
高炉生产过程的智能预测建模
2012-07-31 13:07:44刘慧李沛然包哲静王超颜文俊
中南大学学报(自然科学版) 2012年5期
刘慧,李沛然,包哲静,王超,颜文俊
(浙江大学 电气工程学院,浙江 杭州,310027)
随着国民经济的发展,钢铁在社会经济中的重要性越来越突显出来。其中高炉炼铁占炼铁行业的95%,使得高炉成了冶炼钢铁中的重要环节,而高炉炉温的适合与稳定又是高炉铁水质量的保证,是高炉长寿、高产、低耗的保证[1]。高炉炼铁是指高炉生产时从炉顶装入铁矿石、焦炭、造渣用熔剂(石灰石),从位于炉子下部沿炉周的风口吹入经预热的空气。在高温下,一部分焦炭(有的高炉也喷吹煤粉、重油、天然气等辅助燃料)中的碳同鼓入空气中的氧燃烧生成的一氧化碳,在炉内一氧化碳上升过程中除去铁矿石中的氧,从而还原得到铁和二氧化碳,这称为间接还原反应,一般发生在高炉中温度低于1 100 ℃的时候;另一部分焦炭直接与铁的氧化物发生反应还原出生铁,称为直接还原反应,一般在高炉中接近中心温度最高的地方都发生直接还原反应;还有一部分铁的氧化物被氢气还原,生成的水一部分被碳和一氧化碳还原为氢气,还有一部分在高炉上部被铁矿石和焦炭吸收,以降低高炉炉口的温度,保护高炉。炼出的铁水从出铁口放出。铁矿石中未被还原的杂质和石灰石等熔剂结合生成炉渣,从渣口排出。产生的煤气从炉顶导出,经除尘后,作为热风炉、加热炉、焦炉、锅炉等的燃料[2]。在实际生产过程中,由于高炉结构的复杂性使得直接测量高炉内部温度场分布变得困难,而炉温与铁水含硅量密切相关,故可以用铁水硅含量代表高炉炉温,将铁水硅含量控制在一定的范围内就成为了高炉研究的主要内容。目前国内外研究的比较多的是建立高炉的专家系统,包括日本川崎水岛的“ADVANCED GO-STOP系统”、芬兰罗德洛基公司的专家系统以及刘金琨等的高炉异常炉况神经网络专家系统等[3]。但是这类专家系统也存在一些问题:首先,由于准确率主要取决于知识库的知识多少及正确率,因此,专家系统成功与否要看工长的经验成熟程度;其次,知识库的内容、规则一般具有本高炉的特点,由于高炉个体的差异,知识库的内容、规则需要很大的改变,系统移植能力差。为了克服这些缺点,本文作者提出智能复合模型,对历史数据进行预处理后,运用 SVM建立不同工况下的铁水硅含量预测模型;然后,应用模糊拟合推理找出各模型权重与生产输入和模型输出之间的关系,从而得到不同时刻各个模型的权重,进行多模型的智能融合,进而得到复合预测模型并不断在线调整,以便控制和优化高炉生产过程。
