
块备份数据多版本融合方法
2011-08-10 01:51王树鹏吴广君吴志刚云晓春
通信学报 2011年12期
王树鹏,吴广君,吴志刚,云晓春
(1.中国科学院 计算技术研究所,北京 100190;2. 灾备技术国家工程实验室,北京 100876;3. 北京邮电大学 网络技术研究院,北京 100876)
1 引言
各种灾难事件、突发事件通常会引起数据的丢失或者不可访问,为企业、部门甚至个人都会带来巨大的经济损失[1,2]。国标GB/T 20988-2007《信息安全技术 信息系统灾难恢复规范》中将灾难定义为:由于人为或自然等原因,造成信息系统运行严重故障或瘫痪,使信息系统支持的业务功能停顿或服务水平不可接受。根据上述标准,典型的灾难事件包括自然灾害,如火灾、洪水、地震、飓风等;人为错误,如管理员误操作、病毒攻击等。数据的备份和恢复技术便成为数据安保,恢复瘫痪系统的最后一道防线。
多版本块数据备份技术通常在逻辑卷层次或磁盘驱动器层次实现与应用无关的数据复制,支持任意历史版本的数据恢复。常见的备份技术如图 1所示,随着数据复制时间粒度的提高,数据保护性能会越好。目前通常使用在线数据复制技术支持细粒度多版本数据的备份与恢复。在线数据复制技术主要包括以COW(copy-on-write)技术为代表的写时旧版本数据复制技术和 ROW (redirect-on-write)技术为代表的写时新版本数据复制技术。COW 技术在发生写操作时首先复制出旧版本数据,按序存储各个历史版本序列。在数据恢复时从当前时间点开始依次恢复之前版本的备份数据,实现历史状态的回滚。这类技术广泛存在于多版本文件系统中,如Elephant[3], Ext3cow[4],CVFS[5]等。但是COW技术具有如下2个缺点。1) COW具有明显的写延迟。COW 技术需要把原始系统中的一次写操作变为读旧数据,存储旧数据,最后执行写入的3次操作。尽管旧版本数据的转存,新版本数据的写入可以并发执行[6],但是仍然具有明显的延迟。2) COW无法实现系统级别的全量恢复,仅能恢复由于误操作导致的局部数据污染[7]。ROW技术直接复制写数据流或数据块,写入到新分配的存储空间。ROW技术可以应用在数据复制频率较高的场合,如CDP(continuous data protection)等。结合快照备份数据,ROW技术可以实现系统级别的全量恢复,但是随着数据复制频率的增加和数据保存时间的延长,备份数据版本数目会不断增长,形成版本之间相互依赖的版本链条,使得数据管理越来越复杂,直接影响着数据的可恢复性和恢复效率。
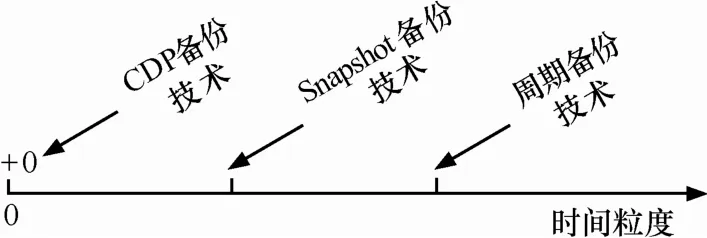
图1 数据保护技术的分类
文献[8~10]中通过专用系统或硬件实现增量备份数据版本序列的管理,但是无法管理分离存储的备份数据。为了提高备份数据管理效率,降低数据备份恢复成本,目前迫切需要建立独立于主端系统的第三方备份数据管理中心[11]。TRAP[12,13]把实时复制的更新数据块单独保存在 CDP数据盘中,实现持续数据保护。但是TRAP在检索目标版本数据时通过按序扫描版本序列,检索时间随着版本序列长度线性增长。文献[14]和文献[15]在定长的版本序列中插入全量镜像数据或快照数据,加速版本链的检索过程。但是频繁的产生系统级别的镜像数据或全量快照数据不仅增加主端系统的备份负担,而且产生的周期备份数据与已经存储的版本序列存在版本冗余现象:即内容相同的数据块保存在多个版本中。如何利用存储端存储的备份数据版本序列构建出任意历史时间点的全量快照备份数据,是提高细粒度多版本条件下备份系统效率的主要途径。
