
基于词典的汉藏句子对齐研究与实现
2011-06-28 06:27洪锦玲
中文信息学报 2011年4期
于 新,吴 健,洪锦玲
(1.中国科学院 软件研究所,北京 100190;2. 中国科学院 研究生院,北京 100190)
1 引言
双语语料库是从事统计机器翻译等自然语言处理研究必不可少的基础资源。构建双语语料库的关键技术之一是对齐,即在双语文本中找到互为翻译的源文和译文片段,对齐的单位包括篇章、段落、句子、短语、词语等,不同的自然语言应用要求做到不同单位的对齐。对于双语而言,构建句子级别的对齐语料库是构建平行双语语料库的基本任务。
目前,藏文信息处理的重心正逐步从文字处理向文本处理转移,汉藏机器翻译/辅助翻译研发都需要大规模汉藏双语平行语料库作为基础。但是构建大规模(百万句对)汉藏平行语料库,仅靠手工对齐是不现实的,因此对汉藏语言句子自动对齐的研究是有意义且必要的。
2 现状分析
英法、英德、汉英等语言的双语句子对齐算法已经较为成熟。句子对齐算法有很多,主要分三大类: 基于长度的算法[1-2]、基于词汇的算法[3-9]和综合使用句子长度与词汇的算法[10-12]。基于长度的句子对齐方法只适用于在没有或只有很少噪声的文本上使用,基于长度方法给出的动态规划框架是解决句子对齐问题的优秀选择,也被之后的众多研究者采用。基于词汇的方法,鲁棒性好,模型选得普遍较复杂,获得词汇对应的过程时间耗费严重,并且抽取互译词对需要大量的已加工好的句子对齐的语料作为训练语料,这对于刚起步的藏文信息处理是不现实的。Haruno和Yamazaki[8]的方法,适用于语法结构相差很大的语言,在算法中只考虑实词之间的匹配,这符合汉藏语言语法结构相差大的实际情况,但这需要对词语进行标注,目前还没有对藏文词语的词性进行整理,没有标注工具来进行这项工作。Ma Xiaoyi[9]的方法利用了词典,取得了很好的对齐效果,这个方法就汉藏语言目前的现状来说是可以借鉴的较好选择。至于其他方法,在有充足语料和资源的情况下,可以进一步尝试,进一步考察这些算法被用于汉藏句子对齐的有效性。
从双语句子对齐问题的本身特点来看,起决定作用的还是译文的对应关系,所得句珠是否准确首先取决于其中词汇的对译程度如何。基于词典的句子对齐充分利用了句对中词汇的互译信息。词汇的对应信息可以通过已有资源来获得,例如词典,也可在文本中通过一定的方法获得,例如通过翻译模型获得。通过词典的方式来获得词汇信息简单直接,但词典信息资源可能不够丰富。通过翻译模型等方法从原文中获得词汇互译的信息,这种方法操作起来较为复杂,时间复杂度较高,需要大量训练语料。
目前,还没有对汉藏句子自动对齐的研究。汉藏句子对齐有其特殊性。基于词典的方法用于汉藏对齐,要解决的第一个问题是藏文分句问题。这个问题在研究的过程中已得到解决,本文主要论述对齐的算法及实现过程,藏文分句问题暂不予讨论。汉藏句子对齐与其他语言的另一不同之处在于汉语和藏文两种语言都需要分词,藏文的一个音节不是一个有独立含义的语义单元,不能被看作词语,藏文词与词之间没有明确的分隔标记,因此藏文和汉语、日语等东方语言相似,同样存在着分词问题。而由于采用不同的分词方法,导致汉语和藏文分词粒度不同,影响了汉藏句子对齐正确率。
