
广义线性滤波模型在非寿险准备金评估中的应用
2011-05-18 08:06:18赵立戎
统计与决策 2011年14期
赵立戎
(中国人民大学 统计学院,北京100872)
0 引言
对于一个广义线性模型(GLM),按照贝叶斯统计推断的理论,假设GLM的参数向量服从某个形式已知的先验分布,其后验分布就是该参数向量关于观测数据的条件分布,通过计算参数向量的后验分布解决参数估计问题。在某些特殊情况如一元离散指数族下,能够找到自然共轭的先验分布,因而容易计算出后验分布的具体形式,此结论在多元离散指数族中并不成立。因此在一般情况下,贝叶斯GLM的后验分布形式很难直接计算,因而产生了很多近似计算的方法。例如West et al.在保留自然参数服从自然共轭先验分布的约束条件下给出了几种参数变换的形式。Fahrmeir和Kaufman研究了估计后验分布的模。近年来还有不少利用MCMC方法处理贝叶斯GLM问题的文献。在精算领域的应用如Scollnik及de Alba等人的研究。MCMC方法便于操作,但得不出后验分布的具体形式。在实际应用中,近似的解析法虽然精度高但计算过于复杂,而随机模拟方法虽然便于实现却又得不到分布形式。
Greg Taylor[4]利用泰勒展开式,在多元离散指数族下构造出后验分布的二阶近似解析表达式,使其满足与贝叶斯GLM的先验分布同分布族的性质,并能够进一步产生迭代公式,生成一个与Kalman滤波算法类似的GLM滤波算法,可推广至动态广义线性模型(DGLM)的参数估计。这种利用二阶近似的GLM滤波算法不同于复杂的传统解析处理方法,通过使用典则联结或伴随典则联结函数能够简化计算过程。
在非寿险准备金评估中,通常使用的确定性模型或随机性模型都假设一个不随时间变化的参数向量,它们都属于静态模型。当保险公司内部或外部环境随时间发生变化时,如果考虑模型参数及参数结构随时间发生变化,就可以使用动态模型,如精算中常用的Kalman滤波模型,张连增[6]研究了Kalman滤波法在非寿险未决赔款准备金评估中的应用。Kalman滤波模型的应用局限性在于假设观测数据服从正态分布,不能处理其他常用分布(如泊松分布、伽玛分布等)类型的数据。
本文将从动态模型的角度出发,探讨非寿险未决准备金评估问题:应用广义线性滤波模型,基于离散指数族分布,建立关于赔付数据的动态广义线性模型;通过对流量三角形数据逐期(事故年或日历年)迭代,实现模型的参数估计和准备金评估。
1 广义线性滤波模型
1.1 贝叶斯GLM的二阶近似法
GLM 的标准结构为:Y=h-1(Xβ)+ε,其中 Y=(Y1,…,Ym)T是观测数据向量,各个Yi(i=1,…m)之间相互独立且服从离散指数族(EDF)中的分布,EDF分布的对数似然函数形如:L(yi:θi,λi,b,k)=λi[yiθi-b(θi)]+k(λi,yi),β=(β1,… ,βq)T(q≤m)是参数向量,X是m×q阶设计矩阵,h为联结函数,ε是一个随机误差向量。可见,Yi具有相同的分布形式,但位置参数θi和尺度参数 1/λi可以取不同的值。 E(Y)=μ(θ)=h-1(Xβ)。
