
一种融合读者心情要素的新闻推送方法
2011-06-14 03:34路冬媛李秋丹
中文信息学报 2011年3期
路冬媛,李秋丹
(中国科学院自动化研究所 复杂系统与智能科学重点实验室,北京 100190)
1 引言
互联网技术的迅猛发展使得网络新闻数量呈指数级增长。用户在享受海量信息的同时,也面临着如何高效搜寻感兴趣的新闻的困扰。因此,如何充分挖掘新闻的特性,为用户提供更便捷的浏览体验已逐渐成为新闻相关领域的研究热点,有广阔的应用前景。目前,已有大量挖掘新闻内容和时间信息等新闻传统特性的研究[1-2]。基于关键词的检索方式考虑新闻内容与查询词的相关性,方便用户浏览主题相关的新闻。新闻的时间特性也得到利用,例如网站上的时事新闻充分考虑新闻的时效性,便于用户实时了解事态的最近进展。
近年来,随着Web 2.0技术的迅猛发展,带有用户交互特性的网络新闻网站日渐流行起来。以中新网、新浪网为代表的网站,允许用户在阅读新闻后投票表达自己的心情,网站通过对投票结果进行统计,进而了解该则新闻如何影响读者的心情。这种新特性使得网络新闻要素发生了很大的变化,不仅包含传统的内容要素和时间要素,还包含读者心情要素,为用户通过多种途径选择自己感兴趣的新闻提供方便。例如,新浪网提供心情中心*http://news.sina.com.cn/society/moodrank/index.shtml,满足用户分心情浏览新闻的需求。然而,基于用户投票的新闻心情分类需要耗费较长时间,使得研究自动的心情分析方法十分必要。文本情感分析方法是近年来兴起的一个研究方向[3-9]。在新闻领域,文献[10]分析新闻中的情感,利用机器学习的方法将新闻分为正面新闻和负面新闻;文献[11]中作者认为,虽然新闻本身是对事实的客观陈述,但是读者的情绪会受到新闻内容的影响。因此,在对新闻的相关研究中考虑读者心情是必要的。因此文献[12]的作者提出一种基于有序对损失最小化(Pairwise loss minimization)的读者心情排序方法,将一则新闻引起读者的多种心情进行排序。
然而,目前的新闻检索多针对新闻的传统特性,这些方法虽然可以方便用户便捷地浏览主题相关的新闻,但却忽略了用户在检索新闻时对心情因素的要求。基于上述分析,本文在已有工作的基础上,研究同时考虑读者心情、新闻内容和时间信息的新闻推送方法,并基于该方法设计了一个考虑读者心情因素的新闻推送系统,方便用户浏览感兴趣的新闻。该方法首先依据查询词过滤内容不相关新闻;然后根据心情具有负相关性的特点,利用加入负关联约束的半监督排序算法,计算新闻与特定心情的相关性;接着度量查询词与新闻内容的相关性;最后在综合考虑心情相关性和内容相关性的同时,融合新闻时效性的漂移特点,实现一种全新的新闻推送模式。本文通过实验验证了依据读者心情的新闻排序算法的有效性,并结合实例展示了新闻推送系统在帮助用户浏览感兴趣的新闻时具有很好的效果。
