
我国房地产上市公司财务预警研究
2012-03-06 10:37:14刘立新
华东经济管理 2012年8期
李 恩,刘立新
(对外经济贸易大学 金融学院,北京 100029)
一、引 言
所谓企业财务预警,是指企业财务危机的预测与警报。自上世纪末我国住房市场化改革后,国内房地产企业开始蓬勃发展,房地产企业经营资金需求量大,对商业银行的信贷资金依赖严重,易受宏观经济政策的影响,房产价格变化莫测,这些特点使房地产企业面临很大的财务风险。因此,对房地产企业进行财务预警研究不仅对于房地产企业的稳健发展具有重要的现实意义,而且也是政府、商业银行、投资者关注的热点问题。本文以我国房地产上市公司为研究对象,通过建立并选择合适的财务预警模型来研究我国房地产企业的信用风险管理问题。
至今,关于企业财务预警的研究已近半个世纪,研究文献比较丰富,主要以构造不同财务预警模型为主。其中,Beaver(1966)做出了开创性的贡献,建立了一元判定模型,发现现金流量与负债总额的比率能较好地判定公司的财务状况[1]。Altman (1968) 研究出“Z-Score”多元判定模型[2],其改进版ZETA®被商业化并获得成功。Ohlson(1980)首次将Logistic回归模型应用到企业的财务预警当中[3]。之后有更多方法被应用于企业财务预警分析研究,包括一些非参数统计方法(如K阶近邻法、聚类分析、决策树法、支持向量机等)、数学规划法与专家系统方法等。近些年来,人工智能模型也被引入企业的财务预警研究,如Odom(1990)最先将神经网络引入信用风险评价,Barniv(1990)对神经网络模型和Logistic模型进行了比较,发现这两种模型在预测公司财务危机的准确率上并没有什么不同[4],Varetto(1998)首次将遗传算法引入了财务预警分析。
国内对财务预警的研究始于上世纪末,陈静(1999)利用国内上市公司的数据,用判别分析法研究了企业财务预警问题[5],吴世农、卢贤义(2001)建立了企业财务预警的一元判定模型、多元判定模型及Logistic回归模型并进行了比较,认为就单个财务指标而言,净资产报酬率的判别成功率最高,相对同一信息集而言,Logistic预测模型的误判率最低,财务困境发生前1年的误判率仅为6.47%[6]。其后许多研究者都在这一领域进行了研究。
目前,针对我国房地产企业进行财务预警的研究不多,主要有廖剑(2008)选取了2000年后的6家ST房地产公司,12家非ST房地产公司进行研究[7],肖冰、李春红(2010)基于2003—2008年房地产行业上市公司的季度财务数据运用Logistic模型进行了财务预警分析[8],孙晓琳等(2010)同样用2003—2008年间房地产行业上市公司的数据应用混合Logit模型预测了信用风险情况[9]。这些研究共同存在的一个问题是对模型自变量的选取标准来自其他研究文献,选取存在一定程度的任意性,未对自变量进行严格统计意义上的筛选,而选取合适的自变量是建立一个有效模型的基础。
