
基于组合分类器的信用卡信誉检测
2012-09-19 06:40周宓
成都大学学报(自然科学版) 2012年3期
周 宓
(泉州师范学院应用科技学院,福建泉州 362000)
基于组合分类器的信用卡信誉检测
周 宓
(泉州师范学院应用科技学院,福建泉州 362000)
给出了支持向量机的信用卡信誉检测模型和基于决策树的信用卡信誉检测模型的建立方法,并在这两种单一分类器的基础上,归纳总结支持向量机方法和决策树方法对信用卡信誉检测的偏好特性,提出了一种基于偏好特性进行组合的组合分类器模型建立方法.
信誉检测;支持向量机;决策树;组合分类;测全率;测准率
0 引 言
信用卡作为一种先进的金融支付工具,因其所具有的操作便捷、结算安全等特点得到快速发展.如何利用客户的基本信息及交易行为信息,演绎客户信用卡的交易行为模式,识别和控制信用卡交易中的恶意提现以及恶意透支行为以及检测信用卡账户的信誉水平,以更好地为优质客户提供满意的服务,同时降低非优质客户所带来的坏账风险,是银行信用卡风险管理迫切需要解决的问题.本研究给出了基于支持向量机的信用卡信誉检测模型和基于决策树的信用卡信誉检测模型的建立方法,并总结支持向量机方法和决策树方法对信用卡信誉检测的偏好特性,提出了一种基于偏好特性进行组合的组合分类器模型建立方法,并对结果进行了分析.
1 基于支持向量机和决策树组合分类模型
1.1 支持向量机分类法
支持向量机就是首先通过用内积函数定义的非线性变换将输入空间变换到一个高维空间,在这个空间中求最优分类面的一种线性分类器[1].支持向量机分类函数形式上类似于一个神经网络,输入是d维特征向量,输出是中间节点的线性组合,每个中间节点对应一个支持向量.由于支持向量机的求解最后转化成二次规划问题的求解,因此支持向量机的解是全局唯一的最优解.
本研究对信用卡信誉检测数据抽取了较多的相关属性,但每个属性对信誉检测的影响并不一致,甚至有可能会有干扰检测效果的不良影响,对此,可先采用巴氏距离法[2]和Relief算法[3]对多个属性进行处理,以去除无关属性.
1.2 决策树分类法[4]
决策树分类法是应用最广的归纳推理算法之一.它对数据进行分类,可达到预测的目的[4].决策树方法首先根据训练集数据形成决策树,如果该树不能对所有对象给出正确的分类,那么选择一些例外加入到训练集数据中,重复该过程一直到形成正确的决策集.本研究采用的是C5.0决策树算法.
1.3 组合分类器法
组合分类器是多种学习算法的组合,是目前比较流行的机器学习算法之一,其主要目的是提升分类的准确率[5].目前,常用的组合模型多为两层结构:第一层为多个不同的学习算法独立地对训练样本集进行学习训练;第二层为一个分类器组合,它对第一层中各分类器的输出进行某种组合(多为线性组合).
通常,组合分类器模型会出现多个分类结果,如何处理和组合成员分类器的分类结果,实现分类器的融合是组合分类器研究中的一个重要部分.目前,对成员分类器分类结果的处理方法主要分为投票法和非投票法[6].
1.4 信用卡数据来源与数据描述
由于目前国内尚没有公开的信用卡持卡人的交易数据,因此本研究实验数据选取自国外某银行发布的信用卡数据.该信用卡数据由8个ASC文件组成:ACCOUNT.ASC,CLIENT.ASC,DISP.ASC,ORDER.ASC,TRANS.ASC,LOAN.ASC,CARD.ASC,DISTRICT.ASC,其包含持卡人以及持卡人对应账户信息所包含的关联信息以及相关数据.数据关联如图1所示.
