
人文社会科学学术成果跨界影响力研究
2012-02-01 07:58袁卫
中国人民大学学报 2012年4期
王 星 袁卫
一、学术成果跨界影响力的研究背景
近年来,我国人文社会科学研究发展迅猛,学术成果激增,社会影响不断扩大。人文社会科学学术成果对社会的发展具有十分重要的意义。在学术成果的评价方面,刘大椿指出,目前对人文社会科学成果的复杂性研究不够和对成果评价指标的非单一性认识不够,已有评价方法存在很多局限,对本土化规律的揭示不够。[1]跨学科、跨机构、跨领域等学术合作催生出大量面向重大现实问题的新理论、新思想和新方法,这些新知识借助文献网络平台迅速传播,共同编织出一幅巨大的学术成果跨界影响网络图。所谓学术成果的跨界影响力,主要是指由学术成果所产生的某一领域对其他领域的影响程度,统称为跨界影响力,主要反映学术影响广度。跨界影响力的研究目标是揭示蕴藏于文献之中的跨界影响规律,并基于所发现的状态规律,分析形成跨界辐射的差异。探索这一课题将为充实和发展人文社会科学成果评价体系提供新思路,为科研管理、学科建设和学术评审提供决策参考。[2]
选择从文献的角度探索学术合作规律和分析跨界影响的首要问题是从怎样的数据出发研究跨界影响。学术影响力评价研究中的数据产生方法主要有两类:第一类是直接测量法,即设计评价指标,收集同行专家意见,形成学术成果影响力评价得分,指标体系设计的数据来自现成的数据。代表性的方法如同行评议法,它是期刊选文和学位论文审核中较为常见的一种反映学术成果影响力的方法。然而将同行评议法直接用于跨界影响评价存在着困难:一是跨界评审专家需要精通各个领域,跨行专家遴选很困难;二是得到的数据主观性强,成本高,可比性差。[3]第二类方法是客观估计法,这种方法以关系估计为核心,测量数据并非现成的,而是在大量微观的客观数据基础上估计产生的。代表性的研究如国际上著名的SCI、SSCI以及南京大学的CSSCI核心期刊评价方法。[4]这些方法都是以引文数据为基础,从文献间的引证关系出发设计的期刊影响力评价方法。然而,引证关系在揭示中文跨界学术影响方面存在时间滞后、自引比例较大、跨学科指向不明和数据规模小等局限性。[5]来自科学网有关引文数据规模的报告显示,根据引用率进行的热点论文统计中,2010年美国热点论文数最多,为1 070篇;截至2011年11月,中国热点论文数仅为196篇,占国际学术热点论文数的9.9%。[6]学术热点常常是理论与现实的结合点,是领域交叉的重要成果,热点不足暴露出引文数据作为反映时代客观问题方面的设计不足,仅依赖引证关系将低估广大哲学社会科学工作者的跨界实践研究。目前关于学术专业深度的研究与评价较多,但对学术交叉广度的跨界影响研究较少,2010年基于引文的学术影响力因子中扩充了文献对其他学科影响广度和时间跨度的评价内容,这一变化反映出学术界对跨学科和跨时间评价的广泛需求。[7]
综上所述,直接测量或仅使用引证关系而试图揭示人文社会科学学术合作规律,很难把握人文社会科学学术思潮的相互作用、相互影响等客观规律,也不足以反映不同学科、不同群体的学术交流活动的差异性。本文从更易实现且可建立更为客观、更具实时性和预见性的读者文献搜索数据入手,探讨跨界关系矩阵的估计与算法建模问题。