本文的研究路径是:在样本选择的基础上,首先对于构建模型的自变量进行筛选,包括初选、根据两类公司财务指标分布是否相同进行筛选、根据单变量Logistic回归结果进行筛选、根据自变量间相关系数进行筛选,然后用筛选出的自变量构建三个Logistic回归模型,并根据三个模型的回归结果选择最适宜的模型,最后应用所得模型针对样本公司ST发生前一年、前两年、前三年、前四年的数据进行预测分析。
与以往房地产企业财务预警研究文献相比,本文的研究有几个方面的不同。首先,样本时间长,采用了从1998—2010年的所有房地产上市公司的数据;其次,以往的研究文献在变量的选择方面基于前人的研究,并未进行筛选,而本文通过统计手段对变量进行了筛选;最后,在结论的验证方面,向前追溯的时间长,验证了本模型的结论在样本前一年、前两年、前三年和前四年的预测准确率水平。
二、研究内容
(一)样本的选择
本文的研究基于使用公开数据进行财务预警分析,为了方便得到数据,选取房地产业的ST(特别处理)上市公司作为财务危机公司,非ST上市公司作为财务正常公司。需要说明的是,本文所选取的样本在2004年前为ST公司,在2004年后为*ST公司,这是由于2004年我国上市公司的上市规则发生了变化,对ST的规定有所改变,尽管名称有所变化,但2004年前的ST公司和2004年后的*ST公司被特别处理的原因是相同的,都是因为最近两个会计年度的审计结果显示的净利润均为负值、最近一个会计年度每股净资产低于股票面值或被注册会计师出具无法表示意见或否定意见的审计报告,表明这些公司财务状况出现异常。属于非财务因素被特别处理的公司不在样本选择范围以内。
本文样本数据选取了自1998—2010年48家ST房地产公司,48家正常房地产公司,数据来源于Wind数据库和北京聚源锐思数据库,财务危机公司与正常公司的比例为1∶1(这也是房地产上市公司ST与非ST的自然比例),组成一个包括96家房地产公司年度数据的数据库。将ST公司和正常公司各随机平分为两部分,组成各包含48家房地产公司(24家ST公司,24家非ST公司)的预测样本(Prediction sam⁃ple)和确认样本(Validation sample),其中,预测样本用于模型的估计,确认样本用于评估模型的有效性。
(二)自变量的筛选
1.初步选择