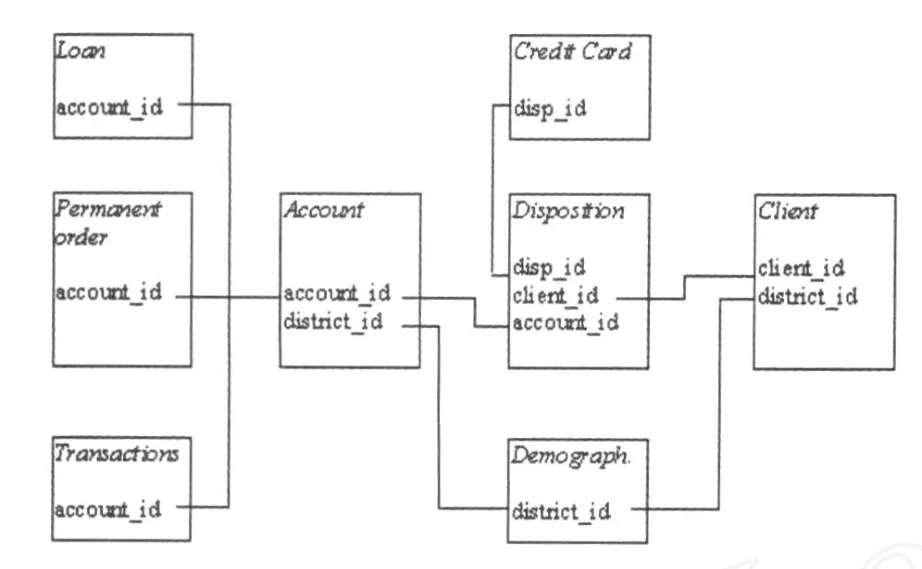
图1 数据关联图
由于上述数据的初始格式为文本格式,本研究选取了SQL Server 2000将其预先处理存储到数据库中,并在数据库基础上对数据进行统计分析和属性抽取.抽取如下13个属性用于后面的数据挖掘训练及测试:①Sex,顾客性别;②Age,顾客年龄;③Amount of loan,顾客的借贷总额;④Loan duration,借贷归还的时间区间;⑤Type of the credit card,顾客所持有的信用卡类别;⑥District,顾客居住的地区;⑦Minimum amount,某时间段内该客户所有交易中的最小额度;⑧Maximum amount,某时间段内该客户所有交易的最大额度;⑨Average amount,某时间段内该客户所有交易的平均额度;⑩Minimum account,某时间段内该账户所有交易的最小额度; ○11Maximum account,某时间段内该账户所有交易的最大额度; ○12 Average account,某时间段内该账户所有交易的平均额度; ○13Credit status,信用卡信誉状态,离散属性,A表示优质信誉客户,B表示非优质信誉客户.
根据数据数量,属性中所对应的某时间段取1年时间为限定条件,其中第13个属性为信用卡信誉状态,该属性是本研究的信用卡信誉检测的目标属性.
1.5 模型建立
本研究采用支持向量机和决策树方法对信用卡信誉检测进行模型的建立,具体如图2所示.
2 实验结果与分析
2.1 实验环境
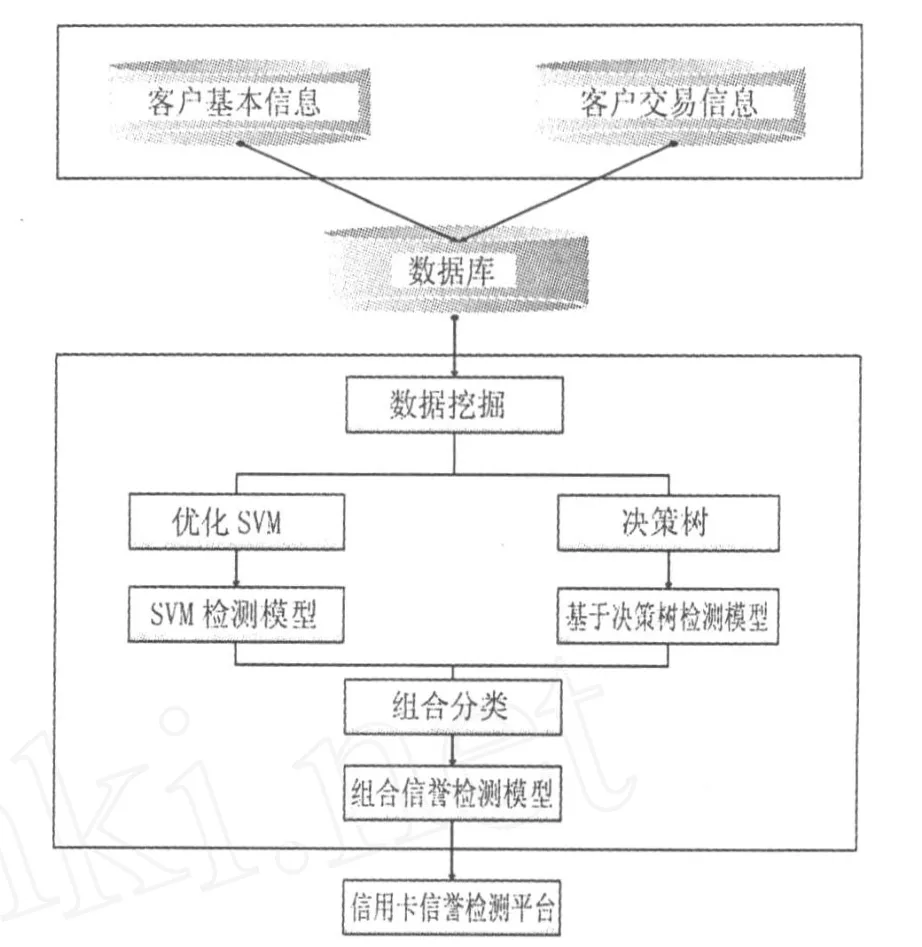
图2 信用卡信誉检测建模示意图