二、文献的跨界影响研究数据基础
我们从现代科学交流模式的变化和科学家文献交流特点入手,来探讨文献的跨界学术影响力的数据构成和定义。
(一)现代网络文献交流关系是研究跨界影响力的数据基础
美国社会学家罗伯特·默顿1985年在《科学的规范结构》中提出了学术成果作用的定义,指出其价值是在科学家之间起着根本的交流作用。这个定义强调了交流能力对衡量学术成果价值的基础性作用。文献的跨界影响力研究的本质是要在知识传播的微观结构下,发现科学家通过所选文献而产生的不同领域交流方面的差异,进而揭示知识传播的微观结构在连接不同领域之间彼此影响中的积极作用。
从交流关系看,基于引文关系的学术影响力因子是从知识创作和信息加工交流关系出发所建立的学术成果评价理论的代表,它反映了较大时间跨度上作者与作者之间的交流关系,表达了知识的继承性与持续性交流信息,反映了知识纵向交流特征,是利用知识传承关系衡量知识创造力的客观工具。然而,文献的横向交流作为科学研究成果的影响作用不容忽视。横向交流可以反映协作性和竞争性。建立在引文基础上的学术影响力因子在反映横向交流能力方面存在两个基本的不足:一是引文网主要反映作者与作者通过最终成果所建立起来的交流,很难体现同时期作者与读者之间的交流关系;二是引文关系更注重反映文献对新成果的结果影响,但对文献的社会化影响效果反映不充分。在横向跨学科影响上,塔佳(Talja)、瓦卡瑞(Vakkari)、弗莱(Fry)和沃特斯(Wouters)指出跨学科性与一个领域的科学家使用其他学科的文献有关,科学家对文献的选择行为可用于度量学科之间联系的程度。[8]从文献的影响效果来看,跨界影响强调作品的影响应贯穿于对其他学者的研究过程中,这个过程包含由学者选择作品所建立的文献对研究者的提供、传递、获取和利用行为数据。基于以上分析,使用学者下载文献行为数据作为研究跨界影响力的基础数据是合适的。
事实上,20世纪80年代之后,网络和数字文献革命对传统文献交流模式产生巨大冲击。陈雅和郑建明指出,专业知识的演进规律和更新模式已不再是现代文献交流的主要模式,知识如何通过载体流通所得到的交流规律和模式越来越受到重视,特别是网络文献交流模式。[9]文献交流模式内容的变化突出了文献在沟通学术交流中的提供、传递、获取和利用价值,也使其成为测量学术跨界影响力的重要渠道。通过知识库的网络交流数据,不仅可以体现作者之间的交流,而且可以反映作者与读者之间的交流。网络文献交流对于学术的跨界影响所起的作用是通过改善接收者的知识结构,形成接收者新的思考或对事物的态度和行为,从而影响到学者所属学科对学术方向的把握、科研机构对学术合作伙伴的选择。由于在交流过程中接收者充当了对知识认可信息的发送者,通过文献的交流形成了人与人之间双向的知识交换,由此带来不同机构或学科之间的相互渗透。这种建立在学者与学者之间通过文献所发生的学术交流所引起的宏观层面不同学界的互相影响原理如图1所示:
在图1中,学者1通过阅读学科文献B实现了跨学科学术需求的一致性,学者1与学者2通过阅读文献B实现了学科和机构学术需求的一致性,一旦这种一致性在统计规模上实现了显著性,这一微观数据可用于度量跨界影响关系。
