
一种基于支持向量机的数字音频认证方法
2011-09-25 03:24林晓丹
华侨大学学报(自然科学版) 2011年2期
林晓丹
(华侨大学信息科学与工程学院,福建泉州 362021)
一种基于支持向量机的数字音频认证方法
林晓丹
(华侨大学信息科学与工程学院,福建泉州 362021)
提出一种基于数字水印技术的音频内容认证方法.选取稳定的梅尔倒谱特征构造特征向量,利用支持向量机自适应地选取合适的帧进行水印的嵌入和提取.结果表明,算法在保证嵌入水印的不可感知性的同时,能够有效地区分恶意的内容篡改和非恶意的常规信号处理操作,准确地定位篡改发生的位置.
数字音频;水印技术;认证;梅尔倒谱系数;支持向量机
数字音频认证包括精确认证和选择性认证,前者要求需要认证的音频和原始音频完全一致.但人们更关心的问题是音频所传达的信息是否真实,是否遭受了篡改,并不要求精确到每个数据位完全相同.文献[1]用量化小波系数的方法嵌入水印,检测时不需原始音频,通过比较归一化相关系数判断音频是否遭受篡改.文献[2]采用奇偶调制的方法对指数刻度下的傅里叶变换系数进行量化,对某些信号处理操作具有鲁棒性,对恶意篡改具有脆弱性.然而,大多认证算法未能利用多媒体信号自身特征以自适应地嵌入水印,需要较多的人工干预,导致算法性能过分依赖于参数的选择.支持向量机(SVM)由于其良好的学习和泛化能力,近年来开始被引入数字水印领域.文献[3]利用支持向量机,把水印的检测问题转化为一个支持向量机的二分类问题,提高水印检测的性能.文献[4]采用自适应量化的水印嵌入策略并将回归型支持向量机用于水印的检测,实现水印鲁棒性和不可感知性的良好平衡.本文利用支持向量机选择合适的帧在音频离散余弦变换(DCT)域中嵌入水印,并将训练好的支持向量机用于水印的检测.
1 水印信息的构造
选用二值图像作为水印信息,图像大小为M×N.为了去除图像像素点之间的相关及增强认证系统的安全性,对二值图像进行A rnold置乱.将置乱后的图像G经过降维处理,可以得到一维序列W1={g(l)=G(i,j),1≤i≤M,1≤j≤N,l≤i×M+j}.用两个不相关的长度均为cr的伪随机序列PN(0)和PN(1)对序列W1扩频[5],若嵌入0,则映射成PN(0);否则,映射成PN(1).即

式中,PN(0,k)代表PN(0)的第k位,mod表示取模运算,W为最终要嵌入音频载体的水印信号.
2 构造特征向量
先对音频分帧,计算各音频帧的12阶M el系数.然后,取出第1阶和第12阶频率倒谱系数(M FCC)[6],构造出特征向量 p=.其中:r是帧号.由音频掩蔽特性可知,能量大的区域嵌入水印透明性好.因此,定义目标向量 dr:当大大时,dr=1;而当小小时,dr=-1.将两类特征向量(样本数分别为S1和S2)与目标向量 dr(1≤r≤S1+S2)一起构成S1+S2组训练样本以训练支持向量机.
3 水印的嵌入与提取
对原始音频信号A分帧,每帧包含N个采样点,共L帧.计算各帧音频的12阶M FCC,构造特征向量δr=1≤r≤L).将δr输入训练好的SVM,得到预测输出 dr.若 dr值为1,则此帧被选中用于水印的嵌入;否则,不用于水印的嵌入.对被选中的音频帧作离散余弦变换(DCT)变换,选择cr个中频系数作为水印的嵌入点.然后,根据c′i=ci+(2w i-1)·α修改DCT系数.其中:α为水印嵌入强度,w i是扩频后需要嵌入的水印位.最后,对修改后的帧施行DCT逆变换,得到含水印的音频A′.