本研究在Window XP的系统环境下,使用SQL Server 2000存储实验数据,利用C#.net作为编程语言来搭建实验环境,构建信用卡信誉检测模型.其中,支持向量机的模型建立结合了LIBSVM的使用.通过数据预处理得到234组用于数据挖掘的有效数据,其中优质信誉客户即A类数据有203组,非优质信誉客户即B类数据有31组.通过非对称信息处理,数据训练集包含51组数据,其中A类数据30组,B类数据21组;数据测试集包含183组数据,其中A类数据173组,B类数据10组.
2.2 评估标准
测试集数据通过信用卡信誉检测模型后,输出结果被划分为两类:A(优质信誉客户)和B(非优质信誉客户).其中分类结果A数据中包含真实信誉为A的数据Ta以及真实信誉为B被误判为A的数据Fa,分类结果B的数据包含Tb和Fb,解释同理.具体而言,
①A的测准率=Ta/(Ta+Fa)
②A的测全率=Ta/(Ta+Fb)
③B的测准率=Tb/(Tb+Fb)
④B的测全率=Tb/(Tb+Fa)
为了避免单次试验结果的偶然性,本研究对数据进行多次随机分组,并将每次分组得到的训练集和测试集作为多个信用卡检测模型建立方法的输入,同时对各个检测方法的检测效果进行比较和评估.
2.3 结果分析
2.3.1 改进的支持向量机方法结果分析.
本研究建立了巴氏距离和Relief结合的支持向量机检测模型.其中巴氏距离算法用于排除与信誉检测关联最小的属性,结合Relief算法后,综合考虑了属性间的关联性,找出利于信用卡信誉检测的属性子集,得到的相关实验结果如表1、2所示.
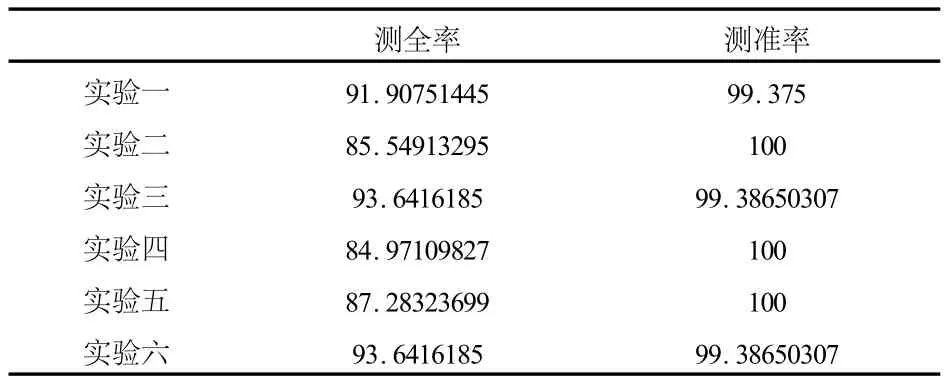
表1 改进的支持向量机中A类预测效果
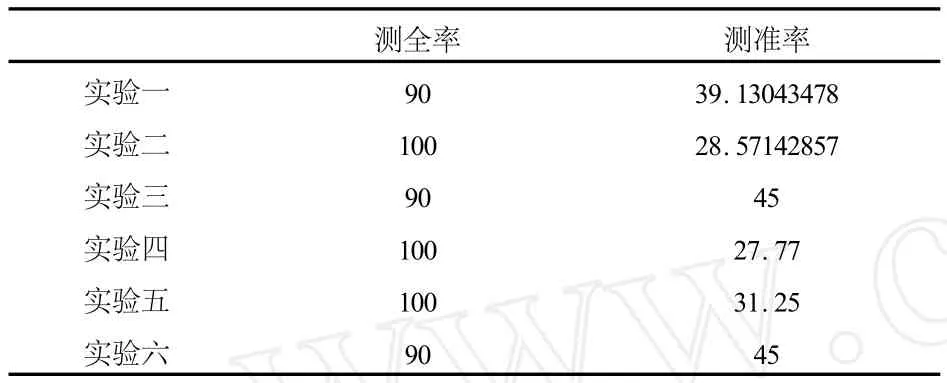
表2 改进的支持向量机中B类预测效果
从表1、2中可以看出,改进的支持向量机方法对A类的分类效果很好,测全率和测准率都很高,且B类的测全率也很高,说明该方法能较好地覆盖到B类,但是它的测准率却很低.
