
基于DM6446的齿轮参数图像测量算法优化
2012-10-08 12:12:36孙志海
杭州电子科技大学学报(自然科学版) 2012年2期
江 琦,孙志海,张 桦
(杭州电子科技大学计算机应用技术研究所,浙江杭州310018)
0 引言
利用计算机视觉来实现齿轮的参数测量,实现对齿轮参数的非接触式测量,可以减小瞄准误差以及测量人员的主观误差,提高测量效率,且测量稳定,成本低廉。TI公司推出的 Davinci系列TMS320DM6446平台的DSP采用了VelociTITM超长指令字,通过指令间的并行来获取更高的性能,具有高速处理、强大的操作系统及低功耗等优点[1,2],给齿轮的实时性测量带来了可能。本文基于DM6446平台,充分利用二级Cache结构、Ping-Pong双缓存、EDMA数据传输以及使用高效的库函数等技术,对基于机器视觉的齿轮测量算法进行了优化。
1 系统硬件构成
本系统采用的TMS320DM6446处理器是TI公司推出的高度集成的视频处理器,系统的功能结构图如图1所示。
图1中的TMS320DM6446处理器是ARM+DSP双核架构处理器。ARM子系统采用ARM926EJ-S内核CPU,工作频率高达297MHz,具有独立的16KB指令Cache和8KB数据Cache。而DSP子系统CPU采用TM320C64x+TMDSP内核,其时钟频率高达594MHz,使用二级Cache结构,L1程序Cache为32KB直接映射Cache,L1数据Cache为80KB的双向配置Cache,L2 Cache包含一个64KB的存储器空间[1,3,4]。此外,DM6446还包含视频处理子系统以及其它众多的外设资源。

图1 TMS320DM6446的功能结构图
2 齿轮测量算法
基于DM6446的齿轮图像参数测量算法,首先对原始齿轮RGB图像I(i,j)进行预处理,包括彩色图像灰度化得到灰度图像G(i,j)、中值滤波、二值化处理及利用形态学进行边缘定位得到齿轮的边缘轮廓图像E(i,j);然后以轴心圆轮廓所对应的前景象素点作为样本点,利用最小二乘法[5]拟合出齿轮的轴心圆。为了抑制图像噪声的影响,本算法对齿轮的轴心圆进行了二次拟合,同样采用最小二乘法拟合出齿轮的齿顶圆和齿根圆。最后根据齿轮的特征以及拟合出来的轴心圆、齿顶圆、齿根圆,计算出齿轮的几何参数[6]。
3 算法优化
本算法的优化,首先对C代码的循环进行优化,如尽量减少循环,将循环展开,将乘法和除法运算转化为移位操作等。接着,根据DSP处理器的特点,充分利用二级Cache、Ping-Pong双缓存,实现EDMA数据传输及使用高效的库函数等技术,以进一步优化算法。
3.1 二级Cache配置
采集的齿轮图像是1 024×768的RGB格式图像,因此,在图像处理过程中的数据量较大,对片内存储资源有限的高速DSP处理器来说,一般需要借用外部的存储空间来存放CPU处理的数据。为了使CPU能够高速运行,可以充分利用DM6446提供的二级Cache结构,将SDRAM映射到Cache上,缩短CPU访问数据的时间。
3.2 Ping-Pong双缓存结构
第一级Cache拥有比第二级Cache更快的速度,为了进一步提高齿轮测量算法的速度。本算法采用Ping-Pong双缓存结构,使用EDMA传输方式将数据分小块搬运到第一级Cache L1D中进行各种处理,处理完后再搬运到目标的空间,使输入数据单元和输出数据单元相互配合,实现对图像数据的流水线并行处理。
