
基于最大熵与Bootstrapping的关联三元组识别方法
2012-09-11 13:58:34赵乃刚邓景顺
山西大同大学学报(自然科学版) 2012年6期
赵乃刚,邓景顺
(山西大同大学数学与计算机科学学院,山西大同 037009)
基于最大熵与Bootstrapping的关联三元组识别方法
赵乃刚,邓景顺
(山西大同大学数学与计算机科学学院,山西大同 037009)
基于<产品特征,情感词>关联对的缺点,讨论了情感词与否定性副词搭配的必要性,提出了<Pfeature,Flag,Sword>关联三元组,能够更准确地表达文本中相关评论句对产品特征的情感倾向。采用两个步骤来提取关联三元组:首先,利用已训练好的最大熵模型作为分类器,结合Bootstrapping方法完成了产品特征与情感词语关联对的抽取;其次,将情感词前的否定性副词抽取出来,合成关联三元组。
最大熵;Bootstrapping;关联三元组;情感倾向
汽车产品评论通常涉及多个对象(如可能涉及多个品牌、同一品牌的多种车型等),评论者经常就某个或某些属性(如汽车的性能、部件等)进行比较,以区分优劣。比如:“发动机强劲”、“车身平稳”、“性价比高”等。在相关英文的评论中,Nozomi等[1]利用文本挖掘技术,采用对象描述模式<Subject,Attribute,Value>,提出了一种从产品评论中抽取带有主观倾向性的对象描述语句的半自动方法。柴玉梅等[2]对Web文本的褒贬倾向性进行了研究。该文介绍了Web文本褒贬倾向性分类的原理和实现方法,特征选用已有的特征选择方法与褒贬特征提取技术进行选择,使用几种分类算法实现了名人网页的褒贬倾向性分类。
文献[3]提出采用关联对<产品特征,情感词汇>的方式来描述产品特性和其评价词汇间的修饰关系。关联对的情感倾向直接影响到产品评论文本的情感倾向。在实际应用中,它也是产品评价的重要依据。然而,该方法有一定的局限性,当评论句中出现了否定性副词时,该关联对就不能从客观上正确地表达评论句中对产品的情感倾向,因而,提出了关联三元组<Pfeature,Flag,Sword>。
1 关联三元组
1.1 考察情感词与否定性副词搭配的必要性
在众多网上发布的汽车评论中,评论者经常就某个或某些属性,如汽车的部件、性能等进行比较,以区分优劣。比如:“车身平稳”、“发动机有力”等。文献[3]将这些评价的对象(汽车的某些特征)独立出来,称其为产品特征。将能够反映产品特征情感倾向的词汇称为情感词汇。将产品特征和与之关联的情感词汇组合起来,称为关联对。这样,便可以抽象地将<产品特征,情感词汇>关联对理解为句子的一个最基本的情感描述成分。通过对关联对情感倾向的分析,得到文本中评论句子对产品特征的客观情感倾向判别。
例句1:方向盘偏重,灯光偏暗。
从句子中抽取出来的关联对以及关联对情感倾向值:<方向盘,重>-1、<灯光,暗>-1。
由上例可以看出,两个关联对所体现出来的情感倾向均为负面,与文本中评论句子对产品性能的评价倾向是一致的。再看下面一个例句。
例句2:这车的空间不大。
从句子中抽取出来的关联对以及关联对情感倾向值:<空间,大>+1。
在这个例子中,评论句子对产品性能的评价倾向为负面,仅从关联对判断,对产品特征的评价倾向为正面,二者不统一。究其原因,主要是没有考虑评论句子中的否定性副词“不”,所以出现了关联对与句子中产品特征情感倾向的不一致情况。综上所述,否定性副词会影响关联对中情感词的情感极性,所以有必要对这类副词与情感词的搭配进行深入研究。
1.2 关联三元组的定义
基于上面的分析,为了保证关联对与文本评论句中体现出来的产品特征情感倾向的一致性,我们有必要将是否含有否定性副词这一特征嵌入到关联对中,这样便形成了<Pfeature,Flag,Sword>关联三元组。其中,Pfeature表示产品特征;Sword表示情感词汇;Flag是一个判别标志,若情感词汇前未出现否定性副词时,Flag值为+1,否则其值为-1。这样,对于一个产品评论句子,核心的部分就是评论涉及的产品特征、评价产品特征所使用的情感词汇、以及否定性副词判别标志。以后就可以使用这三个核心部分代表一个句子。下面是典型的一个汽车产品评论句子。
