
评价对象及其倾向性的抽取和判别
2012-06-29 06:15顾正甲姚天昉
中文信息学报 2012年4期
顾正甲,姚天昉
(1.上海交通大学 软件学院; 2.上海交通大学 计算机科学与工程系,上海 200240)
1 引言
主观性文本是相对于客观性文本而言的一种自然语言文本表达形式。它主要描述了作者对事物、事件、人物等的组织、个人或群体的想法或看法。这类文本通常出现在互联网(如论坛、电子公告、购物网站的评论板块)报刊(如读者意见)等媒体上。其中,在文本中包含有表达意见的语句,即具有褒贬意义成分的语句,我们称此类文本为意见型主观性文本。
近年来,对描述非事实的主观性文本处理方面的研究十分活跃,主要的特点是对基于断言或评论的文本进行处理。此类文本内容包含有个人、群体、组织等的意见、情感和态度等。基于主观性文本的意见挖掘技术是一种新颖的语言技术,它不仅可以运用于自然语言接口、文本分类、文本过滤、自动摘要、自然语言生成、问答系统等方面,还可以应用于现实生活中的许多方面,例如,电子商务、电子学习、商业智能、出版编辑、企业管理、信息监控、民意调查等。
本文以评价性语素的抽取和判定作为研究对象,利用SBV极性传递法定位抽取内容,并对抽取的极性词的倾向性作出判定。本文提出的ATT链算法结合互信息算法可以非常有效地提高识别评价对象边界的正确率,同时指代消解的引入能够进一步增加评价对象的覆盖率。本文在对极性词进行倾向性判别时,充分考虑了不同类型的句子,把一般副词、贬义副词、连词,特别是副词“太”对极性的影响作了全面的论述。
2 评价对象的抽取
2.1 SBV极性传递法
SBV极性传递法利用句法分析中的依存关系来识别句子的主题、主题与情感描述项的关系。这种方法在句子比较规范的条件下,可以通过识别依存关系对,找到句子中谓语的极性,然后再传递给主语。同时,通过谓语动词向宾语中的主题词传递极性。
通过对句法分析结构的依存关系的分析,可以发现SBV结构可以提供主语和谓语的修饰关系等信息。在大部分SBV结构中,主语要么是意见的持有者,要么是主题。而谓语部分的词性可能有两种情况,一种是形容词,另一种是动词[1]。
2.2 指代消解
指代是自然语言中一种非常普遍的语言现象,是一个复杂综合的过程。指代一般可分为两大类: 回指与共指。本文主要讨论的是回指现象。
在篇章中经常看到这种现象[2],某一个成分(人物、事物、事件、概念、现象等)被引进篇章后,如再次提及,作者有可能重复使用这个成分,也可能不再重复使用这个成分,而是使用另一个成分来指称前一个成分,这一前一后两个成分之间的关系我们称为回指关系。
按回指的方式分,汉语回指主要有三种: 零形回指(也称作零照应或零指代)、代词回指和名词回指。知名学者如胡壮麟、黄曾阳等认为零形回指较为反映汉语特点、是汉语偏好使用的形式。Li和Thompson认为零形回指的出现频率最高,分布最广泛,不受限制,是汉语回指的标准模式[3]。
按回指的表达形式分,通常有以下几种表达形式: (A)同形表达式;(B)局部同形表达式;(C)异形表达式: (1)同义词(包括异形简称);(2)统称词;(3)指代词;(4)零形式或省略式。