使用典则联结函数 h=(b′)-1时,模型形式简化为 θ=Xβ,位置参数就等于线性响应部分。不失一般性,以下讨论均在典则联结函数下进行。忽略不含自然参数θ的项,Y的对数似然函数简化为 L(y;β,Λ)=yTΛXβ-1TΛb(Xβ),其中 Λ=diag(λ1,…,λm),1表示所有元素均为1的m阶向量。假设β的先验对数似然形式为 π(β)=Mβ-(Mβ),则 β 的后验对数似 然 形 式 为 L (β|y,Λ)=(w0TM+yTΛX)β-[n0Tb (Mβ)+1TΛb(Xβ)],其中M是一个q阶非奇异方阵。对后验似然中的每一项分别按照泰勒展开式在β=β0处展开,最多取到二次项,忽略与β无关的零次项,再通过一系列正交变换,可以构造形如PMβ的近似后验似然,其中P表示一个线性变换,w1和n1分别对应w0和n0。为了方便计算,可选定β0的取值为满足 h-1(Mβ0)=Eβ[h-1(Mβ)]。 通过二阶近似变换后,参数向量β的先验似然与后验似然具有相似的形式,且存在以下替代关系:w0→w1,n0→n1,M→PM。 因而,在 β 的先验似然和后验似然之间形成了一种递推关系。值得注意的是,对于非典则联结的其他联结函数,变换公式要复杂的多,递推关系也未必成立。常用的分布及典则联结函数有正态分布和单位联结函数,伽玛分布和倒数联结函数等。
对于势方差函数, 有 h (μ)=μ1-p/(1-p), 不满足对任意p∈(-∞,+∞)成立,因而可能使得 b(Xβ)在某些值上没有定义。考虑到典则联结函数存在的这种问题,Taylor[4]定义伴随典则联结函数(companion canonical link)h*=b◦(b′)-1,并且在伴随典则联结函数下得到了与使用典则联结函数时一致的似然函数递推关系,仅其中涉及参数的形式发生一定的变化。常用的分布及伴随典则联结函数有伽玛分布和对数联结函数等。
1.2 动态广义线性模型
考虑参数向量β随时间随机变化,则GLM模型形式变为:Y(t)=h-1(X(t)β(t))+v(t),其中 Y(t)是 Y 在 t时刻的观测数据向量,设计矩阵 X(t)、参数向量 β(t)和误差向量 v(t)都表示t时刻的相应状态。类似状态空间模型的定义,上式为观测方程,还需定义参数演化的状态方程:β(t+1)=Φ(t+1)β(t)+r(t+1),其中 Φ(t+1)为已知矩阵,r(t+1)是均值为 0 的随机干扰项,且与 y(1),…,y(t)及 β(0),…,β(t)相互独立,记Var[r(t+1)]=R(t+1)。允许参数向量的维度随时间变化。这样就构成了动态广义线性模型(DGLM)的基本形式。在实际应用中,t可以选为事故发生年,也可以选为日历年。
利用贝叶斯二阶近似法得到的先验似然与后验似然之间的递推关系,可以在保留分布形式的同时通过不断变换参数实现多次贝叶斯GLM的模型估计。这就形成了一个与Kalman滤波类似的贝叶斯GLM序列,可以称之为贝叶斯GLM滤波或广义线性滤波,利用这一滤波算法实现对DGLM各时刻的参数估计。
类似状态空间模型的定义,用记号t|t-j表示在t时刻利用t-j时刻之前(包t-j含时刻)的全部信息所进行的估计。使用典则联结函数时,似然函数的形式转变为:
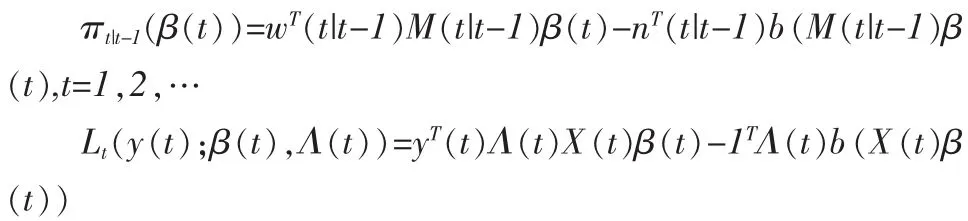
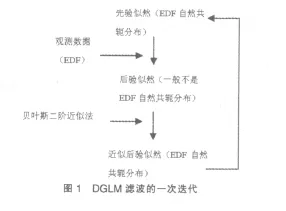
