
基于粒计算的物流节点选址理论建模
2012-06-15 01:30张丽岩
物流科技 2012年9期
张丽岩,马 健
(1.苏州科技学院 土木工程学院,江苏 苏州 215011;2.同济大学 交通运输工程学院,上海 201804)
基于粒计算的物流节点选址理论建模
张丽岩1,2,马 健2
(1.苏州科技学院 土木工程学院,江苏 苏州 215011;2.同济大学 交通运输工程学院,上海 201804)
首先对物流节点进行了三维界定,从物流节点选址问题的特点及人的决策思维模式,以客观数据为出发点,以 “有限理性”、 “有限记忆”、 “群体决策” 和 “粒计算”为理论基础,提出了金字塔理论架构,并应用于物流节点选址问题,进而提出了数据挖掘模型。该模型与选址的决策思维过程相适应,具有很好的理论指导意义。
粒计算;物流节点选址;金字塔模型;数据挖掘模型
物流节点选址问题属于物流系统规划中的子问题,其位于物流系统规划层次中的战略规划层。目前,物流节点选址方法缺乏系统的理论指导和规范的决策流程,各种选址方法都有其各自的优劣势,没有一种方法既能够兼顾主观与客观,又能够保持决策的科学合理性和使用的方便性。因此,物流节点选址领域迫切需要引入新思想、新理论、新方法来解决这些问题。粒计算理论 (Granular Computing Theory,GCT)作为信息处理的一种新概念和计算范式,为物流节点选址研究中的一些问题提供了新的思路和途径。
物流节点选址的影响因素众多而复杂,直接基于众多影响因素建立决策模型是非常复杂和不经济的,通过粒计算理论将众多影响因素进行简化是做出低成本的科学合理决策的重要途径之一。故本文先从物流节点本身的界定出发,引入粒计算的思想与选址问题相结合,建立了金字塔模型,并将之运用于物流节点的理论选址中,具有很好的应用前景。
1 物流节点的界定
物流选址是物流系统规划中的战略重点,它决定了整个物流系统的模式、结构和形状,影响着库存成本、运输成本。全部物流活动是在线路和节点进行的。其中,在线路上进行的活动主要是运输。物流功能要素中的其他所有功能要素都是在节点上完成的。所以,物流节点是物流系统中非常重要的部分[1]。
广义的物流节点是指所有进行物资中转、集散和储运的节点,按作用不同可分成转运型物流节点、储存型物流节点、流通加工型物流节点、综合型节点四大类型[2]。狭义的物流节点仅指现代物流意义的物流中心、物流园区和配送中心[1]。如无特别说明,本论文所叙述的物流节点,均指狭义物流节点。随着现代物流学的发展,本文从三方面来界定物流节点:
(1)交通方式:不同的交通方式如水路运输、铁路运输、公路运输、航空运输、管道运输等可以在节点处交汇、衔接,形成一个功能强大的多式联运体系。
(2)拓扑结构:多个节点组成的网络拓扑结构,节点内部的布局结构、不同节点间的连通方法及衔接方式、信息传递的流通结构等等,对于节点网络的顺畅运行至关重要。
(3)空间形式:节点空间包括多种制约因素,如交通空间、经济空间、政策空间、环境约束、用地条件及人口状况等等,这些因素对于节点的选择和有效运营非常重要,甚至有着决定性的作用。图1是物流节点的三维界定关系。
2 建模基础——粒计算在选址问题应用中的可行性
粒计算 (Granular Computing,GrC)[3]是 T.Y Lin教授在1997年第一次提出的,是软计算科学的一个重要分支,已成为不精确信息、模糊信息、不完备信息及海量信息处理的重要工具,也是人工智能领域研究的热点之一。