本文采用向心理论[4],对语料中存在的指代现象进行消解处理。在回指中,无论是同形表达式、局部同形表达式或同义词、统称词等均不会对评价对象的抽取造成什么影响,所以本文主要讨论零形回指、代词回指这两种回指形式。
为了便于分析和行文,定义为口语中有语音停顿,书面中有点号标记的主谓结构(含主语或宾语为零形式的情形)。换句话说,这里讲的“句子”,是仅就句法层面而言,不管是否能单独表达满足交际需要的完整意思,它不同于传统语法学中一般的“句子”概念[5]。
2.3 评价对象边界的识别
通过对大量语料的观察,可以发现,评价对象(也作: 意见目标)表现的形式不仅仅有原子意见目标(Atom opinion target),更多的是以复合意见目标(Compound opinion target)的形式出现。
在语料中,经常能观察到如“燃油的消耗”这样的“NP+的+VP”结构。陆俭明教授认为,这种结构是名词性结构,但不是偏正结构,而是由结构助词‘的’的插入使这种主谓词组中间所构成的另一类‘的’字结构,并称这类结构的中心语是作为名词性功能标记的结构助词‘的’而不是后面的动词[6]。现在较新的观点认为,“NP+的+VP”的结构是名词性结构,但不是偏正结构,也不是“的”字结构,而是正偏结构。其中正偏结构是和偏正结构相对而言的。再稍加观察,不难发现“VP+的+NP”、“NP1+的+NP2”、“VP1+的+VP2”等结构也具有这些特点。可以把这类结构统一标记为“XP1+的+XP2”。由于表达习惯及语感顺畅等因素,“XP1+的+XP2”中的‘的’经常会被省略。而完整的复合意见目标往往就是由一个或多个“XP1+(的)+XP2”的叠加组合而成。
由此可见,要寻找的主题词在更多的情况下是以复合意见目标形式存在的,在上述SBV极性传递法中所判别出的主题词往往是原子意见目标,或是复合意见目标的一部分,为了在此基础上进一步识别意见目标的真实边界,本文将采用ATT链算法及互信息算法相结合的方法来实现这一功能。
2.3.1 ATT链算法
ATT链算法如图1所示,通过遍历句首到原子意见目标之间的所有词,把当前词做为起点,遇到ATT和DE关系时就沿着ATT链继续寻找下一个词,如果ATT链中断,则从下一个遍历词开始,直至找到满足链尾词为原子意见目标词为止。满足这样要求的第一条ATT链即包含了我们要找的最先链首词,从该词开始至原子意见目标结尾,其间的所有词即为我们要找的复合意见目标。
其中有一点值得注意的是,量词有时候会位于ATT链的链首,在进行处理时需要把这种情况滤除。

图1 ATT链算法
2.3.2 互信息算法
信息论中的互信息是衡量两个信号的关联尺度,后来引申为对两个随机变量间的关联程度进行统计描述[7]。该算法分别以原子意见目标词为中心,向前向后依次添加新词。在添加前,通过计算当前词和预添加词的互信息量来判断这两个词之间的相关度,然后决定是否添加。
3 极性词倾向性判定
倾向性,又可以被称为极性、褒贬性,它是意见持有者对事物或其属性表达的一种带有主观色彩的喜好或憎恶的情感。极性词以形容词或动词为主,还有少量名词在形容词化时也会带有感情色彩,例如,“他很绅士。”,但是这种情况在对人的描写中较多,而对于产品评价类的语篇中很少出现,故本文对此不作进一步讨论。