本文结构安排如下: 第2节概要介绍新闻推送方法的实现流程,第3节详细介绍该方法的核心部分新闻排序方法的实现步骤,第4节给出心情排序算法的实验结果分析及新闻推送系统的实现。
2 新闻推送方法流程
图1展示了新闻推送方法的流程图。由图中可以看出,该方法主要由索引构建模块、新闻排序模块和用户交互模块三部分组成。
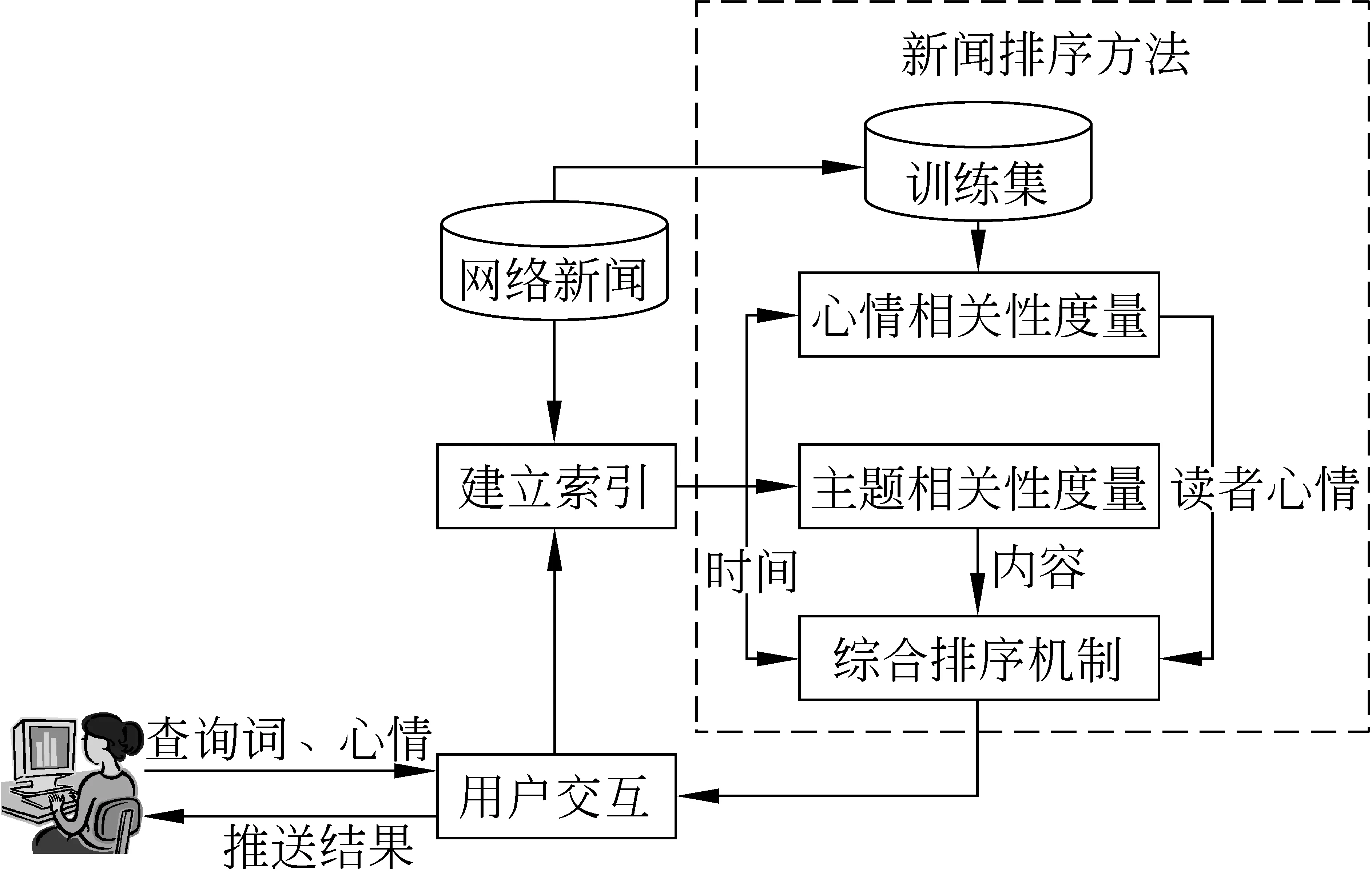
图1 新闻推送方法流程图
本文利用Lucene*Apache软件基金会Jakarta项目组的一子项目[13]为网络新闻建立索引,当用户输入查询词并选择心情,该方法将利用索引结果从新闻源中抽取包含查询词的网络新闻,作为新闻排序方法的输入。考虑读者心情因素的新闻排序方法是新闻推送方法的核心部分。其中心情相关性度量根据用户输入的心情,计算每则新闻引起读者该种心情的强弱;主题相关性度量则根据用户输入的关键词,计算每则新闻与该关键词的主题相关程度;综合排序机制在将以上两种度量值进行线性综合的基础上,考虑新闻重要性的时间漂移,即在考虑主题相关及心情相关的同时考虑时间对新闻的影响。最终的排序结果返回给用户,从而为用户推送综合考虑读者心情、新闻内容和时间信息的新闻。
3 新闻排序方法
3.1 读者心情相关性度量
心情相关性度量新闻引起读者某类心情的强弱,本文利用已带有读者心情标注的新闻作为训练集,采用一种改进的基于半监督的机器学习方法,计算新闻的心情值。
3.1.1 特征抽取
借鉴Chen在文献[11]中使用的特征抽取方法,抽取新闻内容的三种特征:
基本特征: 利用计算技术研究所的开源中文分词软件ICTCLAS*http://ictclas.org/index.html将新闻内容进行分词,每则新闻被表示成若干词语的集合。全部新闻的所有词语构成一个词表,将每则新闻映射到词表上构成n维向量News={t1,t2, ...tn},其中ti表示第i个词语在该则新闻中出现的频率,n表示词表的长度。
相似性特征: 相似性特征包含前缀相似性和后缀相似性,本文以后缀相似性特征的计算方法为例进行说明,前缀相似性特征的计算方法类似。后缀相似性是指将两个句子从句尾开始逐字比较,最长的共有字符串的长度作为后缀相似性值C(s1,s2)。后缀相似性特征的计算方法如下:
(1)
其中suffixi(s)表示句子s在心情ei上的后缀相似性特征;sk表示训练集中的第k句,Weight(sk,ei)表示sk在心情ei上的权值。(该权值是用户标注的结果,其计算方法将在实验部分介绍)。