为了估计 E[h-1(M(t|t)β(t)|Y(t))]和 E[h-1(M(t+1|t)β(t+1)|Y(t)]的值及对应的方差,在估计过程中应用贝叶斯GLM二阶近似的结论,随着观测数据向量 y(1),y(2),…逐渐引入模型,对β(▯)的均值及方差的估计值逐步递推调整,即产生一个滤波,滤波的起始点是对 E[β(1)]和 Var[β(1)]的先验估计值。在应用广义线性滤波模型评估非寿险准备金时,初始值的选定依赖于对经验数据等先验信息的分析和精算师的主观判断,随着迭代步骤的增加,初始值对整个计算结果的敏感性将越来越低。在滤波迭代的过程中,每一步迭代都是从 E[h-1(M(t|t-1)β(t))|Y(t-1)]和 Var[h-1(M(t|t-1)β(t)|Y(t-1))]通过一系列运算公式递推到 E[h-1(M(t+1|t)β(t+1))|Y(t)]和 Var[h-1(M(t+1|t)β(t+1)|Y(t))],t=1,2…,即从利用t-1时刻之前的信息对t时刻的估计值前进到利用t时刻之前的信息对t+1时刻的估计值,直至迭代到流量三角形的最近一期观测值为止。对于一般的贝叶斯GLM,先验似然πt|t-1属于EDF自然共轭分布族,其后验似然πt+1|t通常并不属于同一分布族,只有在迭代过程中应用贝叶斯二阶近似法,用同属EDF自然共轭分布族的二阶近似式代替原后验似然,贝叶斯GLM滤波迭代才能够实现递推。DGLM的滤波迭代的逻辑结构如图1所示。
Taylor[4]将Kalman滤波算法从动态一般线性模型推广到DGLM,保留了模型的线性系统成分。应注意的是,当使用正态分布和单位联结函数时,广义线性滤波就等于Kalman滤波,可见Kalman滤波是广义线性滤波的一种特殊情况。广义线性滤波模型的一般形式及其实现过程仍是比较复杂的,但对于几种特殊分布(如正态分布、泊松分布、伽玛分布)以及使用典则联结或伴随典则联结函数的情况,滤波迭代公式能够大为简化,因此在解决非寿险准备金评估问题时具有实际应用价值。广义线性滤波模型对各期参数的估计是基于迭代的过程,因此各期参数估计值比一般GLM的参数估计值较平滑,能够降低经验数据中的异常值对准备金估计结果的影响。在早期赔付数据缺失或观测数据出现异常值的情况下,应用广义线性滤波模型能够改善未决赔款准备金的估计结果。
2 伽玛广义线性滤波模型
在GLM中假设误差项服从伽玛分布,使用对数联结函数(伴随典则联结),即 b(θ)=-log(-θ),h(u)=logu。 建立伽玛广义线性滤波模型如下:
观测方程:Y(t+1)=exp{X(t+1)β(t+1)}+v(t+1)
状态方程:β(t+1)=Φ(t+1)β(t)+r(t+1)
为了简便,将滤波迭代主要关注的两个量记为:
Θ(t|t-j)=E[exp{-M(t|t-j)β(t|t-j)}]
Γ(t|t-j)=Var[exp{-M(t|t-j)β(t|t-j)}]
其中矩阵 M(t|t-j)是使参数方差阵 Var[β((t|t-j)]对角化的正交矩阵,即使得 M(t|t-j)TQ(t|t-j)M(t|t-j)=Var[β((t|t-j)]成立,Q(t|t-j)是对角阵。
首先需要选定滤波迭代的初始值,即为E[β(0|0)]和Var[β(0|0))赋先验值。其他需要选定的输入值还包括伽玛分布的参数 Λ(t),可以利用观测数据 Y(t)的变异系数(CV)来计算(λ=1/CV2)。矩阵Φ(t)根据模型参数结构随时间变化的规律确定。随机扰动变量的方差R(t)根据精算师的判断人为选取,通常选为一个常矩阵,即R(t)=R。