3.1 情感句的分类
通过对原始语料库的观察,本文将情感句分为四类[8],如表1所示。
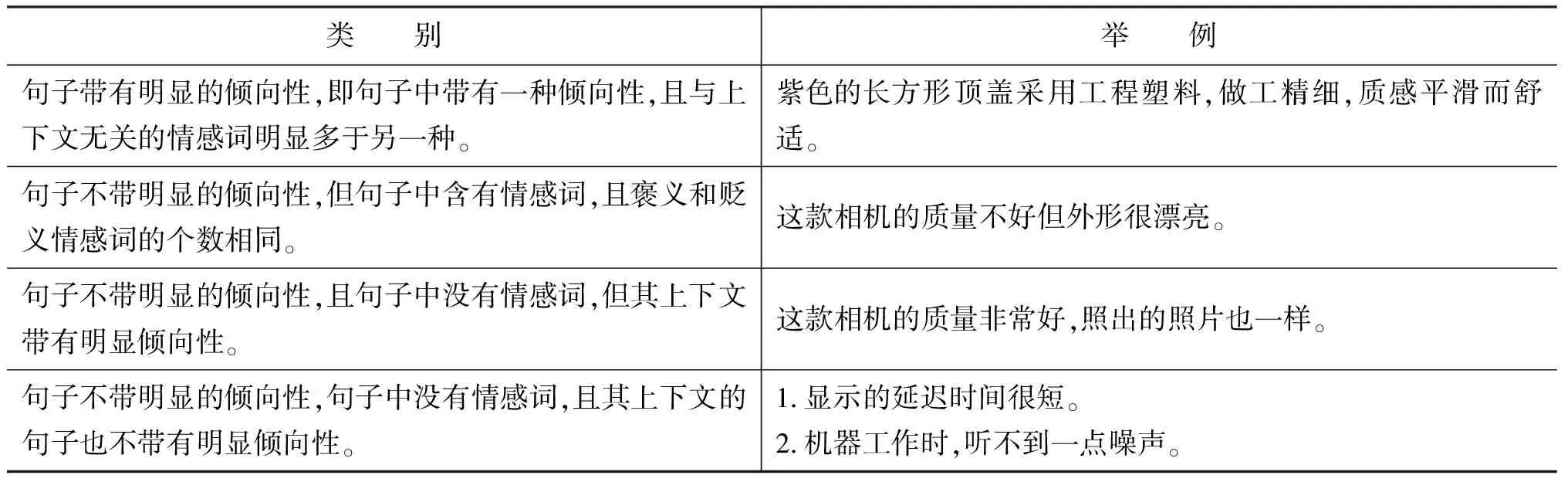
表1 情感句的类别
3.2 语义倾向性判定
针对第一类和第二类的句子,只要参照SBV极性传递法分析的结果,通过查找褒贬义词典来获取词语的倾向性即可做出判断。在处理第三类句子的时候,则需要通过使用上下文信息进行判断,优先考虑当前的句子与前一句子的极性相同,如果前一句子也不存在明显的倾向性,则认为当前句子与后一句的倾向性相同。
对于前三类情感句,虽说通过查找褒贬义词典来获取词语倾向性的方法非常简单,但是单纯使用褒贬义词典存在以下问题。
(1) 由于褒贬义词典规模的限制,无法处理没有在词典中出现的词语;
(2) 如果一个词语在不同的情况下可以是褒义词,也可以是贬义词,如何判定倾向性。例如,“如此奢华的配置展现出强劲的性能,有点台式机的感觉了。”这句中的“奢华”一词,一般表示“奢侈”、“华丽”。现在多形容有钱人的生活,也形容爱慕虚荣的人所渴望的生活,多作贬义用。但这例句中却是用来表示机器配置高档,属于褒义。
基于问题1,目前有以下几种解决方法。
(1) 首先是对HowNet的所有情感词通过手工标注的方法完成倾向性的标注工作,同时从网络上选取一定数量的极性词语,共同组成了具有相当数量褒贬词的词库。对于没有包含在词库中的新词,则通过计算新词与词库已有极性词的倾向相似性来判断新词的倾向性。
(2) 通过手工选取一定数量的基准词,使用HowNet进行语义相似度及语义相关场的计算得出新词与基准词间的相似度,从而判断新词的语义倾向性。
(3) 使用同义词词林,通过扩展基准词汇得到更大的极性词集合。
(4) 使用机器学习等统计的方法来获取词语的语义倾向性。
基于问题(2),首先要关心的是如何发现这种褒贬义误判的情况。通过观察3.1节中的第二类情感句时可以发现,这类既带有褒义极性词又带贬义极性词的子句中往往都会有如“但”、“而”、“却”之类的转折连词,它们在语句中起到转换语气和转折语义的作用,否则整个子句的语义倾向性是不变的。例如,“如此奢华的配置展现出强劲的性能,有点台式机的感觉了。”中“奢华”与“强劲”的极性应该相同,当出现不同时,就知道是发生了褒贬义误判的情况了。
其次,在发现之后如何判断是哪个词误判就成为当前下一步需要解决的问题了。这时分为以下两种情况。
(1) 当句中没有“但”、“而”、“却”等转折连词,出现句内极性词极性误判时,就认为句子里和前句或后句极性相同的词的极性判断是正确的,优先考虑与前一句子的极性相同,如果前一句子也不存在明显的倾向性,则认为与后一句的倾向性相同。然后,把极性判断错误的词修正为相同的极性。
(2) 当句中有“但”、“而”、“却”等转折连词,出现句内极性词极性误判时,就认为第一个出现的和前句或后句极性相同的词的极性判断是正确的,可以考虑与前一句子的极性相同,如果前一句子也不存在明显的倾向性,则认为与后一句的倾向性相同。然后,把极性判断错误的词修正为相反的极性。
对于不包含极性词的第四类情感句,又可分为以下两种类型。
