
一种高分辨率深度图实时提取算法与硬件实现
2012-08-10 04:44王建伟滕国伟李贺建邹雪妹
电视技术 2012年23期
王建伟,滕国伟,2,李贺建,邹雪妹
(1.上海大学通信与信息工程学院,上海 200072;2.上海国茂数字技术有限公司,上海 201204)
责任编辑:哈宏疆
在多视点或自由视频3DTV实时显示系统中,包含了前端视频采集、编码传送、解码显示等部分。多视点或者自由视点视频其数据量远比单视采用H.264编码方法的数据量要大。一般而言,若考虑的多视点是9个视点,如果9个视点采用基于H.264联播方式编码,数据量就是原来的9倍。鉴于此,2009年JVT推出了MVD(多视+深度)数据模式。在该模式中,对传输的视频端除了原来视点的纹理彩色视频外,对于每个视点都附加一个与之相应的深度图视频。提出深度图的概念有2个最直观的好处:
1)深度图较平坦,对编码来说效率极高,即使采用H.264的编码方式其编码比特率也仅是彩色视频编码比特率的20%~30%。
2)通过提取具有场景几何信息的深度,可绘制出高质量的虚拟视。
综上所述,快速准确地提取深度图是实时3DTV系统的关键,也是MVD模式的核心,因此诸多学者对此从未停止探索的脚步。
就深度提取而言,现阶段的主要研究重点是对极线校正过的测试序列提取准确的深度信息,减少遮挡和误匹配点的比率,提高绘制端虚拟视频的质量,并且提高深度信息的提取速度。最常用的图像像素点的匹配方法是立体匹配算法(stereo matching),通常来说,其可分为局部算法和全局算法。全局匹配算法一般用相容性约束和平滑性约束来构成一个评价函数,再通过各种最优算法求得评价函数的最小值。由于基于全局的匹配算法是全局寻优,所以匹配准确性较高,可直接获得致密的视差图,尤其是采用图割思想的算法在精度上取得了很好的效果。但是当前应用比较广泛的全局立体匹配算法大多还存在着自身的缺陷,例如图割匹配算法能够实现较好的匹配效果,但其不可避免的缺点是计算量过大,难以满足实时性要求;动态规划法可得到稠密的视差图,但不能得到较好的匹配精度,水平和垂直连续性约束整合不够,所得的视差图会存在瑕疵。局部算法中大多是采用窗口的匹配算法,先根据图像特点制定相应的相似度测量准则,在一定的区域上来计算相似度。局部匹配算法实现简单,速度快,但对噪声较敏感,对遮挡区域、无纹理区域和视差不连续区域的匹配效果不理想。也有通过计算角点、特征点的基于特征的匹配方法,但是如果这样做同样难以得到致密的像素级的深度图。就最新的发展来看,对于深度提取的实时性要求越来越高,窗口式的局部算法应用较广,具体过程为通过视差d将参考图像和目标图像的窗口联系起来,通过两个窗口内数据的相似度测量,在诸多视差参考值中利用WTA(Winner Takes All)原理选取其中最为相似的一个视差值作为结果。
1 实现平台
对于深度图的提取,从研究方向和实现方法上都大致可分为软件和硬件两大类。软件方面可对深度提取方法进行灵活配置,但由于普通计算机处理器的指令循环机制,海量数据操作会造成大量结构指令周期延迟而使得难以达到实时性的要求。例如日本名古屋大学深度估计参考软件DERS,其对深度图的提取从匹配区域选择、相似准则、时间一致性增强、后处理等方面都进行了优化,但其执行速率远远不能满足实时的需求。即使不选择时间一致性增强等方面的功能,该软件在2.53 GHz的PC平台上对一帧1024×768深度图进行提取所需时间也在5 min以上。
在实时3DTV系统中,深度图的提取必须是实时的,这就要求系统必须高速处理大量数据,而这必须在合适的硬件平台上用合理的系统架构才能实现。从20世纪80年代末期人们就开始研究利用各种硬件架构来实现深度提取。S.Kimura和T.Shinbo等人设计了一种基于卷积器的实时立体器(SAZAN)以20 f/s(帧/秒)的速率生成320×240分辨率的深度图[1]。A.Darabiha和J.Rose等人使用Xilinx XC2V2000 FPGA以大约30 f/s的速率生成640 ×480分辨率的深度图[2]。
可用于深度图提取的硬件平台有多种,针对立体视觉的硬件加速方法可分为以下4类[3]:
1)ASIC(通用集成电路)。采用ASIC可以使立体视觉的硬件加速达到最优性能,Y.Jia和X.Zhang等人利用DeepSea处理器设计了立体视觉系统[4]。但ASIC投入成本过高,开发周期过长,灵活性差,难以普及使用。
2)DSP。DSP的哈佛总线结构使其能够适应大数据量的通信需求,内部的硬件乘法器等资源以及多级流水等特性也能够很好地满足设计的高强度需求。文献[3]中提出了立体匹配算法的DSP实现方法,利用TiC64xDSP并行计算进行立体匹配。
3)GPU(图形处理卡)。GPU在处理视频数据时不占用CPU资源,可多条绘制流水线并行计算,能够高密集地运算,且具有超长图形流水线。文献[5]提出了利用GPU进行立体匹配得出深度图。
4)FPGA(现场可编程门阵列)。FPGA自身的结构很适合底层立体视觉的单指令多数据流并行处理,其内部大量的存储单元,也可以很好地实现立体视觉算法的多级流水特性。文献[6]和文献[7]分别提出利用FPGA进行立体匹配,从而快速得到深度图。
基于现有实验条件,根据census transform、立体匹配、流水的WTA算法特征,选择FPGA作为平台对算法进行实现。
2 立体匹配算法
立体匹配算法是立体视觉中的关键算法,假设两路视频是经过水平矫正的,根据硬件平台特点,对欲求取视差的两路视图分别进行CT变换,然后将参考视的某一像素点作为参考像素,在视差视图的视差范围内求出所有像素点与该参考像素点census序列的汉明距,接着进行WTA最优选择,视差范围内与参考像素汉明距最小的像素点可视为与参考像素点相似度最高,即为该参考视点对应的匹配点,该匹配点位置与参考像素位置的相对平移量即为参考像素的视差,最后将所得视差转换为深度图。
2.1 CT变换
基于实验效果和实验条件的综合考虑,本文选择CT变换(census transform)[8-9]作为基本原理进行立体匹配,该算法是由Zabih和Woodfill提出的一种非参数化的立体匹配方法。以下就实际运用对该算法的执行过程进行说明:在视图中选取任一点,以该点为中心划出一个例如3×3的矩形,矩形中除中心点之外的每一点都与中心点进行比较,灰度值(intensity value)小于中心点即记为0,灰度大于中心点的则记为1,以所得长度为8的只有0和1的序列作为该中心点的census序列。按照此过程,将视图上的所有点都转换成相应的census序列,变换过程如图1所示。

图1 CT变换过程
由上可知,CT变换是CT窗口内中心像素与周围像素相比较的结果,是CT变换窗口中心像素的一种特征表示。随着CT窗口和视差搜索范围的增大,FPGA资源占用率将急剧增加[10]。对于m×m大小的CT窗口,n×n大小的立体匹配范围(匹配视图大小),及r大小的视差搜索范围,求取视差的计算量为:(r+1)·m2·(n2-1)次的像素值相减,r·m2次对n2-1长度的比特向量进行汉明距计算,r·m2次汉明距相加[2]。由此可知,CT变换窗口大小、匹配视图的分辨率及视差范围的大小对于深度提取的执行效率和资源占用有着决定性的影响。过大的视差图分辨率、CT变换窗口都会对实现平台造成过大的计算负载。与此同时,CT变换窗口越大,中心像素与周围像素比较结果越全面,那么系统后端根据汉明距所求的视差值就越准确。
为适应于高分辨率的深度图提取,同时便于增大CT变换窗口和视差搜索范围来提高视差提取结果准确度,而又不至于对执行效率和资源占用率造成过多影响,本文提出大范围稀疏CT变换,使变换窗口的中心像素在45°十字形方向上隔行隔列地与周围像素进行比较,其他位置上像素点的比较则省略。如图2所示,CT变换窗口为15×15,census序列长度由原来的224降为16,使匹配精度与复杂度之间达到一个较好的平衡。

图2 大范围稀疏CT变换过程
2.2 汉明距计算
