
基于Apriori算法的中药复方配伍规律的数据挖掘研究
2012-09-22 06:56王晓维杨伟吉
中国医学教育技术 2012年4期
傅 斌,王晓维,杨伟吉,罗 杰
1浙江中医药大学,杭州 310053;2杭州方回春堂国医馆,杭州 310000
基于Apriori算法的中药复方配伍规律的数据挖掘研究
傅 斌1,王晓维2,杨伟吉1,罗 杰1
1浙江中医药大学,杭州 310053;2杭州方回春堂国医馆,杭州 310000
关于中药复方配伍规律认识在古今文献中有或多或少的记载,但以往文献多是作者的经验表述,而不是研究成果。以文献研究和理论研究为基础,结合新兴学科—数据挖掘技术,主要运用关联规则方法分析,开展配伍规律研究,既能为中医新药的临床和实验研究提供目标和思路,减少盲目性,缩短研究周期;同时又为大量古今验方研究探索出一条有价值的研究途径和方法。
Apriori算法;中药复方;配伍规律
中华民族五千年的文化底蕴是中医药发生、发展的基础。中医药领域的无数临床实践与理论研究积累了大量的科学知识,这些知识包含在中医药古籍文献以及当前的研究文献中。中药复方组成是在中医药理论指导下经长期临床实践而总结出来的。一个好的中药复方,绝不是简单的药物堆砌,它不仅包含着中医学独特的医理和思辨,其药物的选择还蕴涵着一定的配伍规律[1]。
中医药学有其自身的思维模式,具有系统性、整体性、复杂性、不确定性等特点,不适宜运用传统的还原论的方法研究。而数据挖掘是一门交叉学科,它汇聚了数据库、人工智能、统计学、可视化、并行计算等不同学科和领域,能从大量的、不完全、有噪声、模糊、随机的数据中提取蕴含其中的、事先不得知但又潜在有用的信息和知识的过程[2]。它是在数据中正规地发现有效的、新颖的、潜在有用的,并且最终可以被读懂的模式的过程。数据挖掘可以从海量的数据中寻找潜在的规律,完成普通人不能完成的任务。因此,利用数据挖掘进行中药复方配伍规律的研究是一个有着非常美好前景但又充满挑战的研究方向。
1 数据挖掘在中医药领域中的国内外研究现状
1.1 近年来国家自然基金资助分析
从国家资助的相关研究来看,代表性的有2010年国家自然基金资助数据挖掘研究项目共66项。其中,资助西医类一项:基于多模式序列超声图像识别系统诊断乳腺癌的方法学研究(哈尔滨医科大学);资助中医类四项:应用数据挖掘技术研究中医药治疗再生障碍性贫血的组方规律(中国人民解放军第210医院);基于智能计算的中医方剂基础治法模型的构建(北京中医药大学);基于数据挖掘的针灸法效应特异性基本规律及特点的研究(河北医科大学);中药新药有效核心处方发现的随机对照盲法设计方法研究(中国中医科学院中医临床基础医学研究所)。如何面对方剂理论体系的复杂性,尤其是海量的信息特点,以及方剂的效应评价多靶点的特征,使得数据挖掘在方剂研究领域中越来越显重要,也是国家自然基金重点资助的课题。提高挖掘技术针对性和适用性,对集成方剂文献信息、评价方剂效应以及中医药知识发现具有重要作用。
1.2 数据挖掘技术在中医复方用药规律中的应用
1.2.1 相关性分组或关联规则挖掘 相关性分组或关联规则挖掘是数据挖掘中的一个非常重要的研究领域,它通过几组特定的搜索算法,发现大量数据之间的关联或相关性。例如:在中药领域采用基于关联规则的算法,分析挖掘“症状—方药”之间、“基本症状—证型”之间、“证型—方药”之间以及中药配伍之间的多重关联关系,总结归纳名老中医的辨证规律并模拟其诊断推理过程,还可以发现客观有用的新知识以丰富专家经验和中医理论。
1.2.2 决策树 决策树是用二叉树形图来表示处理逻辑的一种工具。可以直观、清晰地表达加工的逻辑要求。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。首先,通过名老中医的临证医案实录建立一棵决策树;然后,利用建好的决策树,建立一个模型;最后,对数据进行预测。决策树的建立过程可以看成是数据模型的生成过程,因此在继承名老中医经验的基础上,可根据决策树的结果,参照后续病人的病兆、病症、病理进行医治。
