
面向语音情感计算的数据库的构建与应用研究
2012-06-07 04:15任鹏辉张雪英
电视技术 2012年21期
任鹏辉,张雪英,孙 颖
(太原理工大学信息工程学院,山西 太原 030024)
随着人机交互技术的发展,语音技术已在科学研究与应用等领域中起到了很重要的作用[1]。其中,语音情感计算是一项研究如何模拟或识别说话人语音信号中的喜怒哀乐等情绪和情感因素的研究课题,具有很大的研究意义[2-3]。语音情感计算主要包括语音情感识别与情感语音合成。其情感识别率与合成的语音质量、情感表达都与语音库原音选择有直接关系,因此越来越多的研究人员开始致力于情感语音库的构建与研究[4]。
目前,国外已有多家机构组织建立了情感语音数据库[5],如 Belfast Database,Belfast Natural,Albelin,Banse and Schere,Mozziconacci,Reading-Leeds Database 等,这些数据库涉及到英语、德语、瑞典语、荷兰语等多个语种,国内情感语音库有中科院情感语音库、CESD,一些高校如清华大学、浙江大学、江苏大学等也都建立了自己的情感语音库。上述语音库的情感诱发方式,数据收集,收录情感状态、规模以及发音人数量都不尽相同,以满足不同需求的情感语音研究。
语音库的构建为情感计算的应用提供了重要的应用基础。在情感识别中,语音库经训练形成供输入语音匹配的情感模板库。在情感语音合成中,语音库经参数提取形成情感语音模板,输入文本利用模板来合成出相应情感的语音。一般来说,可满足语音合成需求的语音库也可满足情感识别。本语音库的特点有:数据规模要求比较大、特定人发音、语音标注准确、以句子为收录单位、情感表达准确等。现有数据库由于版权、规模、费用、功能用途等方面原因很难满足现有的语音合成系统要求。因此,本文设计了一种利用录音截取与韵律特征修改这种创新方法,建立了既可满足情感语音合成又可满足情感识别需求的多用途情感语音库。
1 语音库构建概述
语音库的建立流程可分为3个阶段:1)文本筛选及录音截取阶段。首先运用贪婪算法对文本源语料进行筛选,然后对文本所对应的语音文件进行截取。2)韵律调整阶段。对截取出的语音韵律特征进行调整,得到高兴、愤怒、悲伤等不同情感的语音。3)数据筛选阶段。运用本文所提出的一种改进的模糊综合评价方法对情感语音数据的听辨与评选。下文将对每个阶段作详细说明。其制作流程如图1所示。
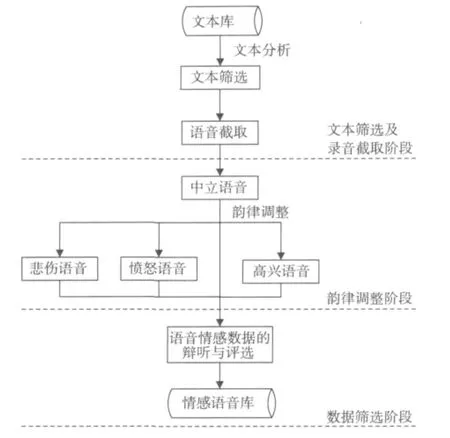
图1 情感语音库制作流程
2 面向语音情感计算的数据库构建
2.1 文本筛选
构建语料库要求文本覆盖语言中的各种语言单元,同时又要求语料库的规模不能过大。与语音识别语料库不同的是语音合成语料库要求语料遵循语音单元的自然平衡规律,音素在语料中出现的概率贴近于自然,让稀少的音素出现频率小,让常用的音素出现频率大。所以,需要筛选出最有利用价值的句子来组成文本语料库。
