
Apriori算法在高职院校贫困生认定工作中的应用
2012-07-12 02:06曹路舟
池州学院学报 2012年6期
曹路舟
(池州职业技术学院 信息技术系,安徽 池州 247000)
为了更好的完成贫困生资助工作,减轻贫困生认定过程中的工作压力,广义上的数据挖掘就是指知识发现[1]。它是从大量数据中发现并提取隐藏在内的、人们事先不知道的、但又可能有价值的信息和知识一种新技术[2]。狭义的数据挖掘只是知识发现过程中的一个重要步骤,是知识发现过程中一个最核心的环节,通过这个环节可以发现需要的模式。关联规则挖掘技术是最常用的技术之一,本论文通过对我校所有在校生的基本信息进行数据分析,并利用这些数据采用经典的Apriori算法进行数据挖掘,找出其中的部分数据之间内在的关联,从而提高贫困生认定工作的效率。
1 关联规则挖掘算法
1.1 关联规则的基本概念
关联规则[3]的挖掘问题可以用下面的形式来描述:
令I={i1,i2,…,in}为一个项目集。令D为一任务相关数据构成的事务数据库,每个事务T是一项目集且TI。每个事务T都与一个被称作TID的标识符相关联。令A为一个项目集,当且仅当AT时事务T包含A。关联规则的表示形式为AB,其中AI,BI,且 A∩B=。关联规则AB以支持度S包含事务集D,其中S表示事务集D中包含A∪B的事务占有的事务百分比,即概率P(A∪B)。关联规则AB是以置信度C包含事务集D,其中C表示事务集D中既包含A事务同时又包含B事务的百分比,即条件概率P(A|B)。表达式如下:
1.2 关联规则的主要算法
关联规则的算法主要有Apriori[5]算法,FP-growth[6]算法,以及一些在此基础上改进的算法。由于Apriori算法属于单维、单层、布尔关联规则,思路比较简单,以递归统计为基础,通过剪枝生成频繁集,所以该算法得以广泛使用。
1.3 Apriori算法
Apriori算法挖掘数据可以分为两个阶段:
第一阶段:全部的频繁项目集通过循环迭代识别,并保留满足支持度不小于用户预设的最小支持度要求的频繁项目集。
第二阶段:从求出的频繁项目集中挖掘出置信度不小于用户预设的最小置信度的规则。
算法描述:
数据显示,2017年四川省完成地区生产总值3.70万亿元。其中,成都以1.39万亿元,占比达到37%,可谓遥遥领先。排行第二的绵阳GDP总量为2074.8亿元,成为四川首个跨过2000亿门槛的地级市。德阳、宜宾、南充则紧随其后,逼近2000亿大关。在“1500亿”一档的泸州、达州、乐山差距并不大。