(1)自变量初选。按照信用评级理论,反映企业财务风险的指标应包括宏观、中观、微观分析三个方面。房地产业受国家政策调控影响非常明显,在宏观方面,它受税收政策、货币政策、土地政策、经济周期、房产政策、外汇政策(外汇汇率预期升值会吸引外资进入投资房地产业)、居民收入可支配收入的影响。在中观方面,反映房地产行业景气度的主要指标为:土地购置面积、房地产开发投资额、商品销售面积、商品房销售总额、商品房平均价格、从业人数。在微观方面,包括反映企业运营能力、偿债能力、变现能力、成长能力和盈利能力的财务指标。另外,规模、股权结构也影响房地产企业的财务风险。
根据以上分析,按可获得性,初步选取了以下指标:净资产收益率(X1)、资产报酬率(X2)、资产净利率(X3)、销售净利率(X4)、销售期间费用率(X5)、销售费用率(X6)、管理费用率(X7)、财务费用率(X8)、流动比率(X9)、速动比率(X10)、超速动比率(X11)、营业收入增长率(X12)、利息保障倍数(X13)、净利润增长率(X14)、总资产增长率(X15)、营业周期(X16)、存货周转率(X17)、应收账款周转率(X18)、流动资产周转率(X19)、总资产周转率(X20)、自由现金流量(X21)、资产负债率(X22)、流动资产/总资产(X23)、经营活动净收益/利润总额(X24)、所得税/利润总额(X25)、股东权益相对年初增长率(X26)、资产总计相对年初增长率(X27)、资产规模(=log(总资产/GNP价格水平指数))(X28)、Z指数(第1大股东持股比例/第2大股东持股比例。该指数越大,股东力量的差异越大。)(X29)、GNP增长率(X30)、国房景气指数(X31)、房地产市场价格指数(X32)、人民币对美元汇率(X33)、中长期贷款利率(X34),共计34个指标。
(2)财务预警模型的选择。利用SPSS18.0的非参数检验中的单样本K-S检验,对上述34个自变量的数据进行正态性检验,结果表明除X15、X19、X20、X23、X27、X28服从正态分布外,其他财务指标的数据均不服从正态分布,因此本文未选择要求数据分布为正态分布的模型,比如判别分析法。根据以往参考文献的研究结果,Logistic模型是目前运用较为成功的财务预警模型,且对样本数据没有正态分布要求,因此模型选取如下形式的Logistic回归模型:
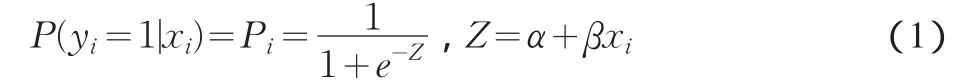
其中,Pi为第i个案例发生的概率;xi为自变量;α为截距项,β为回归参数。
模型(1)的左端为公司被ST的概率,因变量P对于ST公司取值为1,正常公司取值为0,自变量的选取为下面最终筛选的变量。
2.第一步筛选
初选变量能够进入模型的标准是它们是否有能力区分正常公司和ST公司,借鉴Beaver(1966)所用的剖面分析方法,运用统计手段,我们可以检验同一自变量在ST公司和非ST公司中的分布是否存在显著性差异,如果分布不存在显著性差异,证明这一指标对判断公司是否被ST没有作用,要予以剔除,反之要保留。