
一种新的基于频繁加权概念格的视觉单词生成方法
2012-10-16 07:38张素兰张继福
太原科技大学学报 2012年6期
褚 萌,张素兰,张继福
(太原科技大学计算机科学与技术学院,太原 030024)
基于BOV(Bag-of-visual words)模型表示的方法来源文本检索和自然语言处理,通过一系列视觉单词的统计直方图将图像表示出来,因其简单直观的表示方式,BOV(Bag-of-visual words,视觉词袋)成为图像表示和场景语义分类的研究热点之一。近年来,BOV[1]模型广泛存在于图像众多领域当中。
目前,对BOV的研究主要集中在:1)局部基元提取,大部分采用David Lowe提出的SIFT[2](Scale Invariant Feature Transform,尺度不变特征变换)算法,SIFT特征对图像缩放、旋转以及仿射变换保持不变性,并且对视角变化、噪声保持一定的稳定性,是目前图像局部特征研究领域取得较成功的一种方法,在目标识别[2]、图像拼接[3]、图像匹配[4]等领域应用极其广泛。2)视觉单词生成,目前主要有两种视觉单词方法:一种是Vogel[3]等人所使用的人工标注方法,另一种为无监督聚类算法[4],例如K-means算法。因为手工标注在某些方面存在问题及缺陷,比如工作量巨大、主观性强,所以当前在生成视觉单词的方法中,采用无监督聚类算法已成为一种最主要的渠道。文献[5]在普通的视觉单词基础上提出了一种新的能够融合单词多层上下文的核函数,提高了图像识别的准确率。文献[6]考虑视觉单词的语义信息,提出了一种基于上下文语义信息的图像块视觉单词生成算法,有效地提高了视觉单词的语义准确性,改善了场景分类的性能。视觉词包模型提供的结构化图像描述框架,在解决类的多样性、相似性、光照变化、位置差异等一些问题中,优点尤为突出,所以,基于视觉词包模型表示图像内容已成为一种主流方法,并且BOV方法已经在图像分类等领域中得到广泛应用[4-9]。但是由于传统的视觉单词生成方法没有考虑视觉单词与语义类别,及其视觉单词本身之间隐含的关联关系,而且,利用大量高维的视觉单词进行分类,效率不高。因此,通过分析BOV视觉词典中视觉单词,以及视觉单词之间隐含的关联关系,对视觉单词进行约简,生成一种有效的视觉单词,提高图像分类的性能,仍然是个值得研究的主题。
概念格[10-12],是进行数据分析和知识提取的有力工具,具有知识表示的直观性、完备性和概念层次性,已在信息检索、数字图书馆、知识发现等方面得到广泛应用[10-13]。文献[14]给出了一种新的概念格结构:加权概念格,弥补了一般概念格假定内涵各属性同等重要的不足。为使得基于加权概念格上提取的知识更好地满足用户需求,并且更加具有实际意义。文献[15]提出了一种基于信息熵的加权概念格单属性权值获取方法。由于大量高维的视觉单词影响图像语义标注的精度和效率,本文采用频繁加权概念格对视觉单词进行分析与约简,提出了一种新的视觉单词生成方法,实验验证了该方法的有效性。
1 BOV模型与频繁加权概念格
1.1 BOV 模型
基于视觉单词的词包模型表示就是在图像中构建与文本单词相类似的视觉词汇,首先使用某种算法(例如SIFT算法)提取图像局部特征,进而描述这些特征区域,其次通过K-means算法对这些区域的特征向量进行聚类,以此来构建视觉词典,最后根据图像中各个视觉词汇出现的统计分布,得到表述图像的视觉单词统计直方图。
图1为我们所选50副场景图像(Lazebnik[9]场景图像库中)中的一幅图像,假设视觉词典的大小为200,图2是描述该图像的视觉单词统计直方图。

图1 场景中的一幅图像Fig.1 An image in the scene

图2 图1的视觉单词统计直方图表示Fig.2 The visual words histogram representation of Fig.1
1.2 频繁加权概念格
在文献[14]中,针对对象属性的不同重要性,将权值引入到概念格的内涵中,提出了加权概念格这一新的格结构。相关概念如下:
定义1 设一个形式背景K:=(U,A,R,W),U表示对象集,A是属性集,W为属性的权值集,R⊆U × A,其中 U={o1,o2,…,on},A ={d1,d2,…,dm},W={w1,w2,…,wm} 且0 ≤wi≤1,wi表示属性di的重要性,设h=(O,D,w)为K上任一个三元组,且O⊆U,D⊆A,w为属性集D的权值,并且关于R满足完备性,即
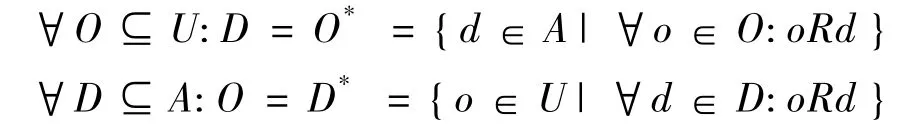
同时成立,则称h是K上的一个加权概念,O称为h的外延,D称为h的内涵。
定义2 设形式背景K上的加权概念h1=(O1,D1,W1) 和 h2=(O2,D2,W2) 是两个不同的结点,则h1≤h2⇔D2⊆D1⇔O1⊆O2,≤表示为概念之间的偏序关系,如果不存在加权概念h3=(O3,D3,W3)有h1≤h3≤h2成立,则h2称为h1的父结点,h1称为h2的子结点。形式背景中的所有加权概念及其之间的这种偏序关系构成的K上的一般加权概念格,表示为 < LW(U,A,R,W),≤ >,简记为LW(U,A,R,W).