从跨学科交流关系的估计样本选择来看,把握理性读者的可长期跟踪交流关系是产生可靠估计的关键。理性读者有两项基本假设:第一,可表示性:理性读者研究兴趣由其文献选择来表示,即理性读者的选文模式能够体现其学术旨趣;第二,抗干扰性:理性读者应满足时间稀缺性质,即理性读者不会浪费时间大量下载与自己研究不相关的文献,因而其选择的文献中不属于其学术兴趣的杂质非常少。一些利用大型的公开网如Google、Baidu等搜索引擎的读者,虽然浏览页面数量很大,但读者身份较为庞杂,浏览信息过于繁杂,精准度不高,很难满足这两点基本要求,在反映读者学术旨趣方面具有较大的随意性,不易形成稳定的结论。直接使用期刊网的用户则不能保证人文社会科学读者的代表性。为获得充足的有代表性的样本,我们认为应以人文社会科学读者群为对象,将其对中文知识网的中文信息搜索作为基础数据,这样,既反映了群体的学术旨趣,又可获得长期跟踪和验证结果的实验环境。
综上所述,以科学家学术主旨为引导获取文献的交流数据提供了形成知识横向传递和利用的微观结构,以网络文献搜索行为数据为基础建立跨界影响是可行的。
(二)学术成果跨界影响力要素构成
学术成果跨界影响力研究的关键是掌握跨界合作规律和一个学科对其他学科的辐射差异。从科学学的历史和发展现状来看,科研机构和学科是学术发展的基本要素,科研机构是学术活动的基本单位,学科规定了学术共同体活动的范畴与边界,学术成果则构成了学术共同体的实践和理论,学术成果的跨机构和跨学科规律是跨界影响力的主要内容。[10]科学家是科学交流的主体并最终决定跨界影响,而且也是学科评价服务的最终用户。于是,建立在以学者研究行为为基础的学术共同体和学术机构群体科学交流活动不仅为跨界研究提供基础,而且基于文献下载数据所获得的跨界交流模式将有利于为学者研究提供更好的服务。从文献来看,学者的研究身份主要是两个:一是作为成果的创作者,二是作为预备新成果的读者。传统的引文分析主要强调作者身份,而忽略读者身份。事实上,读者是创作中的主要身份,贯穿研究全程,它能够记录更广泛的学术交流线索,通过学者对文献的选择行为可以帮助机构选择期刊,引导读者阅读文献,指导作者针对自己的研究成果进行投稿。
跨机构影响研究主要考虑跨机构合作行为,目标是对机构合作建模和对合作结构的估计。跨科研机构研究合作网络可由科研机构学者的合作网络数据生成,跨学科关系网络由科研机构学者的合作网络估计生成。一般来说,跨机构发表的成果越多,越能说明这种跨界合作在学术领域中产生的影响力。对跨学科的研究主要考虑两种对话行为:使用文献和创作文献。一个领域的研究人员使用其他学科文献的程度可以用来衡量一个学科的跨学科性,跨学科创作关系定义为不同学科作者之间的合作关系;跨学科使用文献影响则主要针对由读者和作者针对共同的文本所产生的对话与共鸣所引起的。其中作品的学科归属比较容易定义,但是读者的学科归属则受学术旨趣影响常常发生变化,需要基于读者的学术旨趣分布定位获得跨学科的影响强度。我们将着重给出基于共读文献的跨学科影响,即一学科的文献被另一个学科的学者阅读,以及文献被两个不同学科学者阅读所产生的学术交流影响。
三、跨界影响力关系估计模型