下面来具体介绍基于词典的汉藏句子对齐方法及上述问题的解决方法。
3 算法研究与实现
3.1 算法简介
该算法在动态规划的框架下,寻找最优对齐路径。最优的含义是指这条路径上所有句对的总得分最高,每一句对的得分是按照评分函数计算的。评分函数综合考虑了源译文的词语互译个数,句子长度以及句对对齐模式(0-1,1-0,1-1,1-2,2-1,2-2,1-3,3-1)的概率。其中,源译文的互译词语按照出现的频度给了不同的权重,一个词对在句子中出现次数越多,权重越大;而这个词对在整个文本中出现的频率越大,权重越小。
3.2 评分函数
任给一组句子(Si,Ti)定义为
C= {c1,c2,...,cn-1,cn},B= {b1,b2,...,bn-1,bn}
其中ci和bi是分词后的词语。假定有k对互为翻译的词对,分别为(c1′,b1′), (c2′,b2′)…(ck′,bk′), 则(Si,Tj)的相似度定义为:
其中,stf(cm,bm)是(cm,bm)这对互为翻译的词语在句对中出现的次数,由查词典得到的,每查到一个词,值就增加1;
idtf(cm)为cm在Si中出现的总次数与cm在其所在文本中出现的总次数的比值。idtf(cm)起调节权重的作用,一个词语在篇章中出现频率越高,所占权重越小。
|Si|和|Tj|分别是源语言Si和目标语言Tj中的句子数;
LSi和LTj分别是Si和Tj中的句子长度;
为了克服算法将更多句子组合在一起的倾向,引入惩罚因子matching_penalty(|Si|, |Tj|),是对不同对齐模式的惩罚,前面已经提到过,1:1模式的句珠占90%的比例,其他模式根据所占比例给予适当的惩罚,当|Si| = 1 且|Tj| = 1时为1,其他情况为区间[0,1]内的值;
length_penalty则是由长度决定的惩罚因子。
3.3 动态规划递归式
S(i,j)代表从文本开始到第i个源语言句子和第j个目标语言句子的最优路径的得分,Sim(i,j)代表第i个源语言句子与第j个目标语言句子的相似度得分,由评分函数得到。考虑了1-0,0-1,1-1,1-2,2-1,2-2,1-3, 3-1共8种对齐模式。
3.4 算法实现核心流程图
下面给出算法核心部分的伪码和流程图:
MatchSentences(ChineseSentences, TibetanSentences)
{
score <- MatchSentencesWithLexicion(ChineseSentenceWordFrequency, TibetanSentenceWordFrequency)
if(max(ChineseSentencesLength*TibetanToChineseRatio, TibetanSentencesLength ) > 60)
{
computer lengthPenalty
score = score * lengthPenalty