2.3.2 基于决策树模型结果分析.
同时,本研究建立了基于决策树的信誉检测方法,将数据预处理后得到的训练集中所有13个属性数据作为模型建立的输入,训练得到一个检测方法,以此来对测试集进行测试分类,相关实验结果如表3、4所示.
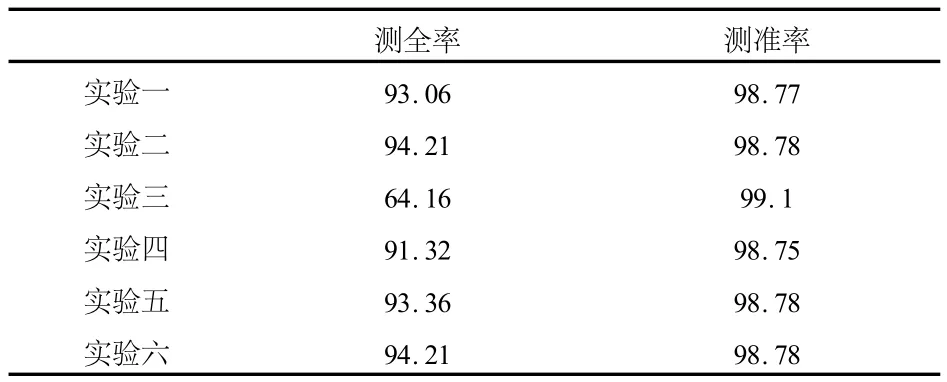
表3 决策树中A类预测效果

表4 决策树中B类预测效果
从表1和表3的比较中可以看出,决策树方法对A类预测效果不论从测全率还是测准率均劣于改进的支持向量机方法,但对B类预测效果的测准率比改进的支持向量机方法高.
2.3.3 组合分类器模型结果分析.
考虑到改进的支持向量机方法对A类的分类效果比决策树方法的信誉检测方法效果好,测全率和测准率都很高,而且对B类的测全率也很高,说明它能较好地覆盖到B类,但是它的测准率却很低.相比而言,决策树模型对B类的测准率相对较高.所以,组合分类器模型将先采用改进的支持向量机信誉检测方法来对测试集进行第一次检测,将检测结果为B的数据再经过决策树信誉检测方法进行第二次检测,相关实验结果如表5、6所示.
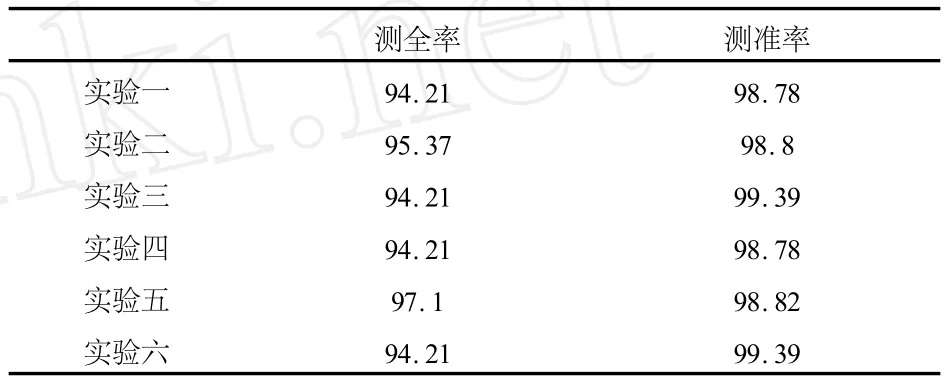
表5 组合分类器模型中A类预测效果

表6 组合分类器模型中B类预测效果
所有试验结束经过统计分析得出实验结果如图3~6所示.
