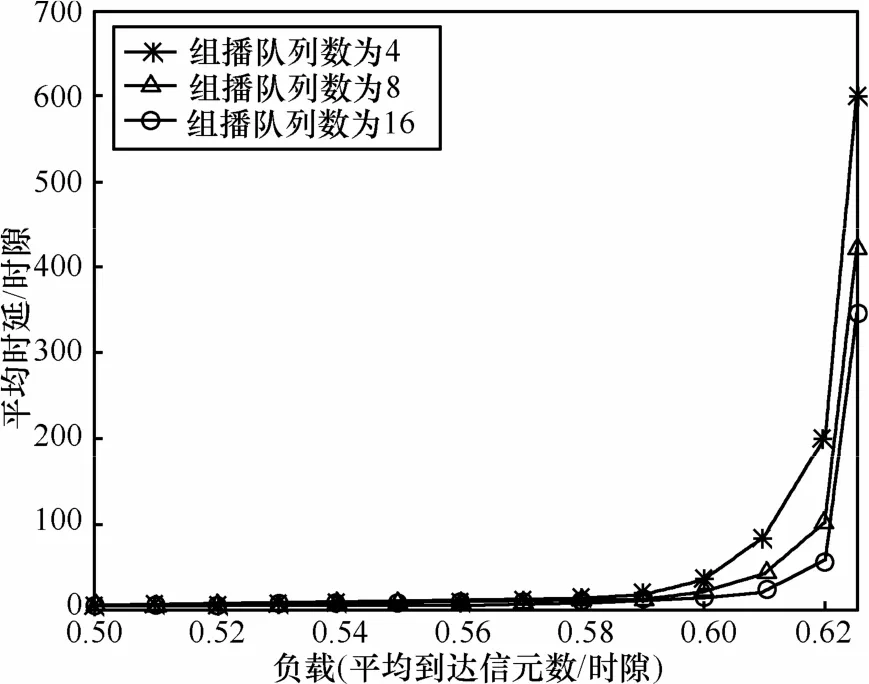
图7 Bernoulli均匀流量到达下,MUMF调度算法的时延性能
5 结束语
以视频点播、VoIP等为特征的多媒体业务及相关技术成为下一代互联网和三网融合下业务发展的典型特征。多播技术为多媒体业务的运营提供了重要支撑。基于联合输入交叉点排队交换结构,本文首先讨论了 CICQ下单多播混合调度的理论模型,基于理论模型给出了一种逼近调度算法MUMF。仿真结果表明 MUMF调度算法具有良好的性能。依托于这一思想,后期将在支持区分服务方面进行深入研究。
[1] SHEN Y, PANWAR S S, CHAO H J. SQUID: A practical 100%throughput scheduler for crosspoint buffered switches[J]. IEEE/ACM Transactions on Networking, 2010, 18(4):1119-1131.
[2] PAN D, YANG Y Y. Localized independent packet scheduling for buffered crossbar switches[J]. IEEE Transaction on Computers, 2009,58(2):260-274.
[3] NABESHIMA M. Performance evaluation of a combined inputand crosspoint-queued switch[J]. IEICE Trans on Commun, 2000,83(3):737-741.
[4] ROJAS-CESSA R, OKI E, JING Z, et al. On the combined input crosspoint buffered switch with round-robin arbitration[J]. IEEE Trans on Commun, 2005, 53(11):1945-1951.
[5] MHAMDI L, HAMDI M. MCBF: A high-performance scheduling algorithm for buffered crossbar switches[J]. IEEE Communications Letters, 2003, 7(9):451-453.
[6] ZHANG X, BHUYAN L N. An efficient algorithm for combined input-crosspoint-queued (CICQ) switches[A]. IEEE GlobeCOM[C].2004.1168-1173.
[7] JAVIDI T, MAGILL R, HRABIK T. A high-throughput scheduling algorithm for a buffered crossbar switch fabric[A]. IEEE ICC[C].2001.1586-1591.
[8] PAN D, YANG Y Y. Localized independent packet scheduling for buffered crossbar switches[J]. IEEE Transaction on Computers, 2009,58(2): 260-274.
