
基于配价结构的词汇化句法分析模型
2012-07-31 13:07袁里驰
中南大学学报(自然科学版) 2012年5期
袁里驰
(江西财经大学 信息学院,数据与知识工程江西省重点实验室,江西 南昌,330013)
句法分析[1]又称文法分析,通过构造句法树以确定句子的结构以及各组成成分之间的关系。句法分析是自然语言理解的一个关键组成部分,是对自然语言进行进一步语义分析的基础。在自然语言理解中,准确的实体识别、事件识别等信息抽取任务和语义角色标注、问题分类等深入的自然语言处理任务都必须基于可靠的句法分析结果。句法分析的研究大体分为 2种途径:基于规则的方法和基于统计的方法[2-9]。基于规则的方法是以知识为主体的理性主义(Rationalism)方法,以语言学理论为基础,强调语言学家对语言现象的认识,采用非歧义的规则形式描述或解释歧义行为或歧义特性。基于统计的句法分析必须以某种方式对语言的形式和语法规则进行描述,而且这种描述必须可以通过对已知句法分析结果的训练获得,这便是句法分析模型。概率上下文无关文法(PCFG)是将统计方法引入到上下文无关语法规则系统而形成的语法规则系统。然而,经典的PCFG实际上是建立在一些非常理想化的独立性假设基础之上,而这些假设并不符合实际,于是,造成PCFG的实际效果不理想。目前的概率上下文无关语法研究主要集中在如何突破这些独立性假设上。通过逐步放宽这些假设条件,分析的正确率得到很大提高。词汇化的句法分析是目前自然语言处理研究的趋势和热点,在PCFG中引入词汇信息,构成了词汇化的PCFG,弥补了词汇信息的不足。句法结构是句法形式和语义内容的统一体。对句法结构不仅要进行形式分析例如句法层次分析、句法关系分析以及句型分析等,而且要进行种种语义分析。对句法结构的语义分析越全面、越深刻,就越有可能对句法形式上的各种现象以科学合理的解释。目前的词汇化句法分析如中心词驱动句法分析模型、依存语法仅仅考虑词语之间的语义依存关系[10-13],没有引入更多的反映词语语义特点的信息,如语义类[14-16]、语义搭配等语义信息,而这些语义信息对句法分析和语义计算是至关重要的。现有主流的句法分析理论并没有有效刻画出汉语的本质特性,导致目前汉语句法分析和语义计算的效果与英语相比相差较大。在汉语中,配价结构可以较好地刻画汉语句子的句法结构和语义构成关系,因此,有必要更系统、广泛地研究形式化语法理论,尤其是配价语法,并在此基础上建立句法分析模型。
1 配价语法
依存语法由法国语言学家Tesniere于1959年提出的,依存语法是天然词汇化的,直接按照词语之间的依存关系构建模型。由于依存语法中词汇的依存本质是语义的,而不同语言间的语义层面是相通的,因此,依存语法是一种跨越语言界限、客观揭示人类语言内在规律的句法理论。与短语文法不同,依存文法理论认为每个句子中存在1个唯一中心词,支配着句子中其他所有的词,其他词直接或间接依赖于中心词;同时,句子中除了中心词外每个词都只被1个词支配。依存文法可以使用依存句法树表示,依存分析的结构没有非终结点,词与词之间直接发生依存关系,构成1个依存对,其中一个是核心词,也叫支配词,另一个叫修饰词,也叫从属词。依存关系用1个有向弧表示,叫依存弧。在本文中,规定依存弧的方向是由从属词指向支配词。