1 高炉生产过程数据预处理
1.1 生产过程建模框架
整个建模过程可由以下几个部分组成:工况分析模块、数据处理模块、单工况模型确立模块、模型复合模块。
工况分析模块在获得足够多的历史数据后对这些数据进行分析,提取出能够反映高炉大多数工作情况的点,即不同的工况;
数据处理模块根据各个工况的不同特点对其数据进行滤波去噪、剔除异点等预处理;
单工况模型确立模块利用 SVM 分别对各工况的历史数据进行建模,得到各个工况符合精度要求的模型;
模型复合模块运用模糊逻辑推理得到各模型的权重系数,进行多模型的智能联合。
参数调整模块根据实际输出与复合模型输出之间的误差修正各模型权重。
本文提出的高炉生产过程的模型是根据冶金高炉系统的现场数据以及系统工艺机理,基于 SVM 建立的不同工况下的多变量模型。整个建模流程如图 1所示。
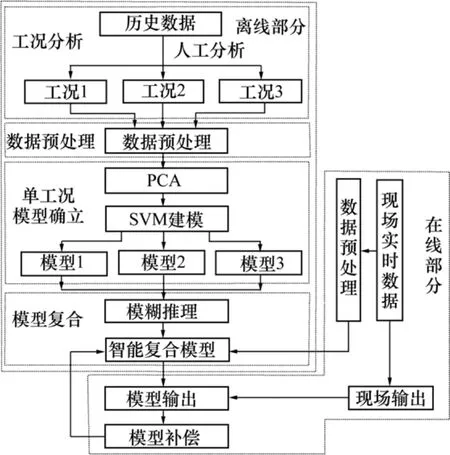
图1 智能复合模型流程图Fig.1 Flow of intelligent mixed predictive model
1.2 工况分析
为了获得更加精确的高炉生产模型,本文基于对大量的高炉生产过程历史数据的分析,根据专家经验和铁水Si含量的历史数据,发现该高炉一般稳定在3个工作点,即高温、适温和低温,各工作点的Si含量如图2所示。
1.3 数据预处理
高炉铁水硅含量受到众多因素的影响,根据专家经验炉温较低时一般选择较为密切的7个变量包括风量、风温、风压、喷煤量、下料量、透气性、炉顶压力。
由于高炉数据的采样时间间隔不一样,比如风量和风压等变量每隔1 s采样1次,而铁水硅含量则是在每炉出铁时采样1次,所以需要先将所有采样得到的数据化为同一采样时间间隔。
另外由于采样过程中可能会出现外界干扰、样本不均匀等现象造成采样得到的数据包含噪声,所以采用滑动滤波对所得数据进行预处理,最后得到数据曲线的包络线,取数据曲线上下包络线的平均得到最终数据。图3所示为以喷煤量、风量和透气性这3个参数为例,描述了经过滤波后的历史数据曲线。
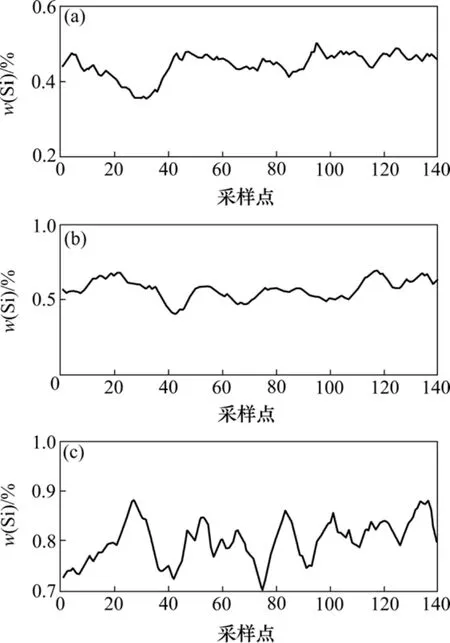
图2 各工况下的Si含量Fig.2 Content of Si in every work condition