本文选择了美国之音VOA新闻稿作为文本源,该语音由Steve Ember播音,其特点是资源开放、发音标准、语音纯净、朗读风格,涵盖涉及文化、军事、农业等广泛内容,其语义不包含某一方面的情感倾向,有较高的情感自由度。选取了3500句播音文本作为语料集,每句朗读时长5 s以上。参考HTS demo,从中选出1000句作为最终的语料库。语料筛选采用一种改进的贪婪算法(S={所有句子的集合},U={要覆盖的音素集合},C=空集)[6]:
1)将文本转化成音素,统计每种音素在文本中所出现的概率P。
2)逐一统计S中句子i的分值

式中:K为句子中所有音素分值之和;将1/P作为该音素的权值;n为句子中语音单元的个数。
3)删除S中分值最高的1000个句子,并将其归入集合C,并从U中删除这1000个句子中所包含的单元。
4)若U不为空集,则将S中包含U中剩余音素得分最高的句子替换C中分数最低的句子。
5)C即为语料库集合。
2.2 语音截取与情感韵律修改
按照已筛选出的语料文本用Cool Edit Pro软件截取出其对应的1000句语音文件,由于原始新闻朗读语音不带有其他情感色彩,所以可以直接作为中立情感语句。再通过调整其韵律特征,修改成高兴、愤怒、悲伤等其他情感语句。
2.2.1 情感语句韵律分析
参考Russell采用4个象限的概念来定义情感种类[7],本文采用了4种主要情感:愤怒、高兴、中立和悲伤。这4种情感模型的好处是情感粒度大,容易区分辨别[8]。说话者在不同的情感状态下说出的语音对应着不同的韵律特征,韵律特征主要有基音频率、幅度和时长等[9]。所以对语音信号中的情感信息研究首先需要对韵律特征进行研究。表1所示为语句“生活是这样的”分别在中立、高兴、悲伤、愤怒4种情感下的韵律特征的具体数值。
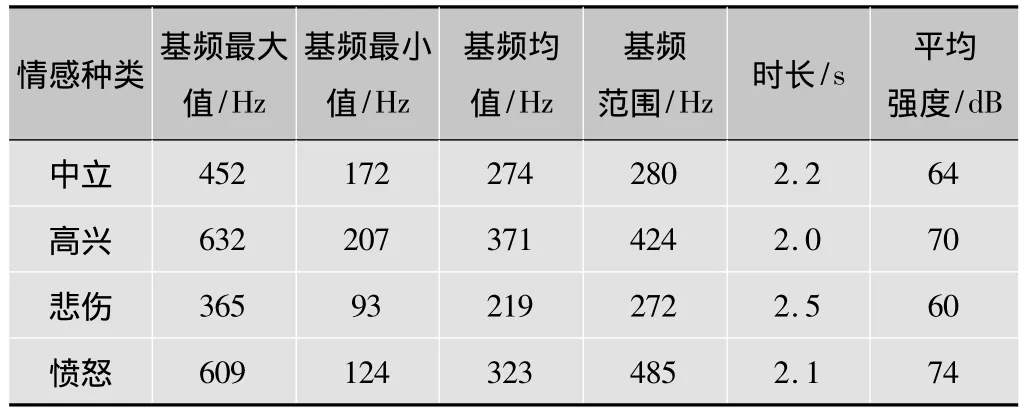
表1 各种情感语句韵律特征的具体数值
通过大量情感语句的比对,可以总结出:“高兴”的基频最高、语速最快;“愤怒”次之,但能量略高于“高兴”;“悲伤”的各项韵律特征数值均低于其他3种情感。另外,各种情感状态的波形在重音部分是否加强,头尾部形状也不尽相同,运用以上规律,可以很清楚地把“高兴”、“愤怒”与“悲伤”情感语音区分开来。
2.2.2 情感韵律修改
根据已统计的韵律参数规律对截取的中立语音进行相关韵律参数的修改,可以得到其他带有情感的语音[10]。其修改方法为:通过调整基频曲线,提高或者减小整体基频数值,再对重音、头尾部形状做相应修改。通过调整语音时长,改变不同情感状态下的语速快慢。通过调整语音音量,控制其能量大小。