Collins提出的中心词驱动句法分析模型[17]将词汇依存关系引入到文法中,同样,依存语法直接按照词语之间的依存关系构建模型。可以说,目前的词汇化句法分析仅仅考虑词语之间的语义依存关系,而没有引入更多的反映词语语义特点的信息,如语义类、语义搭配等语义信息。如在句子“Astronomers saw stars with telescopes”中词“telescopes”在语义搭配上既与其直接的核心词“with”有关,也与整个句子的核心词“saw”有关,如果采用依存分析法,由于受依存语法公理的制约,“telescopes”和“saw”之间无法建立依存关系。同样,在汉语句子“王冕七岁时死了父亲”中,若采用依存分析法,由于受依存语法公理的制约,“王冕”和“父亲”之间无法建立依存关系,而这种关系对句法分析是至关重要的。
配价语法与依存语法一样,同样被认为是来源于法国语言学家特斯尼耶尔的语言学思想。按照陆剑明的《现代汉语配价语法研究》序言中的说法[19],“价”(valency/valenz,亦称“配价”/“向”)这一术语源自化学,化学中“价”的概念用于说明在分子结构中各元素原子数目之间的比例关系,而特斯尼耶尔在语法学中引进“价”的概念,是为了说明1个动词能支配多少个名词词组。如“吃”是1个二价动词,需要支配2个名词词组,分别说明“谁吃”和“吃什么”;而“给”是1个三价动词,需要支配3个名词词组,分别说明“谁给”、“给谁”、“给什么”。不难看出:配价语法和句子级的语义计算(特别是语义角色标注)有着紧密的联系。现在,配价的研究已经不仅仅局限于动词,形容词和名词的配价也有很多人在研究。如形容词“年轻”和名词“姐姐”都是一价,分别需要支配1个名词词组,用于说明“谁年轻”和“谁的姐姐”。
国内配价语法研究方面的著作除了《现代汉语配价语法研究》[17,19]以外,主要还有袁毓林的《汉语动词的配价研究》等[19]。不过,配价语法目前主要还是停留在语言学的层面,还没有看到利用配价语法建立算法模型的研究。
2 配价结构的形式化
现有配价语法[19-20]的研究多集中于研究词语的配价特点,而没有考虑整个句子的配价结构。希望定义1种句子的配价结构,能反映句子中所有词语之间的配价关系。所希望标注的配价关系不仅涉及动词与名词短语直接的关系,也涉及名词与名词短语、形容词与名词短语甚至副词与动词形容词短语之间的关系,也就是说,配价结构应该是一种完整的句法结构,应该把句子中所有的词语都串起来,而不是现有的短语结构或者依存结构的一种补充。
在配价语法中,领主属宾句指“王冕七岁时死了父亲”这种句子,与一般的句式相比,可看到这种句式有以下特点:(1) 句中的主语与述语动词没有直接的语义关系,不是述语动词的必有语义成分,表现为主语类型的非典型性;(2) 句中宾语多为述语动词的施事,表现为宾语类型的非典型性;(3) 主语与宾语的联系不是靠动词而是靠2个成分之间在词汇语义上的“领有-隶属”关系,伴随这个特点的是述语动词(或形容词)为一价(或一向)。
以“陈楠三十岁生了儿子”、“王冕七岁时死了父亲”为例,给出依存树和设想中的配价结构,如图1~4所示。其中图2和图4所示为所设想的一种可能的配价结构形式,这种形式可能在研究过程中还会发生变化和改进。可以看到:2个句子具有形式相同的依存树,却具有不同的配价结构,可见与传统的短语结构树和依存树相比,配价结构反映了更多的语义特点。同时,词语的配价信息比较稳定。最后,配价结构从形式上并非1棵树,而是1个有向图。因此,配价结构具有比短语语法和依存语法更强的表现能力,有潜力获得更高的句法语义计算性能。因为在句子“王冕七岁时死了父亲”中,“王冕”是零价的,“死了”和“父亲”都是一价的,而“七岁时”是1个两价的时间副词(2个配价成分分别说明“谁七岁”、“七岁发生了什么事情”)。而在句子“陈楠三十岁生了儿子”中,“陈楠”是零价的,“儿子”是一价的,“生了”和“三十岁”都是两价的。有了这些词语的配价信息,就可以比较准确地获得上述配价结构。