水印提取不需要原始音频,能够实现盲检测.首先,将待检测音频按照嵌入时的长度分帧,计算各帧特征,得到各音频帧的特征向量.由于输入之前已训练好SVM,若SVM预测输出的结果为1,则表明该帧包含水印,需要在此帧中进行水印的提取;否则,跳过该帧.然后,对包含水印信息的帧进行DCT变换取出cr个中频系数fi(l)(i=1,2,…,cr),l为帧号,计算水印嵌入分量f(l)与伪随机序列PN(0), PN(1)的相关值cor0和cor1.即

提取水印时,不需设置检测阈值,只比较哪个相关值大即可,使算法的检测性能不受阈值设置的影响.cor0>cor1,提取出水印位“0”,否则提取水印位“1”.对选中的音频帧进行相同操作,提取各水印比特,再进行升维、反置乱处理,便可恢复嵌入时所使用的二值图像G*.计算篡改评估函数TA F,有
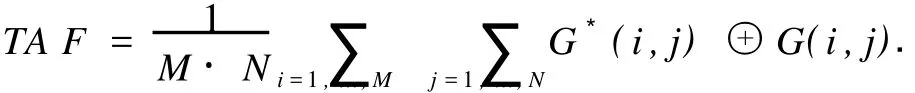
其中:G为原始二值图像;⊕表示异或操作.若TA F大于某个阈值则认证失败.G*(i,j)⊕G(i,j)=1,说明该比特发生错误,对应于该比特的帧即为篡改发生区域.
4 仿真结果分析
实验选用长度10.38 s的音频信号,采样率44.1 k Hz,16位量化,单声道.选择512作为音频帧长,水印嵌入强度α=0.1,SVM选用RBF核,参数σ取0.01,TA F检测阈值设为0.3.内容篡改后提取的水印图像,如图1所示.图1(a)为嵌入的原始二值图像,大小为24 px×24 px;图1(b)为含水印的音频未受任何攻击时所提取的二值图像.为了验证算法对音频内容篡改的检测性能,剪切中间第5~6 s的音频,图1(c)是提取出的二值图像;替换第7~8 s间的一段音频后,提取的二值图像如图1(d)所示;在8 s时插入10帧其他音频后提取的二值图像,如图1(e)所示.

图1 内容篡改后提取的水印图像Fig.1 Extracted watermarks after audio tampering
当音频遭受恶意替换时,算法对篡改定位的结果如图2所示.图2(a)中:嵌入了水印的音频峰值信噪比为39.816 dB;φ为归一化幅值.
此外,算法对常规信号处理操作具有一定的鲁棒性.含水印的音频信号在不同常规信号处理操作后,提取的水印图像的误比特率(RBE)不同.64 kbit·s-1的M P3压缩,RBE为0;截止频率为11.025 k Hz的低通滤波,RBE为 1.56%;高斯噪声(均值为0,方差为0.01),RBE为0.35%;重采样(下采样到22.05 k Hz,再还原成44.1 k Hz),RBE为1.04%;重量化(从16 bit量化成8 bit,再量化成16 bit),RBE为0.
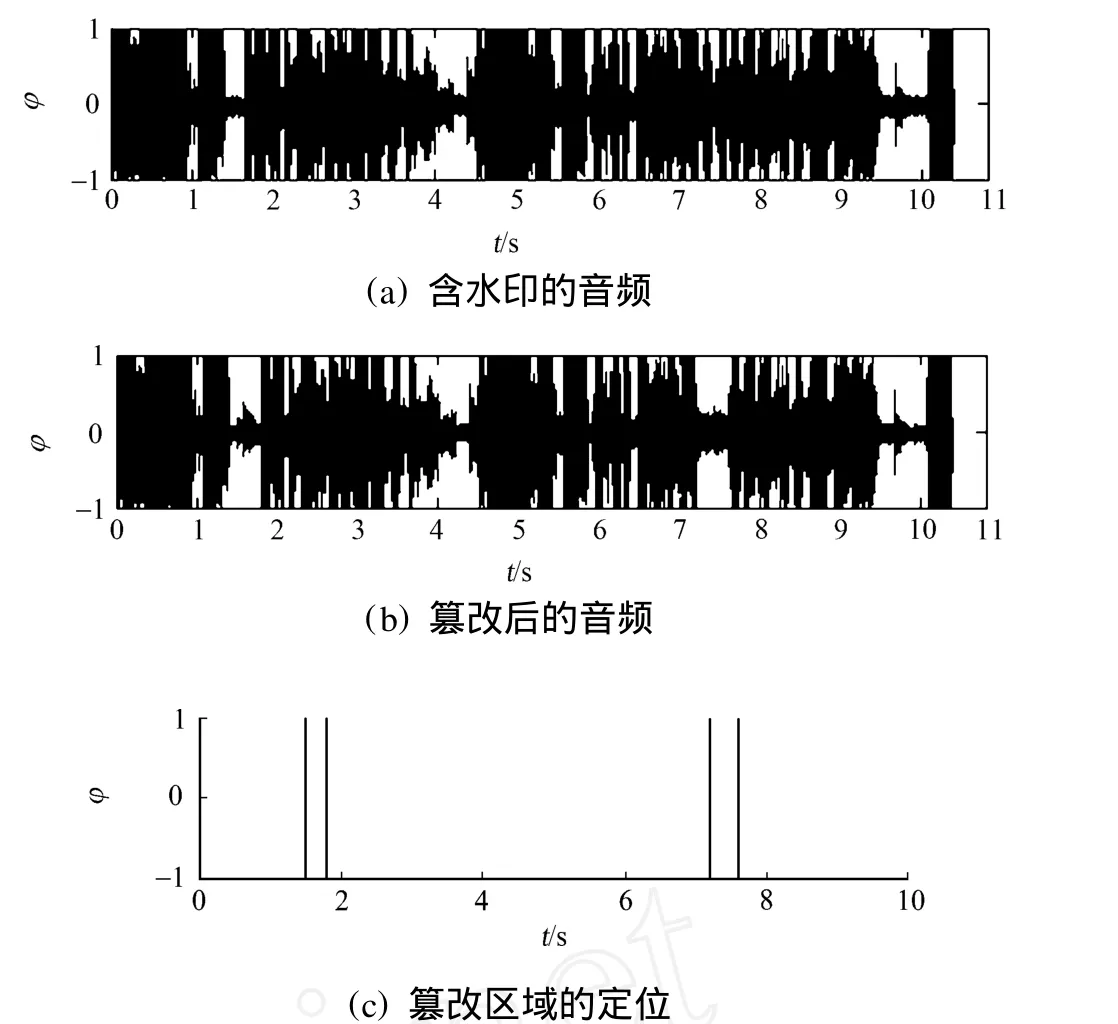
图2 算法对篡改定位的结果Fig.2 Results of tamper detection
5 结束语
提出一种选择性音频认证方法,利用支持向量机自适应选取合适的帧进行水印的嵌入和提取.实验结果表明,算法在保证嵌入水印的不可感知性的同时,能够有效地区分恶意的内容篡改和非恶意的常规信号处理操作.此外,认证方法能够实现盲检测,在需要对音频语义内容进行认证的应用中具有一定的实用价值.
[1]孙圣和,王秋生.数字音频信号的脆弱水印嵌入算法[J].计算机学报,2002,25(5):520-525.
[2]WU Hung-ping,KUO C C J.Fragile speech watermarking based on exponential scale quantization for tamper detection[C]∥Proceedings of IEEE International Conference on Acoustic,Speech,and Signal Processing.Florida: IEEE,2002:3305-3308.
[3]王剑,林福宗.基于支持向量机(SVM)的数字音频水印[J].计算机研究与发展,2005,42(9):1605-1611.