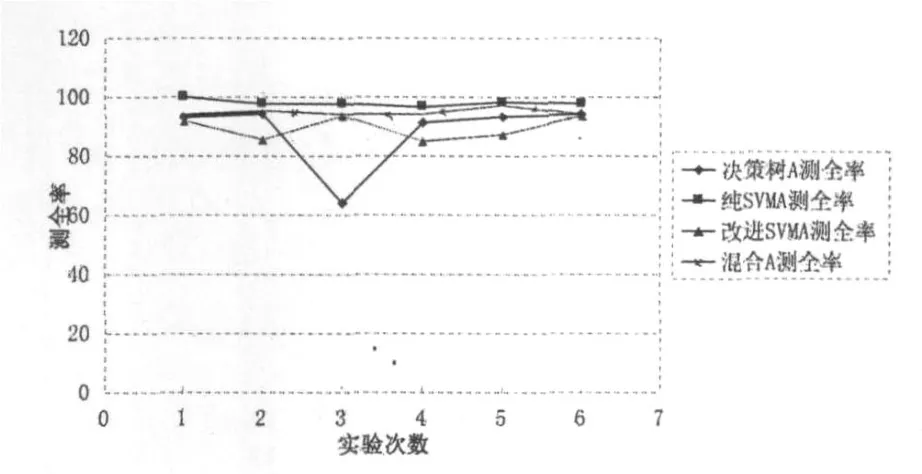
图3 A类测全率比较图
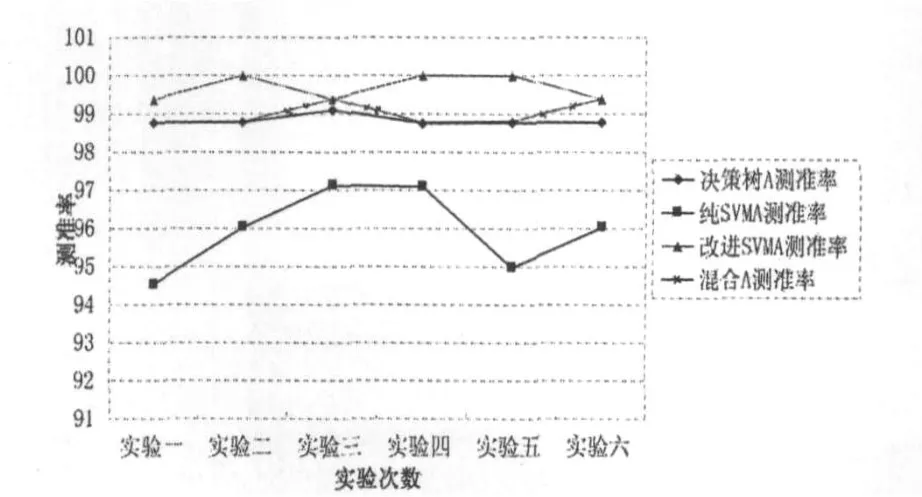
图4 A类测准率比较图
从图3、4可以看出,组合分类器模型对A类的分类效果无论在测准率和测全率上都是比较好的.虽然纯支持向量机方法的测全率最高,但是测准率却很低;改进的支持向量机方法的测准率最高,但是测全率又很低.组合分类器模型则是一种两方面都表现较好的折衷算法.