跨界影响力关系估计模型主要解决两个问题:一是关系的识别,二是关系结构的分布。目前的算法主要分为两大类:一类是基于矩阵分解的模块发现算法,典型的方法如模块社群挖掘法(Block Models Community)[11]、连通社群挖掘法(Link Community)[12],这些算法的前提是关系定义清楚,算法主要解决关系的模块分布,其优点表现为可与并行计算结合,运算快,不必事先确定群个数,有较好的理解性,能处理大型网络数据等,适用于互连结构的发现;另一类是将关系的识别与结构的模块分布结合起来的方法,如社群提取算法(Community Extraction)[13],适用于稀疏结构的发现。在跨界问题研究中,跨学科的问题数量中等,可以采用二步图和第一类方法结合的方法;跨机构合作关系数量大,需要同时解决关系发现与结构发现算法,比较适合用第二类方法来解决。下面是几类模型和它们在跨界研究中的应用。
(一)基于社群挖掘的跨界影响力模块分割模型
社群挖掘算法是近年来发展较快的一种对关系分块的算法,多用于社群发现。其中较为典型的方法是2004年纽曼(Newman)提出的模块Q方法,Q方法的基本原理是使用模块划分评分函数实现最大化网络模块划分。其中Q的表达式如下:
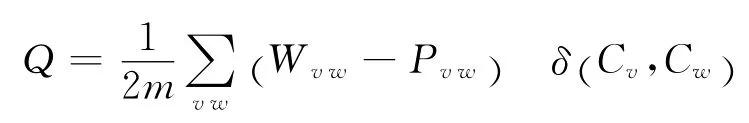
式中Wvw表示实际图顶点v和w之间的边数(在加权图,为边的权重),Pvw表示随机图模型中顶点v和w之间期望的边数;m是总边数(在加权图中,为权重之和),常数项1/2m是归一化常数;如果社群Cv=Cw(即顶点v和w属于同一个社群),示性函数δ(Cv,Cw)=1,否则为0。Q定义了实际图社群边连通密度相对于随机图的差异,社群内边密度与随机图期望边密度相比越大,表明社群结构越明显。我们将使用Q方法估计跨机构合作关系矩阵和跨学科影响矩阵。
社群挖掘算法比较适用于模块特征突出且不同模块之间分割的社群挖掘问题。它的缺点是当模块之间的质量差别比较悬殊时,点数较小的模块容易被与之相连的点数和度较大的模块吞噬,不易在算法中被发现。[14]社群挖掘算法①社群挖掘算法需要考虑带边权重的WFN算法,我们将另文说明这些新用法。可用于跨学科和跨机构关系模块的提取。在跨学科研究中,学科合作具有规模不等和合作不平衡等特点,直接使用Q算法,将掩盖小学科的特色合作,在使用该算法时将设计基于学科规模和关系密切等因素的带权重FN算法解决。
(二)连通社群挖掘算法
连通社群挖掘算法是近几年比较流行的社群挖掘算法,与模块算法侧重于对网络节点的划分不同,它的主要特点是对边聚类,由此可以发现连接多个群之间的节点。如果将其用于跨学科研究,则可以发现不同学科群之间起着桥梁作用的学科。连通社群挖掘算法由两部分构成:
第一步:计算边的相似矩阵,然后利用分层聚类算法根据边的相似矩阵对边聚类。两条边的相似系数一般使用Jaccard系数如下:
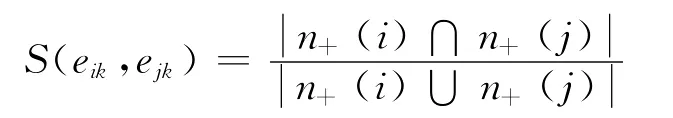
其中eik、ejk为共享同一个节点k的两个条,n+(i)表示节点i的所有邻居(全文中有关节点的邻居是指与该节点右边相连的其他节点)。S(eik,ejk)衡量的是节点i与节点j共同的邻接数占它们所有不同邻居总数的比例,比例越大,表明eik和ejk相似度越高。
