
国产个人高性能计算机系统研制
2011-07-16 03:46陈国良罗秋明
深圳大学学报(理工版) 2011年6期
陈国良,蔡 晔,罗秋明
国家高性能计算中心深圳分中心,深圳大学计算机与软件学院,深圳518060
高性能计算的一个发展方向是可扩展系统,当前研究人员主要研究千万亿次高性能计算机 (high performance computer,HPC)的关键技术;另一个发展方向是普及型系统,当前科研人员主要研究方向是个人高性能计算机 (personal high performance computer,PHPC).计算规模达千万亿次的高端HPC是服务于国家的战略应用需求,而计算规模在万亿次的低端PHPC则是要普及HPC,服务于国家经济建设.
PHPC适合办公室环境、规模化产品、用户为中心的使用模式,面向生产率的编程模式[1].表1给出了HPC和PHPC的特征比较.面向普及的PHPC提供了更多创新研究的机会,尤其是国产PHPC的研制,涵盖了从处理器设计、基础硬件平台到基础软件平台等各个方面的关键技术.
1999年美国纽约州立大学石溪分校基于量子器件研制的PeT(personal teraflops computer)概念,率先用10万美元设计制造功耗为1 kW的1 Tflops桌面万亿次机.2004年,Ohio Supercomputer Center[7]提出了蓝领计算 (blue collar computing)概念,呼吁研制面向普及的高性能计算机系统.当前市场上商业化的PHPC雏形产品包括由IBM推出的6个双路SMP刀片机群;Sicortex公司推出并定制的6核CPU和互连部件的SoC芯片构成的桌面化系统;中国曙光信息产业有限公司推出的5个双路SMP刀片机群.

表1 从HPC到PHPC的主要变革Table 1 The revolution from HPC to PHPC
中国科学院计算技术研究所、中国科学技术大学和深圳大学在国产PHPC研制方面获得了重大进展.配合国产龙芯处理器的研发进展,先后联合研制了 KD-50[2]、KD-50-E[3],KD-60、SD-1、KD-90和SD-30等国产PHPC系统,其主要目标是逐渐把万亿次高性能计算带到“个人”和“桌面”,实现高性能计算的普及.国产PHPC的发展规划由国家高性能中心与中国科学院计算技术研究所在2007年初联合制订,该规划制定了国产PHPC系统发展的3 个阶段[1],如图 1.

图1 国产PHPC发展路线图Fig.1 The roadmap of domestic PHPC
在保持计算峰值能力为万亿次规模的情况下,通过不断升级和技术创新,降低系统体积、价格和功耗,逐步把万亿次高性能计算带到“个人”和“桌面”,最终实现高性能计算的普及.第1阶段的PHPC定位在功耗6 kW内,价格约100万元人民币,体积为电冰箱大小,其代表产品是KD-50及KD-50-E系统;第2阶段的PHPC定位在功耗3 kW内,价格约50万人民币,体积为洗衣机大小,其代表产品是KD-60及SD-1系统;第3阶段实现功耗2 kW内,价格约25万人民币,体积为微波炉大小的可移动式个人高性能能计算系统,代表产品为KD-90系统.拟进一步实现的SD-30系统为应用PHPC技术设计的一个10万亿次的面向云计算的高效能计算系统,其价格、大小与第一代PHPC相当,但性能提高10倍.
1 国产PHPC主要研究内容及其特点
国产PHPC主要研究内容包括核心处理器设计、体系结构选择、处理单元设计、互连结构和并行编程环境等.
国产PHPC采用具有自主知识产权的国产处理器,其核心芯片设计上实现了技术突破,使适用于PHPC的国产处理器芯片应在性能功耗比上比传统处理器有较大优势.2002年,中国科学院计算技术研究所成功研制龙芯1号通用处理器,其后研制的龙芯2C、2E和2F单核处理器性能逐级跃迁,龙芯2F单核处理器SPEC 2000分值超过500分,达到同主频奔腾4水平,功耗仅约3 W.2009年64 bit 4核龙芯3A高性能通用处理器及2010年8核龙芯3B处理器先后研制成功.龙芯3A处理器采用4核片上SMP(symmetrical multi-processing)结构;龙芯3B进一步在片内集成高达8个处理器核,每个核256 bit向量扩展,主频1 GHz时双精度浮点运算速度128 Gflops,为龙芯3A计算能力的8倍.国产处理器在多核技术上的突破,使单芯片具有很高的计算密度,从而缩减PHPC的体积和功耗,使万亿次的PHPC系统小型化成为可能.
