
用于多级交换网络的一种高效自寻路技术
2012-09-03 06:00:52张子为陈志云
电讯技术 2012年10期
倪 杰,张子为,陈志云,许 都
(1.电子科技大学宽带光纤传感与通信教育部重点实验室,成都 611731;2.华为技术有限公司,广东 深圳 518129)
1 引 言
随着网络业务量的日益增长,网络承载的带宽需求渐渐提高。IP技术作为承载网的必然选择,需要满足高带宽的传输与交换压力[1]。为此,大容量可扩展交换设备的设计受到越来越多的重视。目前,业界对可扩展交换结构的研究主要集中在多级交换结构[2],如三级Clos[3]网络结构。基于Clos网络的调度算法有很多,包括传统的RD(Random Dispatching)算法、CRRD(Concurrent Round-Robin Dispatching)[4]算法等。但在高速、高负载量环境下,采用这类算法仍存在一些不足之处,比如CRRD等算法,需采取一定的仲裁策略及多次匹配过程,复杂度较高[5],这大大影响了交换性能。
采用自寻路技术则无需复杂的仲裁机制,交换过程简单易处理。然而,自寻路交换容易造成网络内部阻塞,尤其当网络负载量增大、突发业务增多时,阻塞概率也会随之增大,网络性能随之降低。为了减少连续冲突,进一步提升网络性能,本文基于三级Clos交换网络,提出了一种新的高效自寻路机制。该机制通过在交换网络前端采取“信元间插”策略,保证业务被均匀地发送至网络中,大大减轻了网络内部的连续阻塞,从而减少了信元交换的端到端时延;同时,通过在第一级采取一定的负载均衡分发策略,进一步提升了网络性能。
本文第3节详细描述了三级Clos网络中的新自寻路交换机制,包括“信元间插”的具体策略、第一级交换单元的负载均衡分发方式,以及第二、三级交换单元的自寻路交换,并从理论上分析解释了“信元间插”可以提升网络性能的原因;第4节给出了新自寻路交换机制下的Clos网络性能详细测试结果,将其与传统的CRRD算法进行了仿真对比,进一步证明了该机制的高效性;最后对全文进行了总结。
2 三级Clos交换网络架构
新自寻路交换机制下的三级Clos网络架构主要由流量管理模块和交换结构两部分组成,如图1所示。图中,IM(Input Module)表示输入级,CM(Central Module)表示中间级,OM(Output Module)表示输出级,OQ(Output Queue)表示输出端缓存队列。