对于已给定的形式背景,在专家和用户先验知识未知的情况下,很难得到形式背景单属性内涵权值,各属性特征的重要程度无法确定给出,在文献[15]中,为标识属性内涵重要性的大小,采用了一个与概率有关的函数来测度,即通过信息熵获得单属性权值,见式(1),这种方法为描述隐含于形式背景各属性特征重要性上提供了一条新的途径。

其中任意对象oi∈U(1≤i≤n)具有属性d的概率为P(d/oi),H(d)表示属性d的重要性,即每个对象提供于d的平均信息量。
定义3 形式背景K上属性集为A={d1,d2,…,dm},对于任意属性 di∈ A(1≤ i≤ m),令Wqz(di)=H(di)=wi,wi称为单属性 di的重要性权值。对于形式背景K上的一个加权概念h=(O,D,w),D=dk1∪dk2∪dk3∪…dkm,dk1,dk2,dk3,…,dkm的单属性重要性权值分别为 wk1,wk2,wk3,…,wkm.令:
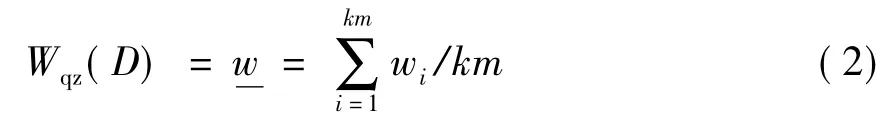
w称为多属性内涵的权值。
定义4 依据用户对内涵感兴趣的程度,定义属性集重要性的最小阈值θmin(1≤θmin≤1),形式背景K上的任意一个加权概念h=(O,D,w),若w≥θmin,h就称为频繁加权概念,则称 < Lf(U,A,R,W),≤>为频繁加权概念格,简记为 Lf(U,A,R,W).
一个形式背景K=(U,A,R,W),如表1所示,U={o1,o2,o3,o4,o5,o6},A={d1,d2,d3,d4,d5},依据式(1),得到视觉单词的权值,如表2所示,W={0.11,0.19,0.21,0.25,0.24}。设定内涵重要性阈值β=0.16,则对应的频繁加权概念格如图3所示。

表1 形式背景Tab.1 A formal context
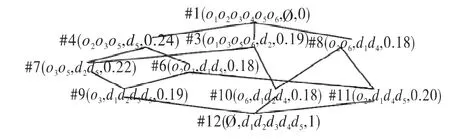
图3 频繁加权概念格Fig.3 Frequent-weighted concept lattice

表2 单属性内涵权值获取方法Tab.2 Acquisition method for single-intent weight value for single attribute
2 基于频繁加权概念格视觉单词生成方法
基于频繁加权概念格的视觉单词生成算法思想:(1)生成基于BOV模型的形式背景,首先对已构造的BOV模型进行0-1归一化(对BOV模型中的每个值做判断,如果大于等于定义的某一归一化阈值α,此时这个值就设为1,否则为0),之后将图像集标识作为对象集,视觉单词标识作为属性集,由此生成BOV模型的形式背景。(2)基于BOV模型形式背景单属性内涵权值的获取,利用式(1)得到H(di),获取单属性内涵di的权值wi,多属性内涵权值采用算术平均值计算。(3)针对某一语义类别,根据输入的内涵重要性阈值β,按照文献[14]已给出了频繁加权概念的渐进式构造方法,构造BOV模型的类别频繁加权概念格。(4)遍历类别频繁加权概念格结点,选取大于外延阈值γ的结点内涵所对应的属性集,并求其并集,得到每一特定类别的视觉词典,进而得到每一类别约简后的视觉词典。(5)融合(4)步约简后的各类别视觉词典,得到最终表示图像的全局视觉词典。
依据上述思想,视觉单词生成算法步骤描述如下:
1) 生成训练图像基于BOV模型的形式背景;
2) VW=Ø,输入β和γ;//VW表示某一类别的视觉词典,β为内涵重要性阈值,γ为外延数阈值;
3) 利用式(1),计算H(di)并且进行归一化,获得单属性内涵di的权值w;
4) 渐进式新增一个结点(O,D);
5) 若D由单属性构成,Step7;
6) 否则,利用式(2)计算内涵D的权值w;
7) 如果w<β,则不生成该结点,Step4,否则,生成该结点;
8) 如果 n(0)≥ γ,VW=VW∪{O},Step4;//n(0)表示结点(O,D,w)的外延元素个数;
9) 分别求出所有类别的视觉词典;
10) 对于每一类的视觉词典,求出Step10中所求出的交集,得到每一类约简后的视觉单词;
11) 将每一类约简后的视觉单词取并集,此并集即为图像的全局视觉词典。
在上述视觉单词生成过程中,利用生成的BOV模型频繁加权概念结构对视觉单词进行分析,将不满足外延数阈值γ的内涵属性(即视觉单词)舍去,从而生成用户所需求的并且对图像语义具有一定贡献程度的视觉单词,更加具有实际意义。

