
用于单视加深度视频编码的快速立体匹配算法
2012-04-04 00:38:34陈贺新刘伯轩
吉林大学学报(工学版) 2012年4期
赵 岩,刘 静,陈贺新,刘伯轩
(吉林大学通信工程学院,长春130012)
近些年来,立体视频的应用已融入我们的日常生活,如三维立体电视、机器人的视觉系统等[1]。与普通的单通道视频相比,立体视频要处理的数据量相当大,因此解决立体视频数据的压缩传输问题成为了当今的研究热点。单视加深度的立体视频编码方法,只编码参考视点(如左视点)和左右视点的视差/深度图,这样可以大大减少传输的数据量,被广泛认为是很有前景的立体视频编码方法。立体匹配的任务是在左右图像上使同名像点得到匹配,并通过计算位置偏差,从而生成视差图[2]。当前的一些算法已经能获得较好质量的视差图,但其算法大都过于复杂,效率较低[3-4]。
本文算法参考了文献[4]基于分块的置信传播立体匹配的算法构架,借鉴了近来比较热点的基于分块的方法[5-7],并在此基础上,针对算法效率不高的问题,利用H.264对参考图像编码过程中产生的运动信息作为辅助信息,通过利用立体视频前后两帧之间的相关性,改变P帧立体匹配给每块分配的视差片的初值,提高立体视频P帧的匹配效率。
1 基于分块的置信传播立体匹配
算法的应用基于假设视差的变化只发生在分块区域的边缘。分块算法对不连续和大块的无纹理区有很好的处理效果,而且可以较精确地定位深度边界。具体算法按照以下4个步骤执行。
1.1 帧参考图像的分割
对参考图像进行分割,假设每个分割区域内的视差变化平滑。算法采用均值平移(meanshift)高效图像分割算法[8]。该算法能将图像中每一个像素归类到相应的密度模式下。从而实现聚类并得到一系列互不交叉的区域,具有分割精度高的特点。
1.2 初始化匹配代价
算法采用基于窗口的局部匹配算法计算稀疏的初始视差图。绝对亮度差(SAD)算法是计算各像素在不同视差时的匹配代价的常用算法[9]。算法采用SAD和基于梯度相结合的算法,定义如下:
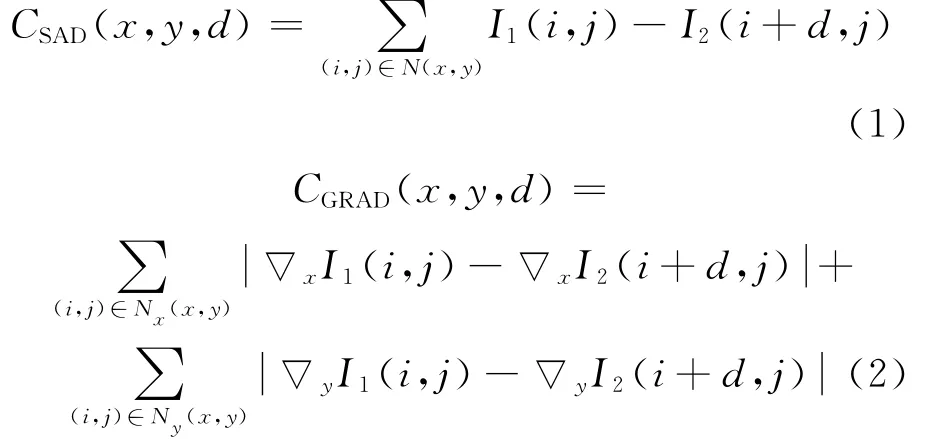
式中:N(x,y)是(x,y)处的一个3×3窗口;Nx(x,y)代表除去最右列后的窗口;Ny(x,y)代表除去最下行后的窗口;▽x代表正向向右梯度;▽y代表正向向下梯度。
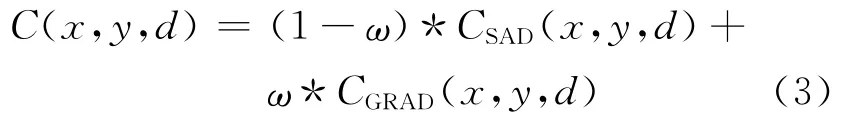
式中:C(x,y,d)即为点(x,y)的匹配代价;ω为最优权重。
此处采用交叉校验,令(x',y')为参考图中像素(x,y)基于初始视差d(x,y)在目标图中的对应点,令d(x',y')为目标图像像素点(x',y')的初始视差,如果d(x,y)=d(x',y'),则取(x,y)为可靠点。令两幅视差图中可靠对应点最多的ω即为CSAD(x,y,d)和CGRAD(x,y,d)之间的最优权重。
1.3 视差片估计
该步的目的是给每个参考图像中的分割块在视差图中匹配一个视差片。算法利用一系列二维视差片来表征图像结构,每个视差片有3个参数c1、c2、c3,确定了参考图像每个像素(x,y)的视差d=c1x+c2y+c3。
此步骤通过下面两个步实现。
平面拟合:由于离群点(outlier)的存在将影响视差片估计,该步的主要目的就是估计离群点的视差。首先对每块中所有位于同一水平线上的可靠视差点求导,将所求的导数δd/δx插入到一个表中并排列,应用高斯内核卷积得到一个最佳水平斜率c1。针对竖直方向重复上述方法可得竖直斜率c2,继而便可以得到c3。确定了视差片参数即可估计块中各点的视差值。