本文基于上述背景,提出块备份数据多版本融合方法,通过版本序列的融合构建出任意历史时间点的全量快照备份数据,避免主端系统频繁产生快照备份数据而降低系统性能。在具体实现中,本文结合块备份数据的分布特点,以版本序列中逻辑地址连续的数据块,作为版本融合单位,降低了版本融合带来的计算负担;最后文章给出了版本融合技术在多版本备份数据管理中的应用案例和性能分析。
2 块备份数据版本融合原理
多版本块备份数据是通过加载在主端的备份代理结合在线数据复制技术而产生的。块数据复制技术本质是复制一定时间保护粒度(T),逻辑地址空间(x)内的变化的数据,可使用写密度函数 wT(x)抽象表达二者关系,如式(1)所示。由写密度函数产生的数据量(d)可以表示为式(2),其中,Length是每个逻辑地址单元对应的数据块长度。式(3)和式(4)进一步给出在整个逻辑地址空间和备份数据生命周期内产生的备份数据总量,公式具体含义在文献[16]中有详细分析。

其中,[0, N]表示一个逻辑卷的地址空间;[0, H]表示备份数据的生命周期,超过生命周期的备份数据直接删除或做进一步的归档处理。
通过式(4)和式(5)可以得出,在备份数据生命周期内,备份数据量的版本序列长度(M)随着数据复制时间粒度的减小(T)而增加。
为了进一步描述多版本序列与主端系统之间的对应关系,引入 Markov转换过程表示。如图 2所示,给出了在一定数据复制频率下主端的数据状态和备份数据版本序列之间的状态转换关系。其中,D表示主端的数据状态,Δ表示增量备份数据。不同版本的数据状态使用版本号i进行区分,Di表示版本号为i数据状态。版本序列和数据状态之间通过版本号进行关联,如由数据状态Di产生更新数据Δi,i+1后变化到数据状态Di+1。
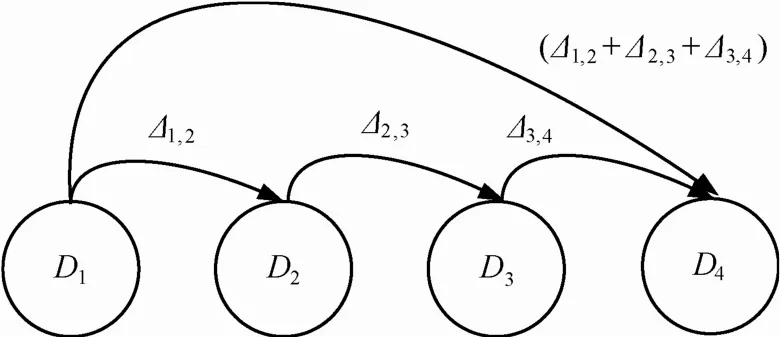
图2 基于Markov过程的数据状态转换过程
利用Markov过程中的状态转换可以表示多版本条件下,数据恢复过程中目标版本的检索过程,比如要恢复早期数据状态,需要利用某一个版本的数据状态点作为起点,结合增量备份数据版本序列转换到目标版本数据状态。传统方法是通过数据备份产生数据状态点,并结合增量备份数据版本序列实现数据状态转换;一种更优化的方法是通过把多个增量版本序列融合,利用产生的融合版本加快状态之间转换。如图D1到D4的状态转换可以通过Δ1,2+Δ2,3+Δ3,4版本之间的融合,实现数据状态之间的转换。块备份数据版本融合过程可以形式化定义为
定义1 版本融合。设 2个相邻版本的块备份数据 Δi={(x, d)|x∈Ni, d∈D};Δi+1={(x', d')|x'∈Ni+1, d'∈D'};其中,N表示块数据的逻辑地址空间,D, D'表示逻辑地址空间内的数据,把Δi与Δi+1合并成一个新融合版本Δ′,构成Δ′的数据块集合可以表示为式(6),这一过程称为版本融合。

