
基于旅游博客和论坛提高旅游产品质量的模型研究*
2012-01-08 03:00:02张军洲连云凯
旅游研究与实践 2012年2期
张军洲,连云凯
(桂林旅游高等专科学校 ,广西 桂林541006)
一、旅游博客和论坛的发展
虚拟社区在近些年发展得非常迅速,博客、论坛、YOUTUBE、Wikis、2nd life等都是虚拟社区发展的例子,这些技术的发展使人们可以和全世界的人们共享自己的经验[1]。而虚拟社区又分为两大类,一类是以YOUTUBE和2nd life为代表,关注点在于视觉的经验分享,比如视频和图片;另一类是以论坛和博客为代表,关注点是网页上的文本,文字的内容容易获取、标记,进而可以综合分析,使管理者能得到需要的商业信息。而作为近几年的一个热门产业——旅游,由于越来越被人们重视,人们总是会在节假日安排自己的旅行。由于网络的发展,越来越多的人乐于以博客和论坛的形式发表自己的旅行经验以及对旅游产品的评价,所以旅游博客和旅游论坛近几年也迅速发展。很多人计划旅行时,也会通过网络查看自己计划旅游地的外部评价,从而选择最优的旅行安排。
本文以旅游博客和旅游论坛为着眼点,介绍了它们对传统旅游产业的影响,论证了在新的网络时代,如何利用旅游博客和旅游论坛为旅游管理者提供改善旅游产品的方向。
二、旅游博客和论坛对旅游产业的影响
传统的旅游业主要通过一些传统媒体,比如电视、报纸、杂志,宣传自己的旅游产品。但是,面对现在新的网络时代,这些做法已经落后,具有明显的缺点:
(1)投资较高。由于传统媒体资源有限,要达到广告效益,投资必然较高。
(2)缺少交互性,较少得到旅游消费者的反馈,不能改进提高。
(3)旅游管理者不易把握旅游市场发展的动向,不易了解自己的竞争对手。
而通过网络的方式则可以明显得以改善。现在很多旅游管理者已经看到这个趋势,在网络上投入广告,推广自己的旅游产品,稍有远见的管理者则专门建立自己的旅游网站进行宣传,通过传统媒体和新媒体的结合推广自己的旅游产品。不过,如何利用当前发展迅速的旅游博客和论坛,却少有人了解。
游客在博客和论坛上所写的文章,往往会包含很多信息,比如自己的喜好、期望得到什么样的服务、对已经去过的旅游景区的评价、下次他可能会去哪里旅游、他对某个酒店的评价等。而且由于网络的发展,虚拟社区可以使游客非常容易地和全世界的人分享自己的旅行经验,从而他的文章不仅仅代表了个人的旅游产品消费信息,还能对其他有同样旅游动机的消费者产生巨大的影响[2-4]。比如,对一个酒店负面的评价有可能会立即减少预定该酒店的顾客,而关于某个餐馆的美味菜肴和服务员的热情接待的正面评价,则可能迅速增加这个餐馆的顾客。
因此,旅游管理者应该尽快学会利用旅游博客和论坛获取信息,从而使其成为改善和提高旅游产品质量的有力工具。旅游管理者使用旅游博客和论坛的优势如下:
(1)通过分析,可以知道消费者是如何评价自己的旅游产品的,或者了解消费者对其它旅游产品的评价,从而做到知已知彼,提高自己的竞争力。
(2)通过检查消费者对某旅游产品正面或负面的评价,可以找到自己存在的问题,以改进和提高服务质量,提高自己在相关领域的产品竞争力,开发新的产品服务,对已有的优势加强宣传。
(3)通过分析消费者感兴趣的内容,可以预测旅游发展的趋势,从而有助于旅游管理者为将来的发展方向做决策。
三、人工分析和软件自动分析比较
由于网络博客和论坛快速扩张,要分析所有相关的旅游文章成为一个巨大的任务,为了达到分析目的,通常要在一定时间间隔内阅读分析几百甚至上千的文章,很明显,这不是一个人可以在一天、一周或者一个月可以完成的任务。因此,人为的分析博客论坛文章显然是不可能的。
而与此同时,博客和论坛文章的数量还在迅速增长,这些文章随时都在增加,而且分析工作还在不断更新,需要每隔一段时间检查一次。而这些工作可以使用软件应用程序完成,还可以通过设置一些参数来完成不同的功能,而软件由于依赖于使用者的参数设定,所以不会像人为的那样,容易根据先前的经验而产生一些带有偏见的选择,且软件应用程序可以存储相应的内容到自身数据库里,从而避免检查重复的数据。另外,人工的核查分析代价非常昂贵,耗费时间和金钱,而软件应用程序从长远考虑具有非常高的性价比。
四、软件程序模型的探讨
要从网络中大量的旅游博客和论坛文章数据中搜索旅游管理者需要的信息,需要使用网络搜索引擎,按照搜索条件或者用户设定的范围,对网页中的数据进行搜索,得到相关的一系列的网址列表,接着利用程序对获得网址的文本内容进行划分,去除不相关的或者很少相关的网址链接,此后,提取相关文本的内容并存储到文件数据库系统,接着利用文本提取算法对数据库当中的文本进行分析,抽取需要的句子,简化分析,获得文本的关键词或者合成词关键词,生成数据表,并链接到相应的句子和文本当中,接着根据设定的分类机制进行文件划分,确定文本的评价性质是正面的,中性的或者是负面的,最后产生报告,给软件程序使用者。其流程图如图1:
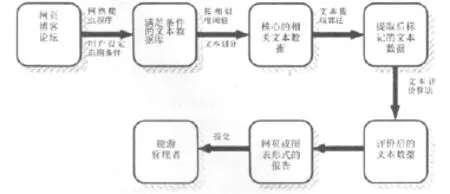
图1 程序模型的流程图
其中,搜索引擎为一个聚焦网络爬虫程序[5],它是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索。
实现此软件模型需要考虑的具体步骤是:
第一步:准备必要的搜索数据。在执行自动搜索前,用户要手工定义一些相关主题、关键词、URL等希望查询的信息,其中也可以包含一些用户想要检查的指定的论坛和博客。