1.2.3 人工神经网络技术 在数据挖掘技术中,人工神经网络是近年来颇受关注的一种技术。由于其本身良好的鲁棒性、自组织适应性、并行处理、分布存储和高度容错等特性,为解决复杂的问题提供了一种相对简单且有效的方法。例如:李建生[3]等提出了用于中医证候诊断的径向基神经网络,利用聚类分析确定RB神经网络隐层的参数,运用最小二乘确定RBF神经网络输出层的参数,进行中医中药研究。
1.2.4 聚类分析技术 聚类是数据挖掘的前期工作之一,通过对有关数据的不同角度分类,为进一步分析提供证据。聚类是根据客体属性对一系列未分类客体进行类别的识别,把一组个体按照相似性归并成若干类别,即“物以类聚”。通过确定数据之间在预先制定的属性上的相似性来完成聚类任务,这样最相似的数据就聚集成簇。例如:高峰[4]等用聚类分析技术研究肾阳虚证辨证因子客观化、标准化的方法和思路,对出现率较高的症状进行聚类分析,寻找对肾阳虚证候诊断的贡献度。
用数据挖掘技术对中医复方配伍数据的智能分析刚刚起步:尚尔鑫的基于改进关联规则算法的中药对药味间性味归经功效属性关系的发现研究[5],主要采用标准关联规则发现Apriori算法[6]以及改进多数据库计算方法,对从历代药对文献中收集整理得到的625个,药对347味药中包括性味、归经、功效等共49个属性形成的数据库进行挖掘研究,并对两种方法得到的结果进行比较。
2 研究的意义
基于Apriori算法的中药复方配伍规律的研究,其研究成果将在以下几个方面存在明显优势:对深入开展中药复方配伍规律的客观化和规范化研究打下良好基础;探讨利用现代科技手段对名老中医经验和学术思想研究、总结的新模式、新方法;得出方剂配伍的规律和单味药或药对的频繁项集,为中医新药的临床和实验研究提供目标和思路,减少盲目性,缩短研究周期;同时又为大量古今验方研究探索出一条有价值的研究途径和方法。
3 研究方法
3.1 数据采集
数据来源:在《中医方剂大辞典》、《中医方剂数据库》以及古今文献中收集的方剂基础上,构建中药复方数据库和分层聚类与关联的检索形式。
标准化:中药分类、药性等内容参照“新世纪教材《中药学》”(高学敏主编,中国中医药出版社,2002年9月第1版)、“中医药高级丛书《中药学》”(高学敏主编,人民卫生出版社,2000年11月第1版)、《中药大辞典》(赵国平主编,上海科学技术出版社,2006年第2版)、《现代临床中药学》(张民庆等主编,上海中医药大学出版社,2002年1月第1版)、《中华本草》(国家中医药管理局《中华本草》编委会主编,上海科学技术出版社,1999年9月第1版)等。
3.2 创建数据挖掘模型
方法:以VC6.0为开发工具,Windows XP为操作系统,SQL 2000为数据库服务器环境,开发关联规则数据挖掘平台。
复方中药数据挖掘系统的体系结构分为两个部分。第一部分是数据的录入、查询、删除部分,该部分为挖掘系统提供原始数据;第二部分是该系统的核心部分,将第一部分的基础数据经过清洗、转换、抽取、汇总,装载到数据集市,然后以数据集市为基础,以数据挖掘技术为核心,进行基于功效的方剂高频用药的知识发现和比较,得出方剂配伍的规律和单味药或药对的频繁项集,发现中药单方之间的配伍规律,为中药新药开发提供决策信息,如图1所示。
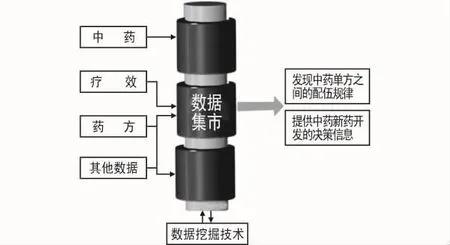
图1 基于Apriori算法的中药复方高频项集体系结构
Apriori算法中发现频繁集的基本步骤如下:第一步,找到所有一阶频繁集:L1;
第二步,假设k为当前迭代次数,Lk-1为上一次迭代产生的频繁集,循环迭代以下步骤直到Lk-1为空;
第三步,从Lk-1中得出包含Lk的候选集Ck,具体为:对Lk-1中所有前k-2个项目相同的项目集作连接操作,即Lk-1∞Lk-1={A∞B|A,B∈Lk-1,| A∩B|=k-2},再根据Apriori属性从该集合中删除其子集在Lk-1未出现的k阶项目集,得到Ck;