所谓图像匹配就是在视差图中找出与参考像素点相似度最高的点,而汉明(hamming)距正是视差图像素与参考像素相似度的度量。具体而言,对于欲求取视差的左右视图,要比较两个视图中两点的相似度,可将此两点的census值逐位进行异或运算,然后计算结果为1的个数,记为此两点之间的汉明值,汉明值是两点间相似度的一种体现,汉明值愈小,两点相似度愈大。由上可知census序列度量的是一个矩形的中心像素和周围像素的灰度值比较结果,并非像素灰度值本身,因此对于由光照不均匀引起的左右图像亮度差异以及窗口内的随机噪声是稳健的。
3 算法实现架构
实现架构充分利用FPGA的并行性和流水结构。在FPGA中取15个Block RAM分别作为Line Buffer,对一幅图像的15行分别进行缓存,每一个Block RAM的大小取4096 bit,支持视差图的分辨率高达1920×1080。以视频数据的行、帧同步信号及数据有效信号作为控制信号控制算法变换过程中的时序,在第15个Line Buffer存在有效数据输出之后即可对前后15行范围内相应位置上的数据进行比较,从而进行CT变换,如图3中①②部分;两路分别进行CT变换得到相应的census序列,在视差视图上将视差范围内所有像素的census序列分别与参考视图中指定像素的census序列进行异或,所得结果分别是这些像素与参考像素的汉明距,如图3③部分;将所得汉明距进行如图3④部分的WTA最优选择,得出视差范围内具有最小汉明距的像素的位置,该位置即为参考像素对应视差;最后一步如图3⑤部分所示,将视差转换为深度即可。需要补充的一点是视差和深度只是几何关系转换,可采用查找表结构实现。
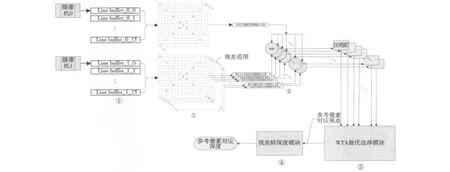
图3 深度提取算法系统架构
4 实验结果及分析
实验取champagne视差序列相邻两个视点同一帧图像,图像分辨率为1280×960,通过本文提出算法进行立体匹配和视差提取,结果如图4所示。

图4 深度图的提取结果
从图4b可以看到在图像背景处深度数据有部分错误,这是由于图像背景呈单一无纹理区域,图像匹配部分发生错误所致,对于重复纹理区域会产生同样的匹配错误。在立体匹配过程中类似误匹配的问题几乎是无法避免的,在本文给出的系统中可以后续通过增大CT变换窗口大小,增加LR-check(左右连续性检查)、单值检验、尖峰消除、亚像素估计等后处理对匹配准确性进行改善。
在深度提取算法的硬件实现过程中,FPGA选用Altera Arria II GX260,其主要内部资源数如表1所示,这些资源对于存储和高速并行运算都是很有优势的。深度提取Verilog程序经过综合、映射、翻译、布局布线后,连同视频采集卡SDI协议解析、DDR2访问、PCIE访问等功能,资源占用情况如表2所示。

表1 FPGA主要参数

表2 程序适配后FPGA资源占用情况
5 总结
普通计算机处理器的指令循环机制造成了其无法胜任深度实时提取的事实,而FPGA的并行结构和流水结构的固有特点恰恰能够在海量数据并行处理方面发挥其特长。本文利用经过改进的大范围稀疏CT变换,通过对大量视频数据的并行计算进行立体匹配,并通过流水线结构对最优像素点进行选择,并在FPGA平台上实现。该方案能够实现高分辨率深度图的实时提取,并能自动适应不同分辨率,配合深度图后处理操作,将成为实时3D系统中重要组成部分。
通过深度图提取算法的硬件实现过程中,行帧同步信号的调整是实际操作过程中的又一难题,因为得到的深度图和参考视图只有和同一个位置的像素上一一对应,才使得在3DTV的系统终端进行准确的绘制成为可能。这就要求统筹考虑Line Buffer缓存、CT窗口大小、WTA过程寄存等模块,分别对行同步信号、帧同步信号、数据使能信号进行准确的缓存调整,使其与深度数据严格同步。另外,在Line Buffer写数据时,将其写地址在视频数据时钟的下降沿进行变化,这样可以有效保证数据写入的建立保持时间。系统每一个模块根据所得结果时序对同步信号利用寄存器进行寄存或利用FIFO进行缓存。最后使得深度图上的有效值与参考视图每一个有效像素一一对应。
[1]KIMURA S,SHINBO T,YAMAGUCHI H,et al.A convolver-based realtime stereo machine(SAZAN)[C]//Proc.IEEE Comput.Soc.Conf.Comput.Vision Pattern Recognit.,1999.Fort Collins,CO:IEEE Press,1999:457-463.