视差片细化:该步把那些经计算具有相同视差值的相邻区域组合,并对其进行重复的平面拟合以确定更加精确的视差片。把每块的所有像素的匹配代价求和得到相应视差片的匹配代价:

式中:S代表所分块;P代表相应的视差定义为d的视差片。
分别把上步拟合中求得的各像素的视差变化范围(dmin,dmax)中的视差代入式(4)中,得到具有最小匹配代价的视差片分配给相应的块。然后把具有相同视差片的相邻区域组合。最后对所有重组视差片进行重复平面拟合使其更加精确。
1.4 用优化算法求精确视差
这步的目的是使每一个分割拟合后的块找到最优对应的视差片。令R为参考图像分割拟合后的块空间,D为视差片的估计值空间,f是分配给每块s的视差片f(s)∈D,匹配的目的就是找到标记f,使得每一个像元集s∈R都能得到相应的标记f(s)∈D,应与观察数据相吻合。这个问题可以看作为分割拟合后的块的一个能量最小化问题[10]来求解,置信传播实现能量最小化时,消息传递发生在相邻块之间:
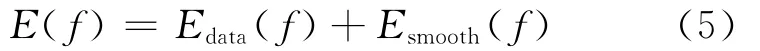

2 算法实现
把参考帧编码过程中产生的运动矢量信息作为辅助信息,用于下一帧的立体匹配过程中,以提高立体匹配的效率。设参考帧编码产生的运动信息水平分量矩阵为Vx,竖直分量矩阵为Vy。
2.1 单视编码中的运动信息
本文算法基于H.264平台,在H.264中,运动估计是视频编码最关键的技术之一,能有效去除视频时间冗余[11]。在运动估计的各种方法(梯度方法、像素递归方法、块匹配运动估计方法等)中,块匹配运动估计算法简单有效且易于硬件实现,被当今视频编码标准广泛采用。本算法采用的H.264平台亦采用此运动估计法,其基本原理是:在给定搜索窗口内,在参考帧中,搜索当前块的最优匹配块,以寻找其最优运动信息Vx、Vy。
2.2 基于运动信息的快速立体匹配
在对I帧立体匹配的过程中,视差片估计会得到一个视差片的估计值CSEG(SI,PI),并把该图像矩阵的坐标与视频编码中I帧到P帧的最优矢量Vx、Vy相加,寻找到运动点在P帧中的位置,以I帧中相对应点的视差估计值作为P帧的视差估计值,重新组合成新的视差片。
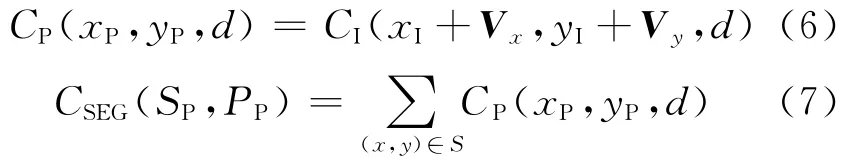
最后把CSEG(SP,PP)代入式(5),得到
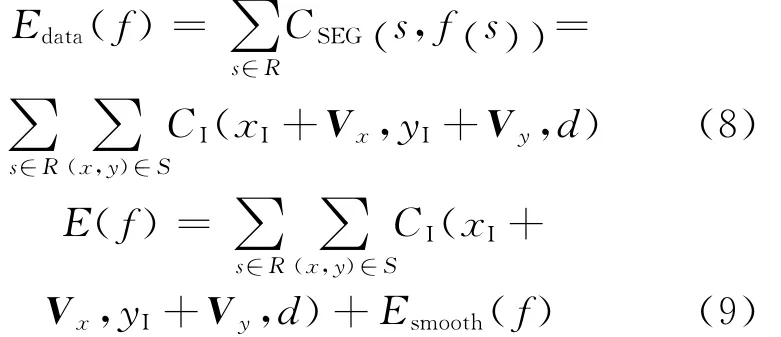
重复立体匹配的第四步用全局的置信传播算法迭代求得E(f)min,以得到最优视差。
3 实验结果及分析
实验选择Breakdancer立体视频测试序列的2、3视点和Book-sale立体视频测试序列对的前三帧作为测试图像。通过记录改进前后的每一帧视差图生成需要的时间来比较算法效率,如图1、图2所示。并利用两种算法生成的视差图与参考图像生成右视图,通过测试视差图绘制右视图的峰值信噪比PSNR来评价算法质量,如表1所示。本文实验序列的各帧图像均为320×240(宽×高)像素。
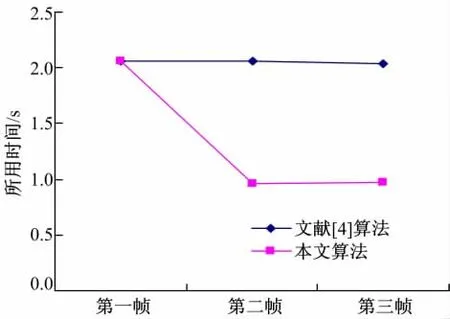
图1 Breakdancer序列两种算法生成前三帧视差图所需时间Fig.1 Time of generating disparity map in two algorithms for Breakdancer