(1)求出频繁1-项集L1
(2)求频繁k-项集Lk,先求出一个候选频繁k项集Ck。Ck可以由JOIN计算获得,这被称为连接步。 如果 r,s∈Lk-1,r={r1,r2,…rk-2,rk-1},s={s1,s2,…,sk-2,sk-1},而且当 1≤i<k-1 时,ri=si,当 i=k-1 时,rk-1≠sk-1,则 r∪s={r1,r2,…,rk-2,rk-1,sk-1}是 Ck这个集合中的元素,频繁k项集的有可能部分来自于候选频繁k项集的集合Ck之中。
(3)由于候选项目集Ck是频繁项目集Lk的超集,这样Ck中部分元素就有可能不是频繁的。Apriori算法从Ck中去掉所有非频繁的 (k-1)-项集,通过剪枝思想使Ck的规模降低。
(4)经过一趟扫描事物数据库D,求出候选项目集Ck中每个项目集的支持度,这被称为计数步。
(5)去掉Ck中不满足最小支持度的项目集,这样频繁k-项集Lk就产生了。
重复操作(2)~(5),直到没有新的频繁项目集生成时结束。Apriori算法能够求出满足最小支持度的所有的频繁项目集。
算法实现[4]:

其中D是事务数据库,min_sup是最小支持度,算法 Apriori_gen(Lk-1,min_sup)的功能是:由频繁项集Lk-1连接生成一个超集Ck作为候选频繁项集。
2 Apriori算法在贫困生认定中的应用
2.1 贫困生认定前的数据准备
2.1.1 数据准备 为了选出满足资助条件的经济困难学生,我们需要对所有申请资助的学生的信息进行汇总,得到与家庭经济困难学生认定有关的信息表有:
学生基本情况表(学号,姓名,性别,出生年月,民族,系,专业,年级,个人特长,入学前户口,孤残,单亲,烈士子女,健康状况,家庭人口数,家庭年收入,家庭通讯地址)。
家庭成员情况表(姓名,年龄,与学生关系,职业,工作单位,健康状况)。
家庭困难认定申请表(学号,姓名,系,专业,年级,班,家庭人均年收入申请理由)。
成绩表(学号,姓名,系,班级,课程名,成绩)。
校园一卡通月消费情况表(卡号、学号,姓名,性别,出生年月,月消费金额)。
助学贷款情况表(学号、姓名、系、专业、年级、班、贷款金额(元)、贷款期限(月)、贷款利率)。