版本融合的基本思想是根据块备份数据逻辑地址的相对关系,通过块数据的替换产生新版本的备份数据。版本融合可以在相邻的多个版本构成的版本序列依次使用,于是得出如下引理。
引理 1 多版本块备份数据构成的版本序列中,可以把版本相邻的序列,融合成一个版本,这一过程可以通过式(7)表示。
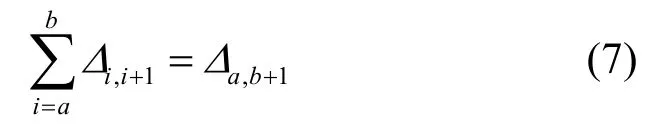
根据版本融合定义,容易证明上述定理,具体的证明过程不再详述。利用定理1可以把一个增量备份数据版本序列融合为一个版本,进而缩短版本链的长度,加快版本链的检索过程。
3 块备份数据版本融合算法
文献[17]中分析了磁盘数据局部访问特性,由此产生的备份数据版本序列是由一系列逻辑地址相对连续的数据块集合构成,本文根据数据块分布的特征提出一种变长数据块版本融合方法。在变长数据块版本融合操作中,需要根据 2个版本数据块的相对关系进行匹配。设新版本中,数据块r的一个连续逻辑地址空间为[a, b], a≤b;旧版本中,数据块R的一个连续逻辑地址空间为[A, B],A≤B;则数据块r与R的匹配关系可以描述成如下6种情况。
定义 2 左独立。if(b<A),则新版本数据块 r相对于旧版本R左独立,如图3中的①,简称左独立,记为Left-Independent。
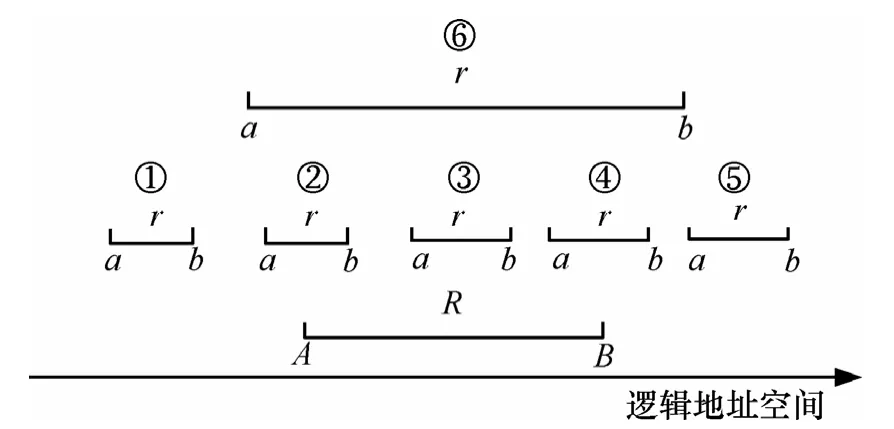
图3 r和R的6种区间匹配关系
定义 3 左重叠。if(a<A and b≥A and b≤B),则称新版本数据块 r相对于旧版本数据块 R左重叠,如图 3中的②,简称左重叠,记为 Left-Overlapping;
定义 4 包含。if(a>A and b<B),则称新版本数据块r包含于旧版本数据块R中,如图3中的③,简称包含,记为Included;
定义 5 右重叠。if(a≥A and a≤B and b>B),则称新版本数据块 r相对于旧版本数据块 R右重叠,如图 3中的④,简称右重叠,记为Right-Overlapping;
定义 6 右独立。if(a>B),则称新版本数据块r相对于旧版本数据块R右独立,如图3中的⑤,简称右独立,记为Right-Independent;
定义 7 覆盖。if(a≤A and b≥B),则称新版本数据块r相对于旧版本数据块R满足覆盖关系,如图3中的⑥,简称覆盖,记为Overlapping。
在系统软件和磁盘调度算法中通常使用起始地址加数据长度记录RAW Data的分布,但是所记录的数据块之间都满足独立的关系,如图3中的①和⑤所示,r全部在R的左侧或右侧。在版本融合过程中 2个数据块会发生重叠情况,如Left-Overlapping、Included以及 Right-Overlapping等情况,需要进行预处理,把旧版本数据块进行分割,分割后的子区间满足独立或覆盖的关系。数据块区间分割方法包括如下2种方法。
定义 8 区间叠加。在满足Overlapping关系条件下,即r覆盖R时,R中任意一点在r中都有与之对应的部分,使用r替代R的过程称为区间叠加,记为:r+R;