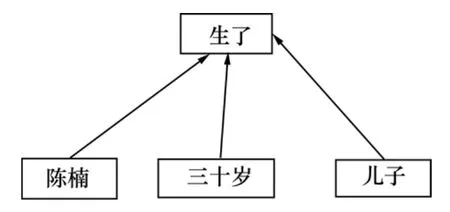
图1 句子“陈楠三十岁生了儿子”依存树Fig.1 Dependent tree of sentence “陈楠三十岁生了儿子”

图2 句子“陈楠三十岁生了儿子”的一种可能配价结构Fig.2 Possible valence structure of sentence “陈楠三十岁生了儿子”
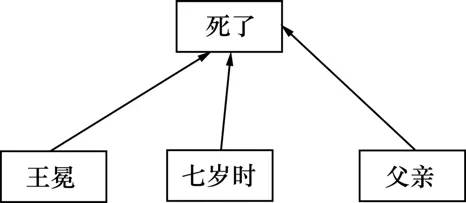
图3 句子“王冕七岁时死了父亲”依存树Fig.3 Dependent tree of sentence “王冕七岁时死了父亲”
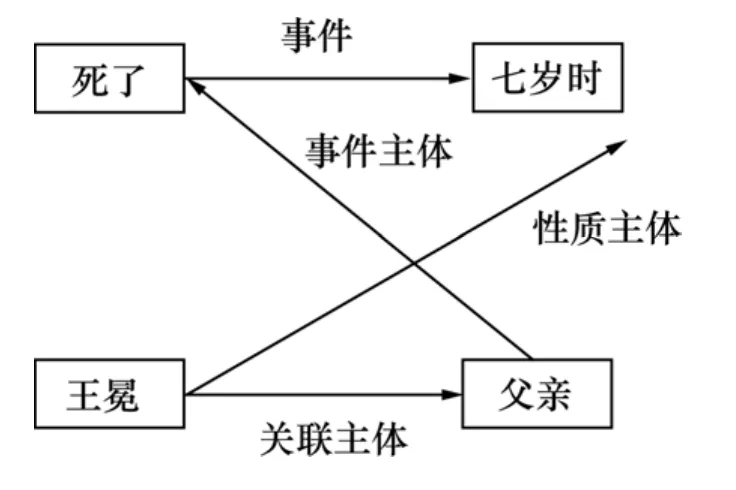
图4 句子“王冕七岁时死了父亲”的一种可能配价结构Fig.4 Possible valence structure of sentence “王冕七岁时死了父亲”
句法结构是句法形式和语义内容的统一体。对句法结构不仅要进行形式分析,例如句法层次分析、句法关系分析以及句型分析等,而且要进行种种语义分析。对句法结构的语义分析越全面、越深刻,就越有可能对句法形式上的各种现象进行科学、合理的解释。在句法分析中引入语义信息,语义信息包括语义类、语义搭配、语义依存信息等。本文的基本思想是:在句子短语结构或依存结构的基础上,利用基于配价理论开发的语义词典分析得到句子配价结构,反过来再利用句子配价结构对句中依存关系进行必要的修正;在句法分析模型中引入丰富的语义信息,既包括由句法树或依存树确定的语义依存信息,也包括由句子分析树对应配价结构图确定的语义搭配信息。
3 基于配价结构的词汇化句法分析模型
3.1 中心词驱动句法分析模型的基本原理
中心词驱动句法分析模型是最具有代表性的词汇化模型。为了发挥词汇信息的作用,中心词驱动模型为文法规则中的每一个非终结符(none terminal)都引入核心词/词性信息。由于引入词汇信息,不可避免将出现严重的稀疏问题。为了缓解这个问题,中心词驱动模型把每一条文法规则的右手侧分解为三大部分,分别为:1个中心成分;若干个在中心左边的修饰成分;若干个在中心右边的修饰成分。可以写成如下形式:

其中:P为非终结符;H表示中心成分;L1表示左边修饰成分;R1表示右边修饰成分;hw,lw和rw均是成分的核心词;ht,lt和rt分别是它们的词性。进一步假设,首先由P产生核心成分H,然后以H为中心分别独立地产生左、右两边的所有修饰成分。这样,形如(1)式的文法规则的概率为:

其中:Lm+1和Rn+1分别为左、右两边的停止符号。
3.2 基于配价结构并结合中心词驱动模型的词汇化句法分析模型
设Φ(h)表示句法树上已经生成的词中与当前核心词 h有语义依存关系(由句法树确定)或语义搭配关系(由句子分析树对应的配价结构图确定)的词和语义关系,其他符号的表示同上文一致。在本文的句法分析模型中,每一条文法规则写成如下形式:
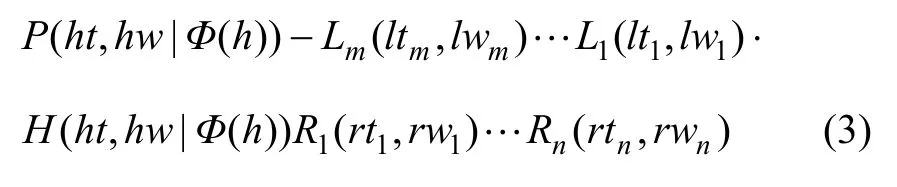
形如(3)式的文法规则的概率为:
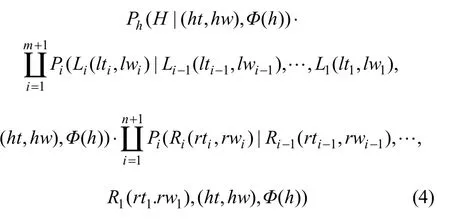
其中:Lm+1和Rn+1分别为左、右两边的停止符号。式(4)中的概率

可分解为2个概率:
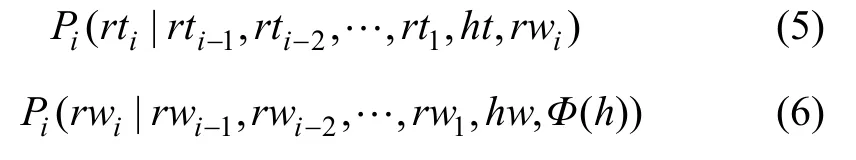
的乘积,记 Φ ( r wi)表示 r wi-1,rwi-2,…,rw1,Φ(h)词中与当前词rwi有语义搭配关系的词,则有:
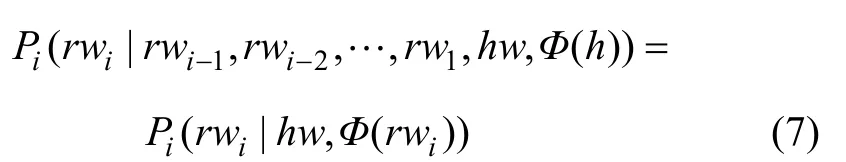
再假定 h w, Φ ( r wi)关于rwi条件独立,则有:
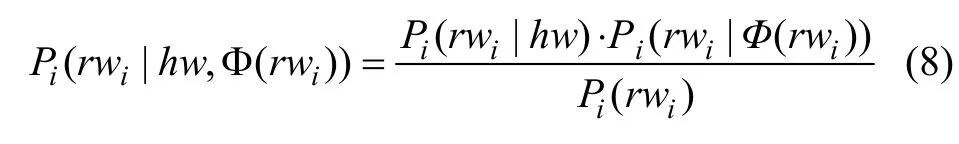
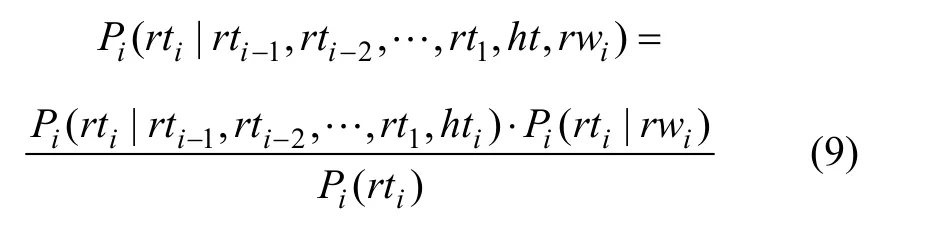
(9)式中概率
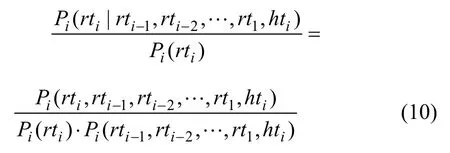
可以说,目前词汇化的上下文无关文法所进行的独立性假设与语言现象不相符合,既不适合于英文,更加不适合于中文。在本文的句法分析模型中,用条件独立性假设取代了中心词驱动句法分析模型中的独立性假设。从统计学的角度来说,相对条件独立性假设,独立性假设是过强假设,与语言现象也不尽符合。因而,该句法分析模型更符合语言的实际物理过程。通过对Collins模型的规则进行分解和修改,基于配价结构并结合中心词驱动模型的词汇化句法分析模型能够更好地融入语义(既包括由句法树确定的语义依存信息,也包括由句子分析树对应的配价结构图确定的语义搭配信息)等语言方面知识,提高句法分析的准确率。
4 实验结果
试验数据取自宾州中文树库(CHTB)5.0版本,大部分取材于新华社新闻、Sinorama新闻杂志以及香港新闻。CTB是由语言数据联盟(LDC)公开发布的1个语料库,为汉语句法分析研究提供了一个公共的训练、测试平台。该树库包含了507 222个词,824 983个汉字,18 782个句子,有890个数据文件。为了在训练集、开发集和测试集中平衡各种语料来源,将语料分割如下:将文件301~320和611~630作为调试集,将文件271~300和631~660作为测试集,其余文件作为训练集。在本文的所有实验中,模型的参数都是从训练集中采用极大似然法估计出来的。
测试结果为常用的4个评测指标,即准确率P、召回率R、综合指标F和交叉括号CB。其定义如下。
精确率(Precision)用来衡量句法分析系统所分析的所有成分中正确成分的比例。
召回率(Recall)用来衡量句法分析系统分析出的所有正确成分在实际成分中的比例。
交叉括号CB:给出了在1棵树中与其他树的成分边界交叉的成分数目的平均数。
实验中采用的句法分析 Baseline系统是 Daniel M.Bikel基于Collins模型实现的DBParser。表1所示为baseline系统和改进模型的句法分析实验结果。
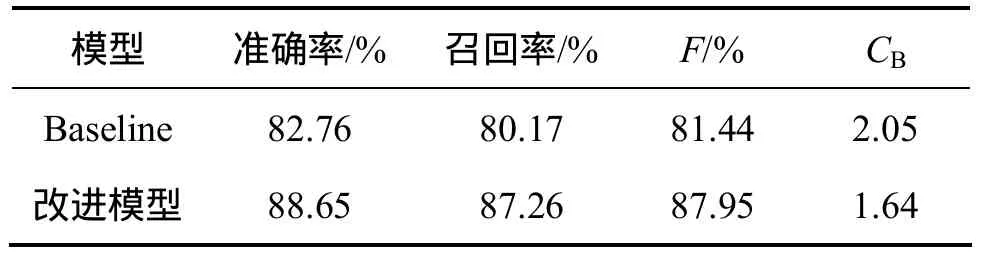
表1 句法分析实验结果Table 1 Experimental results of language parsing
从表1可以看出:由于在规则的分解及概率计算中,既利用了由句法树或依存树确定的语义依存信息,又利用了由句子分析树对应配价结构图确定的语义搭配信息。改进模型的准确率P、召回率R、综合指标F、交叉括号CB与Collins的中心词驱动句法分析模型的相比均有了明显提高。