第二步:连通社群挖掘算法采取用边分离密度确定社群个数并对网络聚类。分离密度D的具体定义如下:
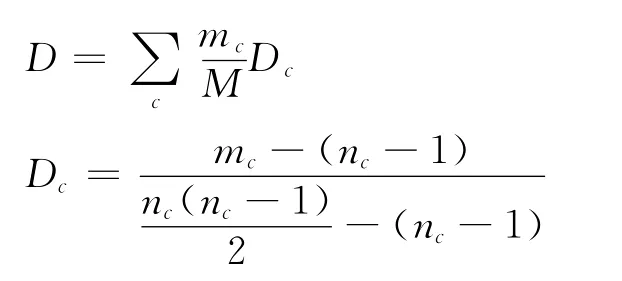
其中,mc表示第c个社群中边的个数,nc表示第c个社群中节点的个数,表示第c个社群的密度,Dc是图的边密度M—估计量。分离密度D越大,表示聚类的效果越好。该算法的优点是可以发现连通社群,并产生跨社群的连接节点,缺点是具有对稀疏结构或发散结构的排斥性。[15]
(三)社群提取算法
社群提取算法是彭捷和朱冀于2010年提出的算法,该算法试图挖掘网络中的主要结构特征,其原理是根据社群的显著性依次提取社群出来,而将剩余的节点和节点之间的关系当做“背景”看待,适用于稀疏图结构提取。假设一个无向网络图G=(V,E),节点个数为n,那么这个网络图可以用n×n的邻接矩阵A=[Aij]表示。如果Aij大于0,则表示节点i和节点j之间有边存在;若Aij=0,则表示节点i和节点j之间没有边。由于是无向图,因此矩阵A是一个对称矩阵。记所要提取的社群为S,剩下的节点集合记为SC。社群选择标准是使W值最大,W定义如下:
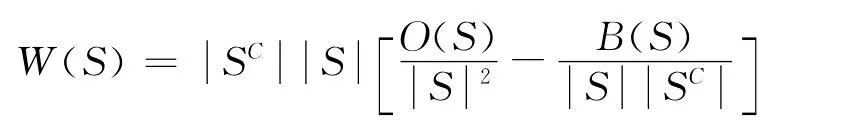
社群提取算法的原理是一个社群应该是内部节点之间的连接较稠密,与外部节点的连接稀疏,具体算法步骤如表1所示:

表1 社群提取算法主要计算步骤
该算法的优点是可以产生按模块显著性排序的社群结构,缺点是模块移除会影响到最初的连接结构,可能产生不稳定的结构。
四、实证研究
(一)跨机构合作
不同科研机构的学者因为同一研究主题合作完成学术成果而产生机构之间的互相渗透,将这样的关系从合作文献中提取出来,就形成了科研机构合作网络。
实证研究选择了1 482所大学学术科研机构作为图的节点,从文献中产生了8 018条机构合作关系,显示机构合作网络图中节点度数的分布近似幂律分布,这表明网络存在“小世界”现象,是比较典型的一类稀疏网络。
我们使用WFN-Q算法对训练数据进行了30次实验,结果比较稳定,共产生9大子群和103个机构合作小社群,节点数为2或1的小群做忽略处理(见图2)。

图2 学术机构社群结构图
仔细观察图2,9大子群中,北京地区高校处于机构合作网络的中心地位;每一个子群具有明显的星型结构,反映了20世纪90年代后国家高等教育发展的非均衡性和区域分层带动高等教育建设格局;每一子群中处于中心地位的科研机构的科研水平排在国内前列。陕西省和东北三省属于同一个群,但它们之间的地理距离相差很大。进一步分析数据表明,陕西省与东北三省的联系主要是以中国科学院为桥梁。作为中国主要自然科学研究机构的中国科学院主要与理工科类院校有很强的合作关系。中国社会科学院、中国科学院、中国人民大学、北京大学、吉林大学、清华大学、南京大学、复旦大学等科研机构在连接学术机构的合作方面起着纽带作用。
进一步分析表明,每一子群具有明显的地理区域特征,结果如图3所示:具有相同纹理的省(直辖市、自治区)属于同一个社群,灰度由深至浅表示群组的节点数量由大到小,可以看出分为9个不同的群,这正好对应着WFN算法得到的9个节点数最大的社群。星型结构中的强校纽带作用比较突出,呈现出明显的差异序社会合作模式。