return score
}
}
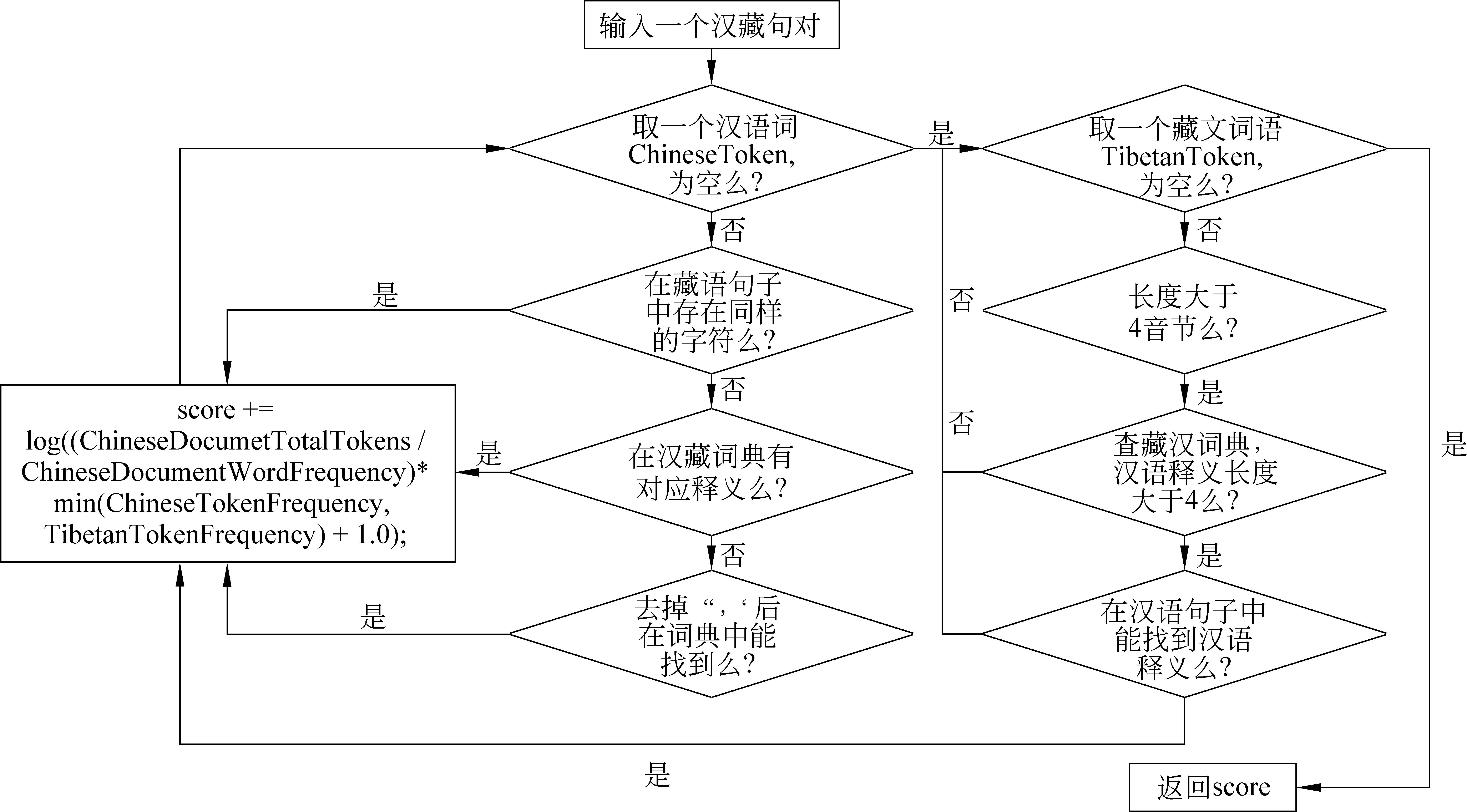
图1 MatchSentencesWithLexicion流程图
3.5 分词粒度问题
由于汉语文本和藏文文本都需要进行分词,这就产生了一个新的问题,汉藏分词粒度不同。
汉语和藏文的分词粒度不同,是因为藏文分词采用的基于词典的最大匹配的方法,造成长词覆盖短词,导致切分粒度过大。汉语分词使用的ICTCLAS采用层叠隐马尔可夫模型,分词的颗粒度较小。
表1是汉语和藏文分词不同的具体的例子。

表1 汉语和藏文分词粒度分词前后比较

续表
分词粒度不同,在词典中便查不到对应词语,会使k值减小,从而使Sim(Si,Tj)减小,句对相似度降低,影响对齐效果。
采用进一步查找藏汉词典的方法来找到互译词对。采用增加藏汉词典的方式,对汉语中未找到对应翻译词语的大颗粒的藏文词语进一步查找藏汉词典,若找到互译汉语,将其拿到汉语原文中匹配,匹配成功,k值增加,从而消除分词粒度不同对句子对齐造成的影响,如图1右半部分所示。
4 实验
根据上述算法,研发了实用的汉藏句子对齐系统。
用准确率(Precision)、召回率(Recall)、F测度值(F-measure)来评价实验结果。
用来评价句子对齐系统的标准对齐语料是先由算法运行出结果,然后由人工校正后得到的。因为藏文句子的判断标准有时不是很明确,可能出现标准语料的结果会与算法给出结果不统一的现象。会使正确率略有下降。
4.1 语料
实验所使用的语料是根据项目需要收集的,均属于政治领域,题材可分为法律、政府公文、伟人著作三种,从中选取部分文件进行实验。法律选取的是《法律汇编》的27篇文档、伟人著作选取的是《江泽民文选》和《毛泽东选集》共18篇文档,政府公文选取的是近几年中共中央的报告和公文共25篇文档,所用语料的汉语版从网上下载得到,藏文版来自中央编译局。
所有语料都整理成以篇章形式存储。首先用篇章对齐工具由人工来篇章对齐生成篇章对齐的XML文件,作为汉藏句子对齐的输入。
篇章对齐XML文件和句子对齐XML文件都以藏文国家标准编码(扩充集A)utf-8编码。
4.2 文本预处理
语料有可能是网上下载,或是OCR识别等等。不经过预处理的语料包含许多噪声数据,使用这样的数据作为对齐输入,会严重影响对齐效果。
主要预处理工作包括: 去除噪声标签,人工修正遗漏的段落分割标记,去掉方正排版标记,编码转换以及字符归一化。
4.3 对词典的评估
实验采用的词典为汉藏词典。这个词典是对汉藏对照词典、藏汉大辞典、藏汉英电子词典合并去重后得到的,共137 873词条。
词典的词汇覆盖率和翻译与译文的吻合度直接影响对齐结果,因此需先对词典作一个评估。
表2是对所使用的词典进行的评价,所用语料为从实验语料中挑选出的5篇文章。可以看出, 不考虑重复出现的词语,所用词典中能够查到的汉语词数所占文章总的汉语词数百分比约为90%;在词典中出现的汉语,不考虑重复出现的词,对应的藏文释义在文章中出现并被正确分词,这样的词语所占的百分比约为55%。