粒计算的基本思想就是利用事物在层次和结构上的特性,建立可以在不同层次上对问题进行求解的模型。其中最基本的概念有粒、粒化、粒结构和粒运算[4]。所谓粒就是按照某种粒化准则对具体问题进行某种层次的抽象所得到的结果。粒度的大小反映了抽象的程度,也是对具体问题不同层次细化的度量。粒化可以理解为粒的构造过程。一个粒化准则对应一个粒层,不同的粒化准则对应多个粒层,所有粒层之间的相互联系构成一个关系结构,称为粒结构[5]。而粒的运算涉及到的主要问题是粒层的映射、不同层次上粒的转换以及粒的性质保持性。
粒计算是信息处理的一种新概念和计算范式,为知识发现研究中的一些问题提供了新的思路和途径。它是研究多层次粒度结构的问题求解方法、思维方式及信息处理模式。粒计算从实际出发,用可行的满意近似解替代最佳的精确解,改变了传统的计算观念,得到对问题的简化,实现问题求解的鲁棒性,降低求解费用。其主要思想是在不同的粒度层次上进行问题求解,在很大程度上体现了人类问题求解过程中的智能[6]。
粒计算理论符合物流节点选址的决策过程,其本质上与思维决策具有一致性;粒计算能够用多层次,多视角的系统分析法来处理复杂问题,使复杂的选址决策问题流程规范化、层次化,综合考虑多方面的影响因素,减少决策成本;粒计算理论通过粒化的方法将问题抽象细化,使复杂问题得到简化,这就可以根据具体问题对选址问题的指标因素进行抽象细化以建立符合实际要求的选址决策指标体系;粒计算从实际出发,用可行的满意近似解替代最佳的精确解,符合选址决策问题的内在要求,可以降低选址成本,提高选址效率,具有很高的实用价值及经济价值。
综合上述分析,本文根据物流节点的选址目标运用粒计算理论将人的思维分为宏观思维、中观思维及微观思维 (当然这种划分不是绝对的、不变的),与之相对应的可以根据因素的影响程度将物流节点选址问题的指标分为一般影响因素、间接影响因素及直接影响因素,由此可以抽象出该问题宏观选址指标模型、中观选址指标模型及微观选址指标模型。
3 基于粒计算物流节点选址的理论架构
本文针对物流节点选址问题的特点及人的决策思维模式,以客观数据为出发点,以 “有限理性”、 “有限记忆”、 “群体决策”和 “粒计算”为理论基础,提出了基于粒计算的物流节点选址模型,形成了一个多层次结构的金字塔理论架构。不同的粒度对应不同的层次,所考虑问题的精度及复杂度各不一样。越接近宏观模型,抽象程度越高,考虑的范围越广,需要的精度越小;越接近微观模型,抽象程度越低,考虑的范围越窄,需要的精度越高。其理论框架如图2所示。
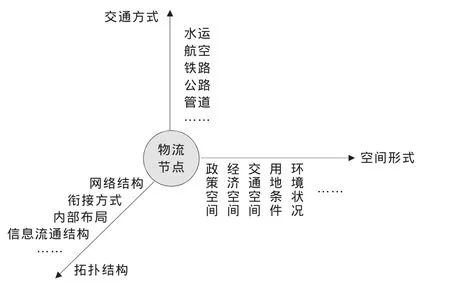
图1 物流节点的三维界定
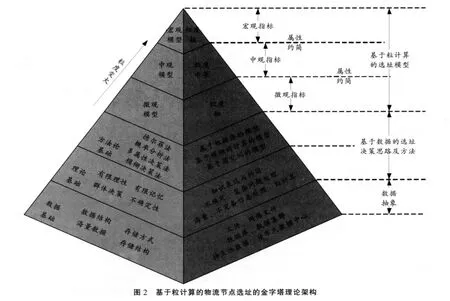
图2中,客观数据是作出合理科学物流选址决策的基础,人的 “有限记忆”决定了人只能具有 “有限理性”,这就需要 “群体决策”来弥补 “有限理性”与 “有限记忆”的不足,使决策尽可能地接近 “完全理性”与 “最优结果”。物流节点选址是一个复杂的多属性决策问题,模糊决策法能够处理许多不确定问题,德尔菲法是 “群体决策”的一种很好的实现形式,这些方法为理论的研究提供应用方式。粒计算的理论结构与认知世界的结构、人类思维模式及行为方式具有一致性,能够处理不确定的、模糊的、不完整的和海量的信息。它从实际出发,用可行的满意近似解替代最佳的精确解,符合 “有限理性”的约束,是选址决策问题的内在要求,可以集成上述的理论及应用方法,进而降低选址成本,提高选址效率,具有很高的实用价值及经济价值。
4 金字塔模型在物流节点选址的实际应用
本节主要研究基于粒计算的物流节点选址的理论框架在应用中如何解决实际选址问题。物流节点选址问题本质上是决策问题,所以我们以一般决策问题的解决方法为思路,以客观信息数据为中心,围绕着数据进行挖掘分析,避免决策的主观性及不确定性,以作出合理科学的选址决策[7]。其应用框架如图3所示。