图3 经过滤波后的曲线Fig.3 Filtered parameter data
2 单工况模型的建立
2.1 主元分析
主元分析是多元统计中的一种数据挖掘方法,利用降维的思想,在不丢失主要信息的前提下选择较少的几个综合变量代替原来较多的变量,以排除原信息中相互重叠的部分[4-5]。而支持向量机(SVM)是Vapnik等[6-8]建立的理论体系,采用结构风险最小化原理,兼顾训练误差和泛化能力,在解决小样本、非线性、高维数、局部极小值等问题中占优势。以炉温较低这一工况为例,单工况模型建立过程描述如下。
假设x=(x1, x2, …, xn)T,n=7代表这7个变量的经过处理后的历史数据,计算相关系数矩阵R=(rij)7×7,进而求得该矩阵特征值λ1, λ2, …, λ7,如图4所示,横坐标表示构成矩阵的变量,纵坐标为矩阵中每个变量对应的特征值从大到小排列。
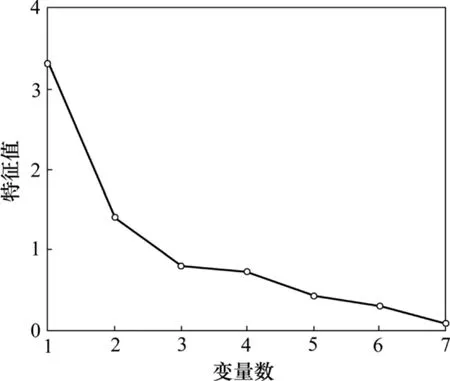
图4 各个变量对应的特征值Fig.4 Eigenvalues of components
一般来说,选择变量个数有2种方法:一种是选择贡献率大于1的所有变量,一种是选择贡献率累积大于 85%的所有变量。在此根据模型精度选择变量个数。

表1 成分方差百分比Table 1 Component of variance %
首先选择贡献率最大的变量得到因子得分系数从而得到相应主成分表达式,将其作为输入,运用支持向量机建立与铁水硅含量之间的数学模型,并计算模型精度,若满足要求,则到此为止;若大于要求的精度,则继续选择贡献率稍小的变量。
2.2 支持向量机建模
由 Hilbert-Schmidt原理和文献[10]可知:在求解上面风险函数的过程中,只涉及到样本间的内积运算(xi, xj),只要找到1个函数K(xi, xj)满足Mercer条件,它就能对应某一变换空间中的内积,就可以用该函数代替此内积。
根据经验,常用的有4种函数:线性核函数、多项式核函数、高斯径向基核函数和样条核函数。本文中选取三次多项式核函数d=3。由于训练误差大,故继续选取贡献率较大的变量,重复以上步骤,直到精度达到要求,最后的拟合效果如图5所示。其他工况也用同样的方法建立模型。
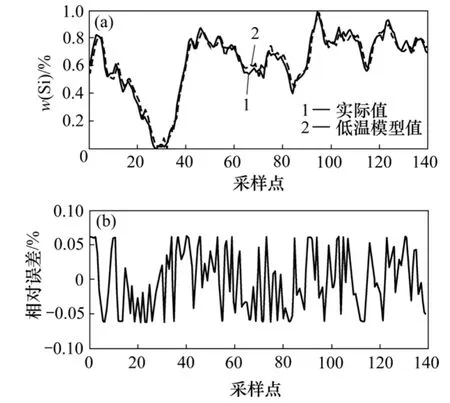
图5 低炉温预测效果Fig.5 Regression result at low temperature