图1 三级Clos交换网络架构Fig.1 Three-stage Clos network architecture
图1中,流量管理模块的主要功能是将待交换业务进行“信元间插”,保证业务被均匀地发送至交换结构。
交换结构是整个网络架构的主要组成部分,它采用三级Clos结构,一/三级共r个交换单元;第二级共m个交换单元;第一级的每个交换单元均有 n个输入端口;第三级的每个交换单元均有 n个输出端口。每个交换单元的输出端口处均有一定大小的缓存空间,当数据发生端口争用时,可在此处进行排队。在第一级,每个交换单元设有一组“逻辑指示器”,用来为输入端口处的数据选取合适的第二级交换单元,尽量保证第二级单元的负载均衡。到达第二级交换单元的信元,将基于自寻路技术,判断信元对应的目的模块(即第三级交换单元),然后选择相应路径交换到第三级[6]。到达第三级交换单元的信元,将通过自寻路,选择相应的目的端口输出。
3 三级Clos结构中的新自寻路交换机制
目前很多交换结构采用的分组交换技术是基于信元的(Cell-Based)[7],即对变长分组如IP数据包进行交换前,先切割为多个定长信元。交换结构发送一个信元的时间称为一个“时隙”。本文提出的自寻路机制中,便将采用这种基于信元的交换技术。
3.1 新自寻路交换机制中的“信元间插”策略
在对交换网络调度算法的研究中,一般会假设输入端口到所有输出端口的流量是均衡的,且输出端口的流量是均衡地来自所有的输入端口,这种业务成为均匀业务。但在实际网络环境中,可能有多个输入端口的流量是去往同一个输出端口的,此时就会出现输出端口竞争冲突现象。在竞争过程中,只有一个信元能够顺利到达对应的输出端口,其他竞争失败的信元需在交换结构的输入端或输出端进行缓冲排队,等待下一个时隙被交换。若网络负载量较大,输入端口处的连续信元较多,则可能导致长时间的流量冲突而影响交换网络性能。
新自寻路交换机制中,信元进入Clos交换结构参与交换之前,将首先在流量管理器中缓存,缓存一定的时间间隔后,流量管理器将对所有已缓存信元进行间插。通过“信元间插”策略,可以将每个输入端口处的连续数据包“打散”,使得目的端口相同的业务在时间轴上离散分布,然后均匀地进入交换结构,从而减少各信元在输出端口的连续冲突,减轻网络内部阻塞,提升网络性能。
信元序列准随机化处理的方法有多种,在此采用简单的可硬件快速实现的二进制编码转换策略进行信元间插。每个输入端均有若干待交换的信元,每个信元均对应一个时隙号。对于具有同一目的端口的某连续信元分组,将其对应的所有时隙号的二进制表示逆向读出后,将得到一个新的时隙号序列。将该分组包含的所有信元分配到新的时隙位置上,即可成功地将该连续信元分组在时间轴上均匀地分散开来。下面以包含8个信元的交换帧为例进行说明。
图2表示间插前的某交换帧,A、B、C分别表示信元的目的端口。时隙0、1、2中的3个连续信元,其目的端口均为A;时隙3、4中的两个连续信元,其目的端口均为 B;时隙5、6、7中的3个连续信元,其目的端口均为 C。对目的端口为A的连续信元分组进行分析:0号时隙位对应的二进制表示为0002,反向读出后仍为0002,则新时隙号仍为0;1号时隙位对应的二进制表示为0012,反向读出后为1002,则新时隙号为 4;2号时隙位对应的二进制表示为0102,反向读出后仍为0102,则新时隙号为2。那么,新时隙号序列即为0、2、4。原本处于时隙0、1、2上的信元A1、A2、A3,将被分别分配到时隙0、2、4上。

图2 间插前的交换帧示意图Fig.2 The frame before interleaved
根据表1类推,B1、B2分别分配到时隙1、6上,C1、C2、C3分别分配到隙 3、5、7 上,这样每个连续分组中的信元都可被均匀分散在时间轴上。

表1 二进制编码转换表Table 1 Binary conversion table
对于任意一个连续信元分组,当判断出它的新时隙号序列后,会将原分组包含的所有信元一一顺序地分配到新时隙中。因此,某连续信元分组经间插后,虽然信元不再连续,但该分组包含的所有信元并不乱序,即先后顺序依然不变。间插后的交换帧如图3所示。可以看出,经过间插后,尽量保证了相邻信元的目的端口不同。

图3 间插后的交换帧示意图Fig.3 The frame after interleaved
业务经过信元间插后才能进入交换结构参与交换,交换时长称为一个“交换周期”,记为 TSwitching。在该 TSwitching时间的交换过程中,流量管理器仍然不断地接收前端业务请求,并将它们进行缓存,待该次交换过程结束,便可对新缓存好的业务进行间插,进入下一次交换。一般来讲,业务的间插所用的时间相对于整个处理过程来说是很短的。在一个交换周期中未能交换完成的业务将在下一个交换周期中继续交换,将每个交换周期平均分成多个时隙。从整体上看,交换结构逐时隙地进行交换调度。
3.2 “信元间插”策略的理论分析
本节将从理论上解释“信元间插”策略可以减少流量冲突的原因。
图4为一个 N×N(N表示输入/输出端口总数,N≥2)的交换网络,“IP”表示输入端口(Input Port);“OP”表示输出端口(Output Port);“t”表示第 t个时隙;m(n)表示该处有m(n)个连续信元。

图4 交换网络中的冲突示意图Fig.4 Conflicts in switching network
图4中,在任意“t”时隙,任意两个输入端口 a和b处的信元目的端口均为x,那么此时,OP“x”处即会产生冲突。假设在“t”时刻,输入端口 a处的当前数据包连续长度为m个信元(m≥1),入端口b处当前的数据包连续长度n个信元(n≥1)。在“t+1”时隙,事件“输入端口a和b处的信元再次基于输出端口`x'产生冲突”相当于“入端口 a处的数据包连续长度La,在这段时间内需满足La≥m+1;且入端口b处的数据包连续长度Lb,在这段时间内需满足 Lb≥n+1”。
不同输入端口的数据产生情况,可以被认为是相互独立的事件。因此,事件“输入端口a和b处的信元在t+1时隙再次基于输出端口`x'产生冲突”的概率P可以表示为