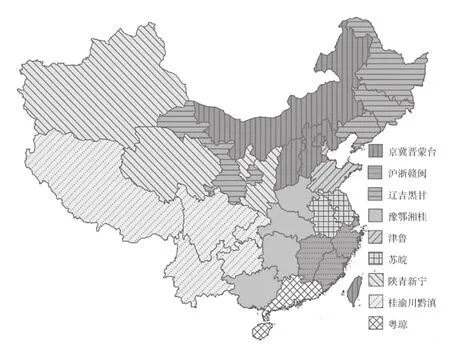
图3 WFN算法得出的社群地理分布特征
(二)学科的机构合作网络提取
学科机构合作网络提取的目标是获取一个学科与另一个学科的合作规律,这些规律包括社群的发现和连接社群之间的辐射带的发现,往往是那些集中了某些竞争力强的大学首先取得明显的发展,既而形成与多个社群的辐射、带动整个学科的发展。这种资源趋优集聚和辐射的现象,在高等教育领域比较普遍。既有比较宏观的、大规模的集聚,又有带状的社群的沟通。
下面以历史学科为例说明机构合作网络的功能。
其中相同线型的边表示属于相同的社群。饼图的节点表示它们属于不同的社群。节点越大表示相应节点的中间性值越大。
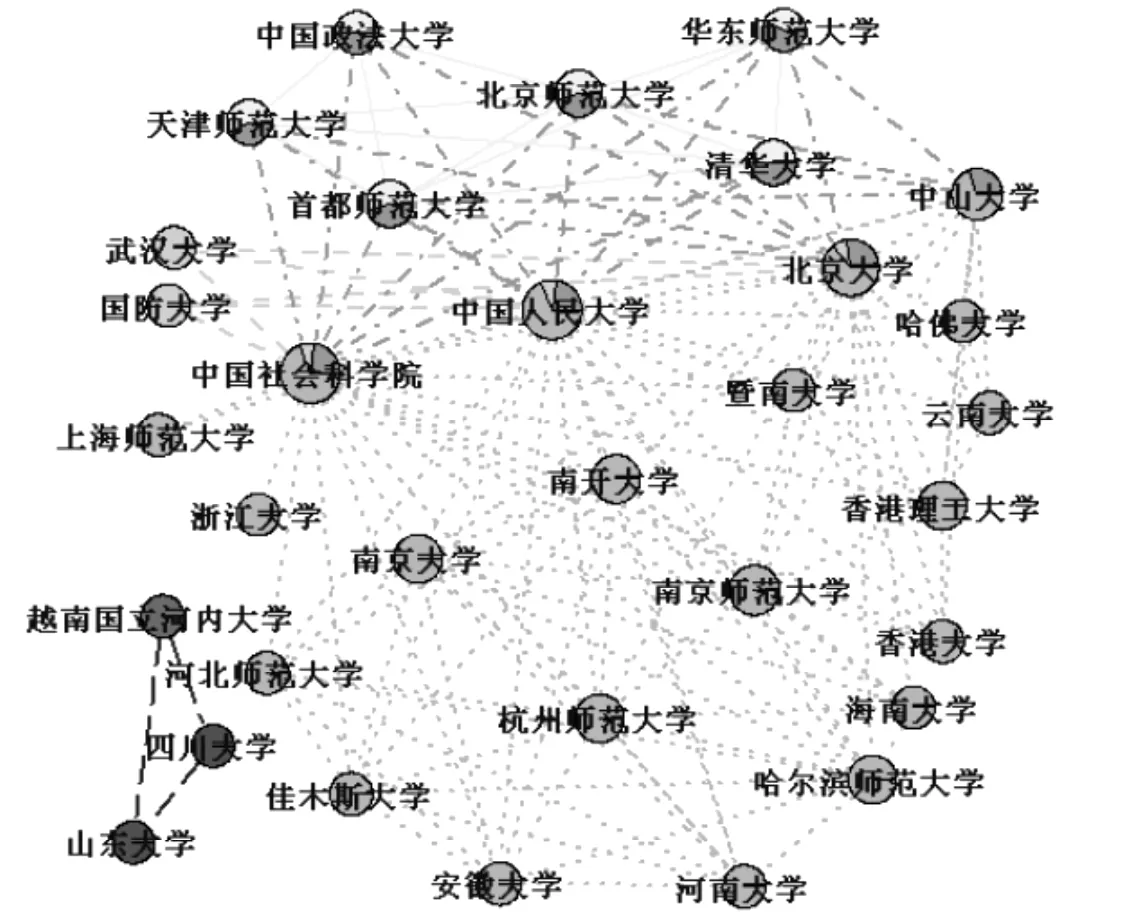
图4 历史学科机构合作网络的社群挖掘
(三)跨学科影响力案例
我们使用2011年上半年从中国知网对某大学博士生和教师相关文献的搜索数据,有效文献53 268篇,学者300位分属22个学科,文献来自37个学科。对数据做二分图转化和过滤程序后,使用社区提取方法得到共读文献的跨学科影响,文献学科网络聚类将跨学科影响关系分为4类;人文社会科学类(人文:灰色圆形类和社会科学:白色圆形类),理工类多为白色方形和灰色方形。见图5。
可以看出,人文与社会科学两类联系很紧密;计算机科学与技术在理工科类和人文社会科学类中起到关键的联系作用。

图5 文献跨学科影响社群结构图
其中最大群是社会科学及其相关学科社群,由政治学、经济学、法学、统计学、药学、社会学、公共卫生与预防医学、环境科学与工程、临床医学、体育学、大气科学、管理学、农学、测绘科学与技术、水利工程、兵器科学与技术、核科学与技术、口腔医学、石油与天然气工程、动力工程与工程热物理学科20个机构构成。经济学在这个群中连通性最强,其中跨学科最强的关系是兵法学与经济学、社会学与经济学、法学与政治学、管理学与经济学、公共卫生与预防医学-经济学、政治学与法学。
第二大群是人文学科及其相关学科社群,包括哲学、新闻传播学、戏剧与影视学、中国语言文学、历史学、外国语言文学、基础医学、其他医学、美术学、设计学、民族学、中医学、地理学、海洋科学、矿业工程、音乐与舞蹈学、艺术学理论、地质学、纺织科学与工程。其中中心学科是中国语言文学,跨学科最强的关系是哲学—中国语言文学、中国语言文学—新闻传播学、新闻传播学—哲学、历史学—中国语言文学、历史学—传播学、外国语言文学—中国语言文学。
第三大群是工程类学科组成的群,包括计算机科学与技术、信息与通信工程、食品科学与工程、系统科学、化学、机械工程、军事学、数学、生物学、化学工程与技术、其他工学、特种医学、物理学、冶金工程。其中核心学科是计算机科学与技术,跨学科最强的关系是计算机科学与数学、信息与通信工程—计算机科学、生物学—计算机科学。
第四大群是城乡规划学、建筑学、地球物理学学科组成的社群。
从跨学科文献阅读来看,自然科学向人文社会科学的渗透强于人文社会科学向自然科学的渗透,人文社会科学各门类之间的交融面上发挥连接桥梁的学科是经济学、政治学、法学、哲学、新闻学、语言文学等。