“速腾的动力和外型虽好,但安全系数不高。”
在上面句子中,可以提取以下关联三元组,作为句子的核心部分。<动力,+1,好>、<外型,+1,好>、<安全系数,-1,高>。
显然,上面句子完全可以用这三个关联三元组代替,而且很好得反映了评论句子当中对三个产品特征的正确评价。对动力的评价为正面,对外形的评价为正面,对安全系数的评价为负面。
2 最大熵模型及其特征设计
2.1 最大熵模型
最大熵模型是用来进行概率估计的。假设y是某个事件,e是事件y发生的环境,那么y和e的联合概率,记为p(y,e)。若用Y={y1,y2,…,yk}表示所有事件的集合,E={e1,e2,…,el}表示所有的上下文环境集合,那么正确的p应满足熵最大原则:

同时,p要服从样本数据中已知的统计证据。在最大熵模型中,通常采用特征来表示证据。如果限制在训练集中,我们将训练语料中体现的随机向量(y,e)的经验知识设为特征函数fi,它相对于经验概率分布(y,e)的期望值与相对于模型p(y|e)的期望值应相同,即:
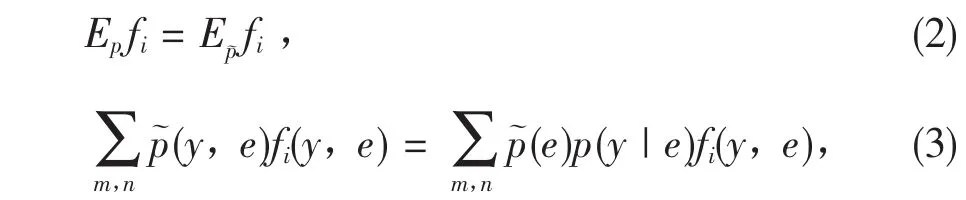
式(2~3)称为约束。这样,可以定义很多这样相关的或不相关的特征函数,从而可以很灵活地将许多分散、零碎的知识组合起来完成同一个任务。给定z个特征函数f1,f2,…,fz,我们可以得到所求概率分布的z组约束为:


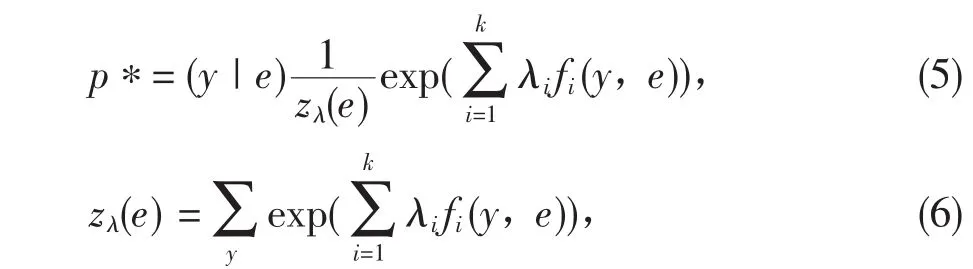
其中,zλ(e)是归一化因子。
λi是关联于特征函数fi的一个参数,可以表示特征函数fi的重要程度。如果通过在训练集上进行学习,知道了λi的值,就得到了概率分布函数,完成了最大熵模型的构造,就可以对未知事件进行分类。
对于本文研究的问题来说,事件y可以是产品特征和情感词汇具有关联关系,也可以是产品特征和情感词汇无关联关系。因此,特征函数可定义成二值函数为f∶e={0,1},fi=1表示环境ei下的产品特征与情感词语组合是关联对,反之fi=0表示环境ei下的产品特征与情感词语组合不是关联对。
2.2 最大熵模型的特征设计
特征设计是基于最大熵原理建模成功的关键,这些特征来源于训练数据中的证据。就寻求产品特征与情感词搭配而言,可以从不同角度进行特征设计,但是需要遵循一条原则——设计的特征样本期望尽量接近总体期望。在文献[3]中,列出了多种最大熵模板的特征选择方法,经过实验验证,其中复合模板7的所有评价指标在所有模板之中是最好的。该模板主要是基于词性与词间距信息的。考虑两个目标词语环境中的几类信息:一是环境中两个目标词前后两个词位的词性信息,二是两个目标词间的距离,距离越小,两个目标词成为关联对的可能性越大,反之越小。当然,该模板还包括另外两个附加信息。否定性副词起到使情感倾向取反的作用,在评论文本中,否定性副词往往会与情感词同时出现,因此,对此附加信息的提取有利于最大熵模板对情感词的识别。“的”字结构表明产品特征是名词性短语的中心词,比如,“别克车的发动机”,其中心词为“发动机”,这样,使得在提取产品特征时更加方便。复合模板设计为:候选产品特征和情感词语前后各两个词的词性+候选产品特征与情感词语间的距离+候选情感词语之前第一个标点符号和情感词语之间是否有否定性副词+候选产品特征前面的第一个词为“的”字。共十一个特征,具体如下:
AposTag-2,AposTag-1,AposTag+1,AposTag+2,SposTag-2,SposTag-1,SposTag+1,SposTag+2,Distance,Fd,De1
其中模板中各符号分别表示:
AposTag-2表示产品特征前第二个词的词性;AposTag-1表示产品特征前第一个词的词性;
AposTag+1表示产品特征后第一个词的词性;AposTag+2表示产品特征后第二个词的词性;
SposTag-2表示情感词前第二个词的词性;SposTag-1表示情感词前第一个词的词性;
SposTag+1表示情感词后第一个词的词性;SposTag+2表示情感词后第二个词的词性;