由于这些表来源于各个部门,每个部门所做的数据表的形式不一定一样,于是我们利用sql server 2005中的数据转换服务,把这些形式不一的表都转换成数据库中的表,使形式统一起来。如图1所示:
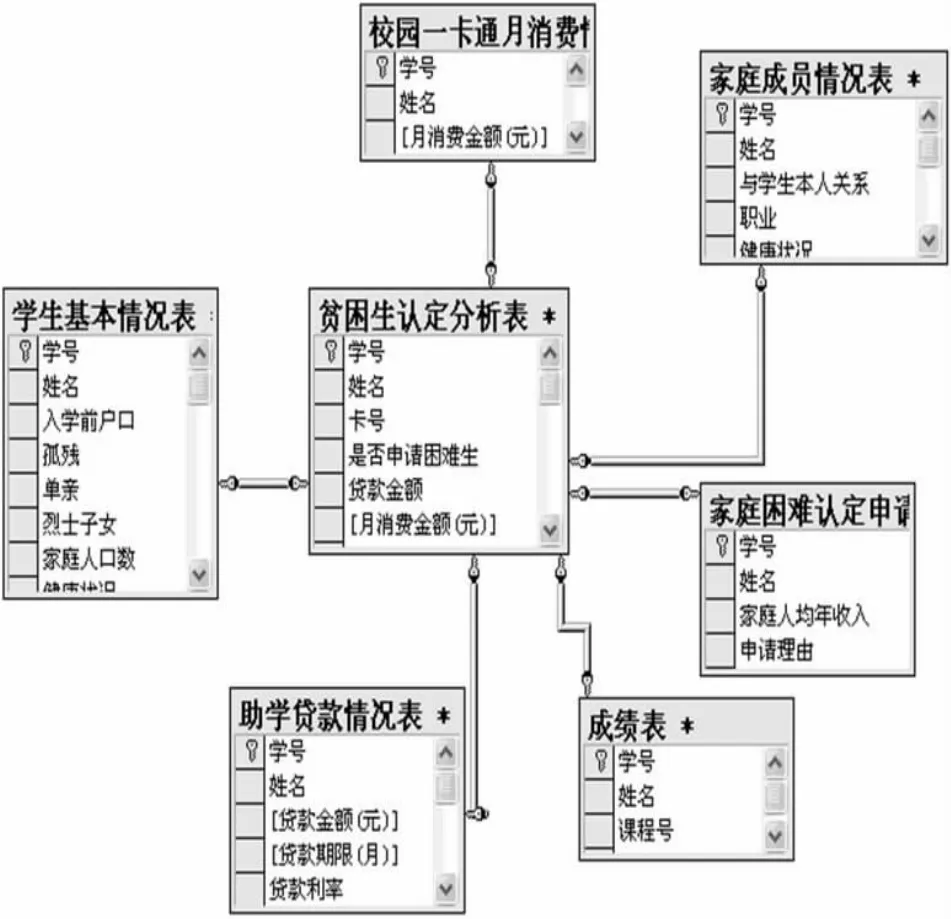
图1 贫困生认定因素关系图
接着以图1中各表的数据作为源数据,提取与贫困生认定有关的字段进行下一轮分析,去掉对后面分析无作用的字段,再进行适当的格式化转换,做好数据挖掘的前期准备工作。提取有关字段后得学生基本信息表如表1所示:
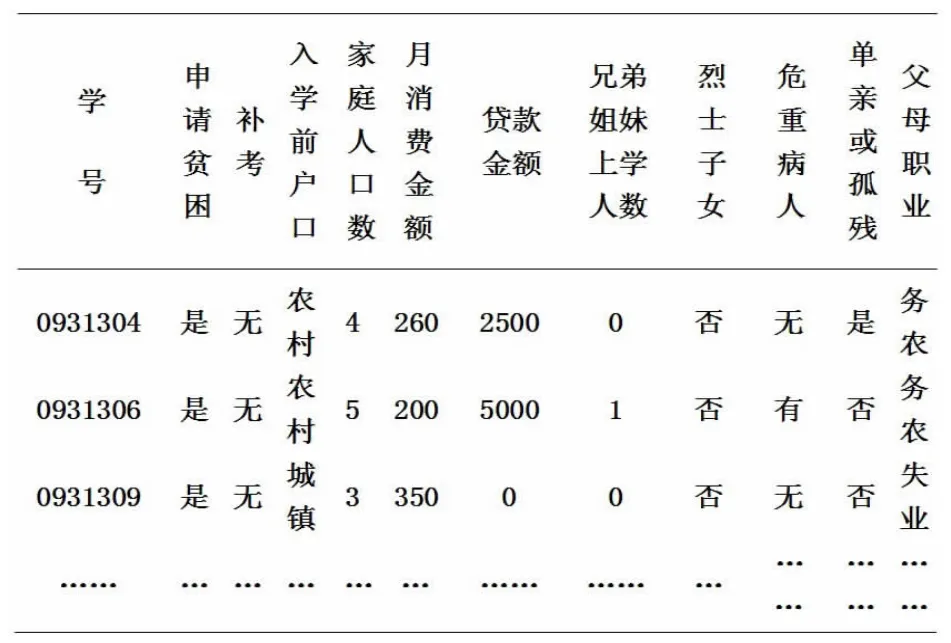
表1 学生基本信息表
2.1.2 数据预处理 因为关联规则算法只能处理离散型数据而不能直接处理连续型数值数据,因此我们先要离散化连续型数值数据,离散化后对应的属性及值域关系如表2所示:

表2 属性与值域对应表
然后将表的值域部分通过设定的项目代码编辑对应生成表3:
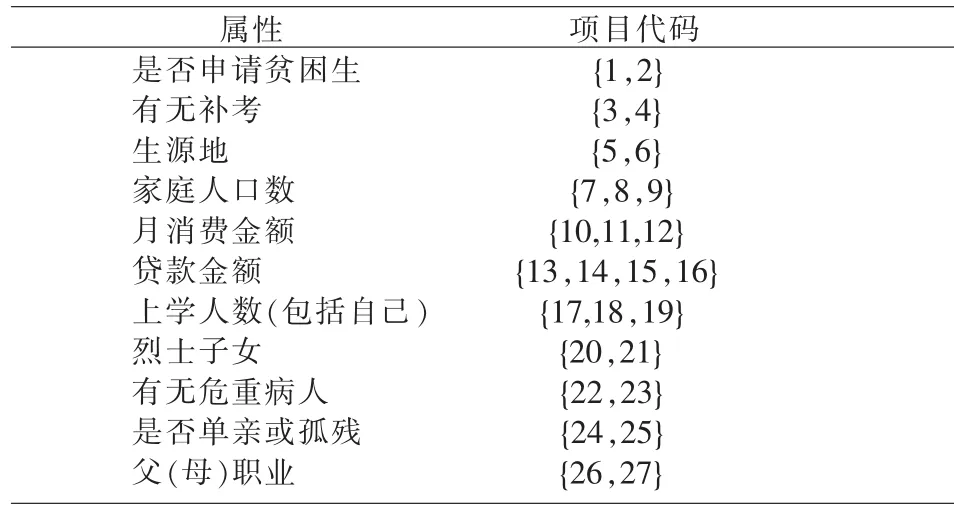
表3 属性与项目代码对应表
再对事务数据集进行转换,得到表4:

表4 转换后的事物数据库表
2.2 数据挖掘结果及分析
2.2.1 挖掘关联规则 本次挖掘设定最小支持度是5%,最小置信度是50%。使用Apriori算法对处理后数据进行挖掘后,得到如表5的部分关联规则(这里只考虑无补考的同学):

表5 关联规则结果表
2.2.2 规则理解和评估
(1)规则理解
针对表5,选择其中的两几条关联规则加以解释:
规则3:月消费金额<=300,城镇户口,父母失业=>一般困难(置信度=75.15%),这条规则表明城镇里同学在父母双失业的情况下,月消费金额不高于300元的同学,申请一般困难的置信度为75.15%,可信度较高;
规则6:月消费金额<200,农村户口,单亲,上学人数=2,申请了助学贷款=>特别困难(置信度=100%),这条规则表明,有兄弟姐妹在上学而且是单亲的同时申请了助学贷款,月消费水平也在200元以下的农村同学,申请特别困难时的置信度为100%,非常可信。
(2)评估
对全校学生进行数据挖掘生成关联规则后,保留超过最小置信度50%的同学信息,同时与学校实际贫困生资助系统中的贫困生信息作比较如表6:

表6 算法挖掘出的贫困生与资助系统的贫困对照表