不考虑边缘信息的Ping-Pong双缓存结构和EDMA技术的实现过程如图2所示。将齿轮灰度图像G(i,j)分割为192块64×64的小块 Bi(i=0,1,…,191),2个存储块A和 B位于64KB的一级数据Cache中,每个存储块分为2个区IN和OUT,形成Ping-Pong双缓存结构,分别如图2中的INBufA、OUTBufA和INBufB、OUTBufB所示。数据的处理过程如下:首先,启动EDMA将数据块B0搬运至INBufA中,并等待搬运完毕。搬运完毕后,在存储块A进行各种图像处理,同时,在存储块B中启动EDMA,将数据块B1搬运到INBufB中。若存储块A中数据处理完毕,则启动EDMA,将数据块通过OUTBufA搬运至Dst图像空间中。再等待数据B1从原始空间全部搬运到INBufB,并在B中做同样的处理。存储块A和B依次循环交替搬运和处理数据块,直到Src中的所有数据块都处理好为止。
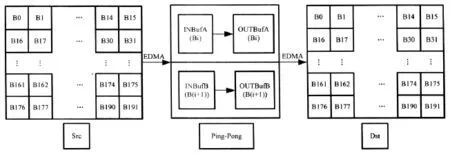
图2 Ping-Pong双缓存结构
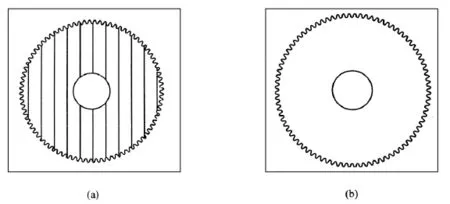
图3 齿轮的边缘图像
本算法中在Ping-Pong双缓存结构中实现的图像处理主要有对灰度图像中值滤波、二值化处理以及利用形态学实现的边缘定位。处理后的效果如图3(a)所示,处理后的图像多了许多额外的伪边缘,这是对64×64的块进行处理时留下的每块的边缘信息。这对于齿轮的测量是绝不允许的,因此,需对Ping-Pong双缓存做进一步改进。为了去除伪边缘,本算法采用68×68的块进行处理,处理后,再从该68×68数据块中搬走其中的64×64的数据块至Dst图像中。数据块的不同位置直接决定了68×68数据块在原图像Src中的位置以及搬运到Dst图像的64×64的数据块在68×68块中的对应位置。图3(b)中是处理后的边缘图像,该边缘图像已经将图3(a)中的伪边缘去除了,达到了所期望的效果。
本算法,将图像的块分为9类进行讨论,如图4(a)所示,包括左上边界块(即图像中的B0)、左下边界块(即图像中的B176)、右上边界块(即图像中的B15)、右下边界块(即图像中的B191)、上边界块(即图像中的B1-B14)、下边界块(即图像中的B177-B190)、左边界块(即图像中的B16、B32、B48、B64、B80、B96、B112、B128、B144、B160)、右边界块(即图像中的 B31、B47、B63、B79、B95、B111、B127、B143、B159、B175)和中间块(除上述8种外的其它数据块)。搬移到Ping-Pong双缓存结构的进行处理的9种块的分割如图4(b)所示,实线对应于图2中的64×64的块,虚线表示扩展成为68×68的块。
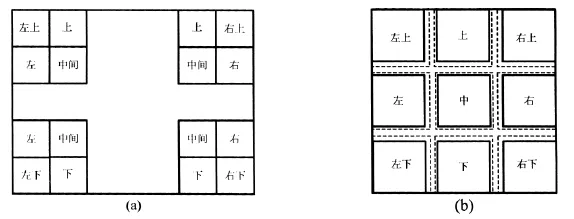
图4 9种不同类型的数据块
3.3 使用高效的库函数和编译器选项
TI公司提供了基础库DSPLIB和IMGLIB,其中有很多经过了汇编优化处理后的高效库函数,可以通过调用这些函数来进一步提高算法执行速度。本算法使用了TI公司提供的中值滤波函数IMG_median_3x3,结果表明,利用高效库函数和内联函数,处理速度明显提高。