伽玛广义线性滤波迭代计算的具体步骤如下:
第一步,计算 E[β(t|t-1)]=Φ(t)E[β(t-1|t-1)]
Var[β(t|t-1)]=Φ(t)Var[β(t-1|t-1)]ΦT(t)+R(t)
近似计算:
Θ(t|t-1)=[I+0.5×Q(t|t-1)]×exp{-E[M(t|t-1)β(t|t-1)]}
Γ(t|t-1)=Q(t|t-1)DIAGexp{-2E [M(t|t-1)β(t|t-1)]},
定义 N (t|t-1)=[Γ(t|t-1)]-1[I+0.5×Q(t|t-1)]DIAGexp{-M(t|t-1)E[β(t|t-1)]}
W(t|t-1)=N(t|t-1)Θ(t|t-1)
则 β (t|t-1)=-M(t|t-1)Tlog(N(t|t-1)-1W(t|t-1))。
定义 B(t|t-j)=-DIAGexp{-M(t|t-j)β(t|t-1)},(j=0,1,…)
G(t)=-DIAGexp{-X(t)β(t|t-1)}
且矩阵 P(t)及 D(t)分别为正交阵和对角阵,满足
P(t)TD(t)P(t)=N(t|t-1)B(t|t-1)+M(t|t-1)X(t)TDIAG[G(t)Λ(t)Y(t)]X(t)M(t|t-1)T
则 M(t|t)=P(t)M(t|t-1),且
J(t)=P(t)TB(t|t)P(t)[P(t)TD(t)P(t)]-1M(t|t-1)X(t)TΛ(t)
第二步,计算增益矩阵 K(t)=B(t|t)-1P(t)J(t)G(t),代表为新观测值所赋的信度因子;
第四步,计算 Θ(t|t)=DIAGexp[-M(t|t)β(t|t-1)][1-K(t)Y(t)-(t|t-1)],用当前观测值与前期预测值之差 Y(t)-(t|t-1)作为状态参数更新的基础。
近似计算:Γ(t|t)=-D(t)-1B(t|t)2
另外,计算 E[β(t|t)]=M(t|t)T{-logΘ (t|t) +0.5 ×Γ (t|t)[DIAGΘ-1(t|t)]21},Var[β(t|t)]=M (t|t)T[DIAGΘ-1(t|t)]Γ (t|t)[DIAGΘ-1(t|t)]M(t|t),作为下一轮迭代的基础。
根据近似公式:
3 实例分析
为了更好地验证广义线性滤波模型的估计效果,下面引用 Taylor和 Ashe(1983)[2]的数据(表 1)对滤波迭代模型进行实证分析。
根据流量三角形数据的特点,用i表示事故年,j表示进展年,Cij表示事故年i进展j的增量赔款额,Ei表示事故年i的风险暴露。以Yij=Cij/Ei作为观测值。建立伽玛广义线性滤波模型,利用Hoerl曲线[1]构造GLM的线性响应部分。假设Yij▯Gamma(μij,λj),选用对数联结函数,μij=exp{βi0+βi1lnj+βi2j}。由于本例中的参数 βi=(βi0,βi1,βi2)T仅与事故年 i有关, 按照事故年 i(即逐行)进行滤波迭代,则Y(t)=(Yt1,Yt2,…,Yt,11-t)T,β(t)=(βt0,βt1,βt2)T,且