(1) 上下文相关倾向型。例如,“显示的延迟时间很短。”和“电池待机时间短。”这两句,同样是“短”字,但在不同的评价对象上下文环境里,它的倾向性也是不同的。
(2) 语义相关倾向型。例如,“机器工作时,听不到一点噪声。”很明显,例句中的“噪声”一词为评价对象,但句子中并没有任何倾向性的形容词和动词,这就需要理解其语义后作出进一步的判定。
对于问题(1),如“短”这样的中性形容词将在后文3.4.2副词“太”一节中详细讨论。
对于问题(2),北大现代汉语教材指出: 感情色彩指词义所附带的表示褒贬态度的色彩。从这一定义我们可以看出词语的褒贬色彩是一种表示程度很高的情感评价,这部分词语在实际语言中比例并不是很高,大多数词语虽然无法说出它的褒贬,但在语言环境中可以表现出积极或消极(正面或负面)的情感倾向[9]。
汉语中具有情感评价的词语并不限于形容词及动词,有时候名词也会有明显的情感倾向性,并且当名词的褒贬程度较高时,就容易出现本章开始处提到的名词形容词化的现象,如“很艺术”、“很败笔”等。
3.3 连词对倾向性的影响
连词为词汇倾向计算提供了指示信息,如表2所示,推测连词可分为四类,其中并列连词在句子中表示语气的连续与顺延,而转折连词与让步连词在句子中都起到转换语气的作用。
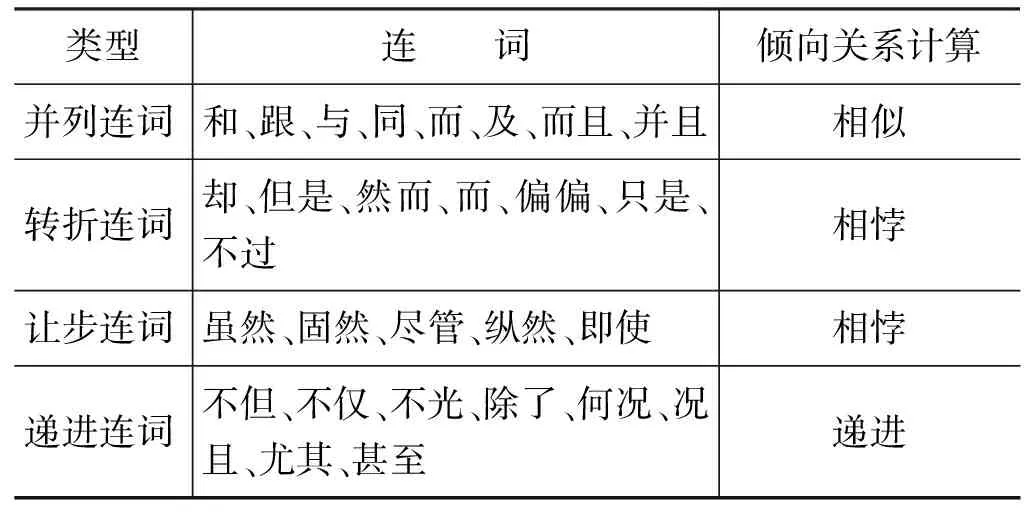
表2 连词的倾向关系计算
连词可以用来判别极性词的倾向性判断是否存在误判。除此之外,连词还能给无法判断倾向性的句子提供指示信息,从而对极性词作出进一步的判断。
3.4 副词对倾向性的影响
3.4.1 一般程度副词
跨语言的研究表明,程度性是形容词的本质特征,而性状的程度是有量级差别的。量级的表示,不同的语言采用不同的方式。印欧语系的多数语言里,形容词有原级、比较级、最高级的句法形态标记。汉语缺乏严格意义的形态变化,程度的量级主要采用性质形容词前加程度副词的词汇方式来表示。
表3中列出了最为常用的副词,其中无论是相对程度副词还是绝对程度副词, 大部分都是用来加强极性词的程度,但不会改变极性词的倾向性。而有一小部分如“偏”、“过”、“过于”、“过分”、“极端”之类的副词却比较特殊,这些副词都是带贬义倾向的副词,一般受这些副词修饰的极性词,无论是褒义的还是贬义的,都会带有负面的倾向性。如“过分高兴”、“过分失落”。

表3 程度副词分类
3.4.2 程度副词“太”
在所有的副词中,还有一个比较特殊的副词“太”,它并不能和所有的形容词都组成“太”+形容词的结构。其中,性质形容词可以构成“太”+形容词结构,状态形容词不可以构成“太”+形容词结构。
先来看一下,“太”字在修饰极性词时的情况。
“太”在修饰褒义形容词时,它可以表示过分,也可以表示程度高,用于赞叹。其后的褒义形容词也可分为两类,如表4所示。
第一类褒义形容词,一般是同时属于“可控形容词”和“二价形容词”,用于表示说话人不认同的形容词。第二类褒义形容词,一般是属于“不可控形容词”或“一价形容词”,或者是属于“可控形容词”或“二价形容词”中的一种,表示赞叹的形容词。

表4 褒义形容词分类