五、总结与未来研究展望
通过研究文献中的跨界评价数据和模型,从科学家网络文献交流数据出发,探讨跨界影响力关系估计问题。我们将跨界关系映射到图中的节点和节点之间的关系估计问题,综合利用模块社群挖掘算法、连通社群挖掘方法和社群提取方法,揭示了人文社会科学跨机构合作和跨学科合作的基本模式。实验从多方面验证了方法的有效性,并给出了应用于人文社会科学领域的实例和分析结果。主要结果包括跨机构影响中的星型结构和地域特点,星型结构中的强校纽带作用比较突出,呈现出明显的差序社会合作模式。跨学科影响研究中,互连结构揭示了经济学、社会学等学科对于沟通人文与社会科学,计算机科学对于沟通人文与理工科之间的桥梁关系。
基于上述讨论,我们认为文献的跨界评价方面还有如下有待研究的问题,希望对本领域的其他研究者有所启发:
第一,深入研究海量文献的跨学科识别技术。当前许多学术成果都是跨学科研究的结果,其中不仅有跨学科机构,也有跨学科的人员合作。我们仅在一级学科上进行了跨学科影响关系的探讨,如果能增强学术成果跨学科识别技术的识别,特别是基于文本和内容的学科识别技术,将有利于在跨界影响的基础上开展有效率的海量复杂文献的读者推荐应用。目前已有研究主要面向主题识别的有效性提出,着眼于如何有效判定两篇文章是否描述同一主题,但是面向学科识别效率的工作较少,因此不能落实到合理定义两篇文献的学科相似性。
第二,算法挖掘模式的深入研究。本文所提及的几个算法虽然都被证实能够发现重要的关系模式,但也遗漏了一些模式,比如连通社群挖掘算法易于发现互连结构,散射结构模式容易被忽略。改进算法以适应更广泛的需求是一个待研究的问题。
第三,加强跨学科热点文献提取模型的研究,当前对文献的提取假设数据是不发生变化的静态数据,因而可以在其上建立宏观的跨界关系等。但是对于热点问题或主题提取等问题,则需要频繁更新的复杂网络数据方法。
第四,加强学术影响力因子与跨界影响力数据的对比分析,对两种不同的数据做深入的对比研究。由于受数据收集时间所限,结论的稳定性还需要更长时间的比较与深入研究。
在我国,基于海量文献数据的跨界影响力研究刚刚起步,本文主要研究基于客观数据的跨界影响力方法。但无论是来自于客观的数据还是评分数据,都有各自的优点,只有将两者有效地结合起来,才能建立起更有价值的能经得起实践考验的文献评价体系,从而为政府决策提供更可靠的数据,为广大学者提供更便捷的学术服务。
[1]刘大椿主编:《人文社会科学研究成果评价体系研究》,北京,经济科学出版社,2009。
[2]魏巍、刘仲林:《国外跨学科评价理论新进展》,载《科学学与科学技术管理》,2011(4)。
[3]袁曦临、刘宇:《人文社会科学评价的复杂性与引文评价指标的修正》,载《图书情报工作》,2010(14)。
[4]邱均平、熊尊妍:《中国人文社会科学著者的引文分析》,载《现代情报》,2008(8)。
[5]李燕:《关于引文评价指标中的三个问题》,载《农业图书情报学刊》,2011(3)。
[6]潘锋、张笑:《2010年中国科技论文统计结果发布》,见科学网,http://news.sciencenet.cn/htmlnews/2011/12/256428.shtm。