定义 9 区间分割。在区间关系左重叠,包含以及右重叠等条件下,把R进行分割,产生的区间子项 Ra、Rb、Rc,其中,r与 Ra具有 Right-Independent的区间关系;r与 Rb具有 Overlapping关系,r与Rc具有Left-Independent的区间关系,把这一过程称为区间分割,记为:R/r。
结合上述基本定义和描述,可以给出变长数据块版本融合基本算法描述。设每个版本内的数据块集合记为F。多次复制过程中产生的版本序列记为:{F1, F2, …, Fn},版本融合算法如下所示。
算法1 版本融合算法:VersionMerge (Fr, FR)
输入:Fr, FR
输出:Ft
Fr表示新版本数据块集合;FR表示旧版本数据块集合;Ft表示融合后的数据块集合;假设FR, Fr集合内的所有数据块都是按照逻辑地址递增的顺序排列;
VersionMerge (Fr, FR){
1) i=1, k=1;//i为Fr内的数据块的标示;k为FR内的数据块标示;
2) for(each ri∈Fr, Rk∈FR){
3) if(Frand FR都没有结束){
4) switch(compare(ri, Rk);) {
5) case Left-Independent:
6) add rito Ft;i++;break;
7) case Left-Overlapping or Included or Right-Overlapping:
8) Rk/ ri→Ra,Rb,Rc;
9) if(Ra≠NULL) add Rato Ft;
10) if(Rb≠NULL) {
11) ri/Rb→ra, rb, rc;
12) if(ra≠NULL) add rato Ft;
13) if(rb≠NULL) add rbto Ft;
14) if(rc≠NULL) rc→ri;}
15) if(Rc≠NULL) Rc→Rk;
16) break;
17) case Right-Independent:
18) add Rkto Ft;
19) k++;break;
20) case Overlapping:
21) k++;break;}}}
22) if (Fr尚未处理结束) 把Fr没有处理的部分直接加入到Ft中;
23) if (FR尚未处理结束) 把FR没有处理的部分直接加入到Ft中;
24) return Ft;}
算法1给出2个版本融合的具体实现过程,在变长数据块分割算法中, 具有重叠关系的数据块可能会被频繁分割处理,这部分数据块的长度在融合版本中会逐渐趋近于磁盘写操作的最小分配单元,如sector长度。版本融合过程使用算符“⊕”表示,也称为版本的叠加,算法1可以表示为Ft=Fr⊕ FR。
4 版本融合在多版本备份数据管理中的应用
4.1 基于版本融合的快照检索方法
快照备份数据描述一个时间点的瞬时数据镜像,对保证数据的可恢复性,加快多版本检索过程具有重要意义。结合算法 1,在备份数据版本序列中,从目标版本开始, 逆序融合每个版本, 直到最近的全量备份数据为止, 这一过程可以使用算法 2表示,记为SnapshotSearch (i, S)。
算法 2在版本序列中循环利用版本融合算法,获取时间点为 i的全量快照备份数据, 可以使用式(8)表达这一检索过程。
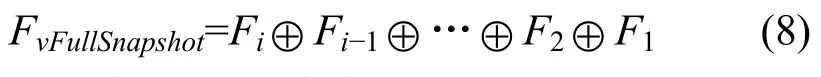