体系结构的选择,单纯的向量机、MPP和CCNUMA这些面向可扩展高性能计算系统的结构并非普及型PHPC所需.随着国产多核通用处理器的研制成功,基于SMP结构的多核处理器通过处理器间直接互连技术组建高性能的CC-NUMA计算节点,在此基础上利用商业化的机群技术进行扩展,是目前国产PHPC发展的最佳体系结构.因此目前采用龙芯多核处理器的国产PHPC使用的体系结构为SMP→CC-NUMA→Cluster的3级并行体系结构.
PHPC处理单元在设计时应具有低功耗、自管理 (不需用户对计算单元进行配置)等特性,出现故障后能一键自愈.单点控制器采用分布式单一系统映像,支持远程调用和监控.操作系统采用单一映像操作系统及有效的透明检查点技术,可支持数月运行的并行应用.
PHPC的互连结构应简单、可靠且易维护.低成本高可靠的千兆以太网是一个较好的选择,可在性能要求高的场合考虑采用定制互连网络或Infiniband等高端互连设备.国产 PHPC系统 KD-50、KD-50-E及KD-60、SD-1采用千兆以太网互连,在KD-90中则采用定制互连结构.
PHPC的并行编程环境应提供以用户为中心的GUI式PC用户体验的使用环境,提供面向程序员的高生产率的“傻瓜式”并行编程工具,提供给非计算机专业人员的易编程方式和通过库调用减少编程难度等.由于PHPC的并行规模不大,在PHPC系统上也可考虑采用软件DSM技术为用户提供便利的全局共享存储编程模式[6].
最后实现的PHPC系统应该具有“三低两高三易”的特性.“三低”指低成本 (性能大于万亿次且保持较低成本)、低功耗 (功耗<2~3 kW,主机电源插头可插在办公室墙面的电源插座上)以及低噪音 (整机噪音 <70 dB,适合办公室环境);“两高”指高效能 (系统具有比PC高一个以上数量级性能,并行应用实际获得的并行效率优于高性能计算机)、高可靠 (整机的可靠性高于高性能计算机);“三易”是指易编程 (有面向大众程序员的并行编程工具,使得非计算机专业人员都可以编写应用程序)、易管理 (零配置零管理且能一键恢复的“傻瓜”式主机)、易应用 (用户使用的体验应和一台PC相仿,既能支持已有应用,还能支持面向大众的其他应用).
2 KD-50与KD-50-E PHPC系统
研发KD-50系统旨在为研制具有低成本、低功耗、低占地、高计算密度特性的国产万亿次高性能计算机系统,为未来研制普适计算的个人高性能计算机打下基础,提高国产高性能计算机的自主创新能力.KD-50系统主要研究内容包括万亿次高性能计算机系统的结构设计,如单个计算节点的结构和整个系统网络互连结构等;系统软件的移植及优化,如Linux操作系统、BIOS(basic input output system)、编译器、千兆以太网卡驱动程序、MPI(message passing interface)消息传递机制、LINPACK数学库等及用户软件的移植与开发,实现若干高性能应用软件的开发、移植与示范应用.
KD-50系统的总体结构如图2.由图可见,该系统各处理单元之间通过节点交换机与机柜交换机互连,每个计算节点通过4个千兆网络接口去连接机柜交换机,机柜交换机之间采用专用的万兆堆叠接口实现高带宽连接,主控服务器为系统提供磁盘存储、系统引导、用户登录和任务调度等功能.