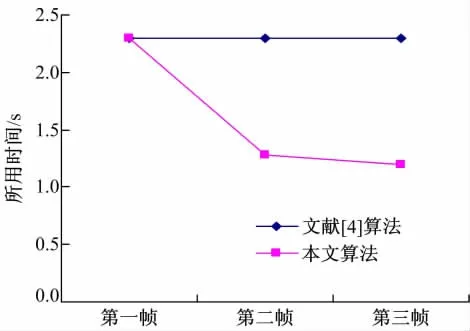
图2 Book-sale序列两种算法生成前三帧视差图所需时间Fig.2 Time of generating disparity map in two algorithms for Book-sale
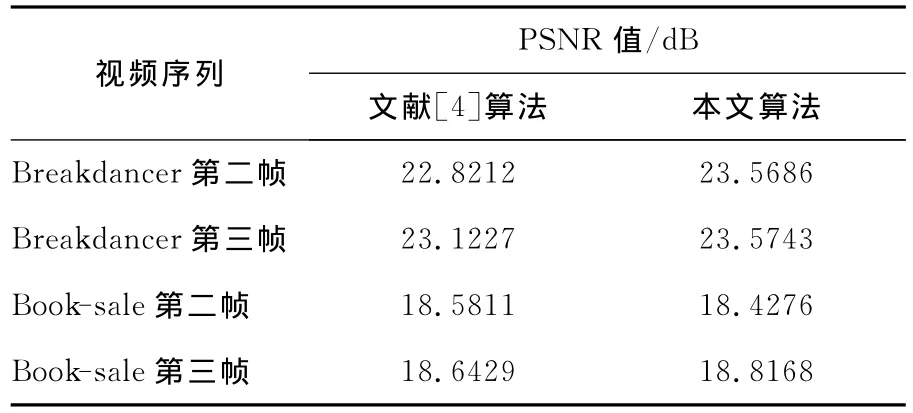
表1 两种算法得到的PSNR值Table 1 Values of PSNR obtained by two algorithms
由图1、图2可得,本文算法在生成P帧的视差图时可节省大约50%的时间,效率大大提高。表1对两种算法在重构右视图的PSNR进行了比较,可以看出,本文算法重构的右视图的PSNR值大都有所提高,虽然Book-sale第二帧的PSNR值有所下降,但其下降幅度也较小,由图3、图4实验结果主观图也可以看出,由本文算法生成的视差图在重构右视图的视觉效果上并没有下降。这个实验结果表明,本文算法可以在保证质量的前提下提高算法效率。

图3 Breakdancer序列的实验结果图Fig.3 Experimental results of Breakdancer

图4 Book-sale序列的实验结果图Fig.4 Experimental results of Book-sale
4 结束语
本文利用立体视频相邻帧之间的相关性,将单视编码产生的运动信息应用到深度图生成的立体匹配过程中,使立体视频传输中立体匹配的算法效率大大提高,该算法充分利用到了视频编码中产生的有用信息,避免了重复分块、重复拟合,从而改善了单视加深度视频编码中立体匹配耗时过多的问题。
[1]Schafer R.Review and future directions for 3D-video[C]∥Proceedings of the Picture Coding.Beijing,China,2006:1-11.
[2]耿英楠,赵岩,陈贺新.基于运动估计的置信度传播立体视频匹配算法[J].吉林大学学报:信息科学版,2010,28(4):330-333.
Geng Ying-nan,Zhao Yan,Chen He-xin.Stereo video matching algorithm of belief propagation based on motion estimation[J].Journal of Jilin University(Information Science Edition),2010,28(4):330-333.
[3]Larsen E S,Mordohai P,Pollefeys M,et al.Temporally consistent reconstruction from multiple video streams using enhanced belief propagation[C]∥IEEE Int Conf on Computer Vision(ICCV)-2007,Rio de Janeiro,Brasil,2007.
[4]Shawn Lankton.3D vison with stereo disparity[EB/OL].[2010-11].http://www.shawnlankton. com/.
