
基于XML的WEB数据抽取模型研究
2012-01-11 07:03:06黄淑芹
通化师范学院学报 2012年2期
黄淑芹
(安徽财经大学 管理科学与工程学院,安徽 蚌埠 233030)
当前互联网已经成为最流行的信息发布媒体和最具潜力的资源,但目前Web上的数据大都以HTML形式出现,HTML通常是一个很难用程序手段处理的媒体.由于Web页面中的很多内容的格式编排不合理,使得现在的Web浏览器在进行HTML语法分析时非常不严谨,另外,现有的WEB数据主要目的是为了显示,用于浏览器浏览,缺乏对数据本身的描述,不含清晰的语义信息,模式也不太明确,这使得应用程序无法直接解析并利用Web上海量的信息,造成资源极大的浪费[1],如何充分应用web数据成为数据库技术研究的热点.
本文针对Web上半结构化的数据,构建一个半结构化的数据模型;然后研究一种半结构化模型抽取技术,它能自动地从现有数据中抽取半结构化模型的数据.
1 XML技术的优点
W3C开发的XML[2]是一种半结构化的数据模型,能使不同结构的数据很容易结合在一起[3],其数据内容和显示数据的格式是分离的,并且容易将XML的文档描述与关系数据库中的属性一一对应起来,实施精确地查询与模型抽取[4].XML提供了一个直接处理Web数据的通用方法,从根本上解决了Web文档和其他资源描述所面临的问题.基于XML从Web文档中抽取有用信息,以更为结构化的方式显示出来,为应用程序利用Web中的数据提供了可能.
2 基于XML的WEB数据抽取原理
从XML文档中提取信息的技术已经比较成熟,这里将信息接口和组织形式各不相同的非结构化的Web数据进行结构化处理.先将HTML转化成XHTML,然后根据抽取规则对XHTML文档进行处理,根据用户需求抽取有用信息形成XML文档.具体实现步骤如下:
①给定URL地址,获取HTML文档对象.
②使用HTML解析器解析获得的HTML文档对象,获得XHTML文档.
③根据用户需求,分析XHTML文档,构造XSL文件.
④根据XSL文件将XHTML文档映射成XML文件.
⑤将XML数据写入数据库.
在HTML向XHTML的转化过程中,借助于Tidy工具实现.Tidy[5]是一个免费使用的产品,可用于改正HTML文档中的常见错误并生成格式编排良好的XHTML文档.Tidy对文档进行数据清洗[6]后,采用基于树路径的抽取规则,用XSL确定数据内的引用点,并处理清洗过的XHTML文档,根据用户需求,抽取出信息,形成XML结构化文档.
3 基于XML的WEB数据抽取模型
3.1 基于XML的WEB数据抽取模型
基于XML的WEB数据抽取模型分成三个层次:用户接口层,数据抽取层,数据存储层.如图1所示.用户接口层负责将用户提交的查询命令提交给数据抽取层,并返回查询结果.数据抽取层完成数据的清洗、转换和抽取,将HTML文档进行规范化处理;把规范化后的HTML文档转化为XML文档,得到结构良好的数据.并将抽取结果返回用户界面或存入数据库.数据存储层保存上一层抽取的结构化数据,以结构化数据库形式进行存储.由于XML强调数据语义与元素之间的关系,因此可以很容易将XML的文档描述与关系数据库中的属性对应起来.在数据存储层建立多层次Web数据库,提供Web的多维分析与层次化视图[7].
3.2 基于XML的数据抽取的系统实现
用户界面用Java类来实现,因为Java的基本类提供了一套全面的图形用户界面类库.
数据库的连接用Java的JDBC实现,JDBC是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成.
XML文档写入数据库时,先是建立与XML文档相对应的表结构,然后把数据写入DataTable,通过sqldataadapter直接把DataTable中的数据Update到数据库.