下面,我们将对交换网络是否采用“信元间插”这两种情况进行对比分析。
(1)直接交换:即未预先采用“信元间插”策略。业务到来并被切割为信元后,交换网络会根据其目的端口,直接发送。若发生冲突,信元将排队输出。
从长期看来,每个输入端口处产生的数据包长度L可以看作是服从(μ,σ)的正态分布(L>0,μ为数据包长度L的均值)。
正态分布概率密度函数为
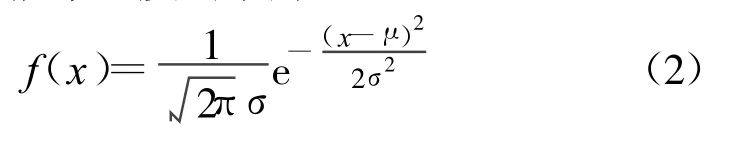
正态分布的累积分布函数为

由正态分布曲线的对称性可知

在上述理论基础上,事件“输入端口a和b处的信元在t+1时隙再次基于输出端口`x'产生冲突”的概率PDirectSwitching满足:
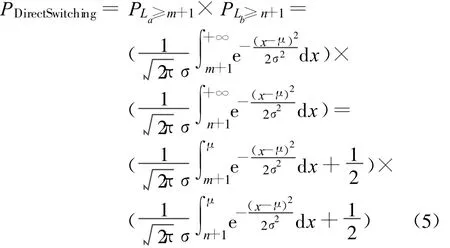
显然,如果 m<μ,n<μ,那么

也就是说,在某时刻“t”,只要入端口a处的当前数据包连续长度La和入端口b处的当前数据包连续长度Lb的值尚未到达μ,那么,在下一个时隙“t+1”,这两个端口基于出端口“x”再次产生冲突的概率满足 PDirectSwitching≥1/4。
(2)“信元间插”后再交换:即数据被发送至交换网络之前,需预先对其进行“信元间插”。输入端口处的数据包经过“信元间插”后,可以被认为是离散分布的。即每个时隙每个信元之间是相互独立的,每个信元的目的端口OP为“x”的概率均为1/N。这种情况下,事件“入端口 a和b处的信元在t+1时隙再次基于输出端口`x'产生冲突”的概率PCellInterleaved满足:

由于 N≥2,且 m ≥1,n≥1,因此 PCellInterleaved≤1/16。当N增大时,PCellInterleaved将更小。
通过以上对比分析可知,PCellInterleaved 信元经间插后,交换结构会逐时隙读取输入端口处的信元。在某一时隙下,某输入级交换单元的所有输入端口处的信元,按照目的模块的不同,将被视为属于不同的业务流[8]。每个第一级交换单元均设有一组“逻辑指示器”,用来指示该单元入端口处的信元应选择的输出端口。分发过程如图5所示。 图5 第一级交换单元内部示意图Fig.5 The first-stage switching unit 信元进入第一级后,交换单元首先判断该信元所属业务流,然后查询该业务流对应的指示器数值,最后将该信元发往指示器对应的输出端口处进行排队输出。每处理完一个信元,指示器数值加一,并基于该交换单元输出端口总数做取模运算。 在每个周期的初始时刻,该交换单元中所有指示器的值都将进行一次初始化处理,不同指示器的初始值是不同的:第一级模块i中,业务流j对应的指示器初始值为(i+j)mod m。其中,i为该第一级交换单元的编号(0≤i≤r-1,r为第一级交换单元总数);j为业务流编号(0≤j≤r-1,r为第一级交换单元总数);m为一个第一级交换单元的输出端口总数(即中间交换单元总数)。 第一级的信元按照指示器选取输出端口后,相当于选取好了第二级交换单元。采用这样的分发策略可以在一定程度上保证第二级交换单元的负载均衡。 第二级和第三级交换单元的每个输出端口处均有一个缓存队列。到达第二级交换单元的信元,将采用自寻路技术,即首先判断信元将去往的目的模块(即第三级交换单元),然后选取对应的出端口缓存队列,排队交换到第三级。第三级交换单元对于到来的信元,将基于自寻路方式,首先判断信元将去往的目的端口,然后选取对应的缓存队列排队输出。 基于本文第3节描述的新自寻路交换机制,我们利用C++语言对图1所示的三级Clos交换网络架构进行了多种配置下的仿真。 注意:仿真中的分组长度等参数设置并不完全代表真实网络情况,只是为了突出算法的性能而选取的特殊值,但这并不影响对新机制性能本身的考察。仿真结果中的时延指信元进入交换网络第一级,到离开交换网络第三级所用的时间,时间计量单位为“时隙”,一个信元对应一个时隙。 (1)本部分对是否预先采用“信元间插”策略的三级Clos网络时延性能进行仿真对比。 仿真基本配置如下:网络规模为m=n=r=8;分组长度以1 024 byte为均值正态分布,定长信元长度为64 byte,一个交换周期包含2 048个时隙,即将每2 048个信元作为一帧;负载量为10%~98%。 图6给出了两种情况下的信元平均网络时延随网络负载量的变化曲线。可以看出,在预先经过信元间插处理的情况下,信元平均时延明显减小。这正是由于“将业务打散再分发”这种处理策略使得前端信元在交换周期中离散分布,大大减少了网络内部阻塞,从而保证了流信元端到端的低时延交换。 图6 新自寻路机制中“信元间插”对网络时延的影响Fig.6 Average delay with andwithout“cell interleaving”in the new self-routed switching scheme (2)本部分通过改变分组的平均长度(即信元的平均连续长度),考察了新自寻路交换机制在分组平均长度不同情况下,信元平均网络时延随负载量的变化情况。 分组长度分别以512 byte和1 024 byte为均值正态分布,其余配置与(1)相同。通过图7可以得知,当分组长度变化,新的自寻路交换方式仍能较好地将业务均匀分散开来。 图7 新自寻路机制中分组长度对平均网络时延的影响Fig.7 Average delay under different configurations of packet length in the new self-routed scheme (3)第3节中指出,“交换周期”的大小是可配置的。当分组平均长度一定时,“交换周期”大小不同,信元平均网络时延也不同。本部分考察了“交换周期”的设置对网络时延的影响。 交换周期分别设为 512、1 024、2 048、4 096 个时隙,即分别以每 512、1 024、2 048或4 096个信元为一个交换帧,其余参数配置与(1)相同。 图8给出了不同交换帧长度下的信元平均网络时延随负载量的变化曲线。可以看出,当交换帧长度增大时,信元平均网络时延逐渐增大。负载率在90%以上时尤为明显。通过进一步仿真研究可以得知,这主要是由交换结构第三级的时延引起的:交换帧长度越长,在同一时隙下不同输入端口处的信元,它们的目的输出端口相同的概率也会越大。 图8 新自寻路机制中“交换帧”长度对平均网络时延的影响Fig.8 Average delay under different configurations of switching frame length in the new self-routed scheme (4)为了进一步体现新自寻路机制对网络性能的影响,本部分将其与传统的CRRD算法进行了对比。 仿真配置如下: “CRRD”:m=n=r=8。分组长度以1 024 byte为均值正态分布,定长信元长度为64 byte,匹配迭代次数为1,网络负载量为10%~98%。 “新自寻路交换机制”:m=n=r=8。分组长度以1 024 byte为均值正态分布,定长信元长度为64 byte,一个交换周期包含2 048个时隙,每2 048个信元被看做一个交换帧,然后进行信元间插;网络负载量为10%~98%。 图9给出了两种机制下,交换网络中的信元平均时延随负载量的变化。对比可以看出,新自寻路交换机制下,交换结构中的信元时延性能相比于CRRD有明显优势(注意:为了更好显示对比结果,曲线图采用了半对数坐标,即纵坐标采用了基数为10的对数刻度,横坐标仍为普通的等距刻度)。 