
基于扫描圈的字符识别方法
2012-09-29 03:19:14宋贤霞李玉琴
自动化与信息工程 2012年5期
宋贤霞 李玉琴
(1.甘肃中医学院 2.兰州理工大学)
0 引言
公式广泛存在于各类文献资料中,当对这些文献进行数字化时,其中的公式只能按照图像格式使用,不能加以识别分析,也不能依据公式对文章进行检索。当需要验证或重用这些公式时,只能使用专门的排版软件进行重新输入,因此找到一种简单有效的方法将文献中的公式转化为可编辑的文本公式是非常必要的[1-2]。
在实际应用中,数学公式一般是由英文字符、阿拉伯数字、特殊符号及希腊字母组成的,因此要正确识别数学公式首先要识别这些组成元素[3-5]。本文所做的关于扫描圈的识别就是针对每一个单独字符进行识别,本文以印刷体的英文小写字母为例对扫描圈识别的方法进行阐述[6]。
1 扫描圈提取
1.1 扫描圈概念
英文字符在外观上是由一些曲线组成的,任何一个连笔符号都可以看成是由一个外圈和若干个内圈组合而成,如a是由一个内圈和一个外圈组合而成的;c则是由一个外圈形成的。用不同的数字代表上下左右四个方向,并且用它们的组合代表左上、左下、右上、右下四个方向(如图1所示)。通过扫描搜索,每一个几何圈都可以一一对应于由这四种符号构成的数字串,这个数字串简称为扫描圈。
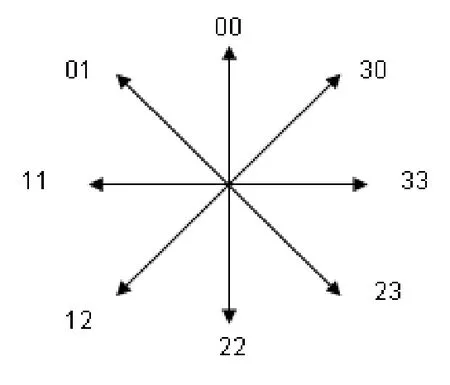
图1 扫描圈的数字串表示
1.2 扫描圈提取
扫描圈的提取是按照相对坐标和邻点搜索实现的,在扫描开始之前需要给出一个初始中心点,即扫描初点。寻找扫描初点的过程有两种方式:一种是按照行扫描的方式以搜索到的第一个黑色点作为扫描初点;另一种是按照列扫描的方式搜索扫描初点。本文采用的是行扫描的方式。
找到扫描初点之后,将其作为当前中心点,按照逆时针的方向搜索它的八个领域点,应当注意此时它的邻点中有四个方向的点已经在行扫描的过程中被考察过,且都不为黑点,因此,此时只要搜索它另外四个方向上的邻点(01、00、30、11)。若在搜索过程中得到一个黑色新邻点,定义这个首次出现的黑色新邻点为下一个中心点,然后按照逆时针方向以前中心点的下一个点为起始点,在8个方向中搜索新的中心点,这样就形成了几何圈的扫描过程;若在扫描过程中未在扫描初点的邻域中找到黑色新邻点,表明此扫描初点为一个孤立的像素点,将其视为无效点清除,并寻找新的扫描初点。表1对遵循以上规律得到的扫描圈结果进行了举例说明。

表1 扫描圈结果举例
按照上述方法,对每一个英文小写字母都可以得到若干个四进制的字符串,如果依照点的绝对坐标的单调性,可以将几何圈分成若干个单调弧,在四进制的字符串中便能得到单调段的个数及序数稳定性,即同一符号在一定范围内的放大和缩小格式具有相同的单调段个数及序数。一个计算机符号实际上是几何符号的有限剖分,符号识别就是研究几何符号的剖分不变性,知道了剖分不变性便可以得到计算机符号的不依赖于硬件的抽象码。
1.3 扫描圈提取过程中的特殊处理
为防止在扫描圈提取过程中由于笔画过细而造成损失单调段及影响序数的情况,在扫描圈提取过程中如果出现相反的方向就进行加宽处理,即在扫描圈中多加入一个与这两个方向按逆时针的垂直方向上的像素点,表2对进行了加宽处理的笔画作了举例说明。
从表2的处理中可以看出,扫描圈是一个很长的数字串,包含多个相同的码字连续出现的子段,它们实际上就是一个个的单调弧。为在不损失图像笔画信息的前提下尽可能的压缩扫描圈的长度,提出扫描核的提取方法。