第二步:运行搜索引擎网络爬虫程序。将第一步设定的主题表(检查条件)放入到搜索引擎网络爬虫程序中,从而得到相关的博客和论坛文章内容,这一步会产生大量的URL列表链接。
第三步:评测搜索到的URL结果。对第二步产生的URL列表进行检查,移除用户认为不相关的或极少相关的,保留用户认为相关的。
第四步:提取URL列表里的相关内容。在这一步,网络爬虫从URL列表里提取所有的相关内容,并写入到文件数据库系统中。
第五步:线性分析。应用线性分析,将前面步骤获得的文件内容拆分成句子,所有的句子富含语法信息(有精简的主谓宾等,句子类型,比如是疑问句,还是陈述句等),句子也将分组成段落。除此之外,将所有的关键词或者合成关键词从文章中也提取出来,构成一张数据表,并链接到相应的句子和文章中,且文本中只要出现和程序使用者提供的关键词相同的词,也标记出来,添加到数据表当中。
第六步:文本分类。基于第五步的数据表,将文本根据不同的分类机制进行分类,比如酒店、景区、活动场所等,把这些分类信息加入到程序模型中,也包含作者、URL、时间等信息。
第七步:确定各个文本评价结果的性质(正面的,中性的或负面的),根据产生的数据表中的关键词或句子的权值和极性来确定文章的评价分类。
第八步:产生报告,反馈给程序使用者。
要考虑的核心问题是:
(1)文本划分:如何将文本划分,去除不相关的或相关很少的文本。
可以通过搜索已有的主题词列表中的关键词实现,将网页文本中获得的关键词与初始使用者设定的条件区域关键词进行匹配,计算出每个网页的相似度,从而得到按相似度排序的一系列网页,设定一个相似度门限阈值,低于此阈值的网页被去除,高于此阈值的保留,留做进一步的分析使用。
(2)文本提取算法[6]:如何提取文章里的核心句子,关键词,合成关键词。
当前的文本提取算法有很多,比如K-最近邻分类算法(K_Nearest_neighbor)、朴素贝叶斯分类算法(NB)、支持向量机算法(SVM)、神经网络方法、最小平方拟合算法(LLSF)、线性回归模型算法、决策树算法(Decision Tree)等。
(3)对文本总结评价算法实现:如何确定文本的评价结果,比如是正面的、中性的,还是负面的,评价的程度如何等。
通过对生成的数据表中关键词或者合成关键词和已有的数据字典匹配,赋予极性(POL)和权值(POW),极性有3种,分别是正面的(Pos)、中性的(Neu)、负面的(Neg),而权值是0到1之间的数字。数据字典需要人为的添加并不断更新而生成,它是保证评价结果准确性的关键。表1为一个数据字典表的例子。这里需要注意,如果关键词前面有“很”、“非常”、“特别”等表达程度的副词时,其权值应相应地按比例增加。
另外,不同的程序使用者可以按不同的目的选择自己想要的信息。比如,一个负责酒店服务质量的酒店经理,往往会关注负面的评价结果,以找出自己企业的不足,从而改进。因此,他在使用时,可以降低对正面信息的关注度,而提高对负面信息关注的参数设定。而客户经理也会关注负面评价,以便能尽快地改进服务,市场部经理会比较关注正面的评价,用这些数据加大网络上对自己旅游产品的宣传。

表1 数据字典表
五、总结
本文分析了新网络时代旅游博客和论坛对传统旅游产业的影响以及如何使用旅游博客和论坛分析提高旅游产品质量,提高自己的竞争力,更进一步可以预测旅游发展的趋势,从而有助于旅游管理者为将来的发展方向做决策。文中给出了软件程序实现的步骤,并分析了其中的核心问题,给出了解决方法。由于本软件程序由多个模块构成,下一步的工作是要完成具体各个子模块的算法实现,选择最优的算法,以便进一步提高此软件程序的正确性。
[1]Archdale G.Computer reservation systems and public tourism offices[J].Tourism Management,1993:3-14.
[2]李莉,王静.从“观望者”到“购买者”:中国旅游电子商务消费者购买决策行为探析[J].旅游学刊,2008,23(5):49-56.
[3]石建中,康伟,李志刚 .关于在线旅游企业网络组织的研究 [J].旅游论坛,2011,21(5):48-53.
[4]王玉洁,颜琪,刘承良.旅游电子商务网站服务质量的感知实证分析[J].旅游论坛,2009,10(1):28-31.
[5]周立柱,林玲.聚焦爬虫技术研究综述 [J].计算机应用,2005(9):25.
[6]曹锋,张代远.文本分类技术研究[J].电脑知识与技术,2009,5(32):9023-9025.
猜你喜欢
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
中国卫生(2016年5期)2016-11-12 13:25:44
中国卫生(2016年4期)2016-11-12 13:24:08
电子测试(2015年18期)2016-01-14 01:22:58
博客天下(2015年2期)2015-09-15 14:12:57
中国卫生(2014年4期)2014-12-06 05:57:02
中国卫生(2014年10期)2014-11-12 13:10:32
计算机与网络(2014年7期)2014-03-25 10:57:07
博客天下(2009年12期)2009-08-21 07:35:10