图9 CRRD和新自寻路机制下的信元平均网络时延Fig.9 Average delay of CRRD and the new self-routed scheme 多级交换网络调度算法的设计会直接影响网络性能,因此对大容量调度算法的研究是很有必要的。本文提出的新自寻路交换机制可通过在交换网络前端采取“信元间插”策略,重新为信元合理分配时隙,大大减轻网络内部的连续冲突;同时,通过在第一级设置逻辑指示器,为不同的业务流选取合适的交换单元,一定程度上保证了第二级负载均衡。 理论分析和仿真实验表明,在平均分组长度或交换帧长度变化的情况下,新自寻路交换机制均有良好的网络时延表现。相比于CRRD等传统交换调度算法,该机制在网络性能上优势明显。新自寻路交换机制中的“信元间插”策略,不仅可以应用于三级Clos交换网络,对其他多级交换网络的工程实践同样具有一定的参考价值。 本文提出的交换机制是通过间插将输入端的业务在“时间轴”上打散,那么是否可以用类似的思想,通过将业务在“空间”上均匀打散来减少网络冲突,获得较好的网络性能,这可以作为下一步的研究方向。 [1] 戴晓慧.对十二五期间信息通信业发展的思考[EB/OL].2010-12-22[2012-09-04].www.ccidcom.com/html/yaowen/201012/22-12/132044.html.DAI Xiao-hui.Reflections on the development of information and communication industry during the second five[EB/OL].2010-12-22[2012-09-04].www.ccidcom.com/html/yaowen/201012/22-12/132044.html.(in Chinese) [2] Chao H J,Park J,Artan S,et al.True Way:a highly scalable multi-plane multi-stage buffered packet switch.Workshop onHigh Performance Switching and Routing[C]//Proceedings of 2005 IEEE Workshop on High Performance Switching and Routing.Hong Kong:IEEE,2005. [3] Clos C.A study of non-blocking switching networks[J].Bell System Tech Journal,1953,32(2):406-424. [4] PunK,Hamdi M.Dispatching schemes for Closnetwork switches[J].Computer Networks,2004,44(5):667-679. [5] Lei Wen,Xu Du.Asynchronous credit-based scheduling scheme for a multi-stage network[C]//Proceedings of 2005 International Conference on Communications,Circuits and Systems.Hong Kong:IEEE,2005:668-672. [6] 李辉,王秉睿,黄佳庆,等.负载均衡自路由交换结构[J].通信学报,2009,30(5):1-8.LI Hui,WANG Bing-rui,HUANG Jia-qing,et al.Load-balanced self-routing switching structure[J].Journalon Communications,2009,30(5):1-8.(in Chinese) [7] Ganjali Y,Keshavarzian A,Shah D.Input Queued Switches:Cell switching vs.packet switching[C]//Proceedings of the Twenty-Second Annual Joint Conference on Computer and Communications.[S.l.]:IEEE,2003:1651-1658. [8] Smiljani A.Rate and delay guarantees provided by Clos packet switches with load balancing[J].IEEE/ACM Transactions on Networking,2008,16(1):170-181.3.3 第一级交换单元中的“负载均衡分发”

3.4 第二/三级交换单元中的“自寻路交换”
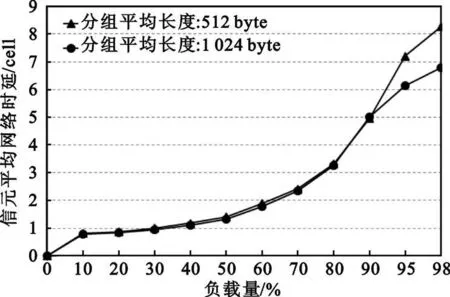
4 仿真分析



5 结束语
猜你喜欢
科学家(2021年24期)2021-04-25 13:25:34
电子制作(2019年23期)2019-02-23 13:21:12
测控技术(2018年6期)2018-11-25 09:50:10
铁道通信信号(2018年9期)2018-11-10 03:26:46
网络安全和信息化(2017年6期)2017-11-23 08:36:18
舰船电子对抗(2016年3期)2016-12-13 05:15:55
广西大学学报(自然科学版)(2016年5期)2016-11-12 06:28:54
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
电测与仪表(2016年17期)2016-04-11 12:38:28
电脑迷(2015年6期)2015-05-30 08:52:42