算法2 快照融合算法: SnapshotSearch(i, S)
i:待检快照版本号;S: 版本序列;Fi:第i个版本;FVFullSnapshot: 结果快照数据块集合;
输入:i, S(1≤i≤n)
输出:FVFullSnapshot

版本序列的融合操作可以在备份系统空闲时发起,并保存融合后的结果版本加速后期的版本检索过程。基于版本融合,可以进一步实现多版本序列的删除操作。对于超过备份数据生命周期的版本序列可以利用版本融合技术,融合成一个新版本的备份数据,起到版本序列删除的作用。
4.2 多版本差异恢复模式
备份数据主要用于数据恢复。根据第2部分的分析,以ROW技术为代表的分离存储系统中,数据恢复过程通常选择距离目标时间点最近的全量数据作为数据的一致性状态,然后再结合更新数据版本序列,逐次前向恢复到目标时间点。在分离存储的备份系统中,需要恢复的数据量是影响恢复效率的主要因素。利用版本融合技术,结合算法2可以直接计算出版本序列中目标时间点的全量快照数据,结合校验技术可以快速判断当前的主端系统的数据状态与历史数据状态实际发生变化的数据,通过仅恢复变化数据提高恢复效率。这一数据恢复过程称为多版本差异恢复,记为 Diffdo,利用算法3表示。
算法3 多版本差异恢复过程:Diffdo(T)
T:待恢复的版本号,1Tn≤≤;
1) 存储端根据算法2,计算版本号为T的全量快照数据FVFullSnapshot(T):
FVFullSnapshot(T)=FT⊕FT-1⊕…⊕F1
2) 存储端根据 FVFullSnapshot(T)计算快照数据的校验文件:CheckFile(T),并发送到主端;CheckFile(T)包括校验规则和校验值:
Check(FVFullSnapshot(T)) →CheckFile(T)
3) 主端根据CheckFile(T)计算本地磁盘当前数据块的校验值,并与 CheckFile(T)中对应的校验值比对,记录校验不一致的数据块对应的逻辑地址,生成CheckErrorFile(T),并发送到存储端:
CheckFile(T)→CheckErrorFile(T)
4) 存储端根据CheckErrorFile(T)和FVFullSnapshot(T)检索备份数据,计算差异恢复索引文件DiffdoLog(T),并根据DiffdoLog(T)进行差异数据恢复:
CheckErrorFile(T)+FVFullSnapshot(T)→DiffdoLog(T)
Diffdo利用版本融合技术,构建版本序列中目标时间点的全量快照数据,可以直接与主端系统当前数据状态进行比对,只恢复实际发生变化的数据块,通过减少恢复数据量提高恢复效率。
5 实验与结果分析
本文采用标准 trace和具体备份系统相结合的方法展开实验分析。首先利用HP cello99 trace分析在持续数据保护背景下使用版本融合技术和定期产生快照备份数据 2种技术产生的备份数据量比较。然后结合具体系统,给出版本融合技术在多版本备份数据管理中的效率分析。
5.1 版本融合后产生的数据量分析