图5所示为低炉温预测效果。图5(a)中,实线表所示为预测结果与实际硅含量相比的误差。从图 5(b)示实际的硅含量,而虚线表示硅含量预测结果;图5(b)可以看出:预测误差能够保持在8%以内,可以用该模型作为整个模型中的单模型来控制和优化生产过程。
然而,在实际的生产过程中,高炉精确工作在某一工况的情况是一种特例,大部分情况下高炉都不能完全工作在这些确定的工况,而是处于某些工况的过渡阶段。这时候只有当工况划分的足够细致,才能反映高炉的每个工况,但是,这又会使建模变得相当复杂,大大增加了计算量,而且很多时候高炉工作情况本身的复杂性也使得高炉的划分工况的工作变得很困难。基于这种情况,本文采用智能模糊模型联合,它既可以反映高炉的特殊工况,又可以反映介于这些特殊工况之间的工作情况,并且工作量并没有增加很多,在工程上是可实现的。
3 模型智能复合
得到各个工况下的预测模型后,进行基于规则的多模型的智能融合和在线调整,并将各个模型与其权重乘积之和作为实际的预测输出,一方面软化模型切换过程中系统参数变换带来的影响,另一方面避免因炉况判断不正确带来的一系列影响。此方法对模型结构的变化无特别限制,只要模型的变化在模型集描述的范围内即可[11]。其基本思想是:将当前系统输入进入各个模型后得到各模型的预测输出,根据这些预测输出与高炉的实际运行输出之间的误差及其变化率,运用模糊逻辑推理,拟合各个工况的权值,并由此来加权各个工况下的模型以得到复合预测模型,再根据复合模型的预测输出与高炉实际输出之间的差值及其变化率在线修正3个模型的权值。
模糊控制是以模糊集合论、模糊语言以及模糊逻辑推理为基础的计算机智能控制,其基本概念是由Zadeh首先提出的,经过20多年的发展,模糊控制在理论研究和实际应用方面都取得了重大发展[12-14]。
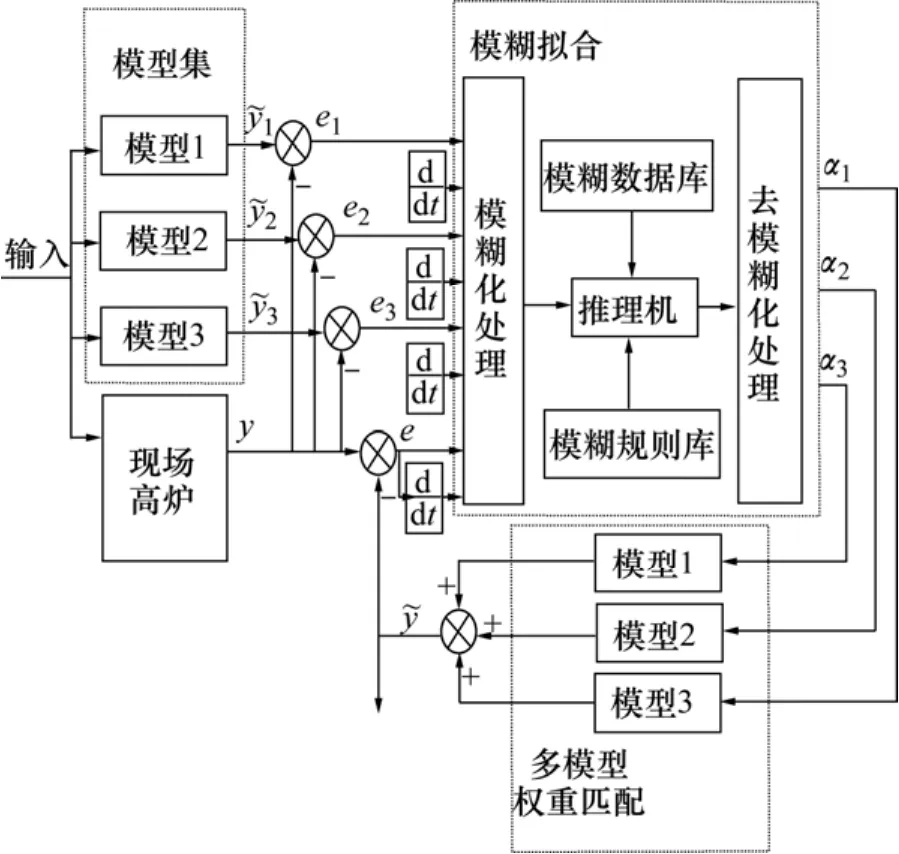
图6 模型复合的推理过程Fig.6 Reasoning process of ally models
3.1 模糊化
当前系统的输入进入到各个单模型,得到各单模型的预测输出,模糊推理的输入分别为3个模型的输出误差及误差变化率,还有复合模型的输出误差和误差变化率;模糊推理的输出为3个模型的权重系数。下面为输入和输出的模糊化分割方式:
(1) |e|表示误差绝对值,选用3个语言变量S,M和B分别代表误差的小、中、大;