图3中主要包括两大部分:一般决策问题通用的理论解决方法及现实应用中的实际解决过程。其中实际解决过程主要包括以下四个模块:
(1)数据预处理模块
在实际系统项目中,数据以文件或表的形式存储在数据库、数据仓库或云存储器中。首先,根据要解决的目标任务,从这些数据源中读取与筛选出相关的数据信息,如果存在不完备信息,则根据一定的先验信息,将不完备信息系统进行补全以转化为完备信息系统;然后选择合适的离散化方法,对连续的属性值进行离散化;最后根据属性值对所有对象进行粒化。
(2)属性约简模块
利用属性约简算法对信息系统进行属性约简,删除冗余的属性数据,得到最小约简集,从而可以大幅度地减少数据量,降低复杂度。属性约简是一个NP-Hard问题,但是在很多应用中,我们不需要求出全部约简,每个约简只是在某个角度上,利用最少的属性对论域进行分类。
(3)规则挖掘模块
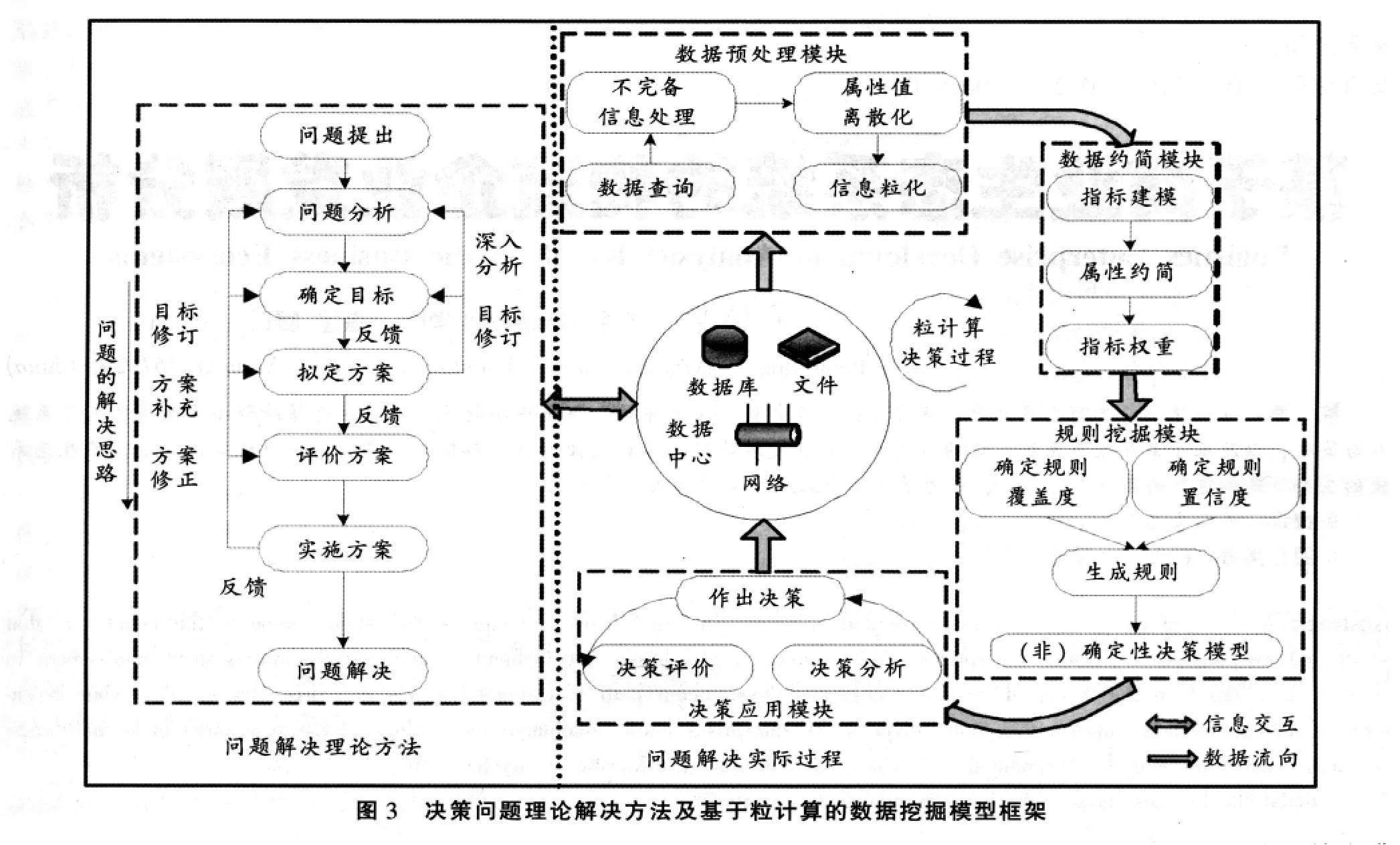
根据用户给定的覆盖度和置信度闭值,挖掘出所有满足条件的最简规则,这个过程为规则的自动生成;具体步骤为:执行完属性约简之后,对每个信息粒与决策属性进行粒化,生成基本粒库,从每个决策粒出发,输出满足条件的决策规则,接着生成高阶粒库,继续提取规则,直到算法结束,从而得到了该约简的规则。
(4)决策应用模块
分析经过解释的规则,从中挖掘出的规律,这些规则为人的主观决策提供参考,这就需要决策者来分析、判断规则是否合适、合理,是否能用于决策。有价值的或者能够揭示数据内部规律的规则才能帮助决策者作出合理科学的决策,而有偏差的或者不能反映数据内部规律的规则可能会误导决策者作出错误的决策。
5 结 论
本文首次对物流节点做了三维界定,通过阐述粒计算理论的特点,分析了其在物流节点选址中的可行性,并论述了基于粒计算的物流节点选址的建模基础及建模方法,并以此为基础建立基于粒计算的物流节点选址的金字塔模型,并利用数据挖掘理论,建立了基于物流节点选址的数据挖掘模型。为物流节点的选址问题提供了新的理论及应用框架基础,具有很好的实际应用价值。
[1]Hainanmumian. 物流节点[DB/OL].(2010-07-15)[2012-05-30].http://baike.baidu.com/view/1048718.htm.
[2]王之泰.新编现代物流学[M].北京:首都经济贸易大学出版社,2005:366-367.
[3]Lin T Y.Granular Computing,Announcement of the BISC Special Interest Group on Granular Computing[DB/OL].(2010-05-16)[2012-05-30].http://www.cs.uregina.ca/~yyao/GrC/.
[4]吴珺.基于粒计算的数据挖掘应用及研究[D].武汉:武汉理工大学 (硕士学位论文),2009.
[5]YAO Y Y.Granular computing for data mining[C]//Proceedings of SPIE Conference on Data Mining,Intrusion Detection,Information Assurance,and Data Networks Security,Kissimmee,USA,2006.
[6]郑征.相容粒度空间模型及其应用研究[D].北京:中国科学院研究生院 (博士学位论文),2006.
[7]Li-yan ZHANG,Yan SUN,Jian MA.A Decision Support System of Logistics Location[C]//2010 the 2nd IEEE International Conference on Information Management and Engineering,2010:85-89.