表2 对扫描圈进行加宽处理
2 扫描核及特征提取
2.1 扫描核
在几何相似变换下,即适当的几何放大或缩小,同一个几何圈的扫描圈是不同的,但具有内在的结构不变性,提取这些结构不变量是结构识别的关键。
扫描圈是由数字0、1、2、3的组合构成的数字串,不同的组合表示不同的方向,如果扫描圈cod为:{i、j}={0、1},{1、2},{2、3},{3、0},则称 cod由数字{i、j}构成的极大段为扫描弧。这里的极大段是指不含相反方向数字的极大弧段。
每一个扫描圈都可以看作是扫描弧的有序组合,如果用cod[ i ]来表示一个扫描弧,那么扫描圈cod可以分解为弧段的表示:
cod=cod[1]cod[2]cod[3] ……cod[n],n称为弧段的个数,这是一个相似不变量,当对字符进行适当的放大和缩小后,n均不会改变。
每一个弧段中由于其不含相反方向的数字,所以可以对弧段进行压缩,例如弧段 2222121212222222可以压缩为12,这样每一个扫描圈便可压缩为扫描基的表示,将其称之为扫描核。
一般,扫描圈在其长度得到大幅度缩减的基础上仍保留着扫描弧个数、方向等重要形态信息。下面对字符的特征提取就是在扫描核的基础上进行的。
2.2 特征代码库的建立
经过压缩之后很长的扫描圈变成了由扫描基表示的较短的扫描核,扫描核所携带的笔画走向信息与扫描圈是相同的,每一个扫描基就表示一种笔画的走向。由于英文字符在结构上具有不变性,因此任一字符在某一方向上的笔画总数是不变的,即每一个扫描基在扫描核中的总数是不会变的,根据这一特性对于每一个英文字符,首先提取它的扫描核,然后数出其中每一个扫描基的个数,用它们组成一个长度为4的特征向量,表3是对一部分字符特征向量的举例说明。

表3 字符特征向量举例
对于26个英文小写字母,按照上述方法分别计算它们的特征向量并保存在计算机中作为匹配的模板。
3 模板匹配
对于输入的单个字符,按照前面的方法提取它的特征向量,将其与所有模板逐个进行比较,计算它们之间的距离

对于距离D,设定了一个阀值,当D大于该阀值时,中断与该模板的比较,并进行与下一个模板的比较。当所有的模板都比较完之后,找出其中距离最短的模板,则识别结果为该模板对应的英文字符,若所有的距离都超过了阀值,则认为该字符无法识别。
4 结束语
文中所设计的方法主要是针对印刷体的英文小写字母,对于不同字体的英文小写字母,它们的像素点位置略有差别,这种差别将影响字符的识别率。因此,为了提高字符的识别率需要针对每一种字体分别提取它们的特征代码库。这样每一个英文小写字母所对应的特征代码就不止一个,在模板匹配过程中需要与这些不同的特征代码进行比较。
[1] 程值军.基于扫描表方法和命令串方法的数学公式识别与文本转化的理论研究[D].兰州大学,2007.
[2] 庞东虎,金伟杰.英文字符特征提取系统[J].计算机仿真,2007,24(12):208-210.
[3] 黄炯生,黄敏琪.基于模型匹配法的字符识别[J].中国科技信息,2008(8):92-94.
[4] 蓝章礼.基于中心与圆周的英文字符识别方法研究[J].计算机科学学报,2007,34(4):241-242.
[5] 黄敏,龙辉敏,杨曦,等.一种典型的英文字符识别算法[J].电子仪器仪表用户,2000,7(4):17-21.
[6] 王萍,刘恒,狄光敏.基于简约码特性树的字母和数字识别[J].天津大学学报, 2008,41(6):668-672.
猜你喜欢
上海航天(2024年1期)2024-03-08 02:52:28
时代英语·初中(2023年4期)2023-09-06 14:41:20
电子设计工程(2022年24期)2022-12-23 12:03:28
光学精密工程(2021年8期)2021-10-04 11:46:28
赤峰学院学报·自然科学版(2021年4期)2021-06-24 23:17:10
中国人兽共患病学报(2021年2期)2021-03-24 05:54:58
老年世界(2016年8期)2016-10-17 00:24:48
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:12
四川建筑(2015年4期)2015-06-24 14:08:40
长江大学学报(自科版)(2014年7期)2014-03-20 13:20:59