(2) e˙,即 de/dt,反映|e|的变化率和变化方向,分别用NB,NM和NS以及PS,PM和PB代表误差的负大、负中、负小和正小、正中、正大;
(3) 输出量α指的是各模型的权重系数,分别用S,M和B代表各模型与当前工况的匹配程度为不好、一般和好。
选择各变量的隶属度函数为均匀三角函数,根据各变量的隶属度函数,可以近似得出各个语言变量的赋值。
3.2 模糊拟合推理
模糊拟合推理是一种不确定性推理方法,其基础是模糊逻辑,它是要找出在不同时刻3个模型权重参数与各个误差以及误差变化率之间的模糊关系,在运行中不断检测|e|和e˙,根据模糊推理规则对 3个权重系数进行在线修改,以满足控制精度的要求。因此,对这3个权重的整定可以考虑如下:
(1) 当|e1|,|e2|和|e3|中有1个很小,而另外2个很大时,说明误差很小的模型与当前工况匹配程度较高。
(2) 当|e1|,|e2|和|e3|中有2个较小,而另外1个较大时,说明系统当前工况介于误差较小的2个模型之间。此时则要根据复合模型的输出误差和2个误差较小的模型的误差变化率共同决定模型匹配度。
(3) 当|e1|,|e2|和|e3|中某个量超过基本论域范围,就说明其对应的模型误差太大,不适合当前工况,则自动将其权重设置为小。
根据这些调整原则以及高炉专家的经验,可以得到相应的模糊规则,形式如下:

3.3 去模糊化
由于重心法对于输入的微小变化推理的最终输出一般都会发生一定的变化并且这种变化比较平滑,故模糊拟合的去模糊化算法采用重心法,取模糊隶属度函数曲线与横坐标围成的面积的重心为模糊推理的最终输出。
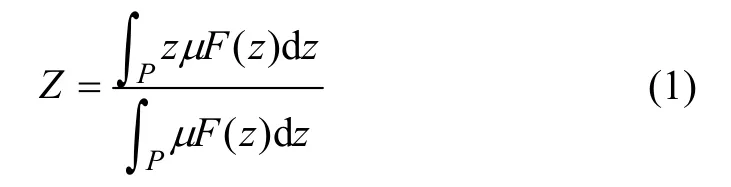
其中:P为输出论域;F为其模糊子集。
3.4 权重在线修正
在实际运行中,系统根据当前输入与模糊修正规则得到各模型权重1α,2α和3α,从而得到复合模型输出
将复合模型输出与系统实际输出之间的误差e及其变化率e˙模糊化后与已经建立好的模糊规则一起在线调整各权重值,假设1α比较大,2α比较小,3α也比较小,同时e比较小且有减小趋势,说明1α对应的工况比较符合当前的运行情况,则继续增大1α,可用下面的模糊修正规则来表达。
3.5 模糊推理结果
将此模糊拟合推理用来生成本高炉3个单模型的权重,进而建立复合模型。图7所示为取介于低温与适温之间的历史数据进行验证的结果,显示了复合模型的预测结果。