通常我们可以用t检验(目的是检验两组不相关的样本是否来自具有相同均值的总体)达到这一目的,但t检验使用的前提是样本服从正态分布,本文上一小节的研究结果表明,财务指标大多不服从正态分布,因此应用非参数检验来进行筛选。运用SPSS18.0的非参数检验中的两个独立样本的四种方法(即Mann-Whitney U、Kolmogo⁃rov-Smirnov Z、 Moses Extreme Reactions和Wald Wolfowitz Runs)进行检验,结果表明销售费用率(X6)、速动比率(X10)、超速动比率(X11)、营业周期(X16)、存货周转率(X17)、流动资产周转率(X19)、总资产周转率(X20)、自由现金流量(X21)、流动资产/总资产(X23)、经营活动净收益/利润总额(X24)、所得税/利润总额(X25)这11个财务指标的渐近显著性均大于0.05,表示这些指标在两类公司中的分布有大于95%的概率是相同的,予以删除。X22、X28、X29、X30、X31、X32、X33、X34这几个变量的渐近显著性也大于0.05,但鉴于在理论分析中,资产负债率、宏观经济变量是影响房地产企业是否违约的重要因素,因此将这些变量予以保留。
3.第二步筛选
应用Logistic回归方法时,通常通过拟合单变量Logistic回归模型来取得变量的显著性检验,因为如果一个自变量与因变量之间有较强的相关关系,在做单变量回归时一定能够体现出来,即获得有效的参数估计和较高的预测准确率[10]。本文对剩余的所有变量进行单变量Logistic回归,结果见表1所列。
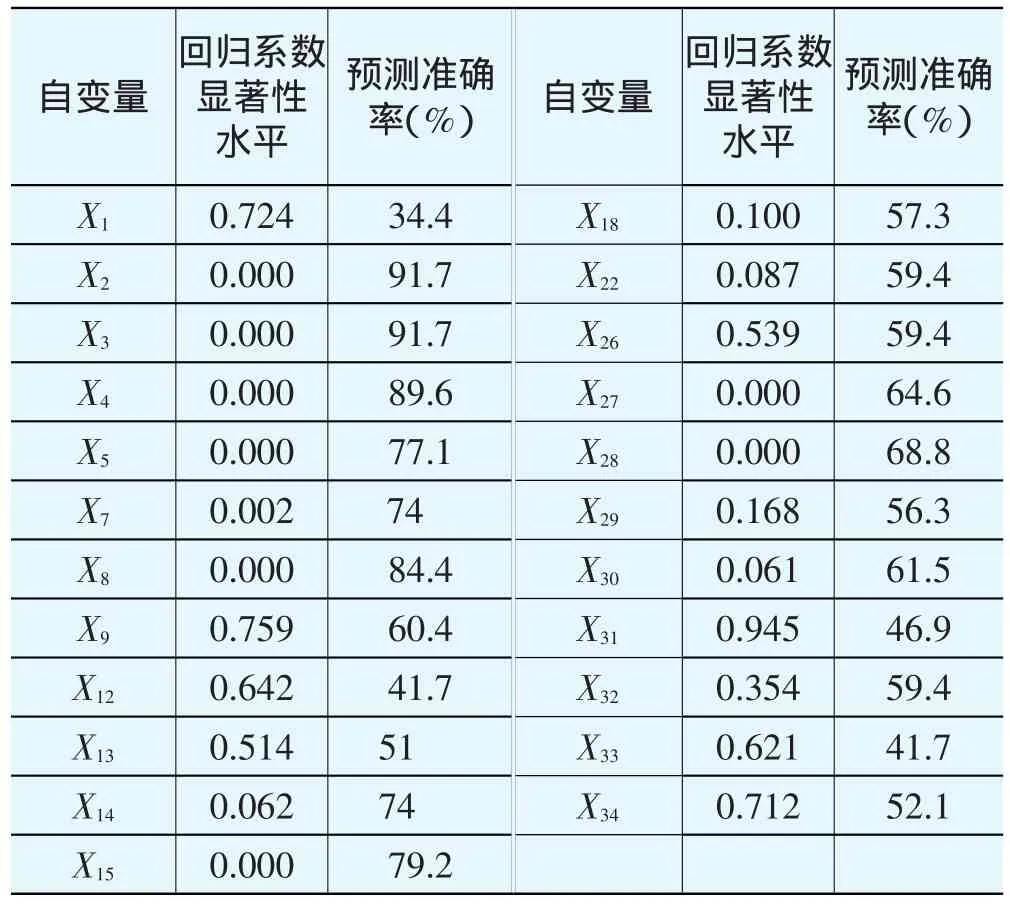
表1 单变量Logistic回归结果
表1中回归系数的显著性水平越小表明系数估值越有效,通常在单变量Logistic回归的变量筛选中,显著性水平<0.25者,都应该考虑与其他重要变量一起作为多元模型的候选变量。同时,一个变量的预测准确率越高,说明这一变量越重要[10]。根据这些原则,可以看到,净资产收益率(X1)、流动比率(X9)、营业收入增长率(X12)、利息保障倍数(X13)、股东权益相对年初增长率(X26)、Z指数(X29)、国房景气指数(X31)、房地产市场价格指数(X32)、人民币对美元汇率(X33)、中长期贷款利率(X34)应被删除,不予考虑进入回归模型。同上小节一样,考虑到宏观经济变量和Z指数的理论意义,予以保留,删掉X1、X9、X12、X13、X26五个财务指标变量。
4.第三步筛选
对剩余的18个变量再进行筛选的方法是相关分析,自变量间皮尔逊(Pearson)相关系数如表2所示。