Cello99 trace是HP实验室记录UNIX服务器全年的磁盘I/O trace。实验中选取cello99-03-03的I/O trace进行分析。本文回放连续24h的磁盘I/O操作,分析2种技术产生的备份数据量关系。图4中给出了实验结果。实验中选取每次写操作作为一个版本,快照周期选取版本序列长度为:40、80、120、160、200产生快照备份数据。实验结束时,使用版本融合技术比周期快照技术少产生备份数据量43.4%左右。实验中进一步发现随着快照周期内版本序列长度的增加产生的快照备份数据量会有所减少,这一现象主要是由于磁盘具有写局部性造成的,一个快照周期内逻辑地址相同的数据块会发生重复写操作,如果能够统计重复写的比率,进而控制融合版本序列的长度,会进一步提高版本融合的效率。
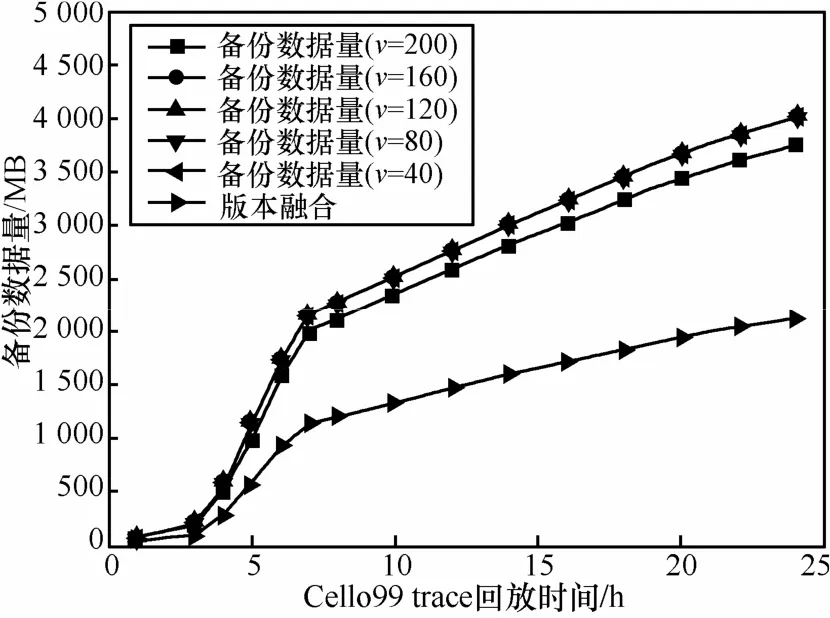
图4 版本融合技术产生的备份数据量比较
5.2 变长数据块索引技术效率分析
本文进一步通过实际的数据备份恢复系统分析版本融合具体的性能。备份系统中主端选取 XP操作系统的PC机,具体配置为Intel(R) Core(TM)2 CPU 1.8GHz/1.79GHz, 1GB内存,NTFS文件系统,目标逻辑卷为20GB。存储端由4台存储服务器构成的存储集群,具体配置为Inter(R) Core(TM)2 Duo CPU2.2GHz/2.19GHz,1GB 内存;Realtek 100M(2);Inter(R) Core(TM)2 Duo CPU 2.2GHz/2.19GHz,2GB内存,Realtek 100M(2)。实验中利用磁盘过滤驱动技术,监控主端目标逻辑卷,产生周期性的增量备份数据。备份周期为10~30min,共产生50个版本的备份数据。
图5给出了定长数据块与变长数据块在多版本数据管理中的索引量比较。索引数据量直接与数据块的分割方式有关,版本融合技术中以逻辑地址连续的数据块作为多版本管理单位,可以比静态数据块多版本管理方法减少 2~3个数量级的索引数据量,为降低版本融合计算复杂度提供基础。图6给出了利用变长数据块融合方法检索全量快照备份数据的时间消耗。变长数据块版本融合的时间消耗明显低于定长数据块多版本管理方法。
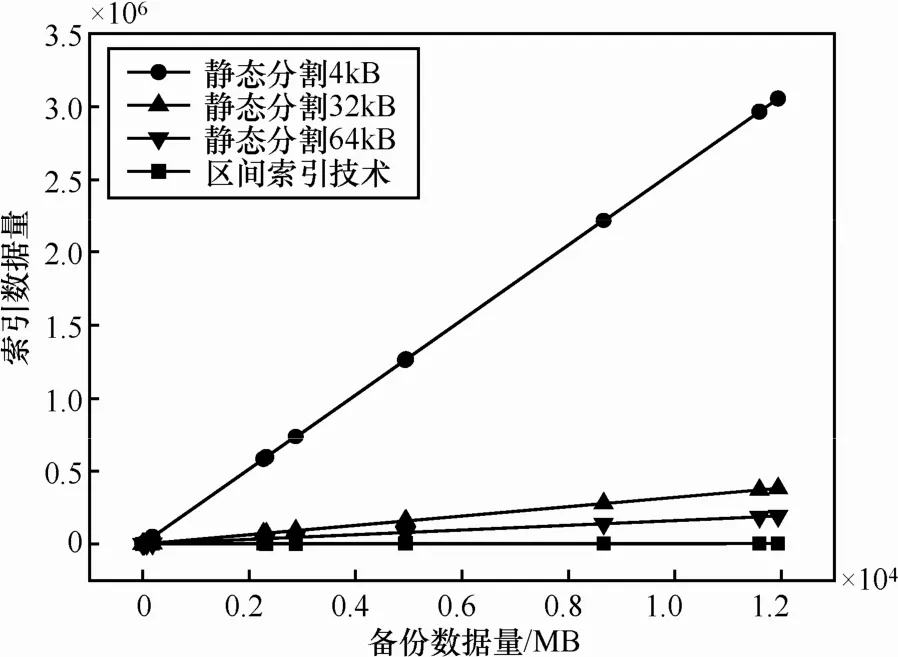
图5 索引数据量的比较
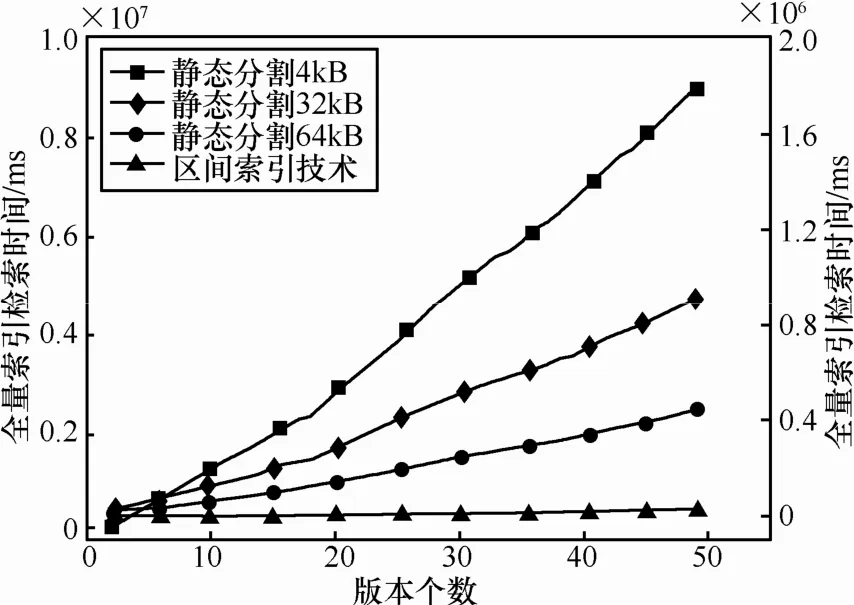
图6 全量快照检索时间比较(图中使用双y轴,静态分割4kB的索引技术使用左侧的y轴,另外3种技术使用右侧的y轴)
5.3 数据恢复效率分析
备份数据恢复效率通常使用RTO(recovery time objective)表示[18]。在分离存储模式下,数据恢复时间消耗主要包括从发生数据丢失一直到业务重新启动的时间间隔,可以表示为
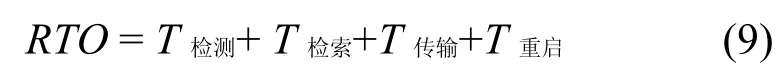
T检测:表示从灾难发生到检测到数据丢失的时间;
T检索:表示在存储端按照一定的恢复模式, 检索待恢复备份数据的时间;
T传输:表示备份数据由存储端传输到主端的数据传输时间;
T重启:表示数据成功恢复后, 重新启动业务的时间;
T检测、T重启与具体的业务相关,在本文中忽略不计,于是RTO可以表示为

T检索与存储端的备份数据组织方式有关,T传输与待恢复的备份数据量和传输带宽相关,在传输带宽一定的条件下,T传输由恢复数据量决定。为了进一步描述T检索和T传输的相对关系,引入检索时间占有率因子α,如式(11)所示:
α表示在存储端检索备份数据的时间占全部数据恢复时间的比率;α主要由备份数据的索引结构和版本序列的组织方式决定。α值越大表示存储端的计算开销越大。
本文主要比较Redo,Diffdo的恢复效率,同时也测试了 COW 数据复制下通常使用的回滚恢复(Undo)效率,3种恢复方式的具体含义如下:
Undo:是指通过回滚方式, 陆续恢复前一个版本数据实现数据恢复;
Redo:是指首先恢复到距离目标时间点最近的全量数据,通过恢复全镜像数据和更新数据版本序列实现数据恢复;
Diffdo:是指本文提出的基于多版本管理技术的差异恢复模式。
图7给出了不同恢复模式下恢复效率的比较。不同恢复模式下,需要恢复的数据量以及备份数据的检索方式不同,导致α有很大的差别。实验中首先选取传输带宽为2MB/s,在Redo恢复模式下,由于恢复的数据量大,RTO值最大。Undo恢复模式由于只恢复变化的数据,恢复的数据量少,RTO值最小。Diffdo恢复的数据量与Undo相同,但是由于引入了数据校验过程,RTO值介于二者之间。在实验环境下,Diffdo模式的RTO值是Redo恢复模式的1/4到1/5左右。图8中进一步给出不同恢复模式下检索时间的占有率情况分析。Redo模式下,数据传输时间占RTO的主要部分,α值很小,占1%左右;但是在Undo和Diffdo恢复模式下需要检索全量快照α值较大。由于Diffdo增加了数据的校验过程,α值最大。根据实验结果可以得出,Diffdo可实现基于时间点的完整数据恢复,是一种适用于低带宽,大数据量的数据恢复场合。
6 结束语
在增量备份数据版本序列中利用版本融合技术可以计算出目标版本全量快照数据,避免通过备份产生全量快照数据。为了降低版本融合的计算负担,本文以逻辑地址连续的数据块作为版本融合单位,可加快版本的融合过程。利用版本融合技术可以实现多种有现实意义的具体应用,如快照检索,多版本差异恢复等操作。但是版本融合技术是建立在所有版本数据的正确性得到保证的条件下实现的,否则任意一个版本数据出现错误都会扩散到融合版本中,为此确保备份数据的可靠性,成为进一步研究的主要方向。
[1] MCKNIGHT J, ASARO T, BABINEAU B. Digital Archiving:End-user Survey and Market Forecast 2006–2010[R]. The Enterprise Strategy Group, 2006.
[2] KEETON K, SANTOS C, BEYER D. Designing for disasters[A].Proceedings of 3rd Conference on File and Storage Technologies[C].USENIX Association, 2004. 59-72.
[3] SANTRY D S, FREELY M J, HUCHINSON N C, et al. Deciding when to forget in the elephant file system[J]. Operating Systems Review, 1999, 33(5): 110-123.