从图7可以看出:复合模型预测误差比较小,能够稳定在7.5%以内,满足精度要求。为增强系统的适应性,实际运行时,需要不断评估所建立的模型是否包括了高炉运行的所有状况,如果没有,则根据出现的情况,建立新模型,加入系统参与预测,以此不断完善系统。
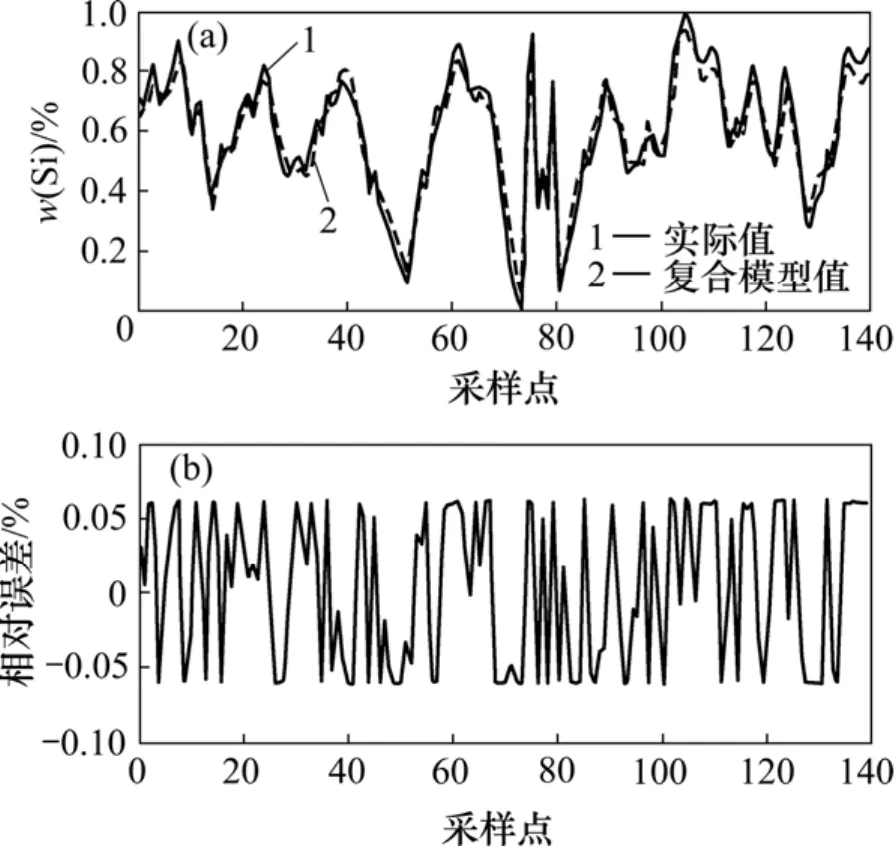
图7 复合模型预测结果Fig.7 Final regression result
4 结果验证
4.1 单模型与复合模型的结果对比
为了对本文所得到的智能复合模型的预测精度进行验证,选取了5组历史数据。这5组数据分别为高、中、低温3个工况下的数据,以及介于高、中温和中、低温之间的数据。对于这5组数据,分别用单模型和复合模型进行预测,将得到的预测结果进行对比,结果如图8~10所示。

图8 低温时2种模型的输出误差对比Fig.8 Output-error of two models at low temperature
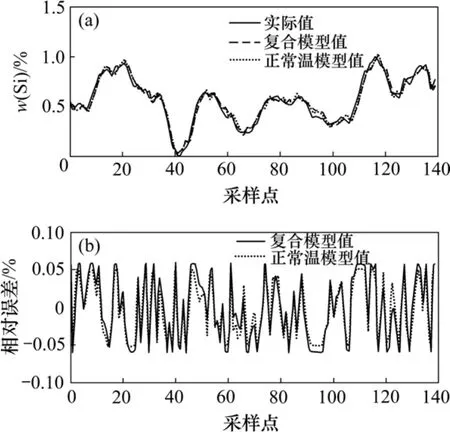
图9 正常温度时2种模型的输出误差对比Fig.9 Output-error of two models at normal temperature
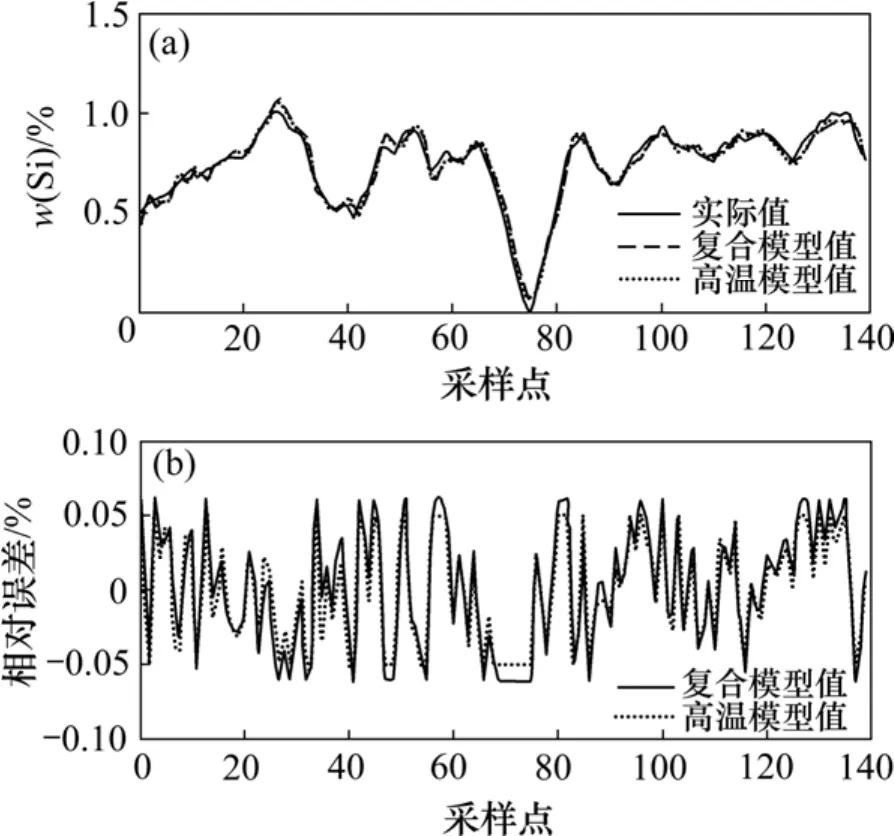
图10 高温时2种模型的输出误差对比Fig.10 Output-error of two models at high temperature
正常温度和高温时,2种模型的输出误差对比结果分别如图9~10所示。从图9~10可以看出:复合模型对处于某特定工况的情况,拟合误差虽然不及单模型,但是能够满足精度要求。
图11和12所示分别为介于低中温、中高温时3种模型的输出误差对比。
从图11和12可以看出:当实际运行情况介于某2种工况之间时,复合模型的拟合误差比各单模型的要小。

图11 介于低中温时3种模型的输出误差对比Fig.11 Output-error of three models at lower temperature

图12 介于中高温时3种模型的输出误差对比Fig.12 Output-error of three models at higher temperature
4.2 复合模型与多模型的结果对比
目前对于多工况的工业控制研究比较多的是多模型。