[2]DARABIHA A,ROSE J,MACLEAN W J.Video-rate stereo depth measurement on programmable hardware[C]//Proc.IEEE Comput.Soc.Conf.Comput.Vision Pattern Recognit.,2003.Madison,WI:IEEE Press,2003:203-210.
[3]陈登,白洪欢.Census立体匹配算法的DSP实现[J].科技通报,2008,24(6):860-865.
[4]JIA Y,ZHANG X,LI M,etal.A miniature stereo vision machine(MSVM-III)for dense disparity mapping[C]//Proc.17th Int.Conf.Pattern Recognit.Cambridge,U K:IEEE Press,2004:728-731.
[5]KAO W C,JENG B C,CHEN T H,et al.Real-time depth map estamation for stereoscopic displays with GPU[C]//Proc.2011 IEEE 15th International Symposium on Consumer Electronics. [S.l.]:IEEE Press,2011:228-231.
[6]JIN S,CHO J,PHAM X D,et al.FPGA design and implementation ofa real-time stereo vision system[J].IEEE Trans.Circuits and Systems for Video Technology,2010,20(1):15-26.
[7]JOHNSON-WILLIAMS N G,MIYAOKA R S,LI X,et al.Design of a real time FPGA-based three dimensional positioning algorithm[J].IEEE Trans.Nuclear Science,2011,58(1):26-33.
[8]ZABIH R.Non-parametric local transforms for computing visual correspondence[C]//Proc.ECCV ’94. [S.l.]:IEEE Press,1994:150-158.
[9]ZABIH R.Individuating unknown objects by combining motion and stereo[D].Stanford,CA:Stanford University,1994.
[10]LONGFIELD S,CHANG M L.A parameterized stereo vision core for FPGAs[C]//Proc.IEEE Symposium on Field Programmable Custom Computing Machines,2009.[S.l.]:IEEE Press,2009:263-266.
猜你喜欢
上海师范大学学报·自然科学版(2021年4期)2021-09-23
计算机应用(2019年3期)2019-07-31
测绘科学与工程(2017年3期)2017-08-16
测绘科学与工程(2017年1期)2017-05-04
软件导刊(2016年9期)2016-11-07
浙江大学学报(工学版)(2016年11期)2016-06-05
中国铁路文艺(2016年6期)2016-05-14
科技视界(2016年2期)2016-03-30
应用数学与计算数学学报(2014年4期)2014-09-26
电视技术(2014年19期)2014-03-11