Distance表示产品特征与情感词的距离;
Fd 表示情感词前第一个标点符号和情感词语之间是否有否定性副词,其值为“1”或“0”;
De1 表示产品特征词前第一个词是否为“的”,其值为“1”或“0”。
例如,训练数据中有句子“速腾/n的/u安全系数/n让/v人们/r感到/v失望/a。/w”,且对词语“安全系数”和“失望”的组合认定是关联对。
通过复合模板可以构造如下特征函数:

3 Bootstrapping方法及其算法设计
3.1 Bootstrapping方法
Bootstrapping[4]是一种被广泛应用于知识获取的机器学习技术。复旦大学王秉卿,张姝等人对中文语料不进行分词的情况下,使用该技术从语料中抽取情感词,通过词和模板之间的关系计算词的情感倾向性。这种机器学习技术首先给定种子集合,通过学习器采用自举的方式来学习新的种子样本。这样用少量的标注训练样本就可以达到传统方法的大标注训练集训练效果。
3.2 基于Bootstrapping和最大熵方法获取关联三元组的算法设计
采用基于Bootstrapping的学习方法,利用文献[3]中已经训练好的最大熵分类器,拟采取两个步骤来获取关联三元组。步骤1:利用最大熵分类器结合Bootstrapping方法取得文本评论句中产品特征与情感词汇关联对;步骤2:根据最大熵模板特征Fd的值来获取否定性副词与情感词的搭配,得到关联三元组。其中步骤1的执行流程可以细化如下:(1)输入初始情感词集;(2)根据情感词提取关联对的最大熵模型特征;(3)执行张乐博士的Maxent包,得到关联对判断结果;(4)根据判断结果并进行适当人工校准提取关联对;(5)提取校准后关联对中的特征;(6)根据特征词提取关联对的最大熵模型特征;(7)执行Maxent包,得到关联对判断结果;(8)根据判断结果并进行适当人工校准提取关联对;(9)提取校准后关联对中的情感词;(10)判断该情感词集是否与上次相同,若不相同则重复执行步骤(2)到步骤(9),若相同则算法结束。
4 实验结果与分析
在实验之前,我们进行必要的数据准备。
(1)文本准备;在网上的汽车评论文本中,往往可以从评论者的立场、观点出发判断出该篇文本对汽车的总体评价。评价结果分成两类,即正面和负面。我们从汽车评论网上下载了对某款汽车的评论文本。用人工方式判断其情感倾向,最后抽取倾向为正面和负面的文本各100篇,共200篇文本。把这200篇文本作为研究对象。
(2)情感词表的准备;在文本的情感分类研究工作中,出现于文本中且带有情感倾向的词汇是文本重要的组成部分,对这些词汇的褒贬义判别也是相当重要的环节之一。文献[5]中的情感词词表SWT对常用情感词汇的倾向作了较明确的标注,将该情感词词表作为后续工作的词汇资源。
(3)情感词种子集的准备;将前面提到的情感词词表中的词汇与经过分词处理的200篇文本通过算法进行词汇对照。选取出现频次最高的20个词作为情感词种子集。这20个词为:好、不错、高、大、差、出色、问题、小、提供、提高、强、达到、新、喜欢舒适、全新、优势、增加、满意、不好。
这样,在前面工作的基础上,利用3.2节中设计的算法首先进行文本中特征与情感词关联对的提取,然后再根据最大熵模板特征Fd的值来获取否定性副词与情感词的搭配,得到关联三元组。实验结果见表1。

表1 关联对提取及否定性副词与情感词搭配的实验结果
结果表明,基于最大熵与Bootstrapping的关联对获取实验中,F值较低。否定性副词与情感词的搭配实验中,F值较高,关于前者,本文只作了初步研究,还有待进一步深入。
5 结束语
本文首先论述了否定性副词与情感词搭配的必要性,解释了什么是关联三元组;利用已训练好的最大熵分类器,从情感词的种子集开始应用Bootstrapping方法来获得文本中的关联对;利用最大熵模板中特征Fd的信息来判断否定性副词与情感词的搭配,获得了关联三元组。这样,利用关联三元组,可将一个文本集表示成非完备信息系统,后续的工作便可以在非完备信息系统的基础上继续深入研究。