对表6进行统计得知:使用Apriori算法挖掘出的贫困生人数为1415人,而我校实际贫困生资助系统中的贫困生总人数为1667人,这说明使用Apriori算法挖掘出的同学有将近85%的人在实际贫困生资助系统中,该算法针对这次的贫困生的数据挖掘效率约为85%,而不是100%。产生这种结果的原因有多种可能:(1)关联规则并不代表因果关系,只是反映了一个客观现象;(2)处理的数据并不代表全面,完全真实;(3)在进行数据处理时并没有考虑到所有的实际情况,尽管如此,通过以上分析,还是能够在一定程度上反映了贫困生的认定与学习成绩、贷款、消费水平以及家庭情况等之间的关系规律,可为贫困生的评定工作提供一定的依据,给决策者提供帮助。
3 结束语
本论文以全体学生的数据为源数据,使用经典的Apriori算法进行数据挖掘,找出数据间的关联规则,再通过这些关联规则来指导学校学生管理部门尽量做到公平的进行贫困生认定,有一定的现实意义,然而关联规则挖掘技术只是数据挖掘技术中的一种,而且每种挖掘技术的挖掘效率也不尽相同,如何选择一个好的挖掘算法来提高挖掘的效率是将来研究的主要方向。
[1]纪希禹.数据挖掘技术应用实例[M].北京:机械工业出版社,2009.
[2]王珊,萨师煊.数据库系统概论[M].北京:高等教育出版社,2010.
[3]JiaweiHan,Micheline Kamber.Data Mining Conceptsand Techniques[M].北京:高等教育出版社,2001.
[4]李剑.数据挖掘技术在学生助学系统中的应用[D].南京:东南大学,2009.
[5]Jiawei Han,Micheline Kamber.数据挖掘概念与技术[M].范明,孟小峰,等,译.北京:机械工业出版社,2001.
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
河南水利年鉴(2020年0期)2020-06-09
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
轴承(2015年2期)2015-07-25
长春大学学报(2013年8期)2013-06-21
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
网络安全与数据管理(2010年1期)2010-05-18