[4] PETERSON Z, BURNS R C. Ext3cow: a time-shifting file system for regulatory compliance[J]. ACM Transactions on Storage, 2005, 1(2):190-212.
[5] SOULES C A, GOODSON G R, STRUNK J D, et al. Metadata efficiency in versioning file systems[A]. Proceedings of the 2nd Usenix Conference on File and Storage Technologies (Fast'03)[C]. Usenix Association, 2003. 43-58.
[6] LIU J N, YANG T M, LI Z H. TSPSCDP: a time-stamp continuous data protection approach based on pipeline strategy[A]. Japan-China Joint Workshop on Frontier of Computer Science and Technology(FCST '08)[C]. 2008. 96-102.
[7] XIAO W J, YANG Q. Can we really recover data if storage subsystem fails?[A]. Proceedings of the 28th International Conference on Distributed Computing Systems (ICDCS 2008)[C]. Beijing: China,2008.597-604.
[8] HITZ D, LAU D, MALCOLM M. File system design for an NFS file server appliance[A]. Proceedings of the USENIX Winter Technical Conference[C]. USENIX Association, 1994. 235-245.
[9] PATTERSON H, MANLEY S, FEDERWISCH M. SnapMirror (R):file system based asynchronous mirroring for disaster recovery[A].Proceedings of the Conference on File and Storage Technologies(Fast'02)[C]. Usenix Association , 2002. 117-129.
[10] FLOURIS M D, BILAS A. Clotho: transparent data versioning at the block I/O level[A]. Proceedings of the 21st IEEE Conference on Mass Storage Systems and Technologies/12th NASA Goddard Conference on Mass Storage Systems and Technologies (MSST’04)[C]. IEEE Computer Society, 2004.315-328
[11] 杨朝红, 宫云战, 桑伟前等. 基于主从异步复制技术的容灾实时系统研究与实现[J]. 计算机研究与发展, 2003, 40(7): 1104-1109.YANG Z H, GONG Y Z, SANG W Q, et al. A primary-backup lazy replication system for disaster tolerance[J]. Journal of Computer Research and Development, 2003, 40(7): 1104-1109.
[12] YANG Q, XIAO W J, REN J. TRAP-array: a disk array architecture providing timely recovery to any point-in-time[A]. Proceedings of the 33rd Annual International Symposium on Computer Architecture(ISCA’06:)[C]. 2006. 289-300.
[13] XIAO W J, REN J, YANG Q. A case for continuous data protection at block level in disk array storages[J]. IEEE Transactions on Parallel and Distributed Systems, 2009, 20(6): 898-911.
[14] AGUILERA M K, KIMBERLY K, MERCHANT A, et al. Improving recoverability in multi-tier storage systems[A]. Proceedings of the 37th Annual IEEE/IFIP International Conference on Dependable Systems and Networks(DSN '07)[C]. 2007. 677-686.
[15] 李旭, 谢长生, 杨靖. 一种改进的块级连续数据保护机制[J]. 计算机研究与发展, 2009, 46(5): 762-769.LI X, XIE C S, YANG J, et al. An improved block-level continuous data protection mechanism[J]. Journal of Computer Research and Development, 2009,46(5): 762-769.
[16] 吴广君, 云晓春, 方滨兴. HCSIM: 一种长期高频Block-Level快照索引技术[J]. 计算机学报, 2009, 32(10): 2080-2090.WU G J, YUN X C, FANG B X, et al. HCSIM: an indexing method for long-lived frequent block-level snapshot[J]. Chinese Journal of Computers, 2009, 32(10): 2080-2090.
[17] RUEMMLER C, WILKES J. Unix disk access patterns[A]. Proceedings of the Winter 1993 Usenix Conference[C]. USENIX Association,1993. 405-420.
[18] KEETON K, SANTOS C, BEYER D, et al. Designing for disasters[A].Proceedings of the 3rd USENIX Conference on File and Storage Technologies[C]. USENIX Association, 2004.59-72.
猜你喜欢
天津科技(2022年5期)2022-05-31
四川劳动保障(2021年7期)2021-12-02
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
现代计算机(2017年7期)2017-04-22
网络安全和信息化(2017年3期)2017-03-10
环境科学导刊(2016年4期)2016-06-30
遥感信息(2015年3期)2015-12-13
网络安全和信息化(2015年11期)2015-03-17