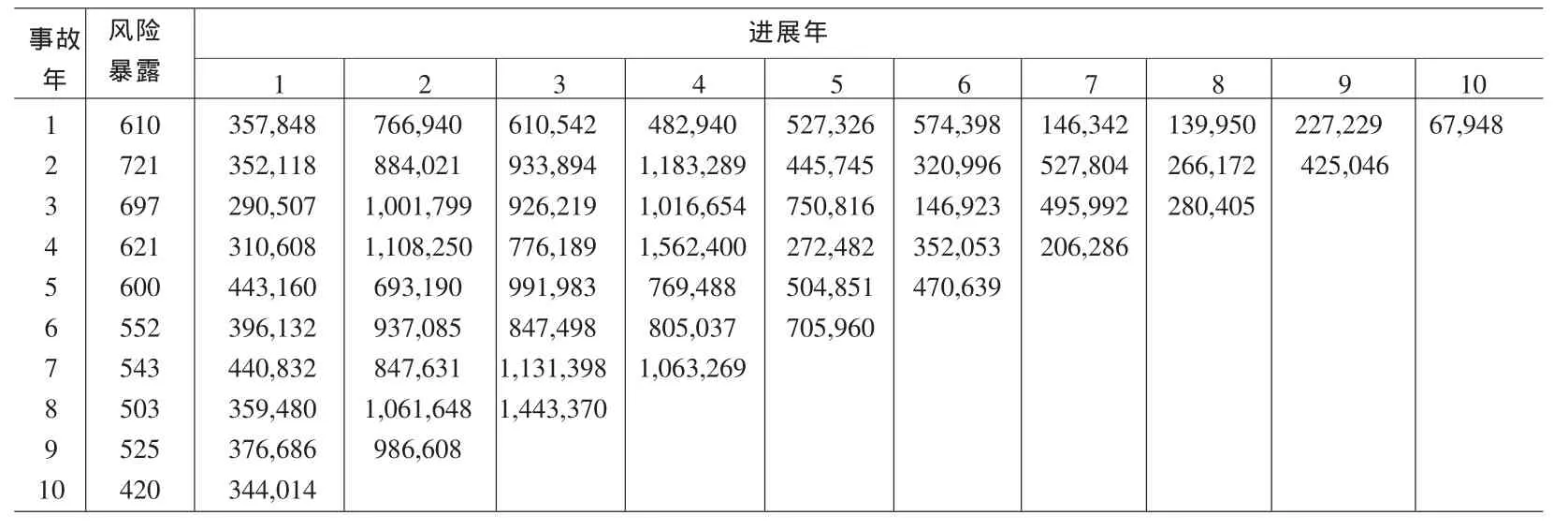
表1 增量赔款额流量三角形
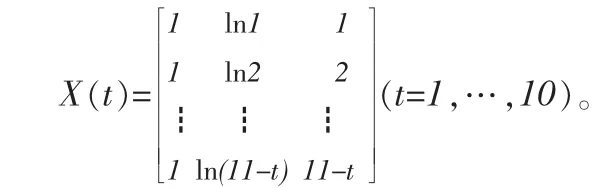
本例中 β(t) t=1,…,10 参数结构未发生变化,则 Φ(t)为单位阵。 迭代初始值 E[β(0|0)]和 Var[β(0|0)]选用伽玛GLM的参数估计结果。参数向量β的滤波估计值E[β(t|t)]如表2所示。由图2可见由于滤波模型的估计参数之间存在递推关系,各事故年的参数估计值比较平稳,反映了增益矩阵K(t)的平滑作用,降低了观测数据中异常值的影响。
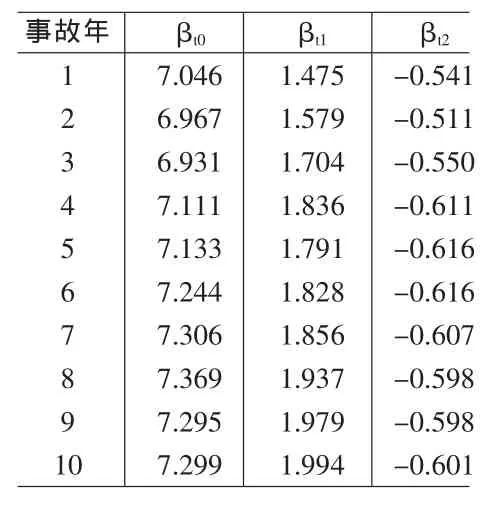
表2 滤波参数估计值
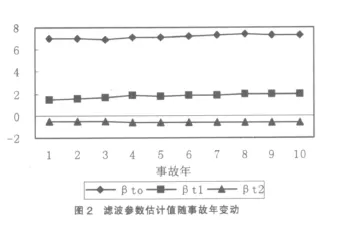

表3 准备金估计结果及稳定性比较
协方差阵Var[β(t|t)]的滤波估计结果选取了其中 4期的结果作为示例:

[1]De Jong,P.B.Zehneirth.Claims Reserving State Space Models and the Kalman Filter[J].Journal of the Institute of Actuaries,1983,(110).
[2]Taylor,G.Ashe,F.Second Moments of Estimates of Outstanding Claims[J].Journal of Economics,1983,(23).
[3]Taylor,G.Loss Reserving:An Actuarial Perspective[M].Boston:Kluwer Academic,2000.
[4]Taylor,G.Second-order Bayesian Revision of a Generalized Linear Model[J].Scandinavian Actuarial Journal,2008,(4).
[5]Taylor,G.Gráinne McGuire,Adaptive Reserving Using Bayesian Revision for the Exponential Dispersion Family[J].Variance,2009,(3).
[6]张连增.未决赔款准备金评估的随机性模型与方法[M].北京:中国金融出版社,2008.
猜你喜欢
数学物理学报(2022年3期)2022-05-25 13:33:00
工程数学学报(2020年3期)2020-07-06 07:38:40
长治学院学报(2019年2期)2019-07-24 07:14:04
中国中医急症(2019年10期)2019-05-21 07:20:28
数理化解题研究(2017年4期)2017-05-04 04:07:54
雷达学报(2017年6期)2017-03-26 07:53:04
数学年刊A辑(中文版)(2016年2期)2016-10-30 01:46:38
铁道通信信号(2016年6期)2016-06-01 12:10:20
电子器件(2015年5期)2015-12-29 08:43:15
郑州大学学报(理学版)(2014年2期)2014-03-01 04:20:49