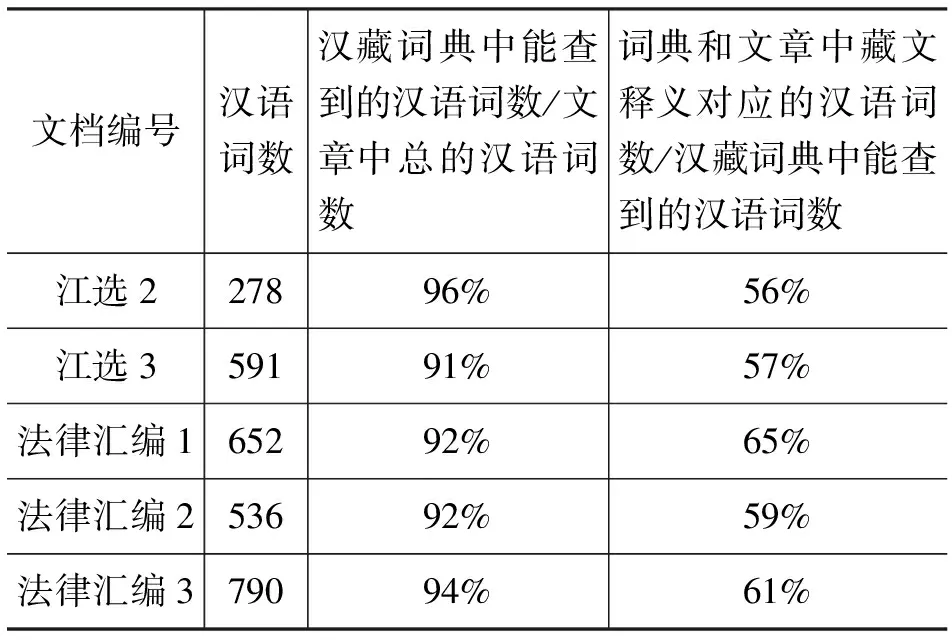
表2 对词典的评价
词典找不到藏文释义的原因有三:
1) 词典自身缺陷。词典的释义不全面,这是因为藏文词语, 一事物多词现象严重, 仅“太阳”一词在不同场合下就有一百多种说法[14],一部词典很难覆盖所有的释义。
2) 翻译是意译的。
3) 分词错误,并且汉语和藏文的分词粒度不同。
4.4 对齐算法参数选择
评分函数中matching_penalty(m,n)是对不同对齐模式(1-0,0-1,1-1,1-2,2-1,2-2, 1-3,3-1)所做的惩罚,实验中matching_penalty(m,n)采用的参数为:
程序会对句子长度相差较大的句子作出惩罚
ChineseLen: 汉语句组长度;
TibetanLen: 藏文句组长度。
c: 单位长度藏文对单位长度汉语的比值, 对600句对统计得到的期望值为1.208。其中,汉语句子按照汉字个数(含标点)计算长度,藏文句子按照音节个数来计算长度。
4.5 结果与分析
对齐是按照篇章来进行的,表3是对每种题材的文档分别累计取得的结果。法律文本的对齐结果最好,平均正确率为82.86%; 伟人著作次之, 平均正确率为80.83%;政府报告最差,平均正确率为78.99%。
将三种题材的文档累计,得到总的实验句对数目为28 697句,得到平均正确率为81.11%,平均召回率为83.86%,平均F测度值为82.47%。
每种类型的文本都有对齐结果好的篇章,和对齐结果不好的篇章。分析个别错误较多的文本,发现影响对齐正确率的因素有以下几点:
1) 格式问题。
分句只能正确切分句子,而不能切分出短语,无论在汉语和藏文文本中都会出现小标题形式出现的短语,而这些地方没有被正确换行,因此文本中这种情况出现较多的话,会影响正确率。

表3 实验结果汇总
从语料中选出3篇文本,将格式校正之前和校正之后的对齐结果做了比较,如表 4所示。
2) 分句错误。尤其是在数字编号的地方较易出错。在汉语标点符号冒号、分号处,藏文的对应不是很明确, 有时可以断句, 有时有连接词不能断句,出错较多。
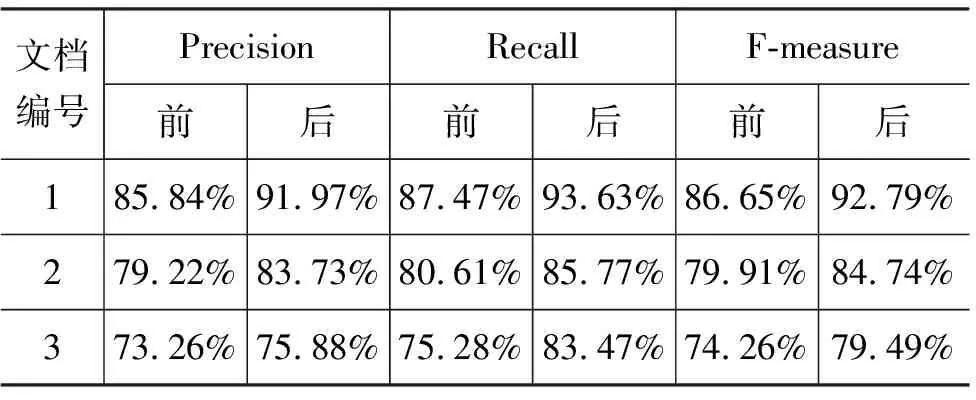
表4 格式整理之前与之后对齐结果比较
3) 翻译是意译的,尤其是口语化比较严重的文章,句中的翻译与在词典中查到的词语不能对应,在伟人著作中出现比较多。
4) 标准对齐是由人工校正得到的,里面有许多人为的判断,句子是否应该断句,有时人为的判断与采用的规则难以统一,即标准句对并不是百分之百正确的,也会影响到正确率。
5 结论
5.1 结论
本文首次对汉藏句子自动对齐进行了探索性研究及实现。采用基于词典的方法来进行汉藏句子自动对齐,该方法借助词典找出句对中的互译词对,低频词语占权重大,高频词语占权重小,利用动态规划框架根据评分函数寻找最优路径,并采用反查藏汉词典的方法解决了汉藏分词颗粒度不同造成的互译词对减少的问题。并对所用词典进行了评价。