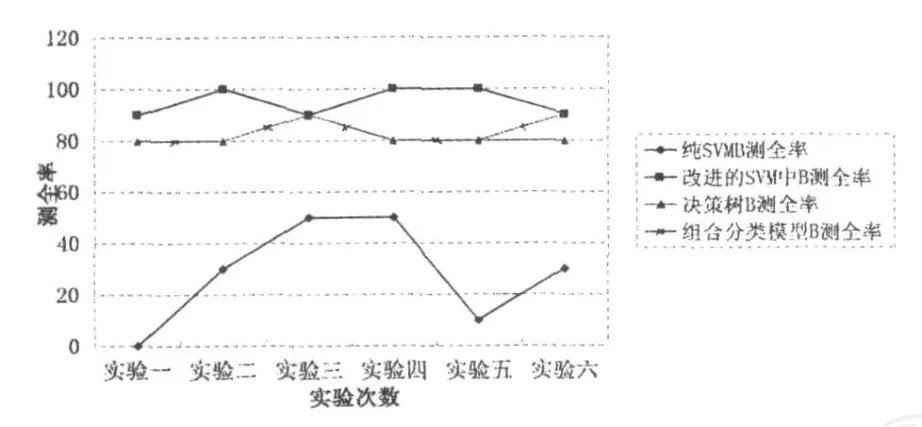
图5 B类测全率比较图
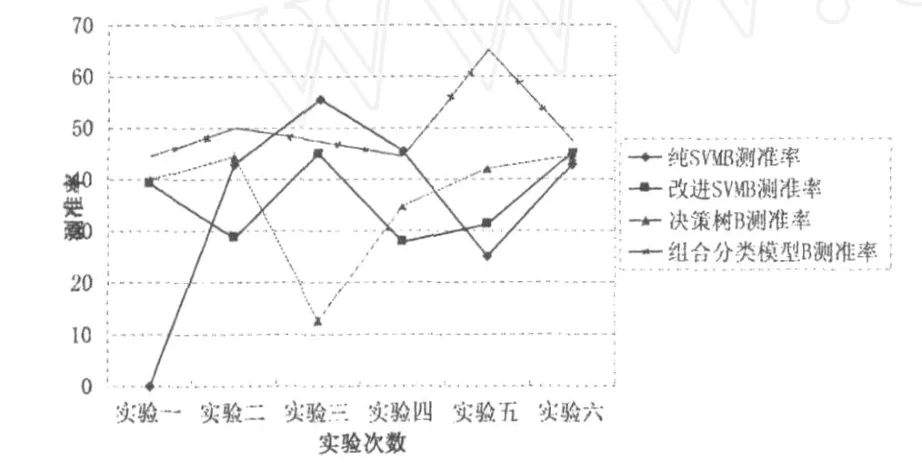
图6 B类测准率比较图
从图5、6可以看出,对于关注的B类,它的测全率仅次于改进的支持向量机方法,但是它的测准率却最高,这也是本研究的希望达到主要研究目的,即模型对非优质信誉客户的检测准确且全面.
3 结 语
本文通过结合改进的支持向量机和决策树方法建立了一个基于组合分类器的信用卡信誉检测模型,实现了准确、有效的客户信用卡信誉检测,本研究在理论上可以丰富信誉检测与数据挖掘领域的研究;在实际中可为银行信用卡风险管理提供有效信息,为银行在以客户为中心的管理理念下,利用信息技术提高银行的核心竞争力提供有力的技术支持.
[1]曹小娟,王小明.金融工程的支持向量机方法[M].上海:上海财经大学出版社,2007.
[2]郑俊翔,宣国荣,柴佩琪.巴氏距离和 K-L交换结合的特征选择[J].微型电脑应用,2004,20(12):12-15.
[3]K ononenko I.Estimating Attributes:Analysis and Extensions of Relief[M].Berlin:Springer-Verlag Publisher,1994.
[4]Quinlan J R.Induction of Decision Tree[J].Machine Learning, 1986,1(1):86-106.
[5]Mitchell TM.机器学习[M].曾华军,张银奎,等译.北京:机械工业出版社,2003.
[6]Anderson E,Weitz B.Determinants of Continuity in Congenital Industrial Channel Dyads[J].Marketing Science,1989,8(4):310-323.
[7]庄玮.基于数据挖掘的信用卡欺诈行为识别模型的研究[D].南京:南京航空航天大学,2008.
Reputation Detection of Credit Card Based on SVM
ZHOU Mi
(School of Science and Technology Application,Quanzhou Normal University,Quanzhou 362000,China)
Credit testing model of support vector machine and construction mehtod of credit testing model based on decision tree were given.Based on the two single classifier,preferences of credift card credit testing supporting support vector machine and decision tree were concluded and summarized.Construction mehtod of combined classification model was proposed based on combination of preference characteristics.
credit testing;support vector machine;decision tree;combined classification;sensitivity;specificity
TP274
:A
1004-5422(2012)03-0239-04
2012-07-06.
周 宓(1981—),女,硕士,讲师,从事计算机算法研究.
文章编号:1004-5422(2010)03-0261-04
猜你喜欢
公民与法治(2022年12期)2023-01-07
计算机应用文摘·触控(2022年8期)2022-05-25
华人时刊(2019年13期)2019-11-26
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
瞭望东方周刊(2017年35期)2017-09-22
中国防伪报道(2016年10期)2016-11-21
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
公民与法治(2016年6期)2016-05-17
华人时刊(2016年19期)2016-04-05