[4]WANG Xiang-yang,QI Wei,N IU Pan-pan.A new adaptive digital audio watermarking based on support vector regression[J].IEEE Transactions on Audio,Speech,and Language Processing,2007,15(8):2270-2277.
[5]LANGELAAR GC,SETYAWAN I,LAGEND IJK R L.Watermarking digital image and video data[J].IEEE Signal Processing Magazine,2000,17(5):20-46.
[6]PFEIFFER S,FISCHER S,EFFELSBERGW.Automatic audio content analysis[C]∥Proceedings of the 4th ACM Multimedia Conference.New York:ACM,1997:21-30.
(责任编辑:钱筠英文审校:吴逢铁)
An SVM-Based Digital Audio Authentication Method
LIN Xiao-dan
(College of Information Science and Engineering,Huaqiao University,Quanzhou 362021,China)
A watermarking-based method for audio content authentication is proposed.Mel frequency cepstral coefficient (M FCC)is adopted to construct training vectors for support vector machine(SVM).Adaptive watermark embedding and extraction is achieved by the well-trained SVM.Experimental results demonstrate that this approach not only can distinguish malicious tampering from content-p reserving operations,but also accurately locate regions that have under gone malicious manipulations while keeping the inaudibility of the embedded watermark.
digital audio;watermarking;authentication;Mel frequent cepstral coefficient;support vector machines
TN 911.72;TN 912.3
A
1000-5013(2011)02-0153-03
2009-12-19
林晓丹(1983-),女,助教,主要从事多媒体信号处理及安全认证技术的研究.E-mail:echo.linxd@gmail. com.
华侨大学科研基金资助项目(09HZR12)
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
测控技术(2018年10期)2018-11-25
电子产品世界(2018年1期)2018-09-21
许昌学院学报(2018年4期)2018-05-02
计算机技术与发展(2017年12期)2017-12-20
中华建设(2017年1期)2017-06-07
计算机应用(2016年10期)2017-05-12
电子制作(2017年10期)2017-04-18
现代商贸工业(2016年35期)2016-04-09