由于一些自变量含有相同的信息,因此具有较高的相关性,直接进行回归势必会引起多重共线性,本文考虑用因子分析来解决这一问题,因子分析要求自变量间要具有一定高的相关性,否则就没有因子分析的必要,但资料表明,如果自变量的相关性极高,比如为1,即使经过因子分析,也不能保证得到的新因子间相关性为0,同样会有多重共线性的问题。由表2可以看出,X5与X7的相关系数为0.999,如果两个相关系数同时被选入自变量,即使经过因子分析,也不能减少多重共线性的影响,从而使得回归结果不显著。因此,综合考虑上一小节两变量对因变量的影响程度,删去X7。
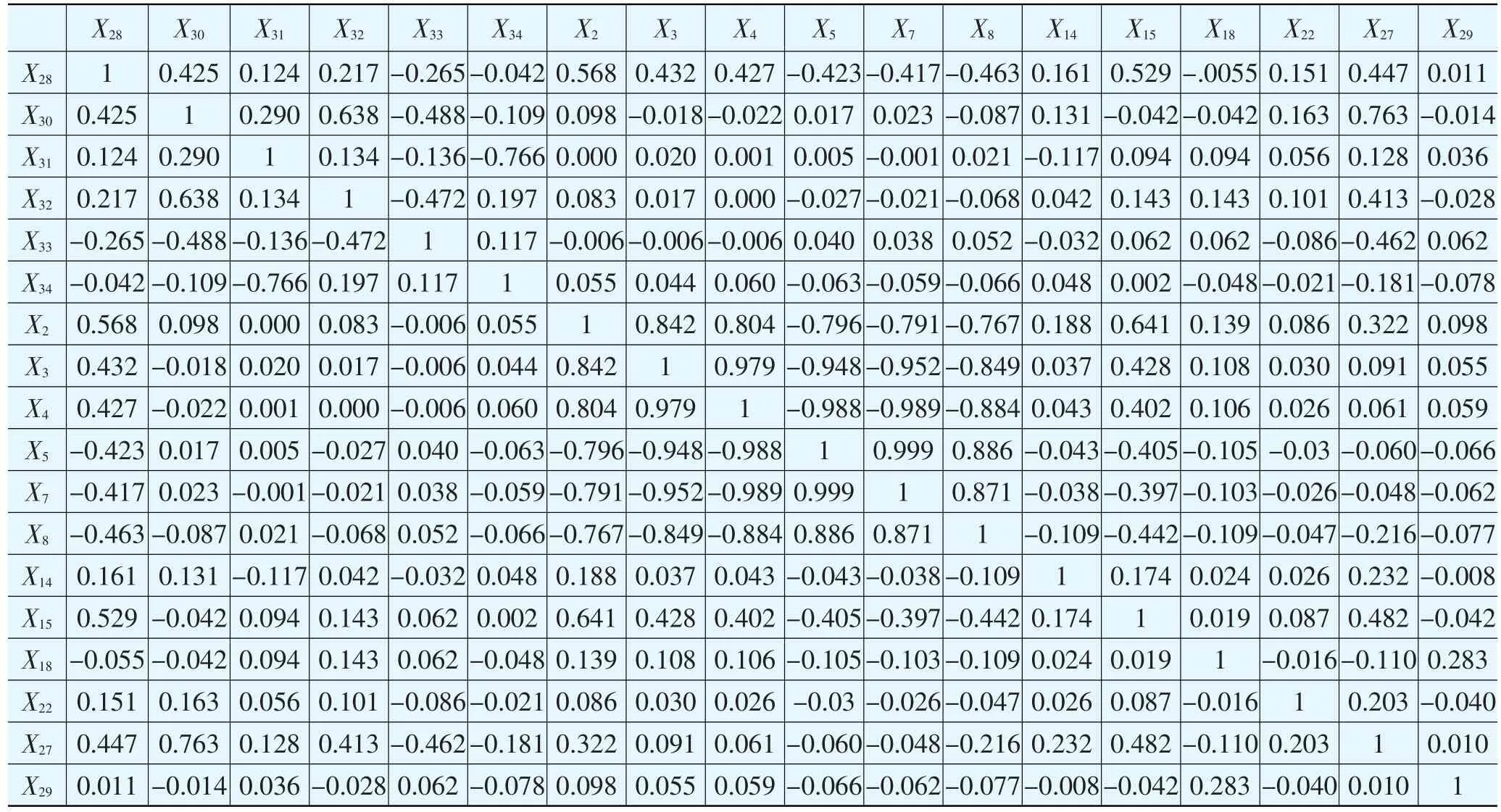
表2 自变量间皮尔逊相关系数
至此,共筛选得10个财务指标变量,分别为:X2、X3、X4、X5、X8、X14、X15、X18、X22、X27,和一个规模变量 X28。同样鉴于理论原因,所有宏观变量和Z指标仍予以保留。
(三)模型比较
分析表2,发现X28(规模)这一变量与入选财务指标有较强的相关关系,Z指数与其他变量相关关系较弱,各宏观经济变量之间相关关系较强,但与财务指标相关关系较弱。基于这些分析,本文拟建立三个模型:
模型一:包括X28和所有的财务指标;
模型二:在模型一基础上加入宏观经济变量;
模型三:在模型二基础上再加入Z指数,
以方便比较哪些变量对房地产公司财务预警最有效。
1.模型一
(1)因子分析。直接用X28与财务指标变量进行回归存在的最大问题是多重共线性,如表2所示,这些指标彼此相关性很高,如直接进行回归不能保证回归系数为无偏估计,因此首先要进行因子分析,通过因子分析,形成新的变量,这些新的变量之间能保证不相关。另外,因子分析的最大好处是降维,使回归的变量减少。本文将10个财务指标与X28共11个自变量进行了因子分析,采用的是主成份分析法,并且为了使得所获因子更易解释,采用了最大方差正交旋转,提取公因子后,再用这些公因子进行回归。
因子分析结果的KMO数据为0.757,Bartlett球形检验近似卡方为643.501,显著性水平为0.000<0.05,表明这些数据适合做因子分析。共提取5个主成份,解释的总方差为91.283%,经过旋转后5个主成份的组成如表3所示。
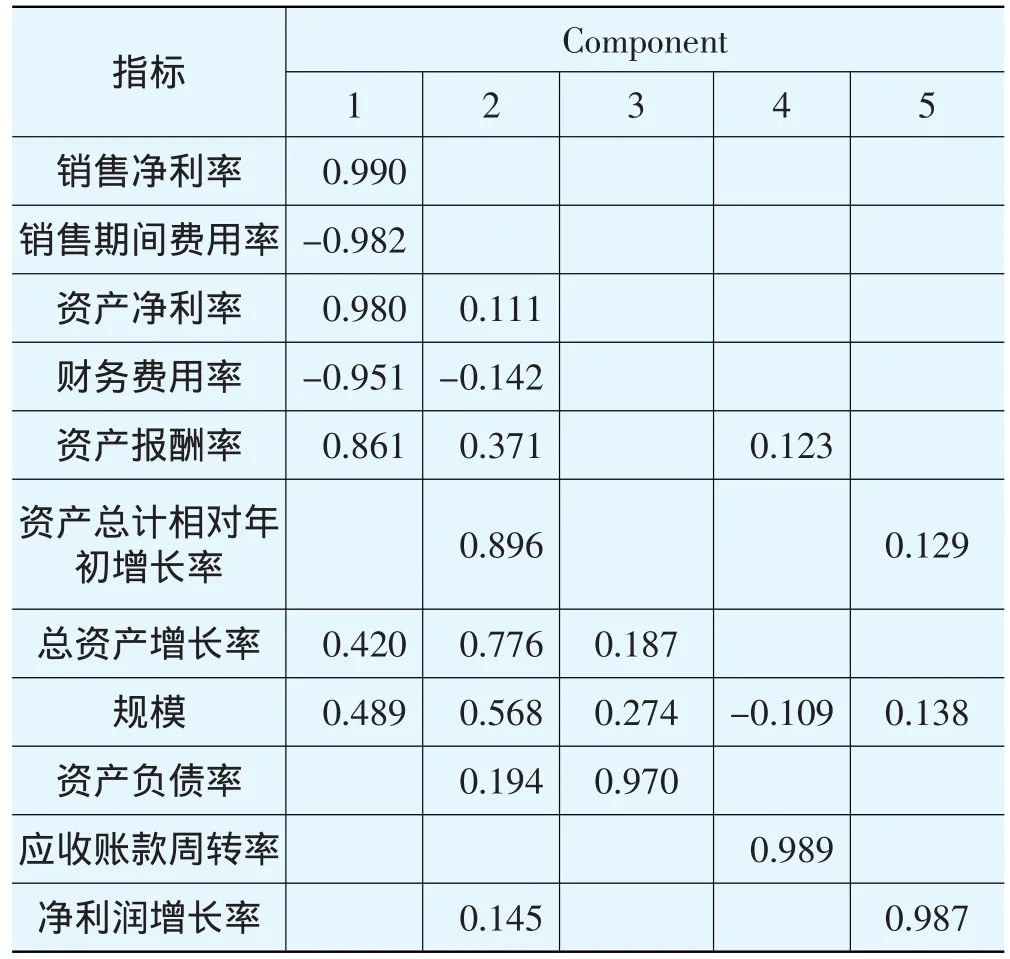
表3 Rotated Component Matrix
由表3可以看出,第一主成份主要反映了企业的盈利能力,第二主成份反映了企业的成长能力和规模,第三主成份反映了企业的资本结构,第四主成份反映了企业的营运能力,第五主成份反应了企业的成长能力。各主成份系数矩阵如表4所示。
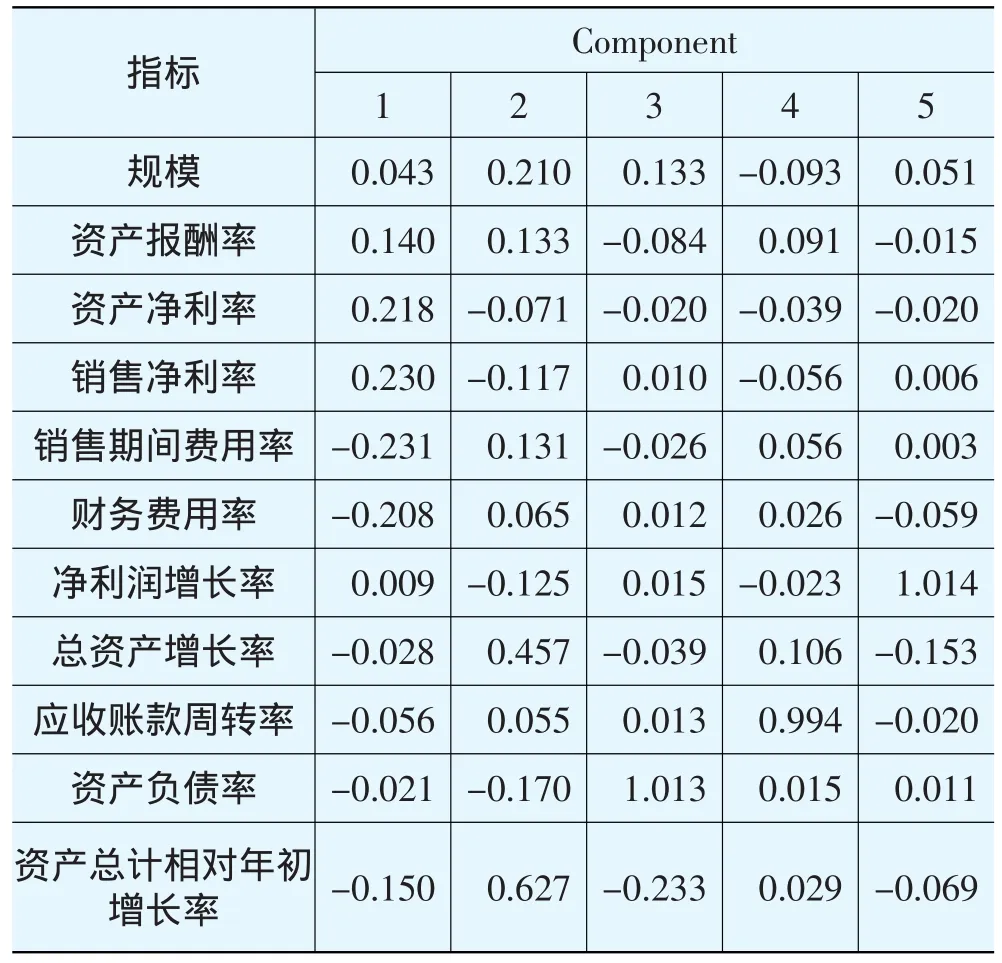
表4 系数得分矩阵
(2)Logistic回归。对主成份进行回归的方法为向后步进(似然比)法,结果如表5—8所示。

表5 拟合优度检验

表6 Hosmer and Lemeshow Test
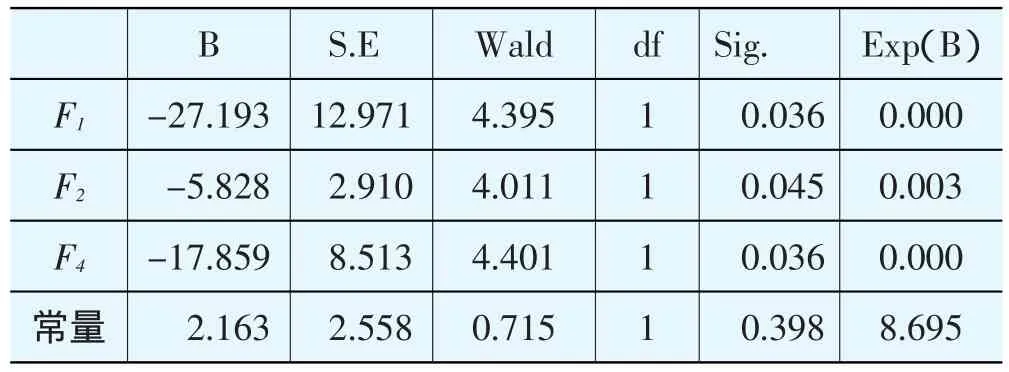