本文中将Steve Ember的1000句中立语音通过Cool Edit Pro与praat软件修改成为高兴、愤怒、悲伤3种情感语音各1000句,其修改数值经大量主观辩听实验验证及相关文献的参考[11],可基本满足其他3种情感表达的需求。另外,修改数值还跟发音人的音质有直接的关系,所以除了遵循韵律参数的大致规律外,还需依靠人工主观辩听修改语音细节,以求得到更加真实、情感表达更加准确的语音。修改规则如表2所示(以中立语音为参考值)。
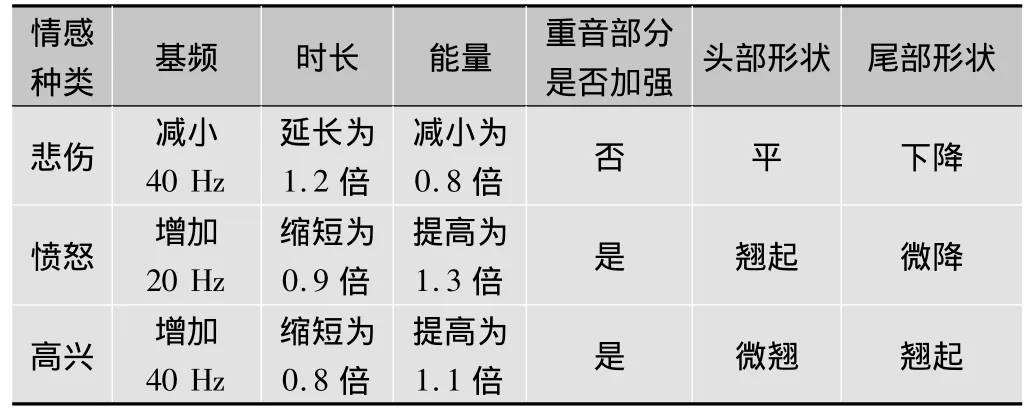
表2 特征修改规则
修改过程中主要以人的主观辩听为参考因素,以语音通顺、自然流畅为前提。
2.3 情感语音数据的听辨与评选
为了保证所采集的情感语料的可靠性,对语音情感数据进行了主观听辨与评选[12]。由于本数据库不同于传统数据库,需考虑语音情感表达准确度、清晰度、自然度等多方面因素来综合验证数据的可靠性,因此本文运用了一种改进的模糊综合评价方法对语音数据进行评测。其步骤如下:
1)确定综合因素评价集 V={V1,V2,…,V6}。其中,V1,V2,…,V6分别代表情感表达、情景感、清晰度、自然度、流畅度、噪音影响等6个子集。
2)根据各子集对整体的影响大小,约定各子集的权重,得权重集 A={a1,a2,…,a6}={0.30,0.20,0.10,0.10,0.10,0.20}。
3)10位评测人对某条语句打分,打分细则如表3所示。
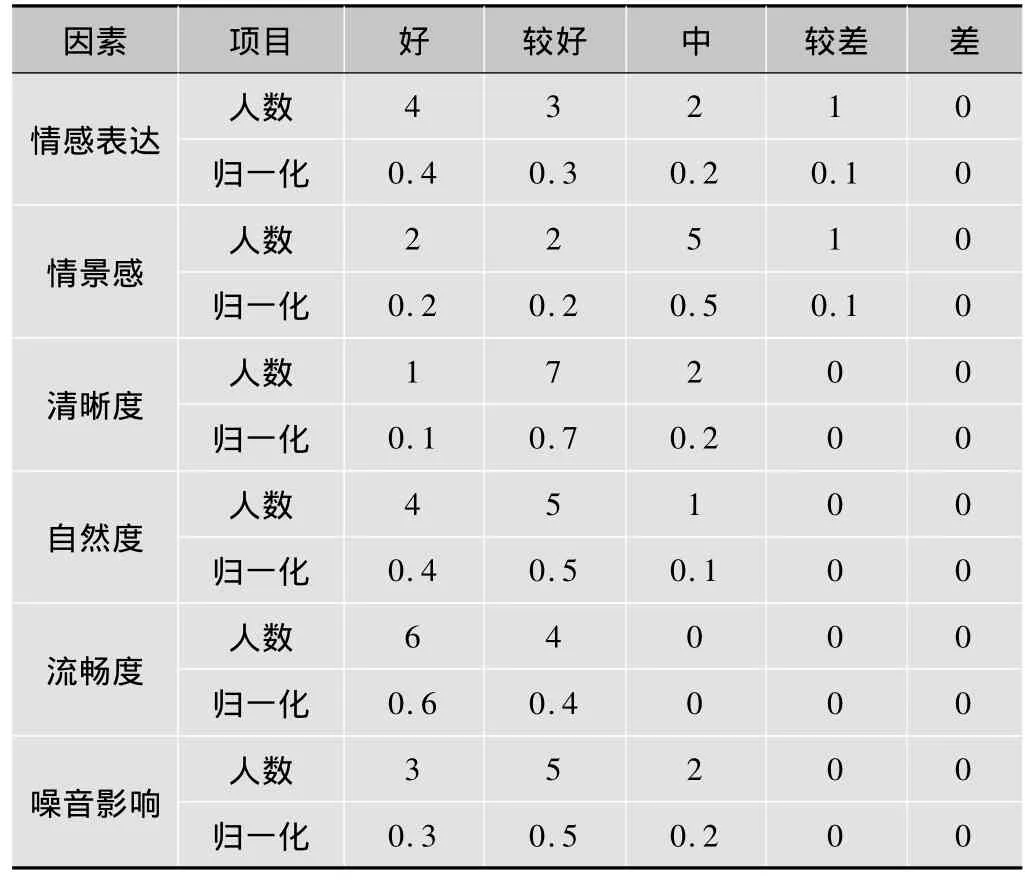
表3 语句打分表
4)归一化后的数据构成一个V的模糊评价矩阵

式中:◦为模糊矩阵乘法符号。归一化得
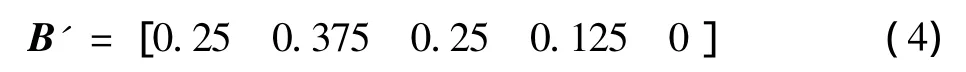
5)求得此条语句的总得分,可以对5个级别分别赋以分值,如约定好为100分,较好为85分,中为65分,较差为35分,差为0分,则总得分
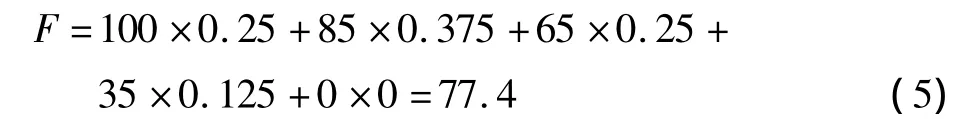
6)如果语句得分大于等于60分,则保留;否则,认为此条语句不合格,剔除之后重新修改。
3 情感语音库的应用研究
将语音情感识别系统与情感语音合成系统有机地结合在一起,使计算机能够与人进行情感语音交流是人机交互应用研究的热点之一。目前,此类技术已经在语音搜索、人工智能、交通医疗等领域都有了相当规模的应用,如谷歌Voice Search、苹果的Siri通过人类语音信号即可实现人机互动。此类技术的前端方面,即面向用户和用户交互(User Interface,UI)的技术,主要就是语音识别以及语音合成技术,在其中加入情感信息可使人机交流变得更加人性化。语音识别技术是把用户的口语转化成文字,其中需要强大的语音知识库,需要用到“云计算”技术。而语音合成则是把返回的文字结果转化成语音输出,这个技术理论上本地就能完成。这里主要介绍情感语音库在语音情感识别与情感语音合成两方面的应用。
3.1 在语音情感识别方面的应用