通过对表4的观察,可以很明显地发现,第二类褒义形容词在评价类语篇中出现的频率更高。究其原因,是因为大部分的评价词都是“不可控形容词”,属于评价产品的特有属性,而第一类褒义形容词在不使用拟人手法时一般不用来修饰物,所以本文主要针对的是第二类褒义形容词。在这类形容词前加上“太”进行修饰时,一般用来表示加强语气和加深程度的作用。
“太”在修饰贬义词时情况较为简单,一般都只是加强语气而不改变其倾向性。
接下来再来看一下,“太”字在修饰中性形容词时所表示的含义。“太”+中性形容词,表示惋惜之义。但这只指出了部分中性形容词在程度副词“太”后的感情色彩,没有涵盖所有的中性形容词在“太”后的倾向性。绝大部分的中性形容词可分成两大类: 不可控形容词及可控形容词[10]。其中前者表示惋惜之义,后者表示不满与斥责之义。在产品评价类的语篇中,中性形容词主要是用来表示客观事物的性质、数量及属性的,是属于不可控形容词中一类,如表5所示。
3.4.3 “太”字组合
一般副词“太”与“了”具有以下关系: 副词“太”,表示强调过分时,后边的“了”可加可不加,加“了“后有增强感叹语气的作用。表示程度高时,一定要有“了”呼应,否则就会变成程度过分之义。加否定程度的“太不”,后而后“了”可加可不加,意义不变,不过不加“了”时一般有后话,不是单纯的感叹。
“太不”是一种表示程度极化的组合,一般适用于可控形容词。在可控形容词前加“不”,先进行否定,而后加“太”,强化感情,这一顺序符合汉语表达的思维习惯,并且多表示贬义的倾向性。若是修饰不可控形容词,尤其是在极性反义义场中的词,根据反义义场的理论,先加“不”进行否定,可直接转换为其反义词,“太不”这一前缀显得多余而累赘。例如,“太不短”,一般就可以直接说成“太长”。基于以上讨论,我们可以认为“太不”组合在评价性语篇中出现的情况主要是描述人对产品的主观感受类的可控形容词,均应呈现贬义倾向。通过对实际语料的观察,我们也可以得到同样的结论。例如,“太不尽如人意”,“太不方便”等。
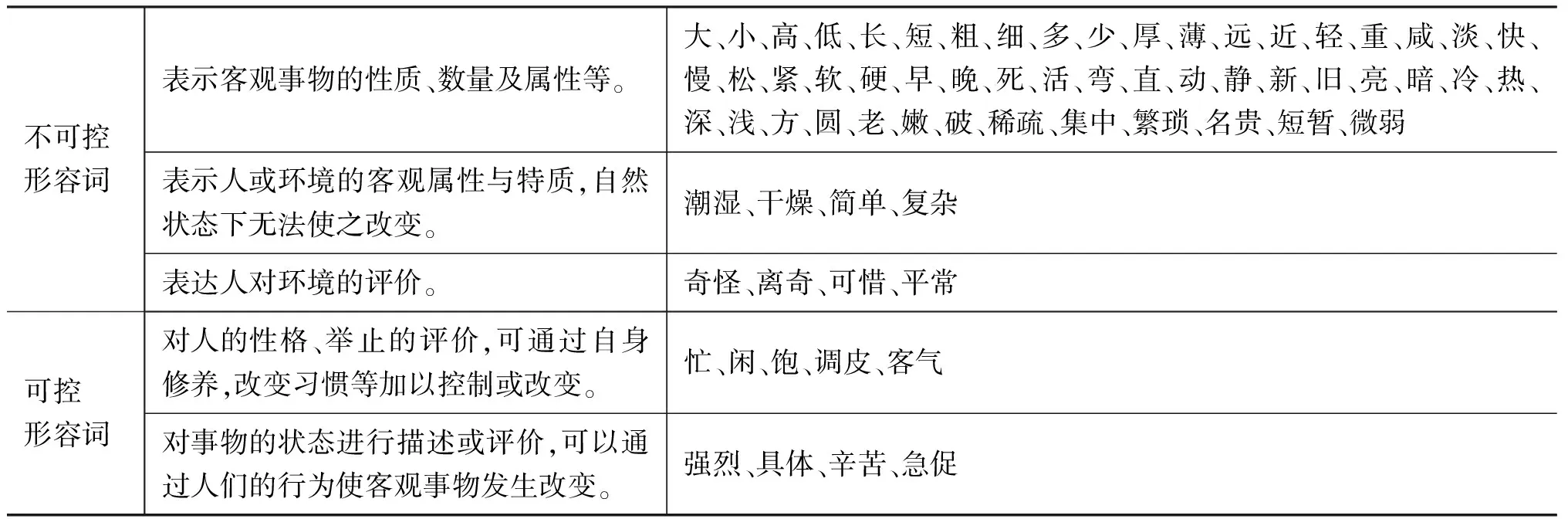
表5 中性形容词的类别
4 解决方案
本文使用了哈尔滨工业大学的语言技术平台(LTP)v2.0版本(加入了v2.0.1的升级包,LTP的.NET接口)进行预处理。同时利用知网的情感词库为本文构建基准词库,通过互联网及原始语料本身收集一定数量的与领域相关的属性词汇,人工筛选后把它们加入到LTP分词扩展字典中去,以免分词的错误影响到后续处理的结果。
在LTP完成预处理后,本文首先使用SBV极性传递法从语料中抽取出评价对象和极性词,然后利用向心理论[11]进行指代消解进一步找全评价对象和极性词,接着通过ATT链算法和互信息算法修正评价对象的边界。由于这样得到的候选评价对象集存在一定的噪声,为此在倾向性判定前先使用词频过滤法、PMI过滤法及名词剪枝法对评价对象集进行相应的过滤处理[8]。
在进行倾向性判别时,本文采用以下方法。
(1) 对于每一个候选情感词,首先查找情感词字典。如果存在,则获取其极性和强度。
(2) 如果没有找到,则分别向前和向后查找情感词,并分别找到与前后情感词之间的关联词[12]。