表7 回归参数表
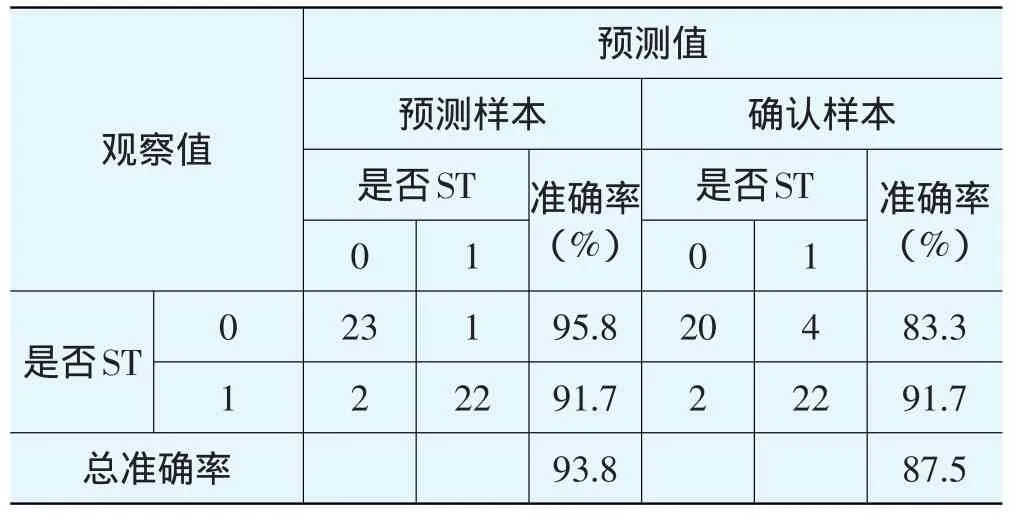
表8 分类表
表5是三个拟合优度指标,-2LL类似于线性回归中的误差平方和,值越小表明模型拟合程度越好,本模型为14.172,后面是两个类拟合优度指标,类似于线性回归中的R2,所得值越大表明拟合越好,本模型分别为66.4%和88.6%,说明本模型拟合很好。
表6是H-L检验,它也是一个拟合优度指标,反映的是模型预测值与实际观测值的拟合程度,Chi-square检验不显著表示模型拟合数据,相反,Chi-square检验统计显著表示拟合不好,本模型Chi-square检验显著性水平为0.965,不显著,说明该模型拟合很好。
表7为模型回归参数,各参数的统计结果显著,说明参数有效。
表8是分类表,它是将观测案例分为事件发生或不发生的频数表,也可以用来检验Logistic回归模型的预测准确性,模型一对预测样本的预测准确率为93.8%,对确认样本的预测准确率为87.5%。将总样本分为预测样本和确认样本进行预测的目的是得到一个无偏的预测准确率,因为同一套数据被用来拟合模型并进行预测得到的预测准确率常常是有偏的。
2.模型二
将模型一得到的5个主成份与所有宏观经济变量进行向后步进的二元Logistic回归,得到的结果为:分类表显示对预测样本的预测准确率为100%,对确认样本的预测准确率为87.5%,但无论将任一宏观经济变量加入模型中,回归参数的显著性水平值都很高,说明该参数没有通过假设为0的检验,证明回归结果是有偏估计,而HL检验的显著性水平为1,χ2值为0,表明这一检验是失效的。总体表明,模型二是不可接受的,不能用来进行财务预警。
3.模型三
将模型一得到的5个主成份再加上Z指标一个变量进行向后步进的二元Logistic回归,得到的结果为:分类表显示对预测样本的预测准确率为100%,对确认样本的预测准确率为81.3%,但同模型二一样,回归参数的结果为有偏估计,HL值异常,表明模型三也是不可接受的。
综上比较三个模型,选择将模型一作为最终确认的财务预警模型。
(四)预测
从表7得到的Logistic回归结果见式(2)。
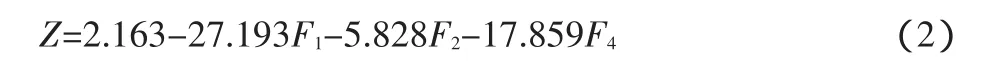
将表4中的系数得分结果代入(2)式,再根据Logistic回归模型的公式(1),可以计算出公司的违约概率。在文献资料中,研究者通常用0.5做为最佳判定点,即P>0.5预测公司会在一年后违约,P<0.5则预测公司在一年后不违约,本模型采用的样本中ST公司与正常公司的自然比例是1∶1,即有50%的概率是ST公司,因此用0.5做最佳判定点是合适的。用这一模型对样本公司ST发生前两年、前三年、前四年标准化后的财务数据进行返回预测,准确率如表9所示。