5 结论
(1) 目前的词汇化句法分析如中心词驱动句法分析模型、依存语法仅仅考虑词语之间的语义依存关系。基于配价结构并结合中心词驱动模型的词汇化句法分析模型在规则的分解及概率计算中,既利用了由句法树或依存树确定的语义依存信息,也利用了由句子分析树对应配价结构图确定的语义搭配信息,性能有了明显提高。
(2) 模型的精确率和召回率分别为 88.65%和87.26%,综合指标F与Collins的中心词驱动句法分析模型的相比提高6.51%。
(3) 配价语法研究拓宽了语言学的研究领域,深化了语言学的本体研究,给传统的语言学研究提供了一个全新的视角,解决了语言应用当中用传统方法无法解决的难点问题,但仍存在一些不足,如:配价语法理论研究过于理论化,缺乏实践操作性;配价语法理论研究时间不是很长,许多理论观点语方学界尚待统一,它在一定程度上制约了该学科的发展。有关配价语法的理论和应用有待进一步研究。
[1]Manning C D, Schutze H. Foundations of statistical natural language processing[M]. London: MIT Press, 1999: 184-197.
[2]Seo K J, Nam K C, Choi K S. A probalistic model of the dependency parse of the variable-word-order languages by using ascending dependency[J]. Computer Processing of Oriental Languages, 2000, 12(3): 309-322.
[3]XUE Nian-wen, XIA Fei, Chiou F D, et al. The Penn Chinese treebank: Phrase structure annotation of a large corpus[J].Natural language engineering, 2005, 11(2): 207-238.
[4]Fung P, Ngai G, Yang Y S, et al. A maximum-entropy Chinese parser augmented by transformation-based learning[J]. ACM Trans on Asian language Processing, 2004, 3(2):159-168.
[5]Vilares J, Alonso M A,Vilares M. Extraction of complex index terms in non-English IR: A shallow parsing based approach[J].Information Processing and Management, 2008, 44(4):1517-1537.
[6]赵军, 黄昌宁. 汉语基本名词短语结构分析模型[J]. 计算机学报, 1999, 22(2): 141-146.ZHAO Jun, HUANG Chang-ning. The model for Chinese BaseNP structure analysis[J]. Chinese Journal of Computers,1999, 22(2): 141-146.