实现了一个实用化的汉藏对齐系统,在正确率上仍有很大的提升空间。文献[9]中在将近4 000句的汉英语料上做对齐,正确率达到96.4%,召回率96.3%。汉藏句子对齐的结果和汉英的相比还是有一定差距的。
实验结果和语料的选取有很大关系,本文选取的语料数量上已经足够发现较多的问题,但在领域上不够全面。
5.2 进一步工作
1) 做一部高频词典,文献[9]中仅用4 000词的高频词典就达到96.4%的正确率,采用高频词典不会影响正确率,可以减少查词典的时间,提高效率。
2) 对分句问题做更严谨的规则总结。根据实际中出现的各种错误,不断归纳总结。
3) 提高藏文分词正确率,采用更好的分词方法,消除分词粒度不同的问题。
[1] Brown P F, Lai J C, Mercer R L. Aligning sentences in parallel corpora[C]//Proceedings of 29th Annual Meeting of the Association For Computational Linguistics.Berkeley, CA: ACL, 1991: 169-176.
[2] William A.Gale, Kenneth W.Church. A Program for Aligning Sentences in Bilingual Corpora[J].Computational Linguistics. 1993,19(1):75-90.
[3] M. Kay & K. Roescheisen. Text-Translation Alignment[J].Computational Linguistics 1993,19(1), 121-142.
[4] S. F. Chen. Aligning Sentences in Bilingual Corpora Using Lexical Information [C]//the proceeding of Annual meeting of ACL - 31, 1993:9-16.
[5] Utsuro T, Ikeda H,Yamane M,et al.Bilingual Text Matching Using Bilingual Dictionary and Statistics[C]//Proceedings of the 15th conference on Computational linguistics, volume 2, 1994: 1076-1082.
[6] Melamed I D, Melamed A geometric approach to mapping bitext correspondence[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing,1996: 1-12.