第四步,从Ck中删去支持度小于最小支持度的频繁集,得到Lk,回到步骤二;
第五步,集合LS=L1∪L2∪…∪Ln为所有频繁集的集合。
Apriori算法的示意如图2所示。
3.3 数据挖掘
采用Apriori高频集算法,对数据库当中的方剂分别进行基于功效的方剂高频用药的知识发现和比较,得出方剂配伍的规律和单味药或药对的频繁项集,技术路线流程图(如图3所示)。
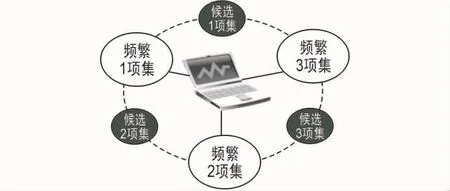
图2 Apriori核心算法示意图
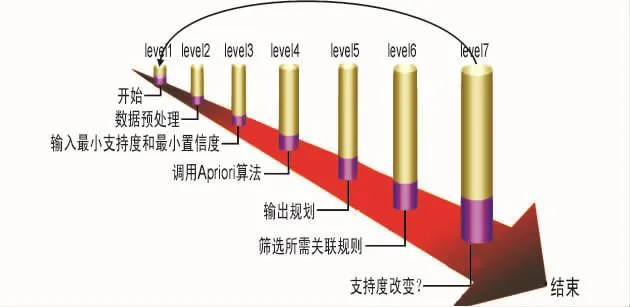
图3 技术路线流程图
复方中药数据挖掘系统(如图4所示)。
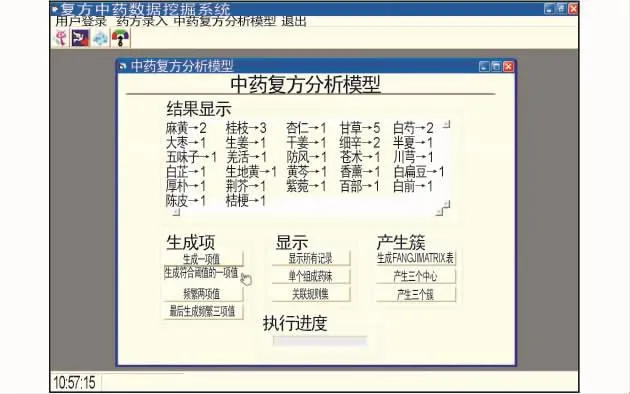
图4 复方中药数据挖掘系统界面
系统的开发实现和相关的核心代码:


3.4 结果及分析
完全符合型:典型的药对能够得到中医方药合理解释的,如(白术,茯苓)→茯苓汤。验证了古今文献中作者的经验表述的记载,实现对脾胃病中药复方配伍规律的客观化和规范化研究;探讨利用现代科技手段对名老中医经验和学术思想研究、总结的新模式、新方法。
模棱两可型:不能或较难用中医方药理论进行合理解释,在临床上也未作为药对看待的组合,如(茯苓,木香)。这个是我们分析以后重点研究的。虽然这些药物组合在临床上不是以药对配伍的形式来使用,但其关联性是客观存在的,如何利用这些相互关联的药物,为中医新药的临床和实验研究提供目标和思路,减少盲目性,缩短研究周期。
明显不是型:虽然关联性很强,但明显不是药对,如(人参,甘草)。因为按照中医用药理论,甘草和生姜等通常做辅药,所以使用得比较普遍,但不应该成为药对、药组的成分。因为药对、药组中的几味药是相互协同、相互促进,产生特殊的功效治疗病症。因此在做数据挖掘时要对这种明显不是药对的数据做二次筛选。
4 总结
Apriori算法固有的缺陷还是无法克服:
4.1 可能产生大量的候选集
当长度为1的频集有10 000个的时候,长度为2的候选集个数将会超过10 M。还有就是如果要生成一个很长的规则的时候,要产生的中间元素也是巨大量的。
4.2 无法对稀有信息进行分析
由于频集使用了参数minsup,所以就无法对小于minsup的事件进行分析;而如果将minsup设成一个很低的值,那么算法的效率就成了一个很难处理的问题。
在Apriori算法的基础上,如果能改进计算方法,采用分步计算,减少大量候选集,则非常适用于药对、药组间关联规则的发现,也可用于不同方剂间关联规则的发现。
然而,关于中药复方配伍规律认识在古今文献中有或多或少的记载,但是以往文献多是作者的经验表述,而不是研究成果。因此,以文献研究和理论研究为基础,结合新兴学科—数据挖掘技术,主要运用关联规则方法分析,开展配伍规律研究,既能为中医新药的临床和实验研究提供目标和思路,减少盲目性,缩短研究周期;同时又为大量古今验方研究探索出一条有价值的研究途径和方法。
[1]周忠眉.数据挖掘在方剂配伍规律研究应用的探讨[J].漳州师范学院学报,2003,16(4):1-3
[2]胡侃,夏绍玮.基于大型数据仓库的数据采掘[J].软件学报,1998,9(1):43-45
[3]李建生,胡金亮,余学庆.基于聚类分析的径向基神经网络用于证候诊断的研究[J].中国中医基础医学杂志,2005,11(9):50-53
[4]高峰,陆明,严石林,等.肾阳虚辨证因子的聚类分析探讨[J].现代中西医结合杂志,2006,15(15):2007
[5]尚尔鑫.基于改进关联规则算法的中药药对药味间性味归经功效属性关系的发现研究[J].世界科学技术(中医药现代化),2010,12(3):377-381