图1 基于XML的WEB数据抽取模型
4 基于XML的WEB数据抽取的实例
4.1 获取Web页并映射成XHTML
这里以天气预报信息抽取为例.天气的变化使每天的预报信息都有所更新,及时分析和抽取各网页的天气预报信息,对做好恶劣天气防范工作、减少经济损失有重要意义.由于各个网站页面风格不同,这给用户获取信息造成不便.图2显示了2011年6月5日yahoo网站发布的蚌埠天气预报信息的屏幕快照.现在想抽取天气的温度、气压、湿度、可见度、露点、风力等信息.
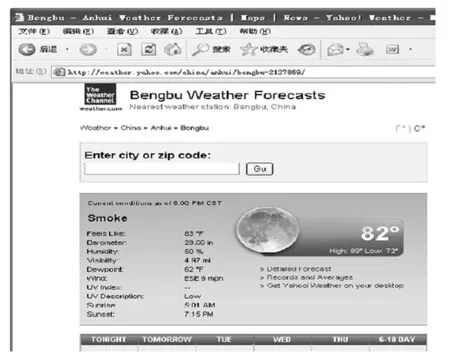
图2 Yahoo发布的蚌埠天气预报信息网页
信息的抽取通过一个Java类ParseHTMLToXML实现.抽取的第一步首先将HTML数据转换成XHTML.通过Tidy库提供的函数在ParseHTMLToXML.tidyHTML()方法中转换.tidyHTML()方法接收一个由URL指定的Web地址作为参数,并将其转化为输入流(InputStream)对象,然后利用tidy的Parse方法清洗输入流,格式化后生成XHTML文档流(OutputStream)对象.outputXMLToFile()方法用于将XHTML文档流对象输出到一个指定路径的文件中.实现HTML转换成XHTML(XML的子集)的代码如下.
public static void main(String args[]) {
try {
Document doc = ParseXHTMLToXML.tidyHTML(“http://weather.yahoo.com/china/anhui/bengbu-2127869/”);
ParseXHTMLToXML.outputXMLToFile(doc, “XML” + File.separator + “FORECASTS.xml”);
} catch (ParseXHTMLToXMLException xmle) {
... }
}
转化成XHTML文档的界面如图3所示.
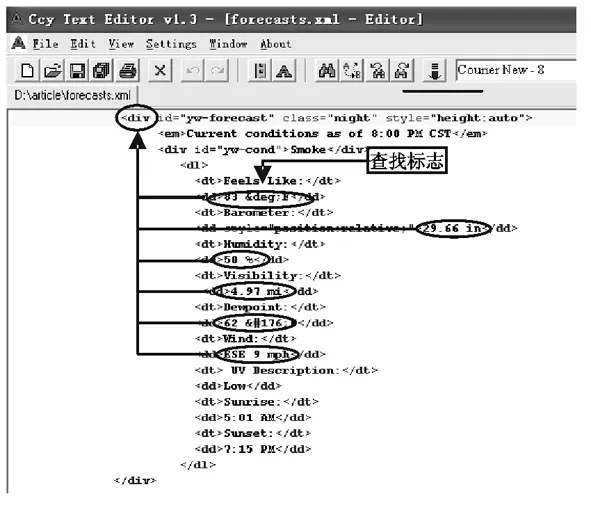
图3 文档清洗后形成XHTML的部分关键区域
4.2 查找数据内的引用点
Tidy清洗与格式化后文档中大多数信息依然与最终数据表现形式无关,因此需要在XML文档中找出特定区域,从该区域中抽取数据,而无需过多关心其他冗余数据[8].根据XHTML文档可以知道要抽取的信息在一个
标记内.设置该
为锚点,然后用Xpath[9]路径表达式确定锚.XPath是一种专门用来在XML文档中查找信息的语言,我们用XPath路径来确定表达式.锚点table在全文档中的绝对路径表示为:
有人一声不吭向你扔了个文档 促进知识结构化的主题式复习初探 结构化面试方法在研究生复试中的应用 数据库 基于RI码计算的Word复制文档鉴别 数据库 数据库 数据库 Persistence of the reproductive toxicity of chlorpiryphos-ethyl in male Wistar rat 基于图模型的通用半结构化数据检索
/html/body/div/div/div/div/div/div
这个表达式指定了从根 元素到锚div的路径.绝对路径表达式的方法会导致页面布局发生改变时查找失效.所以采用仅与内容相关而与格式无关的相对路径指定锚.这时XPath表达式改为:
//div[starts-with(normalize-space(.), 'Feels Like')]
4.3 将数据映射成 XML
XSL是由XML派生的语言,使用XSLT通过模式与模板相结合来转换XML文档[10],主要用于设置数据的格式,实现了信息内容和显示格式分离.这里建立一个XSL文件,用来标识锚,指定如何从锚获取查找的数据,以我们所需的格式构造一个XML输出文件显示查找的数据.