[7] Dagan I, Church K W, Gale W A. Robust Bilingual Word Alignment for Machine Aided Translation[C]//Proceedings of the Workshop on Very Large Corpora, 1993: 1-8.
[8] Haruno, Masahiko, and Takefumi Yamazaki. High-performance bilingual text alignment using statistical and dictionary information[C]//ACL 34, 1996: 131-138.
[9] Ma X. Champollion: A Robust Parallel Text Sentence Aligner[C]//Proceedings of LREC-2006: Fifth International Conference on Language Resources and Evaluation, 2006: 489-492.
[10] DeKai Wu. Aligning a Parallel English-Chinese Corpus Statistically with Lexical Criteria [C]//the proceeding of Annual meeting of ACL-32,1993: 80-87.
[11] Moore R C. Fast and Accurate Sentence Alignment of Bilingual Corpora[C]//Proceedings of AMTA. Springer-Verlag, 2002: 135-144.
[12] Simard M, Foster G F, Isabelle P.Using Cognates to Align Sentences in Bingual Corpora[C]//Proceedings of the Fourth International Conference on Theoretical and Methodological Issues in Machine Translation,1992: 67-81.
[13] 李鹏. 高性能的中英文句子对齐算法及其应用[D]. 清华大学. 2009.
[14] 赵晨星, 杨兵. 藏文信息处理技术发展的广阔前景[J]. 青海师范大学学报(自然科学版),1999,1.
猜你喜欢
西藏研究(2021年1期)2021-06-09
校园英语·月末(2021年13期)2021-03-15
布达拉(2020年3期)2020-04-13
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
西夏学(2019年1期)2019-02-10
西藏大学学报(自然科学版)(2016年1期)2016-11-15
民族大家庭(2016年3期)2016-03-20
中国边疆民族研究(2013年0期)2013-02-13
民族古籍研究(2012年0期)2012-10-27