图4 视觉单词数目对分类的影响Fig.4 The impact of the number of visual words for classification
3 实验结果与分析
为了验证本文提出算法的有效性,采用Lazebnik的15类自然场景图像作为数据集,其中包含大量类别已标注的图像,每一类均包括200幅至400幅图像,总共有4485幅图像,其中包括bedroom,suburb,industrial,kitchen,livingroom,coast,forest等场景。
每类图像随机选择50幅图像加入训练集,选取50幅图像作为测试集,这里采用KNN方法来进行分类,实验中进行5次随机划分得到训练集和测试集图像,然后分别计算每次划分的分类精度,最终的分类精度即为5次划分分类精度的平均值。
首先分析传统视觉单词数目对分类性能的影响,现设定不同大小的视觉单词{50,100,200,400,600,900},实验结果如图4表示。从图4(a)可以得到,随着视觉单词数目的不断增多,分类时间逐渐增大。因为视觉单词数目变多之后,使用KNN方法进行分类,测试图像的sift特征向量与训练集视觉单词之间欧式距离的计算次数相应也会增多,所以,分类的耗时会越多。从图4(b)可以看出:一方面,较少的视觉单词判别力不高,可能导致不相似的两个视觉单词分配到同一个类别中;另一方面,随着视觉单词数目的不断增多,分类性能有所提高,但视觉单词的数目超过200之后,分类性能不再提升反而呈现下降趋势,这是因为过多的视觉单词泛化能力有限,不适应计算量及噪声较大的情况。
实验采用分类精度较高的视觉单词数目为200的情形进行分析。实验阈值的设定分别为:内涵重要性阈值 β=0.05,外延阈值γ=15,aver为BOV模型概率矩阵中所有概率的平均值,归一化阈值α分别取 0.3*aver,0.5*aver,0.7*aver,0.9*aver,实验结果如表3所示。
从表3可以看出,通过该算法四种归一化阈值得到的视觉单词训练集的个数依次为2926、2755、2297、1542,与初始的15类3000个(每一类视觉单词数目为200,共15类,因此15类有3000个视觉单词)视觉单词相比,视觉单词有所减少,分类所需时间也依次减少,这是因为归一化阈值增大的同时,基于BOV模型的形式背景就会越来越稀疏,生成的概念格节点就会相应减少,从而分析约简得到的视觉单词就会缩减,所以分类耗时就会减少。同时从表3中,还可以看出,分类的性能比较稳定,而且在归一化阈值取0.5*aver时,分类精度为74%,与文献[7]和文献[9]的分类精度(分别为72.2%和73.9%)相比,算法的精度有所提高,从而充分地说明所生成的视觉单词能有效地表示图像,并用于场景分类。
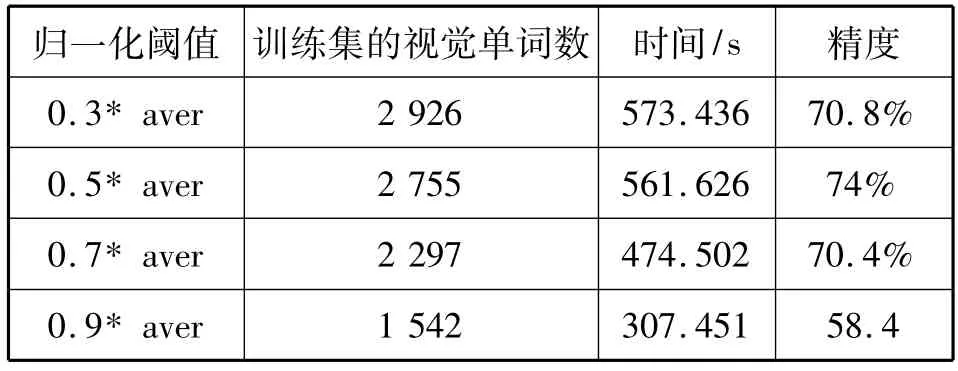
表3 β=0.05,γ=15时视觉单词生成和分类的时间和精度Tab.3 The generation of visual words and the time and accuracy of classification when β is 0.05 and γ is 15
4 结束语
提出了一种新的基于频繁加权概念格的视觉单词生成方法,依照该方法可以得到用户所需求的并且能够有效表示图像集的约简视觉词汇,对于BOV理论的研究与加权概念格的应用研究都有一定的研究价值。另外,充分利用概念格表示知识所具有的概念层次特点,得到用户关心的,能够自动标注图像语义的具有不同层次粒度的场景分类知识是下一步需要研究的工作。
[1]PEDRO QUELHAS,FLORENT MONAY,JEAN-MARC ODOBEZ,et al.A Thousand Words in a Scene[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(9):1575-1589.
[2]LOWE D.Distinctive image features from scale invariant keypoints[J].International Journal on Computer Vision,2004,60(2):91-110.