[9] CHANG C S, HSU Y H, CHENG J, et al. A dynamic frame sizing algorithm for CICQ switches with 100% throughput[A]. IEEE INFOCOM 2009[C]. Rio de Janeiro, Brazil, 2009. 738-746.
[10] SHEN Y, PANWAR S S, CHAO H J. SQUID: A practical 100%throughput scheduler for crosspoint buffered switches[J]. IEEE/ACM Transactions on Networking, 2008, (99):1119-1131.
[11] MAGILL B, ROHRS C, STEVENSON R. Output-queued switch emulation by fabrics with limited memory[J]. IEEE Journal on Selected Areas in Communications, 2003, 21 (4):606-615.
[12] CHUANG S T, IYER S, MCKEOWN N. Practical algorithms for performance guarantees in buffered crossbars[A]. IEEE INFOCOM[C].Miami, 2005. 981- 991.
[13] TURNER J. Strong performance guarantees for asynchronous crossbar schedulers[J]. IEEE/ACM Transactions on Networking, 2009,17(4):1017-1028.
[14] ZHANG X, et al. Adaptive max-min fair scheduling in buffered crossbar switches without speedup[A]. IEEE INFOCOM[C]. Anchorage, Alaska, 2007. 454-462.
[15] HE S M, SUN S T, GUAN H T, et al. On guaranteed smooth switching for buffered crossbar switches[J]. IEEE/ACM Transactions on Networking, 2008, 16(3):718-731.
[16] PAN D, YANG Z Y, MAKKI K, et al. Providing performance guarantees for buffered crossbar switches without speedup[A]. ICST QShine[C]. Berlin, 2009.297-314.
[17] GIACCONE P, LEONARDI E. Asymptotic performance limits of switches with buffered crossbars supporting multicast traffic[J]. IEEE Trans on Information Theory, 2008, 54(2):595-607.
[18] SUN S T, HE S M, ZHENG Y F, et al. Multicast scheduling in buffered crossbar switches with multiple input queue[J]. IEEE Trans on Parallel and Distributed Systems, 2009, 20(6):818-830.
[19] MHAMDI L. On the integration of unicast and multicast cell scheduling in buffered crossbar switches[J]. IEEE Trans on Parallel and Distributed Systems, 2009, 20(6):818-830.
[20] DONG Z Q, ROJAS-CESSA R. Output-based shared-memory crosspoint-buffered packet switch for multicast services[J]. IEEE Communication letters, 2007, 11(12): 1001-1003.
[21] BENNETT J C R, ZHANG H. WF2Q: Worst-case fair weighted fair queuing[A]. IEEE INFOCOM[C]. 1996.120-128.
[22] GOLESTANI S. A self-clocked fair queuing scheme for broadband applications[A]. IEEE INFOCOM[C]. 1994.636-646.
[23] NI N, BHUYAN L N. Fair scheduling for input buffered switches[J].Journal of Cluster Computing, 2003, 6(2):105-114.
[24] PAN D, YANG Y Y. Bandwidth guaranteed multicast scheduling for virtual output queued packet switches[J]. Journal of Parallel and Distributed Computing, 2009, 69(12): 939-949.
[25] HU C, TANG Y, CHEN X, LIU B. Per-flow queuing by dynamic queue sharing[A]. IEEE INFOCOM’07[C]. Anchorage, Alaska,2007.
[26] HU H C, YI P, GUO Y F. Design and implementation of high performance simulation platform for switching and scheduling[J]. Journal of Software, 2008, 19(4):1036-1050.
猜你喜欢
科学技术与工程(2022年34期)2023-01-14
计算机研究与发展(2022年12期)2022-12-15
计算机工程与应用(2022年5期)2022-04-09
计算机研究与发展(2022年4期)2022-04-06
南开管理评论(2021年1期)2021-04-13
中国土壤与肥料(2020年6期)2021-01-18
泰山学院学报(2018年3期)2018-06-01
中国卫生(2015年3期)2015-11-19
汽车文摘(2014年12期)2014-12-15
天津科技(2014年6期)2014-08-08