编译开发平台提供了用于性能优化的编译器选项,能对C代码进行优化,它有4级不同的文件优化级别,分别对应-o0、-o1、-o2和-o3,其中本算法采用-o3级别优化,-o3为是最高级别的优化,编译器将执行各种优化方法,如软件流水线、优化循环代码和SIMD等。
4 实验结果与分析
实验采用SEED-DVS6446开发板、SEED-XDS560PLUS仿真器对齿数为84、模数为0.6mm、基圆半径为23.680 5mm的小模数齿轮进行齿轮参数的测量并分别对原始算法、使用DM6446二级Cache配置后的算法以及使用包含DM6446二级Cache配置、Ping-Pong双缓存技术、高效库函数及编译器优化选项等技术优化后的算法,以下简称为Cache+Ping-Pong+IMGLIB+o3,进行时间性能测试,如表1所示。
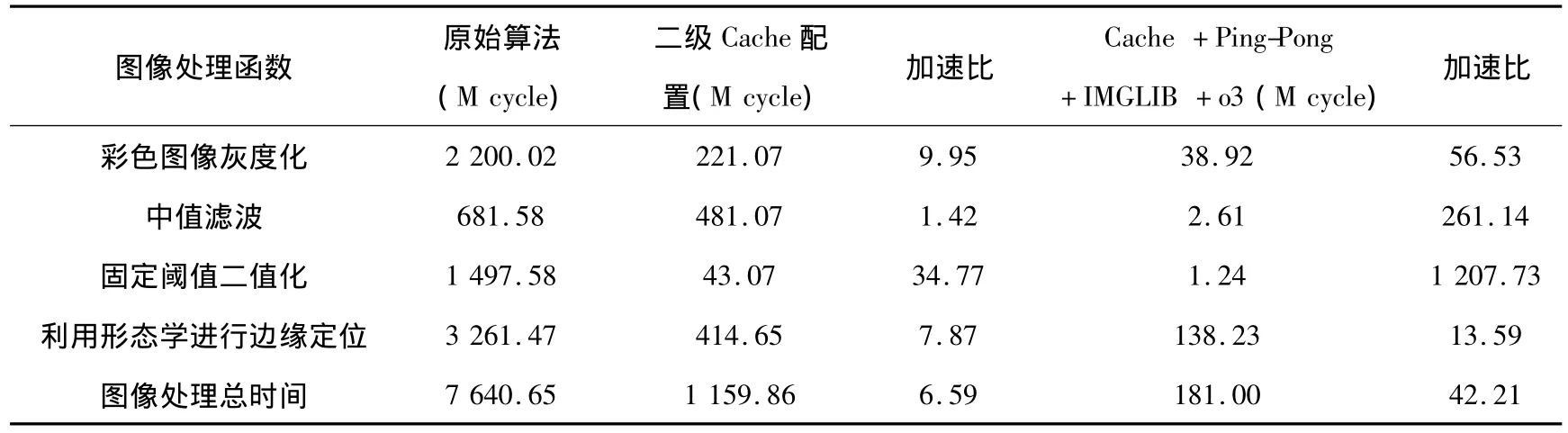
表1 齿轮测量算法性能比较
由表1可知,经过优化后的算法在时间上大大缩短了。齿轮测量算法中图像处理原始算法需耗时12 734.42ms,使用二级Cache配置后,时间缩短为1 933.1ms,处理效率提高了近7倍,经Cache+Ping-Pong+IMGLIB+o3优化后,时间进一步缩短为301.67ms,处理速度提高了42倍多。
5 结束语
本文根据DM6446处理器的特点,对齿轮参数测量算法进行优化,实现算法的并行处理,提高了算法的速度。经优化后齿轮测量图像处理的总时间从12 734.42ms降为301.67ms,算法处理性能加速度比为42。
[1]张起贵,张胜,张刚.最新DSP技术-达芬奇系统、框架和组件[M].北京:国防工业出版社,2009:1-21.
[2]彭启琮.达芬奇技术-数字图像/视频信号处理新平台[M].北京:电子工业出版社,2008:9-20.
[3]李方慧,王飞,何佩琨.TMS320C6000系列DSPs原理与应用[M].北京:电子工业出版社,2002:8-15.
[4]Texas Instruments Incorporated.卞红雨,纪祥春,乔钢,等译.TMS320C6000系列DSP的CPU与外设[M].北京:清华大学出版社,2007:113-140.
[5]于起峰,陆宏伟,刘肖琳.基于图像的精密测量与运动测量[M].北京:科学出版社,2002:132-158.
[6]齿轮手册编委会.齿轮手册[M].北京:机械工业出版社,2004:2-8.
猜你喜欢
内燃机工程(2021年6期)2021-12-10 08:07:46
少儿科学周刊·少年版(2020年9期)2020-03-04 11:38:12
少儿科学周刊·少年版(2020年9期)2020-03-04 11:38:12
制造技术与机床(2017年3期)2017-06-23 08:11:52
通信产业报(2016年44期)2017-03-13 08:41:45
电子设计工程(2015年12期)2015-02-27 12:06:20
汽车零部件(2014年1期)2014-09-21 11:41:11
小青蛙报(2014年1期)2014-03-21 21:29:39
电子设计应用(2004年7期)2004-09-02 08:44:00
雕塑(1999年2期)1999-06-28 05:01:42