多模型是根据系统历史数据,分别获得多个工况的模型,根据经验设置开关函数,根据系统当前运行情况在多个单工况模型之间进行切换。
为了进一步验证复合模型的有效性,选取一组包含了多个工况的数据,分别用传统多模型和复合模型进行预测,结果如图 13所示。从图13可以看出:传统多模型的误差大于复合模型的误差,特别是在工况波动较大的情况下,多模型的拟合精度远小于复合模型的拟合精度。
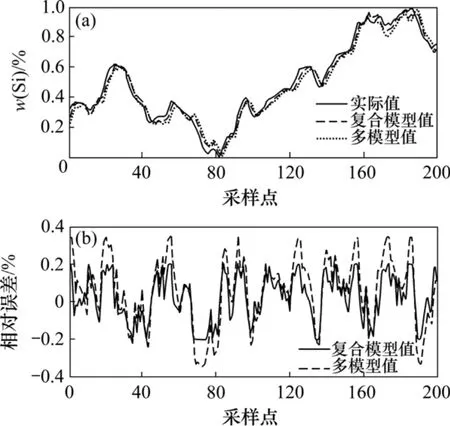
图13 传统多模型与复合模型的输出误差对比Fig.13 Output-error of multi-model and mixed model
5 结论
(1) 采用智能联合预测模型,先建立不同工况下的铁水硅含量多变量预测模型,然后运用模糊推理得到当前生产过程接近某个模型的程度,进行基于规则的多模型智能融合和在线调整,将各个模型与其权重乘积之和作为实际的预测输出,并与传统多模型进行比较。
(2) 建立的规则库比较小,与直接运用传统专家系统相比能够有效降低搜索和匹配规则所用的时间,使计算周期缩短,预测迅速,对被控对象的变化有较强的鲁棒性,实用性好。
(3) 与一般工业常用单模型或者多模型相比,此方法能够软化工况切换过程,提高工况切换过程的预测精度。
[1]张大尉, 高炉炉况预报专家系统的研究[D]. 合肥: 合肥工业大学电气与自动化工程学院, 2005: 1-52.ZHANG Da-wei. The research of expert system for blast furnace situation forecast[D]. Hefei: Hefei University of Technology.School of Electrical Engineering and Automation, 2005: 1-52.
[2]刘祥官, 刘芳. 高炉炼铁过程优化与智能控制系统[M]. 北京:冶金工业出版社, 2003: 1-270.LIU Xiang-guan, LIU Fang. Blast furnace ironmaking process optimization and intelligent control system[M]. Beijing:Metallurgical Industry Press, 2003: 1-270.