XSL文件部分代码如下:
应用XSL文件把前面得到的XHTML文档转化为XML文档,实现该转化的代码如下:
public static void main(String args[]) {
try {
Document xhtml = ParseHTMLToXML.parseXMLFromURLString(“file://FORECASTS.xml”);
Document xsl= ParseHTMLToXML.parseXMLFromURLString(“file://XSL/FORECASTS.xsl”);
Document xml = ParseHTMLToXML.transformXML(xhtml, xsl);
ParseXHTMLToXML.outputXMLToFile(“XML” + File.separator + “result.xml”);
} catch (ParseXHTMLToXMLException xmle) {
// ... Do Something ...
}
}
其中parseXMLFromURLString()和transformXML()方法实现对抽取的XHTML文档在指定的XSL的映射下进行变换,并调用outputXMLToFile()方法将其输出到一个xml文件中.
4.4 合并结果并处理数据
如果仅抽取一次,建立一个XML输出文件就完成了.如果执行多次抽取,则可以通过建立的MergeXML方法,把当前抽取中获得的数据合并到以前抽取数据的XML文件中,并可以通过该文件观察数据抽取的正确性.
4.5 抽取结果入库保存
抽取的数据可以直接作为结果辅助决策,也可以存入数据库直接保存.直接存入数据库的代码如下:
DriverManager.registerDriver(new oracle jdbc driver OracleDriver());
Connection conn=DriverManager. getConnection(“jdbc oracle oci8@”, “username”, “password”);
Oracle.xml.sql.dml.OracleXMLSave Sav=new OracleXMLSave(conn,“tblname”);
Sav.insertXML(xmlOut);
Sav.close();
5 结束语
随着网络的迅猛发展,WEB信息抽取会变得越来越重要.本系统移植性较好,大部分代码可以重复使用,通过选择与内容相关但与格式无关的锚,可以方便、快捷地抽取所需的信息.
参考文献:
[1]陈佳,胡燕,轩艳艳.一种基于XML的Web信息抽取方法[J].计算机数字与工程,2007,38(6):101~103.
[2]范立峰.XML实用教程[M].北京:人民邮电出版社,2009:1~13.
[3]周晓梅,王潜平,苏琳.基于XML的Web数据挖掘模型的设计[J].计算机工程与设计,2007,28(2):272~274,277.
[4]李姗,黄水源.基于XML的WEB信息抽取模型设计[J].微计算机信息,2009,25(3-3):207~208,211.
[5]HTML Tidy[EB/OL].http://www.w3.org/MarkUp/
[6]毛国君,段立娟,等.数据挖掘原理与算法[M].北京:清华大学出版社,2007:39~43.
[7]周翔.基于XML的web内容挖掘研究[D].重庆:重庆大学,2007.
[8]盖磊,王海军,刘俊民.一种基于XML的Web地震信息抽取的实现[J].计算机应用与软件,2007,24(8):103~105.
[9]陈佳.基于XML的Web信息抽取技术的应用研究[D].湖北:武汉理工大学,2007.
[10]陈景霞,张鹏伟.基于XML的Web数据挖掘模型的研究[J].情报杂志,2006(11):100~102.
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
财经(2017年2期)2017-03-10 14:35:35
信息安全研究(2016年4期)2016-12-01 06:06:54
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
财经(2016年6期)2016-02-24 07:41:51
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
计算机工程(2015年8期)2015-07-03 12:20:35