整个KD-50系统以1 U节点作为系统的基本部件,在1个节点内放置12个龙芯2F处理单元,每个处理单元具有1 Gbit内存并内置1个千兆以太网卡.在节点内设置4个4端口千兆以太网交换机,每3个处理单元连接1个交换机,输出1个千兆以太网口.节点内的12个处理单元、4个交换机共用1套电源和散热系统.节点的机箱内布局如图3.

图2 KD-50系统整体结构示意图Fig.2 The architecture of KD-50 PHPC system
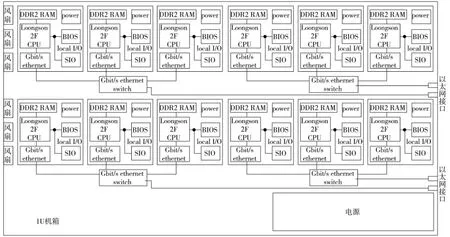
图3 KD-50计算节点 (1U)结构图Fig.3 The architecture of KD-50 1U computing node
KD-50 PHPC高性能计算机的系统软件以开源软件为主,具有兼容性强、易维护及易升级、易使用等特点.处理单元操作系统采用Debian GNU/Linux无盘系统,内核为稳定高效的2.6.18内核.KD-50在系统软件的移植及优化、MPI消息传递机制、LAPACK数学库以及用户软件的移植与开发等做了大量工作[4-5].
KD-50现已在中国37个单位中有良好的运行成效,包括:维也纳第一性原理模拟软件包 (vienna ab-initio simulation package,VASP),在 48个CPU以下时具有较高效率;基于第一性原理的多尺度材料物性模拟软件包 (multiscale material simulation package,MMSP),336个 CPU时加速比可达214.8;扫描电子显微成像模拟ISSEM,336个时加速比可达263.1;32个CPU时,帮助用户并行化的水平井射孔并行计算加速比可达30;cactus在128个CPU时效率可达0.85左右.
KD-50-E型系统是根据用户需求基于KD-50研制的定制型号并安置在用户单位.该系统进一步提升了CPU的主频和存储器的带宽,通过采用具有存储校验 (ECC)功能的内存技术,增强对系统运行状态的监控.
3 KD-60与SD-1 PHPC系统
KD-60系统是在KD-50系统的基础上突破多核瓶颈,采用龙芯3A四核处理器构建的更高计算密集度的个人高性能计算机,是KD-50的后续二期项目,主要依托教育部985二期创新平台的支持.KD-60系统的体积比KD-50系统小50%,与家用洗衣机大小相当,是研制普及型个人高性能计算机系统的第2步规划.KD-60体系结构的主要研究内容包括:单个计算节点的多核SMP结构;多核SMP处理器通过HT总线互连的CC-NUMA结构;系统网络互连结构;计算节点的系统监控与管理结构等.
KD-60系统的总体结构如图4.该体系的处理单元 (PE)之间通过两个48端口机柜交换机互连,每个计算节点通过8个千兆网络接口去连接机柜交换机,两个48口机柜交换机之间采用专用的万兆堆叠接口实现高带宽连接,前置服务器为系统提供磁盘存储、系统引导、用户等录、任务调度等功能.
整个KD-60系统以1 U节点作为系统的基本部件,在一个1 U节点内放置两块计算主板,每块计算主板支持4路龙芯3A四核处理器,4个处理器间可通过HT通道支持互连构成16核的CC-NUMA系统,单计算处理节点结构如图5.1 U节点共支持8个龙芯3A处理单元,每个处理单元具有双通道2 Gbit ECC内存,支持interleaving技术以提高性能.每个处理器单元内置1个千兆以太网卡并通过前置监控面板与机柜交换机互连.因此,KD-60体系结构是一种支持CC-NUMA的SMP机群系统.