(3) 如果没有关联词出现,则利用SO-PMI(semantic orientation-pointwise mutual information)公式计算候选情感词的极性[13]。P(Word1& Word2)表示Word1和Word2同时出现的概率。依此为基础,计算一个新的情感词与种子情感词的互信息概率,可以得到该情感词的极性。
(4) 如果该候选情感词与其前面或后面的情感词之间出现了关联词。首先判断关联词的类型,然后分别根据以下规则计算其极性[14]。
• 如果是递进或是并列关联词,则候选情感词的极性与情感词相同;
• 如果是转折词,则候选情感词的极性与情感词相反。
(5) 判断极性词前是否受到副词的修饰,并根据副词种类对其倾向性作出以下修正。
• 如果是一般副词,则倾向性不变。
• 如果是贬义副词,则把倾向性修正为贬义倾向性。
• 如果是副词“太”,则作如下修正:
(1) 如果受修饰的不是中性形容词,则“太”起到的是加强语气和加深程度的作用,不改变极性词的倾向。
(2) 如果受修饰的是中性词,则“太”表示的是惋惜之义,需要把倾向性修正为贬义。
(3) 判断是否是“太不”组合,如果是则把当前倾向性改为贬义倾向性。
5 实验与评测
本文测试时使用了COAE2008的测试语料(汽车、笔记本电脑、数码相机和手机四大类),对评价对象抽取及倾向性判定方法的有效性进行了测试。采用了COAE2008标准的精确率,覆盖率,召回率和F值作为评测指标,测试结果如表6所示。
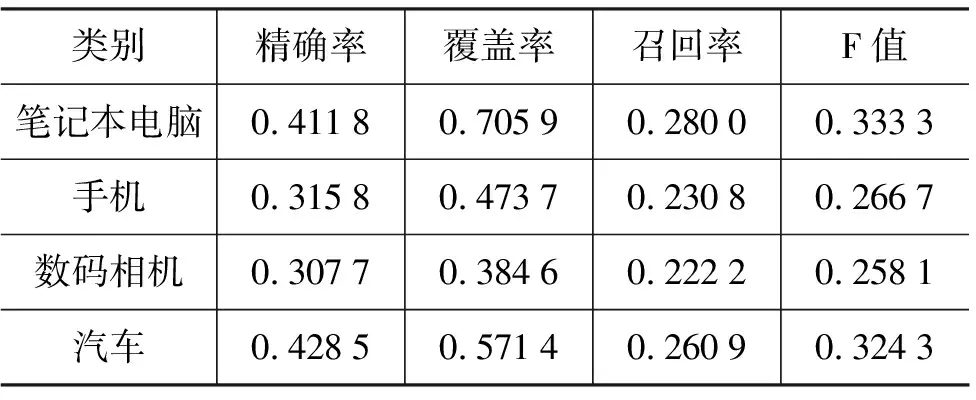
表6 评测结果
从实验结果可以看出,四类语料的精确率在覆盖率中占的比重分布在58.3%~80.0%,还存在一定的上升空间,这说明虽然采用本文提出的ATT链算法对提高精确率有很大的帮助,但该算法对依存关系的依赖度过大。同时笔记本电脑和汽车类语料的召回率要明显高于另两类,通过对原始语料的观察不难发现,这两类语料的文本较为规范。从而表明本文的方法对LTP句法分析结果的依赖度较大,抽取和判定过程会受其很大的影响,方法的容错和修正能力不够,这也是以后需要进一步深入研究和改进的地方。
感谢: 最后,感谢哈尔滨工业大学信息检索研究室的工作人员以及致力于HowNet开发的董振东和董强先生,语言技术平台及HowNet是他们智慧和劳动的结晶。在论文的整个研究过程中,语言技术平台及HowNet的情感词库都起到了重要的作用。在此谨向他们表示最诚挚的谢意。
[1] 姚天昉,娄德成. 汉语语句主题语义倾向分析方法的研究[J],中文信息学报,2007,21(5): 73-79.
[2] 徐赳赳. 现代汉语篇章回指研究[M]. 北京,中国社会科学出版社,2003.
[3] Li,C.N., S. A. Thompson. Third-person pronouns and zero-anaphora in Chinese discourse[C]//T. Givon(ed.). Syntax and Semantics:Discourse and Syntax,1979(12): 311-335