[3]VOGEL J,SCHIELE B.Semantic modeling of natural scenes for content based image retrieval[J].International Journal of Computer Vision,2007,72(2):133-157.
[4]NOWAK E,JURIE F,TRIGGS B.Sampling strategies for bag of features image classification[C]//Proc of European Conference on Computer Vision(ECCV’06).Austria:Springer,2006:490-503.
[5]王宇石,高文.用基于视觉单词上下文的核函数对图像分类[J].中国图象图形学报,2010,15(4):607-616.
[6]刘硕研,须德,冯松鹤,等.一种基于上下文语义信息的图像块视觉单词生成算法[J].电子学报,2010,38(5):1156-1161.
[7]LI F F,PERONA P.A Bayesian Hierarchical Model for Learning Natural Scene Categories[C]//Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,Washington DC:IEEE Computer Society,2005:524-531.
[8]张素兰,郭平,张继福,等.图像语义自动标注及其粒度分析方法[J].自动化学报,2012,38(5):688-697.
[9]LAZEBNIK S,SCHMID C,PONCE J.Beyond bags of features:Spatial pyramid matching for recognizing natural scene categories[C]//Proc.of IEEE Int.Conf.on Computer Vision and Pattem Recognition(CVPR’06).USA:IEEE Computer Society,2006:2169-2178.
[10]WILL E R.Restructuring lattice theory:an approach based on hierarchies of concepts[M].Dordrecht Boston,Rival,ed.Reidel:1982:445-470.
[11]王欣欣,张素兰.基于对象扩展的概念格批处理构造算法[J].太原科技大学学报,2009,30(5):368-373.
[12]杜秋香,张继福,张素兰.基于概念提升的概念格更新构造算法[J].太原科技大学学报,2009,30(1):1-6.
[13]KWON O,KIM J.Concept lattices for visualizing and generating user profiles for context-aware service recommendations[J].Expert Syetems with Applications.2009,36(2):1893-1902.
[14]张继福,张素兰,郑链.加权概念格及其渐进式构造[J].模式识别与人工智能,2005,18(2):171-176.
[15]张素兰,郭平,张继福.基于信息熵和偏差的加权概念格内涵权值获取[J].北京理工大学学报,2011,31(1):59-63.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
读写月报(初中版)(2021年12期)2021-05-25
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
临床骨科杂志(2020年1期)2020-12-12
广东教学报·教育综合(2020年135期)2020-12-07
制造技术与机床(2019年9期)2019-09-10
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
江苏通信(2018年4期)2018-12-04
爱你(2017年13期)2017-06-10
自动化学报(2017年7期)2017-04-18