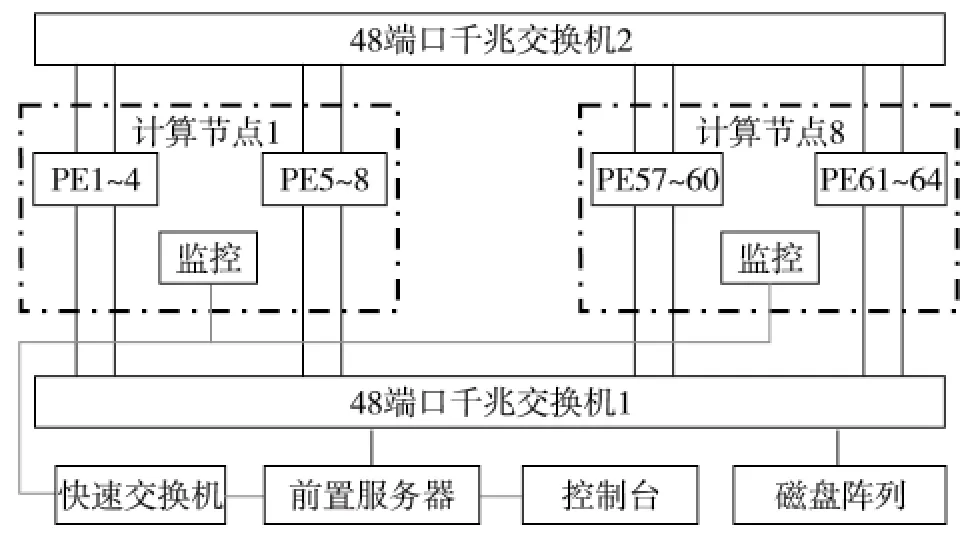
图4 KD-60系统整体结构图Fig.4 The architecture of KD-60 PHPC system

图5 KD60 CC-NUMA 4路计算主板结构图Fig.5 The four-way CC-NUMA computing node of KD-60
KD-60系统采用与KD-50系统类似的软件体系结构,主要针对多核应用对系统软件进行移植及优化,包括多核与多处理器主板的BIOS、支持SMP和CC-NUMA的Linux操作系统、结合龙芯扩展指令的基于GCC技术的编译器及LAPACK数学库等.
KD-60系统能兼容KD-50系统的所有应用,在深入调查相关单位需求后,深圳大学基于KD-60系统设计实现了SD-1系统 (深大1号)并已安装在深圳大学.SD-1系统属于KD-60系统的推广增强型,采用最新龙芯3A3处理器,以龙芯前端服务器替代原PC服务器同时配置了存储阵列、适用商业互连网络应用的Java虚拟机,及定制的OpenMP编译器等.
4 KD-90与SD-30系统
KD-90系统是研制通用普及的个人高性能计算机的第3步,在保持系统性能万亿次的情况下,成本控制在10万元人民币以内,功耗减至1.5 kW,系统体积进一步减小.KD-90系统最终将在家用微波炉大小的空间内实现万亿次计算能力,其功耗更低、性能更强,是一款真正意义上的移动个人高性能计算机.KD-90系统的显著特点在于其计算核心采用了国产8核处理器龙芯3B,实现了一种高效能的3级并行计算体系结构.利用自主BIOS系统、Linux操作系统、开源JVM和国产中间件等支撑软件,该系统实现了在核心芯片设计、基础硬件以及基础软件等关键技术的突破.KD-90系统目前正由中国科技大学、深圳大学及中国科学院计算技术所联合研制,样机预计2011年底研制成功.
KD-90系统采用SMP→CC-NUMA→CLUSTER的3级并行体系结构,为缩小CC-NUAM与CLUSTER的性能差距,采用定制的交换系统,其整体结构见图6.KD-90系统采用5个计算节点 (每个计算节点内部是一个双路的龙芯3B CC-NUMA结构),在定制机箱结构 (宽440 mm、深420 mm、高320 mm)中实现万亿次计算能力,所有计算节点采用定制的48端口千兆以太网交换机进行互连实现高效的3级集群系统,或采用定制的10端口HT交换机实现紧耦合系统互连以实现MPP系统.前者提供了一种兼容现有集群软件的高效率互连方案,后者可通过定制的交换协议进一步提高系统互连性能.这两个交换方案通过在系统底板上的FPGA芯片实现,对FPGA芯片进行不同配置可实现不同的交换方案.与管理用前置服务器的互连采用16端口千兆以太网交换机方案,通过独立的管理网络,与计算网络分开以提高系统性能.交换方案在系统底板上实现,采用Vitesse的VSC7390可管理的24口交换方案.