[3]宋建成. 高炉炼铁理论与操作[M]. 北京: 冶金工业出版社,2005: 1-338.SONG Jian-cheng. Blast furnace theory and operation[M].Beijing: Metallurgical Industry Press, 2005: 1-338.
[4]Reid M, Spencer K. Use of principal components analysis (PCA)on estuarine sediment datasets: The effect of data pretreatment[J]. Environmental Pollution, 2009, 157: 2275-2281.
[5]Honda K, Ichihashi H. Fuzzy PCA-guided robust k-means clustering[J]. IEEE Transactions on Fuzzy Systems, 2010, 18(1):67-79.
[6]Vapnik V. The nature of statistical learning theory[M]. New York:Springer-Verlag, 1995: 1-88.
[7]张学工, 关于统计学习理论与支持向量机[J]. 自动化学报,2000, 26(l): 32-42.ZHANG Xue-gong. About statistical learning theory and support vector machine [J]. Acta Automatica Sinica, 2000, 26(l): 32-42.
[8]许建华, 张学工. 统计学习理论[M]. 北京: 电子工业出版社,2004: 1-594.XU Jian-hua, ZHANG Xue-gong. Statistical learning theory[M].Beijing: Electronic Industry Press, 2004: 1-594.
[9]包哲静. 支持向量机在智能建模和模型预测控制中的应用[D].杭州: 浙江大学电气工程学院, 2007: 1-109.BAO Zhe-jing. Application of support vector machine in intelligent modeling and model predictive control[D]. Hangzhou:Zhejiang University. College of Electrical Engineering, 2007:1-109.
[10]渐令. 支持向量机在高炉炉温预报中的应用[D]. 杭州: 浙江大学数学系, 2006: 1-58.JIAN Ling. Application of SVM to predict silicon content in hot metal[D]. Hangzhou: Zhejiang University. Department of Mathematics, 2006: 1-58.
[11]董海荣, 高冰, 宁滨, 等. 基于模糊PID软切换控制的列车自动驾驶系统调速制动[J]. 控制与决策, 2010, 25(5): 794-800.DONG Hai-rong, GAO Bing, NING Bin, et al. Fuzzy-PID soft switching speed control of automatic train operation system[J].Control and Decision, 2010, 25(5): 794-800.
[12]刘金琨. 先进PID控制和MATLAB仿真[M]. 北京: 电子工业出版社, 2004: 1-470.LIU Jin-kun. Advanced PID control and MATLAB Simulink[M].Beijing: Electronic Industry Press, 2004: 1-470.
[13]刘剑锋, 刘友梅, 桂卫华, 等. 基于模糊预测控制的机车制动控制方法[J]. 中南大学学报: 自然科学版, 2009, 40(5):1329-1335.LIU Jian-feng, LIU You-mei, GUI Wei-hua, et al. Locomotive brake control method based on fuzzy predictive control[J].Journal of Central South University: Science and Technology,2009, 40(5): 1329-1335.
[14]许良琼, 陆新江, 李群明. 模糊PID控制在电磁悬浮平台中的应用[J]. 中南大学学报: 自然科学版, 2005, 36(4): 631-636.XU Liang-qiong, LU Xin-jiang, LI Qun-ming, Application of fuzzy PID control to electromagnetic suspension platform [J].Journal of Central South University: Science and Technology,2005, 36(4): 631-636.
[15]Milosavljevic C. General conditions for the existence of a quasi-sliding mode on the switching hyper plane in discrete variable structure systems[J]. Automation and Remote Control,1985, 46(3): 307-314.
猜你喜欢
山东冶金(2022年2期)2022-08-08 01:50:38
山东冶金(2022年1期)2022-04-19 13:40:16
昆钢科技(2021年3期)2021-08-23 01:27:36
昆钢科技(2021年3期)2021-08-23 01:27:34
当代陕西(2020年17期)2020-10-28 08:18:18
山东冶金(2019年5期)2019-11-16 09:09:06
当代工人(2019年18期)2019-11-11 04:41:23
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
自动化学报(2016年5期)2016-04-16 03:38:39