语音情感识别是利用计算机识别发音人情感状态的技术。其流程包括预处理、特征提取和模式匹配3个部分,如图2所示。
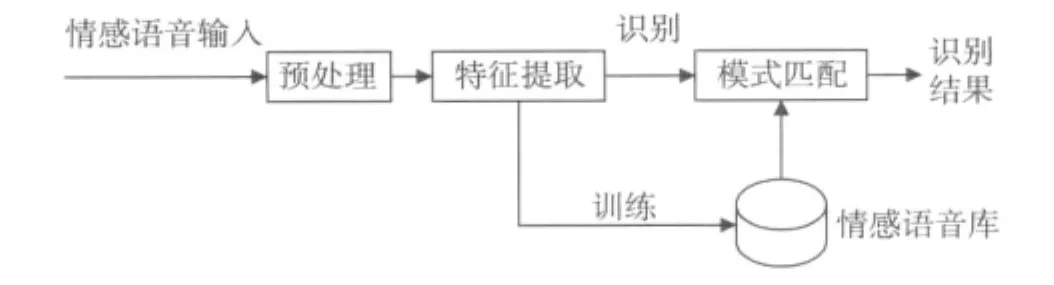
图2 语音情感识别系统框图
语音情感识别系统本质上是一种模式识别系统,语音库中的情感语音信号经过预处理后进行特征参数提取,然后将不同情感的特征参数训练成不同的模板库。待识别的语音信号特征参数与模板库进行模式匹配即可得到情感识别结果。因此识别结果与语音库质量好坏、模板是否准确都有直接的关系。语音库的建立为整个语音情感识别过程提供了重要的前提工作与基础。
3.2 在情感语音合成方面的应用
情感语音合成就是利用语音合成技术实现文本到带有人类情感语音的转换,使机器也能发出带模拟人类情感的语音。本文主要介绍语音库在基于HMM情感语音合成法中的应用,如图3所示。
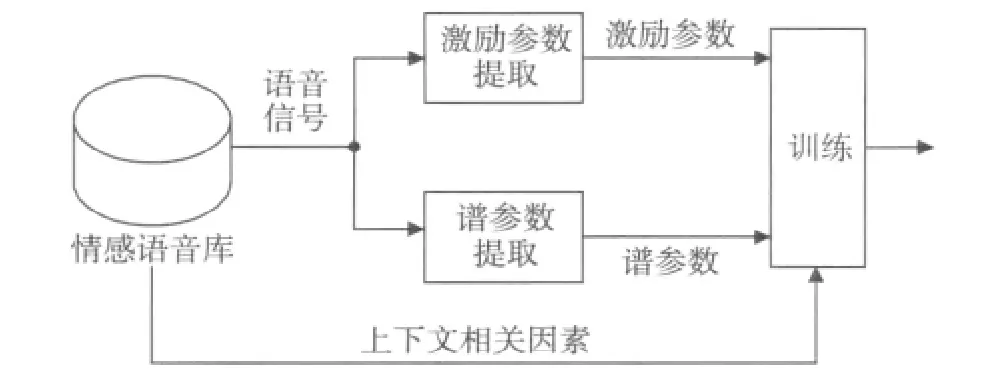
图3 基于HMM语音合成训练部分流程图
基于HMM的语音合成系统包括训练和合成两个部分。在训练部分中需从情感语音库中提取激励参数与谱参数,利用上下文相关因素,对声道谱、基频和时长进行建模[13]。在之后的合成部分中,输入的文本利用这些模型通过参数合成器合成出情感语音。所合成出的情感语音同样与语音库的情感表达准确度、语音质量等因素有直接的关系。
4 小结
本文首先利用贪婪算法对数据进行筛选,然后通过录音截取与韵律特征修改这种创新方法设计并建立了一种面向语音合成的情感语音库。包括中立、悲伤、高兴、愤怒4种情感,每种1000句,共4000句情感语音。最后利用模糊综合评价方法对情感语音数据的听辨与评选来确保语料的可靠性。同时简要论述了本语音库在语音情感识别与情感语音合成方面的应用。
本文总结了各种情感状态下韵律特征规律。按照此规律,通过主观辩听调整中立语音得到情感的语音,这也是本文中的难点。其语音质量受到发音人与主观辩听调整的较大影响,每句语音的具体修改数值也不尽相同。所以总结出一套更加具体、完善的韵律特征修改方案是今后工作的研究重心。建立一个发音自然度高、情感表达准确的语音库才是语音情感计算进入实际应用的一个重要基础和前提工作。
[1]GUDNASON J,THOMAS M R P,ELLIS D P W,et al.Data-driven voice source waveform analysis and synthesis[J].Speech Communication,2012,54(2):199-211.
[2]周沽,赵力,邹采荣.情感语音合成的研究[J].电声技术,2005,29(10):57-73.
[3]陈洁,张雪英,孙颖.基于HMM的可训练情感语音合成研究[J].电声技术,2012,36(3):43-46.