[7]宋歌:《社会网络分析在引文评价中的应用研究》,载《图书情报工作》,2010(14)。
[8]Talja,S.,Vakkari,P.,Fry,J.&Wouters,P.“The Impact of Research Cultures on the Use of Digital Library Resources”.Journal of the American Society for Information Science and Technology,2007,58:1674–1685.
[9]陈雅、郑建明:《基于科学交流的网络文献交流模式分析》,载《情报科学》,2005(10)。
[10]谷景亮、贾培民、钟彩霞等:《科研机构创新能力综合评价应用研究》,载《医学信息学杂志》,2007(6)。
[11]Newman M.“Fast Algorithm for Detecting Community Structure in Networks”.Physical Review,2004,69(6).
[12]Yong-Yeol Ahn,James P.Bagrow,Sune Lehmann.“Link Communities Reveal Multiscale Complexity in Networks”.Nature,2010,466:761-764.
[13]Yunpeng Zhao,Elezaveta Levina,Ji Zhu.“Community Extraction for Social networks”.Proceedings of the National Acadenny of Sciences of the United States of America,2011,108(18):7321-7326.
[14]S.Fortunato,M.Barthélemy.“Resolution Limit in Community detection”.Proceedings of the National Acadenny of Sciences of the United States of America,2007,104:36-41.
[15]Ernesto Estrada.“Community Detection Based on Network Communicability”.Chaos,2011,21,016103.
[16]武书连主编:《挑大学选专业:2011高考志愿填报指南》,北京,中国统计出版社,2011。
猜你喜欢
今日农业(2022年2期)2022-06-01
科学大众·教师版(2022年6期)2022-05-23
大学(2021年2期)2021-06-11
浙江树人大学学报(人文社会科学版)(2021年2期)2021-04-15
课程教育研究(2021年21期)2021-04-14
海峡姐妹(2020年5期)2020-06-22
现代家电(2019年4期)2019-06-12
中国商界(2016年6期)2016-12-27
汽车科技(2015年1期)2015-02-28
创业家(2015年9期)2015-02-27