图6 KD-90系统整体结构图Fig.6 The architecture of KD-90 PHPC system
KD-90与KD-60系统相比较,在采用更高集成密度的8核处理器的基础上,进一步采用了矢量部件加速技术.龙芯3B支持每个核256位向量扩展,当工作主频为1 GHz时,单片龙芯3B的双精度浮点运算速度可达128 Gflops.因而KD-90系统一个很重要的软件工作是底层数学库的移植和优化,以便充分利用龙芯3B的硬件加速部件,提高系统整体性能.KD-90系统与前两阶段的PHPC系统特征比较如表2.

表2 3阶段PHPC系统特征比较Table 2 Comparison of the domestic PHPC systems
SD-30系统是我们拟在KD-90系统研制成功的基础上,结合合作企业天源迪科、金蝶等软件公司对云计算平台的需求,推出的一款国产云计算平台.目前正是中国发展云计算的重要战略机遇期.一方面,从全球来看,云计算尚无统一标准,传统的技术优势在云计算时代不再成为独树一帜,这使我们在云计算技术上有很大的作为空间.另一方面,中国已拥有相对坚实的产业和技术基础,我们在国产PHPC方面展开的工作和取得的成果,实现了核心芯片设计、基础硬件、基础软件等关键技术的突破,为实现国产软硬件一体化的云计算平台发展奠定了基础.
SD-30系统是拟采用KD-90个人高性能计算机在性能、功耗、成本、体积上积累的成熟技术,打造一个10万亿次的国产高效率能云计算平台.并部署在深圳大学,直接服务于深圳的核心企业,做好国产云计算平台的试点工作.
结 语
本研究系统介绍了国产PHPC主要研究问题,以及PHPC的发展历程,给出国产PHPC发展3个阶段代表系统的设计方案.同时介绍了PHPC推广过程中,在用户应用方面取得的成果以及相应的定制系统.正在研制的KD-90系统将是一款真正意义上的移动个人高性能计算平台,它符合PHPC的主要特征,其关键技术和方法值得进一步推广应用和商业化.
[1]孙凝晖,陈国良.PHPC:一种普及型高性能计算机[J].中国科学技术大学学报,2008,38(7):745-752.
[2]张俊霞,张焕杰,李会民.基于龙芯2F的国产万亿次高性能计算机KD-50-I的研制[J].中国科学技术大学学报,2008,38(1):105-108.
[3]张俊霞,李春生,张焕杰.KD-50-I-E:一台增强型高性能计算机[J].中国科学技术大学学报,2009,39(8):894-896.
[4]顾乃杰,李 凯,陈国良,等.基于龙芯2F体系结构的BLAS库优化[J].中国科学技术大学学报,2008,38(7):854-859.
[5]吴 超,孙广中,陈国良,等.KD50增强型上linpack性能测试[C]//2008并行结构、理论和算法会议论文集.合肥 (中国):IEEE出版社,2008:177-188.(英文版)
[6]蔡 晔,史 岗.基于锁CACHE一致性协议的硬件优化策略[J].高技术通讯,2009,19(9):933-938.
[7]美国俄亥俄州超级计算中心.蓝领计算[EB/OL].[2004-07-01].http://www.osc.edu/bluecollarcomputing/.(英文版)
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
北京航空航天大学学报(2022年7期)2022-08-06
净水技术(2022年1期)2022-01-13
科技资讯(2021年10期)2021-07-28
环境卫生工程(2021年3期)2021-07-21
广东通信技术(2020年7期)2020-08-13
个人电脑(2016年12期)2017-02-13
电子制作(2016年19期)2016-08-24
华人时刊(2016年13期)2016-04-05
信息安全与通信保密(2015年9期)2015-11-02