表9 样本公司ST发生前两年、前三年、前四年模型预测准确率
在统计中有两类错误,第一类错误为弃真错误,在财务预警中指将会发生信贷违约的企业判断为好企业,第二类错误为纳伪错误,在财务预警中指将不会发生信贷违约的企业判断为坏企业,这两类错误的发生率是判断一个模型是否有效的标准。对商业银行来讲,第一类错误损失更为巨大,因为将资金贷给一个会违约的企业遭受的经济损失远远大于不贷给一个正常还款公司所带来的经济损失。从表8和表9可以算出,模型对公司ST发生前一年、前两年、前三年、前四年预测结果的第一类错误率分别为8.3%、10.4%、16.3%、24.5%,表明随着时间向前追溯,这一模型对ST企业的预测准确率逐步下降,但总体来看,这一模型预测准确性较高且具有一定的稳定性,说明这一模型是有效的。值得注意的是,两类企业的预测准确率下降速度并不一样,对ST企业预测准确率下降速度较慢,有较好的稳定性,但对非ST企业的预测准确率则下滑辐度较大,说明模型对ST企业的识别能力强于对非ST企业的识别。
三、结 论
本文利用96家房地产上市公司1998—2010年的年度财务数据及宏观经济变量,应用统计方法对34个自变量进行了逐步筛选,用筛选出的自变量构建了三个财务预警模型,经过分析比较,最终得到了一个预警效果较好的财务预警模型,对这一模型的分析结果表明:
(1)模型一的结果表明,只有第一、第二和第四主成份最终进入了模型,说明在房地产企业财务预警中,房地产企业的盈利能力、成长能力、营运能力是最重要的,特别是房地产企业的盈利能力是区分好坏公司的关键因素,其中资产报酬率、资产净利率两个指标最为重要,单个指标的预测能力就能达到91.6%。但代表房地产企业资本结构的指标资产负债率未能进入模型,说明这一指标对区分一个房地产公司是否有财务危机的能力不显著,换句话说,房地产企业都有较高的资产负债率,这一共性特点使其不具有判别好坏公司的能力。
(2)在房地产企业财务预警中,规模这一指标与其他财务指标相关度很高,且对提高预测能力效果显著,说明在房地产企业中,规模大的公司财务危机的可能性要小得多,这一结果与实际情况是相符的。
(3)模型三表明,反应股权集中度的Z指标对提高模型预测准确性的效果不显著,说明大股东存在与否对判断一个房地产企业是否有财务危机没有影响。
(4)本文从筛选自变量到模型的比较都表明,在房地产企业财务预警中,宏观经济变量并不是一定要加入的变量。这与自Beaver和Altman以来许多研究者只采用财务指标的结果是一致的。本文认为可能的原因有两个,一是宏观经济变量对房地产公司的影响已体现在财务数据当中,二是因为本文建模的样本较少,导致宏观经济变量影响不显著,这是未来需进一步研究的方向。
(5)模型预测准确性较高,可以为银行、投资者、监管者和房地产企业自身的风险管理提供一定的参考。