[4] Walker,M.A.,A.K. Joshi, E. F. Prince. Centering in naturally-occurring discourse: An overview[C]//M.A. Walker,A.K. Joshi & E.F. Prince(eds.),Centering Theory in Discourse,New York,Oxford University Press,1998:1-28.
[5] 王德亮. 汉语长距离回指的消解策略[C]//第七届中文信息处理国际会议,湖北武汉大学,2007,10.
[6] 陆俭明. 对“NP+的+VP”结构的重新认识[J],中国语文,2003,(5).
[7] 李治国,蔡东风,周俏丽,等. 在篇章中利用互信息识别命名实体的研究[J],沈阳航空工业学院学报,2007,24(1): 31,35-37
[8] 刘鸿宇,赵妍妍,秦兵,等. 评价对象抽取及其倾向性分析[J],中文信息学报,2010,24(1).
[9] Hatzivassiloglou V.,McKeown R.. Predicting the semantic orientation of adjectives[C]//Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics (ACL-97),Madrid,Spain,July 7-12,1997: 174-181.
[10] 王治敏,朱学锋,俞士汶.基于现代汉语语法信息词典的词语情感评价研究[J].中文计算语言学期刊,2005,10(4): 581-592.
[11] 陆俭明. 汉语和汉语研究十五讲[M],北京大学出版社,2004.
[12] Walker M.A.,A.K. Joshi, E. F. Prince. Centering in naturally-occurring discourse: An overview[C]//M.A. Walker,A.K. Joshi & E.F. Prince(eds.),Centering Theory in Discourse,New York,Oxford University Press,1998:1-28.
[13] Turney P D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL-02),Philadelphia,PA,USA,July 6-12,2002: 417-424.
[14] 姚天昉,娄德成. 汉语情感词语义倾向判别的研究[C]//第七届中文信息处理国际会议,湖北武汉大学,2007,10.
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
有色金属(矿山部分)(2021年4期)2021-08-30
天津医科大学学报(2021年2期)2021-03-29
时代英语·高一(2019年5期)2019-09-03
北方文学(2019年20期)2019-07-15
天然产物研究与开发(2018年9期)2018-10-08
思维与智慧·上半月(2014年8期)2014-09-10
航天返回与遥感(2014年1期)2014-07-31
中央民族大学学报(自然科学版)(2014年3期)2014-06-09
杂文选刊(2013年5期)2013-05-14