[1]Nozomi Kobayashi,Kentaro Inui,Yuji Matsumoto.Collecting evaluative expressions for opinion extraction[A].IJCNLP 2004.Lecture Notes in Artificial Intelligence[C].Sanya city,China.2004:584-589.
[2]柴玉梅,熊德兰,红英.Web文本的褒贬华倾向性分类研究[J].计算机工程,2006(17):89-91.
[3]李伟.关联对识别方法及其在句子情感分类中的应用[D].太原:山西大学,2008.
[4]陈文亮.基于Bootstrapping的文本分类模型[J].中文信息学报,2004,19(2):86-92.
[5]王素格.基于Web的评论文本情感分类问题研究[D].上海:上海大学,2008.
〔责任编辑 高海〕
Correlative Triple Recognition based on Maximum Entropy and Bootstrapping
ZHAO Nai-gang,DENG Jing-shun
(School of Mathematics&Computer Science,Shanxi Datong University,Datong Shanxi,037009)
Based on the shortcoming of“Product feature,Sentimental word”,the new concept of“Pfeature,Flag,Sword”are proposed after discussing the necessary to match the sentimental words with denying adverbial words,which can precisely show the objective sentimental tendency of the text sentence.Two steps are adopted to acquire the Correlative Triple.First,the pair<Pfeature,Sword>is gained by combining Bootstrapping and the Maximum Entropy model trained well as a classifier.Second,the negative adverbs before sentimental words are picked up by using an algorithm,they consist of Correlative Triple.
maximum entropy;bootstrapping;correlative triple;sentimental tendency
O177.1
A
1674-0874(2012)06-0003-04
2012-09-15
山西大同大学教研重点项目[XJY2012105]
赵乃刚(1975-),男,山西应县人,硕士,讲师,研究方向:数据挖掘。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
阅读(快乐英语中年级)(2023年6期)2023-05-24 22:53:36
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
三门峡职业技术学院学报(2021年4期)2021-04-19 09:00:38
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
郑州轻工业学院学报(社会科学版)(2017年3期)2017-07-08 22:02:14
新课程·中学(2015年6期)2015-08-11 11:39:23
高中生学习·高三版(2014年3期)2014-04-29 06:09:37
现代防御技术(2014年6期)2014-02-28 18:26:29
常熟理工学院学报(2013年1期)2013-08-06 12:18:58