[4]ELLEN D C,NICK C,RODDY C,et al.Emotional speech:towards a new generation of databases[J].Speech Communication,2003,40(1):33-60.
[5]徐露,徐明星,杨大利.面向情感变化检测的汉语情感语音数据库[J].清华大学学报:自然科学版,2009,49(S1):1413-1418.
[6]庞敏辉.语音库自动构建技术的研究[D].青岛:中国海洋大学,2010.
[7]LIEBERMAN P,MICHAELS S B.Some aspects of fundamental frequency and envelop amplitude as related to the emotional content of speech[J].Journal of the Acoustical Society of Ametica,1962,34(7):922-927.
[8]SCHERER K R,BANZIGER T.Emotional expression in prosody:a review and an agenda for future researeh[C]//Proc.Speech Prosody,2004.Nava,Japan:ISCA Speech,2004:359-366.
[9]蒋丹宁,蔡莲红.基于语音声学特征的情感信息识别[J].清华大学学报:自然科学版,2006,46(l):56-89.
[10]ELLIOT M II,MARK C,JOHN P,et al.Comparing objective feature statistics of speech for classifying clinical depression[J].IEEE Engineering in Medicine and Biology Society,2004,26(1):17-20.
[11]党培霞.基于情感基音模板的情感语音合成[D].长沙:中南大学,2010.
[12]黄程韦,金赟,赵艳,等.实用语音情感数据库的设计与研究[J].声学技术,2010,29(4):396-399.
[13]张雪英,陈洁,孙颖.改进的HMM合成系统在英语合成中的研究[J].太原理工大学学报,2012,43(1):16-19.
猜你喜欢
北京教育·普教版(2020年9期)2020-10-09
校园英语·中旬(2019年11期)2019-11-26
中华诗词(2019年1期)2019-08-23
广西教育·D版(2019年6期)2019-07-11
福建基础教育研究(2019年11期)2019-05-28
速读·中旬(2018年8期)2018-10-23
乡村地理(2018年4期)2018-03-23
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12