[7]代印唐, 吴承荣, 马胜祥, 等. 层级分类概率句法分析[J]. 软件学报, 2011, 22(2): 245-257.DAI Yin-tang, WU Cheng-rong, MA Sheng-xiang, et al.Hierarchically classified probabilistic grammar parsing[J].Journal of Software, 2011, 22(2): 245-257.
[8]Aviran S, Siegel P H, Wolf J K. Optimal parsing trees for run-length coding of biased data[J]. IEEE Transaction on Information Theory, 2008, 54(2): 841-849.
[9]ZHOU De-yu, HE Yu-lan. Discriminative training of the hidden vectors state model for semantic parsing[J]. IEEE Transaction on Knowledge and Data Engineering, 2009, 21(1): 66-77.
[10]Seo K J, Nam K C, Choi K S. A probalistic model of the dependency parse of the variable-word-order languages by using ascending dependency[J]. Computer Processing of Oriental Languages, 2000, 12(3): 309-322.
[11]袁里驰. 基于依存关系的句法分析统计模型[J]. 中南大学学报: 自然科学版, 2009, 40(6): 1630-1635.YUAN Li-chi. Statistical language paring model based on dependency[J]. Journal of Central South University: Science and Technology, 2009, 40(6): 1630-1635.
[12]王步康, 王红玲, 袁晓虹, 等. 基于依存句法分析的中文语义角色标注[J]. 中文信息学报, 2010, 24(1): 25-30.WANG Bu-kang, WANG Hong-ling, YUAN Xiao-hong, et al.Chinese dependency parse based semantic role labeling[J].Journal of Chinese Information Processing, 2010, 24(1): 25-30.
[13]鉴萍, 宗成庆. 基于序列标注模型的分层式依存句法分析方法[J]. 中文信息学报, 2010, 24(6): 14-22.JIAN Ping, ZONG Cheng-qing. Layer based dependency parsing by sequence labeling models[J]. Journal of Chinese Information Processing, 2010, 24(6): 14-22.
[14]GAO Jian-feng, Goodman J, MIAO Jiang-bo. The use of clustering techniques for language model–application to Asian language[J]. Computational Linguistics and Chinese Language Processing, 2001, 6(1): 27-60.
[15]Lee L. Similarity-Based approaches to natural language processing[D]. Cambridge, MA: Harvard University, 1997:35-56.
[16]袁里驰. 基于相似度的词聚类算法和可变长语言模型[J]. 小型微型计算机系统, 2009, 30(5): 912-915.YUAN Li-chi. Word clustering based on similarity and vari-gram language model[J]. Journal of Chinese Computer Systems, 2009, 30(5): 912-915.
[17]周国光. 现代汉语配价语法研究[M]. 北京: 高等教育出版社,2011: 21-82.ZHOU Guo-guang. The study of modern Chinese valence grammars[M]. Beijing: Higher Education Press, 2011: 21-82.
[18]Collins M. Head-driven statistical models for natural language parsing[D]. Pennsylvania: The University of Pennsylvania, 1999:65-78.
[19]袁毓林. 汉语配价语法研究[M]. 北京: 商务印书馆, 2010:55-170.YUAN Yu-lin. The study of Chinese valence grammars[M].Beijing: Commercial Press, 2010: 55-170.
[20]沈家煊. 句式和配价[J]. 中国语文, 2000(4): 291-297.SHEN Jia-xuan, Vaiency and sentence patterns[J]. Zhongguo Yuwen, 2000(4): 291-297.
[21]聂鸿英. 汉语“配价”语法研究综述[J]. 延边大学学报: 社会科学版, 2011, 44(2): 39-42.NIE Hong-ying. Review of “coordination valence” in Chinese grammar[J]. Journal of Yanbian University: Social Science, 2011,44(2): 39-42.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
客联(2020年7期)2020-09-10
疯狂英语·新悦读(2020年2期)2020-04-29
开放教育研究(2020年2期)2020-03-31
电子技术与软件工程(2019年4期)2019-04-26
环球时报(2016-09-20)2016-09-20
北方文学·中旬(2016年6期)2016-08-01
长江学术(2016年4期)2016-03-11
文理导航(2015年16期)2015-06-18
长江学术(2015年1期)2015-02-27