情感词典特征: 在中文表达中词语是具有实际含义的最小单位,某些词语无需上下文便可以引起人们的某种情绪。鉴于词语与心情之间存在某种映射关系,我们建立情感词典,用三元组的形式储存这种映射关系: <词语,心情,映射权值>。映射权值利用逐点互信息[14](Pointwise Mutual Information: PMI)计算如下:
w(t,e)代表词语t与心情e的映射权值;c(t,e)表示词语t与心情e的共现频率;P(t,e)=c(t,e)/N,N为词语总数;P(e)=c(e)/N,c(e)为心情e出现的频率;P(t)=c(t)/N,c(t)为词语t出现的频率。将每则新闻表示成词语的集合后对每个词语查询情感词典,各维心情上的映射权值分别求和得到与心情数相同维数的情感词典特征。
3.1.2 排序算法
我们将心情与新闻的相关性度量问题描述为一个排序问题,即利用对新闻依据心情强弱进行排序,计算新闻心情相关性度量值。通过大量观察发现,每则新闻引起读者的各类心情之间并不相互独立,某两类心情之间会存在负关联的关系。如图2所示,横轴表示随机抽取的60则新闻,纵轴表示根据用户心情投票统计的愤怒和搞笑两类心情的权值。可以看出,愤怒权值较高处搞笑的权值较低,反之亦然。这暗示,如果某则新闻与愤怒的相关性高,则其与搞笑的相关性低。通过对大量新闻数据进行统计,本文定义三种存在负关联关系的心情对:
• 愤怒←→搞笑
• 搞笑←→难过
• 感动←→无聊
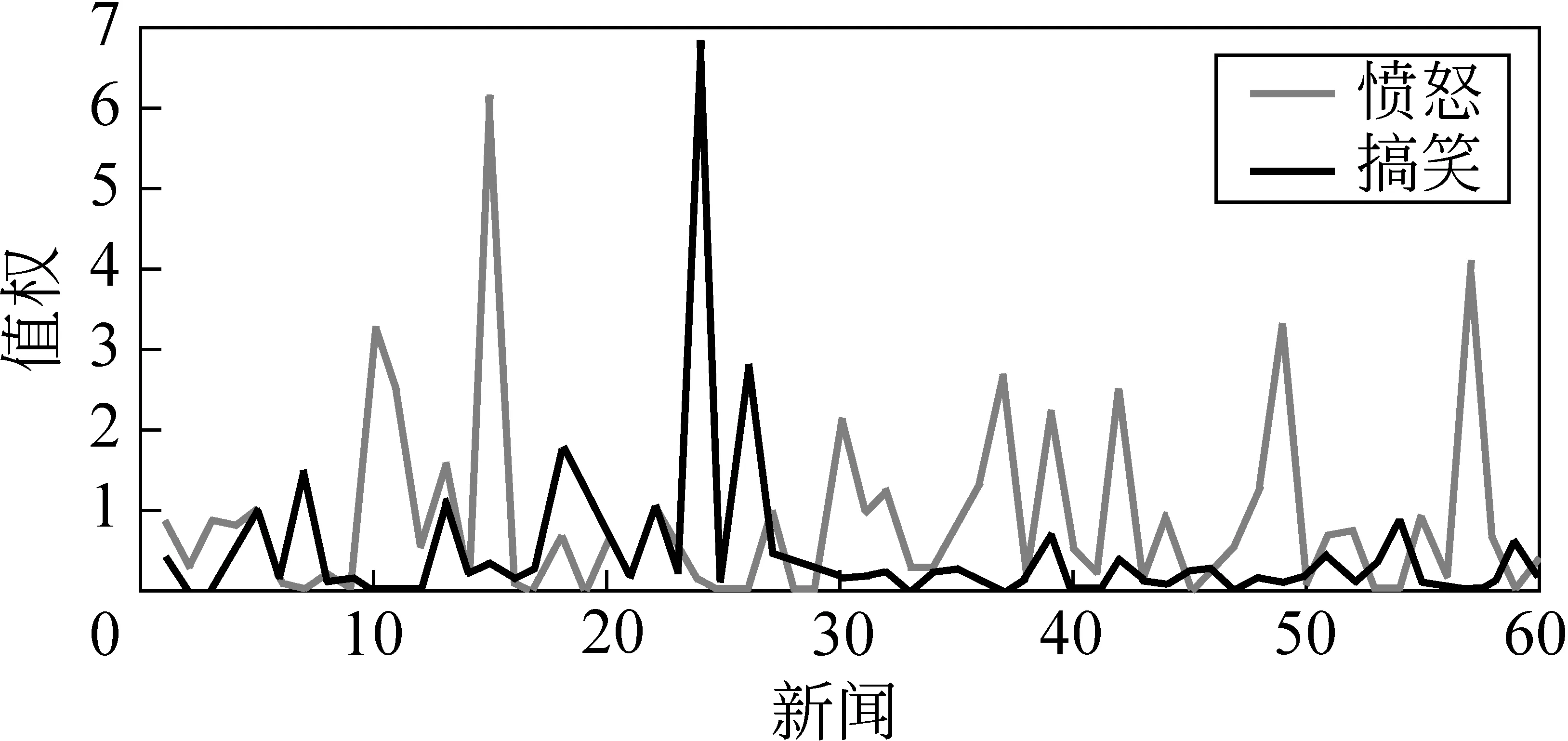
图2 60则新闻上愤怒和搞笑两类心情的权值对比
基于Hoi等人提出的SSER(Semi-Supervised Ensemble Ranking)算法[15],结合新闻心情要素特点,本文设计一种考虑负相关约束的排序算法,实现步骤如下:
步骤一: 利用训练集的人工标注结果计算心情ei下的关联矩阵Ai(Relevance Matrix)
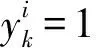
步骤二: 求解优化问题
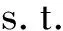
(3)
εi≥0;εj≥0;γ≥0;
i=1,...,N;j=1,...,M;k=1,...,Di

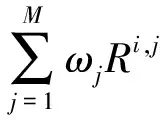
步骤三: 计算读者心情相关性
(4)
其中Emoi(nk)表示新闻nk在心情ei下的度量值,z(nk,nl) 表示有序对
3.2 主题相关性度量
新闻主题相关性根据用户查询词与新闻内容关联性进行度量。本文采用Lucene排序的度量方法:
其中score(q,n)表示查询词q与新闻n的相关性度量值;q表示一次查询,其中可以包含一个或多个查询词{ti};co(q,n)计算新闻n中包含查询词的个数,即当一次查询包含多个查询词时,新闻n中包含的t越多co(q,n)值越高;tf(t)表示n中t出现的词频;idf(t)表示反转文档频率;Boost(t.field)表示t出现的领域权重(本文包含题目和内容两个领域,题目域的权值高于内容域的权值);IN(t.field)是标准化因子。
3.3 综合排序机制
融合读者心情因素的新闻推送机制应满足如下要求: 1)根据用户选择的心情,与此心情越相关的新闻权值越高,即排序应越靠前;2)根据用户输入的查询词,与此查询词内容越相关的新闻权值越高;3)时效性是新闻的重要特性之一,由于人们往往更关注时间较近的新闻,因此与当前时间越近的新闻权值应越高,排序应越靠前。根据新闻推送机制应满足的要求,本文设计一种融合读者心情因素的新闻推送方法,在读者心情相关性度量值和新闻主题相关性度量值上综合时间信息,计算公式如下:
其中,RW(q,ei,nk)表示用户输入查询词q并选择心情ei时,新闻nk的综合相关性度量值。该方法利用参数α(0~1之间)调整读者心情相关性和新闻主题相关性所占的权重;同时假设新闻的重要程度会随着时间增长呈指数减弱,因此引入时间衰减函数,tk-t表示新闻nk的发生时间与当前时间的差值;β决定新闻重要程度随时间的衰减速率。
4 实验及结果
4.1 数据描述
实验的语料集来源于新浪新闻网站的社会新闻,我们收集2009年1月~5月的新闻作为训练集,6月的新闻作为测试集。对每则新闻下载新闻标题,新闻内容,新闻时间,和读者进行心情投票的结果。读者心情度量方法中,本文仅利用新闻标题信息,因为通过大量地浏览新闻数据发现,新闻标题是对新闻内容的高度概括,其用词客观准确,可以排除新闻内容中大量噪声对分类器的影响。鉴于新浪网所划分的8类心情之间存在模糊性和重叠性,本文通过对相似心情进行合并将心情分为5类,合并方式及数据集的基本信息如表1、表2所示。
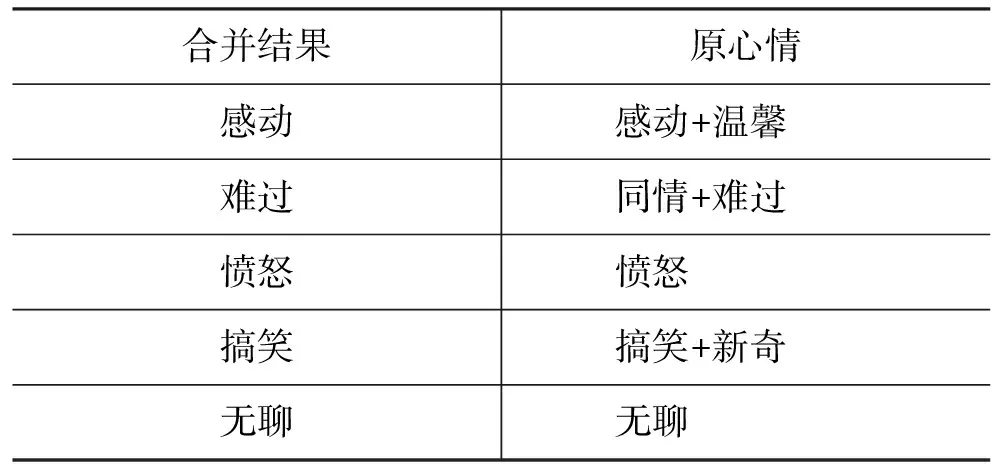
表1 心情合并方式
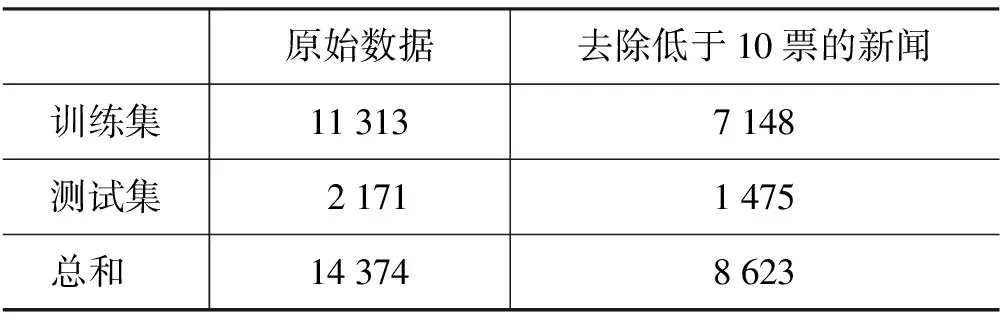
表2 数据集数据量统计
利用用户的心情投票结果对每则新闻自动进行两种标注: 心情类别和各类心情下的权值。前者用于建立情感词典,后者用于训练改进的排序支持向量机,具体方法如下:
• 心情类别: 首先按照表1的规则合并相应心情类别的投票数,然后将投票数最多的一类心情作为该则新闻的心情类别。
• 各类心情下的权值: 同样先按照表1的规则合并相应心情类别的投票数,然后综合考虑绝对票数和相对票数计算权值:
其中,Weight(nk,ei)表示新闻nk在心情ei上的权值;votei(nk)表示新闻nk在心情ei上获得的投票数;ξ,φ为经验参数,共同决定绝对票数与相对票数的权重,当ξ取值越大、φ取值越小时,相对票数所占的权重越大,反之亦然。本文为使得绝对票数与相对票数的权重相当,选取ξ=100,φ=10。基于该权值,可以为数据集中的新闻依据某种心情进行全排序,排序结果用于训练改进的排序支持向量机。
4.2 实验结果分析
4.2.1 评测指标
本文采用信息检索领域中广泛使用的评价指标NDCG@k(Normalized Discounted Cumulative Gain)[16]对算法进行评测。NDCG为排名靠前的检索结果赋予较大的权重,因此适合作为新闻检索结果的评价指标。
公式中IDCG@k为查询相关的归一化常数,以使理想排序结果的NDCG值为1,k为待评价的检索结果数,reli表示第i个结果的相关性值。
4.2.2 参数选择
本文的排序算法中,有四个重要参数需要设定,分别是心情排序优化问题中的惩罚系数c,正则化系数γ,和综合排序机制中的权值参数α,β。
惩罚系数c和正则化系数γ共同影响心情相关性算法的性能,为获取最佳推送结果,我们在训练集上使用四折交叉验证(four-fold cross-validation)的方法,从备选值c={2-8, 2-7,...,20,...,27,28}和γ={1, 1.5, 2,...,5}中选取最优的系数值。通过实验发现,惩罚系数c的变化对算法性能的影响较小(本文选取c=1),正则化系数γ对算法性能的影响较大。图3所示为使用心情相关性度量算法对新闻依五类心情分别排序的平均评价结果。由于正则化系数γ决定查询信息,即半监督项对优化问题作用的权重。当γ过大时,会忽略新闻自身的特征对心情排序的影响,而当γ过小时,则会忽略查询信息对排序结果的影响,我们发现在γ=2.5处,算法取得最优效果。因此,本文其余实验中选取γ=2.5。
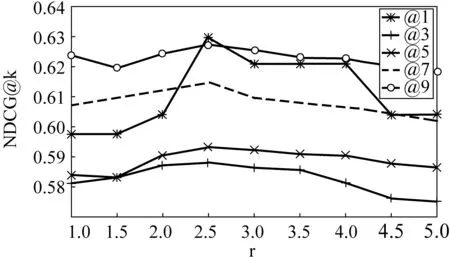
图3 正则化系数γ对算法性能的影响
综合排序机制中的权值参数α,β决定三种因素(读者心情,主题相关性,时间信息)对最终新闻推送结果的影响。当α(取0~1之间的值)取值接近1时,读者心情相比于主题相关性占有更大的权重,相反,当α取值接近0时,主题相关性则更重要。本文中,我们令心情因素与主题因素在最终的推送结果中所占的权重相当,因此选取α=0.5。β决定新闻的重要程度随时间的衰减速率,β取值越大衰减越快,本文根据经验选取β=2.
4.2.3 依据读者心情的新闻排序结果分析
依据读者心情的新闻排序算法是本文研究的重点,本节通过与三种代表性的Baseline方法进行比较,验证算法性能。
• Baseline1: Ranking SVM文献[16]是有监督机器学习中的一类经典算法,它将排序问题转化为有序对的分类问题。