[5]Bleyer M,Gelautz M.A layered stereo matching algorithm using image segmentation and global visibility constraints[J].ISPRS Journal of Photogrammetry and Remote Sensing,2005,59(3):128-150.
[6]Lee S,Oh K,Ho Y.Segment-based multi-view depth map estimation using belief propagation from dense multi-view video[C]∥IEEE 3D-TV Conf,Istanbul,Turkey,2008.
[7]葛亮,朱庆生,傅思思,等.改进的立体像对稠密匹配算法[J].吉林大学学报:工学版,2010,40(1):212-217.
Ge Liang,Zhu Qing-sheng,Fu Si-si,et al.Improved image dense stereo matching algorithm[J].Journal of Jilin University(Engineering and Technology Edition),2010,40(1):212-217.
[8]Comaniciu D,Meer P.Mean shift:a robust approach toward feature space analysis[J].PAMI,2002,24(5):603-619.
[9]殷虎,王敬东,李鹏.一种基于彩色图像分割的立体匹配算法[J].红外技术,2009,31(12):702-707.
Yin Hu,Wang Jing-dong,Li Peng.A stereo matching algorithm based on color image egmentation[J].Infrared Technology,2009,31(12):702-707.
[10]周秀芝,王润生.基于像元集的置信传递立体匹配[J].中国图像图形学报,2008,13(3):506-512.
Zhou Xiu-zhi,Wang Run-sheng.Pixel-set based stereo matching by using belief propagation[J]. Journal of Image and Graphics,2008,13(3):506-512.
[11]张春田,苏育挺,张静.数字图像压缩编码[M].北京:清华大学出版社,2006.
猜你喜欢
小型微型计算机系统(2022年1期)2022-01-21 02:55:06
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30 00:57:46
测绘科学与工程(2017年3期)2017-08-16 02:46:00
测绘科学与工程(2017年1期)2017-05-04 03:40:46
现代计算机(2016年3期)2016-09-23 05:52:13
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
浙江大学学报(工学版)(2016年11期)2016-06-05 09:21:03
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
西部广播电视(2015年5期)2016-01-16 03:45:06