Theoretical Modeling Based on Granular Computing in Logistics Nodes Location
ZHANG Li-yan1,2,MA Jian2
(1.School of Civil Engineering,Suzhou University of Science and Technology,Suzhou 215011,China;2.School of Transportation Engineering,Tongji University,Shanghai 201804,China)
The paper firstly circumscribes a new concept of the logistics node from the three-dimensional aspect.According to the characteristics of the logistics node and the nature ofhuman decision-making,itputs forward a theoretical framework of pyramid,which starts from objective data and is based on “bounded rationality”, “limited memory”, “group decision” and “ granular computing”.Simultaneously,it presents the application framework of logistics location from the process of the decision-making thought and the point of view of data mining,which can provide the reference pattern and standardized application flow for the pyramid model under the actual scenario of logistics location.
granular computing theory;logistics nodes location;pyramid model;data mining model
F250
A
1002-3100(2012)09-0004-04
2012-06-20
国家自然科学基金项目,项目编号:71072027。
张丽岩(1978-),女,黑龙江齐齐哈尔人,苏州科技学院土木工程学院,工程师,同济大学交通运输工程学院博士研究生,研究方向:物流系统、交通规划;马 健(1979-),男,江苏扬州人,同济大学交通运输工程学院博士研究生,研究方向:交通仿真、物流仿真。
猜你喜欢
纺织科学研究(2021年9期)2021-10-14
广西农学报(2019年4期)2019-11-26
成都信息工程大学学报(2019年2期)2019-08-28
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
自动化学报(2018年2期)2018-04-12
成都信息工程大学学报(2017年1期)2017-07-21
温州职业技术学院学报(2014年3期)2014-03-11
河南科技(2014年7期)2014-02-27
宿州学院学报(2013年5期)2013-04-11
上海电机学院学报(2013年4期)2013-03-11