[1]Beaver William H.Financial ratios as predictors of failure[J].Journalof Accounting Research,1966,4:71-111.
[2]Altman Edward I.Financial ratios,discriminant analysis and the prediction of corporate bankruptcy[J].Journalof Finance,1968,23:589-609.
[3]Ohlson James A.Financial ratios and the probabilistic predic⁃tion ofbankruptcy[J].Journalof Accounting Research,1980,18:109-131.
[4]Barniv R.Accounting procedures,market data,cash flow fig⁃uresand insolvency classification:the caseof the insurance in⁃dustry[J].The Accounting Review,1990,65:578-604.
[5]陈静.上市公司财务恶化预测的实证分析[J].会计研究,1999,(4):34-40.
[6]吴世农,卢贤义.我国上市公司财务困境的预测模型研究[J].经济研究,2001,(6):46-55.
[7]廖剑.房地产上市公司财务预警实证分析[D].广州:暨南大学,2008.
[8]肖冰,李春红.基于Logistic模型的房地产行业信用风险研究[J].技术经济,2010,(3):65-68.
[9]孙晓琳,秦学志,周颖颖.基于混合Logistic模型的房地产公司信用风险预测研究[J].现代管理科学,2010,(2):20-22.
[10]王济川,郭志刚.Logistic回归模型——方法与应用[M].北京:高等教育出版社,2001:65-72,145-152.
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
今日农业(2019年12期)2019-08-13 00:50:02
现代营销(创富信息版)(2018年8期)2018-09-08 08:51:58
中国交通信息化(2018年5期)2018-08-21 03:37:40
现代园艺(2017年22期)2018-01-19 05:07:01
中国财政年鉴(2017年0期)2017-07-04 08:49:18
中国财政年鉴(2016年0期)2016-06-05 15:23:31
火控雷达技术(2016年3期)2016-02-06 02:30:27