• Baseline2: SER(Supervised Ensemble Ranking)方法[15]不考虑查询信息对结果影响,即忽略半监督项。
• Baseline3: SSER(Semi-Supervised Ensemble Ranking)方法文献[15]即为Hoi等人提出的对RSVM方法的改进方法。
在对Baseline方法的参数设定中,RSVM方法通过四折交叉验证选取最优的惩罚系数c=2;SER方法与SSER方法的参数选取与本文相同。表3所示为各心情下四种排序算法的结果比较。从中可以看出,本文提出的加入负关联心情约束的排序算法优于其他三种Baseline方法。其中,心情“搞笑”下本文的算法获得较明显的改进效果,心情“愤怒”下,算法较RSVM方法和SER方法改进较大,而与SSER方法相比无明显优势,甚至在某些k值点不及SSER算法。通过进一步分析数据特点,我们发现能够引起读者“愤怒”情绪的新闻往往含有明显的特征,例如含有诸如“殴打”等词语,因此即使使用最基本的RSVM方法,相比其他心情也能获得较理想的排序结果。而在心情“搞笑”下,新闻中则无类似的明显特征,因此使用加入负关联心情约束的排序算法,结果较好。可见,本文的排序算法对无明显心情特征的新闻排序效果较好。此外,从实验结果中我们还发现,k值较小时,本文算法有较好效果。这说明,改进的排序算法能够更准确地发现引起读者强烈情感的新闻。考虑情感之间的负相关性不仅可以提高排序精度,还可以更准确地获取情感最强烈的新闻。
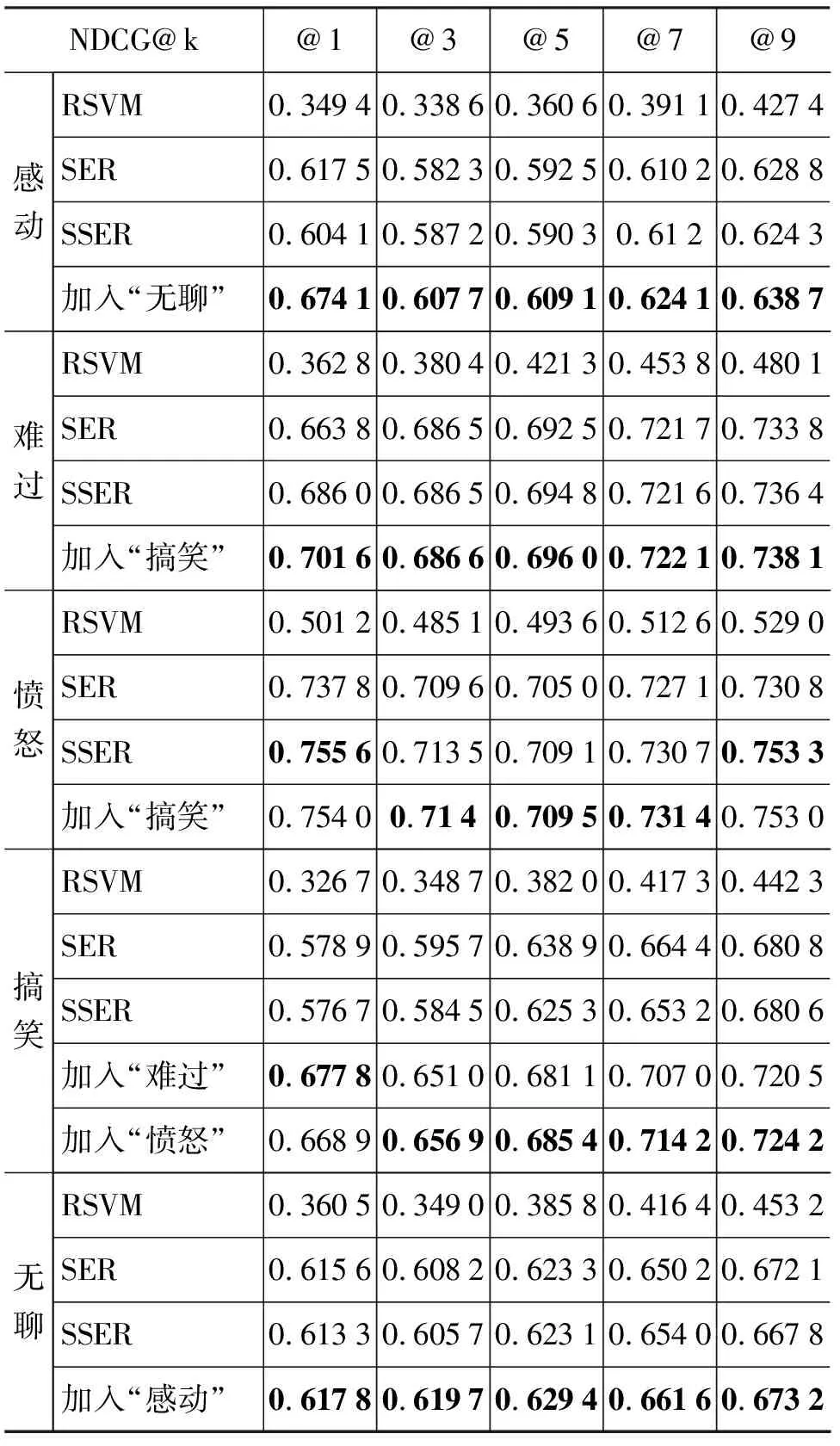
表3 不同心情排序算法的NDCG结果比较
4.2.4 新闻推送结果示例
我们基于Lucene框架,利用本文提出的考虑读者心情的新闻推送方法,搭建新闻推送系统平台。图4展示了系统界面并给出一个推荐实例。在该实例中,用户希望浏览一些令人感动的与大学生相关的新闻。在检索框中输入查询词 “大学生”并选择心情“感动”,系统推荐的新闻以超链接文本的形式显示在页面上。从结果可以看出,系统推荐的新闻不仅在主题上和大学生相关,而且内容的确令人感动。为分析考虑心情因素对新闻检索结果的影响,我们进行如下实验,仅考虑新闻的内容与时间信息,即令综合排序机制中的参数α=0,则前两则新闻为“大学生返乡当农民,当年收益达4万元”、“大学生遭开除后为实施报复专偷母校”。显然,该推送结果无法满足用户查询令人“感动”的新闻的需求。由此可见,融合心情要素的排序结果可以帮助用户更便捷地浏览自己感兴趣的新闻。
结束语