[6]Agrawal R,Srikant R.Fast algorithms for mining associationrule[A].Proceeding soft the Twentieth International Conference on VeryLarge DataBase(VLDB.94)[C].Santiago,Chile:MorganKaufmann,1994:487-499
Apriori-based data m ining of compatibility regularity of Chinese traditionalmedicine
Fu Bin1,Wang Xiaowei2,Yang Weiji1,Luo Jie11Zhejiang Chinese Medical University,Hangzhou 310053;2Hangzhou Fang Hui Chun Tang,Hangzhou 310000
The compatibility regularity of Chinese traditionalmedicine has been documented in ancient literature,but previous literature is more of authors'experience accounts rather than research results.Based on literature-based research and theoretical study combined with datamining technology,a newly emerging discipline,we studied compatible regularity of Chinese traditional medicine with association rules analysismethod.Itwill provide target and thoughts for clinical and experimental studies of new traditional Chinesemedicine,reduce blindness,and shorten research cycle.At the same time,it will explore a valuable research approaches and methods for research on a large number of ancient and modern prescriptions.
apriori;traditional Chinesemedicine compound;regularity of compatibility
G40-057
:A
:1004-5287(2012)04-0434-04
2012年浙江省中医药科学研究基金计划“基于Apriori算法的脾胃类中药复方配伍规律的研究”(2012ZB026);浙江中医药大学校级科研基金项目“基于Apriori算法的复方中药频繁项集的发现研究”(2010ZY23)
2012-03-13
傅斌(1983-),男,浙江绍兴人,软件工程硕士,助理研究员,主要研究方向:数据挖掘。
猜你喜欢
世界科学技术-中医药现代化(2021年8期)2021-12-21
大众投资指南(2021年35期)2021-02-16
Digital Chinese Medicine(2021年4期)2021-02-14
中国民间疗法(2020年22期)2021-01-07
中国交通信息化(2020年1期)2020-07-27
中成药(2018年9期)2018-10-09
中成药(2018年6期)2018-07-11
中成药(2017年8期)2017-11-22
中南民族大学学报(自然科学版)(2015年2期)2015-12-16
中国药业(2014年12期)2014-06-06