Web2.0技术的发展使得网络新闻要素发生了很大的改变,不仅包含新闻内容和时间,还包含心情要素等用户交互信息。这些新闻特性为用户通过多种途径搜索感兴趣的新闻提供方便。为了更有效地帮助用户便捷地浏览新闻,本文提出一种融合读者心情要素的新闻推送方法,该方法集成读者心情相关性、查询词与新闻内容相关性和重要程度随时间漂移性三种新闻特性,方便用户依据心情浏览主题相关的最新新闻。鉴于目前的工作主要针对社会新闻,未来工作在进一步深入测试系统性能的同时,将针对其他类别的新闻开展研究工作。

图4 新闻推送实例(输入查询词“大学生”,选择心情“感动”)
[1] 宋锐,林鸿飞,杨志豪. 面向中文新闻领域的移动摘要系统[J]. 中文信息学报,2008,22(1): 87-92.
[2] 杨伟杰,戴汝为,崔霞. 一种基于信息检索技术的网络新闻影响力分析方法[J]. 软件学报,2009,20(9): 2397-2406.
[3] 周立柱,贺宇凯,王建勇. 情感分析研究综述[J]. 计算机应用,2008,28(11): 2725-2728.
[4] 姚天昉,程希文,徐飞玉,汉思·乌思克尔特,王睿. 文本意见挖掘综述[J]. 中文信息学报,2008,22(3): 71-80.
[5] 徐琳宏,林鸿飞,赵晶. 情感语料库的构建和分析[J]. 中文信息学报,2008,22(1),116-122.
[6] 王素格,李德玉,魏英杰,宋晓雷. 基于同义词的词汇情感倾向判别方法[J]. 中文信息学报,2009,23(5): 68-74.
[7] 朱嫣岚,闵锦,周雅倩,黄萱菁,吴立德. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报,2006,20(1): 14-20.
[8] 唐慧丰,谭松波,程学旗. 基于监督学习的中文情感分类技术比较研究[J]. 中文信息学报,2007,21(6): 88-108.
[9] K. Eguchi, V. Lavrendko. Sentiment retrieval using generative models[C]//Proceedings of Empirical Methods in Natural Language Processing (EMNLP), Sydney: 2006, 345-354.
[10] 徐军,丁宇新,王晓龙. 使用机器学习方法进行新闻的情感自动分类[J]. 中文信息学报,2007,21(6): 95-100.
[11] Kevin Hsin-Yih Lin, Changhua Yang, Hsin-Hsi Chen, Emotion Classification of Online News Articles from the Reader’s Perspective [C]//Proceedings of the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Washigton: 2008: 220-226.
[12] K. HY.Lin, H.H. Chen. Ranking reader emotions using pairwise loss minimization and emotional distribution regression [C]//Proceedings of Empirical Methods in Natural Language Processing (EMNLP), Honolulu: 2008: 136-144.
[13] Jakarta Lucene online document [EB/OL]. [2008-06-05]http://lucene.apac-he.org /.
[14] K. W. Church, P. Hanks, Word association norms, mutual information and lexicography [C]//Proceedings of the 27thAnnual Conference of the ACL, New Brunswick: 1989: 76-83.
[15] Steven C. Hoi and Rong Jin. Semi-supervised ensemble ranking[C]//Proceedings of 23rdAAAI Conference on Artificial Intelligence, Chicago: July 2008: 634-639.
[16] T. Joachims. Optimizing search engines using clickthrough data[C]//Proceedings of 8thACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Edmonton: 2002: 133-142.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
上海文化(文化研究)(2022年3期)2022-06-28
名家名作(2021年4期)2021-05-12
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
科普童话·学霸日记(2020年1期)2020-05-08
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
小天使·一年级语数英综合(2019年2期)2019-01-10
江苏通信(2018年4期)2018-12-04
自动化学报(2017年7期)2017-04-18
