
基于前缀的Apriori算法
2011-05-11 11:58粟莉萍杨文伟
网络安全与数据管理 2011年4期
粟莉萍,杨文伟
(广东工业大学 计算机学院,广东 广州510006)
关联规则挖掘概念最早由Agrawal等人在1993年提出[1]。1994年,Agrawal等人建立了用于事务数据库挖掘的项集格空间理论[2],并提出了著名的Apriori算法,后其成为基本的关联规则挖掘算法。其核心原理是频繁项集的子集是频繁项集,非频繁项集的超集是非频繁项集。
关联规则挖掘算法的设计可以分解为两个子问题:
(1)找到所有支持度大于最小支持度的项集(itemset),称之为频繁项集(frequent itemset);
(2)由频繁项集和最小可信度产生规则。
其中,提高整个过程效率的关键在于提高问题(1)的效率。针对问题(1),本文对Apriori算法的实现提出了基于前缀的频繁项集挖掘算法。主要针对大型数据库,通过减少项集占用内存和分段处理,使设备资源在有限的情况下有效地实现频繁项集挖掘。
1 Apriori算法简介及评价
1.1 Apriori算法简介
Apriori算法是较为经典的关联规则挖掘算法,该算法利用逐层迭代搜索的方法挖掘数据间的关联关系。其基础思想是重复扫描数据库,根据项集格空间理论,可以由频繁k-项集迭代地产生候选(k+l)-项集;再扫描数据库验证其是否属于频繁(k+1)-项集。
1.2 相关关联规则算法的评价
由于Lk和Ck+1数目可能很大,因此涉及的判断和查找的计算量将会很大;此外多次扫描事务数据库,需要很大的I/O负载;同时,Lk和Ck+1占据的大量存储空间中,有很大一部分是重复的。
针对Apriori算法的性能瓶颈,许多的研究者在Apriori算法的基础上提出了很多解决方法;同时,也有许多研究者提出了非基于分层搜索的频繁项集挖掘算法。其中基于分层搜索的算法,主要从减少候选项集的规模并提高查找速度及扫描数据库次数和规模两方面考虑。如Park基于散列技术和事务压缩技术提出了DHP算法[4],有效缩减了2候选项集的规模和扫描事务量,减少内存消耗,但此方法对大型数据库如何合理地构建Hash桶时比较难把握。针对多次扫描数据库的问题,有人提出了基于 Tid表[5]、基于矩阵[6]、基于位阵[7]等的频繁项集挖掘算法。基于Tid表的频繁项集挖掘算法利用得到L1后重组数据库,生成频繁项集表,只需要2次访问数据库。基于矩阵、位阵的算法是利用矩阵来存储事务数据库,只需1次访问数据库,同时利用矩阵、位阵的特性,提高了运算速度。无论是基于频繁项集表,还是基于矩阵位阵的频繁项集挖掘算法,都需要占用大量内存来一次性存储频繁项集表和事务数据库。此外,对于基于频繁项集表的算法,一个重组后规模为n的事务,根据排列组合原理将生成(2n-1)个规模大于1的子集,再根据互补子集原理及栈原理,得出在最优情况下时间复杂度为O(2n),显然生成频繁项集表的时间消耗也不小。因此,此类型算法不适于大型的事务数据库。
在非基于分层搜索的算法中,主要以FP_Growth[8]算法及其各种改进算法为主。这类算法,需要2次访问数据库。通过第1次访问数据库,得到L1,并按支持度计数的递减顺序排序,再采用“分治策略”构造FP_Tree,最后由FP_Tree挖掘出频繁项集。同基于矩阵的算法一样,该算法需要大量内存空间存储FP_Tree;此外,删除某一项时,对与此相关的节点支持度计算进行调整将花掉不少时间,这主要是由于在Tree中只能由父节点直接查找子节点,而不能由子节点查找父节点。因此,对于大型数据库,此类算法也不适合。
而对于Apriori算法,可以考虑对每一轮的Lk重组项,利用SQL优化查询访问数据库,来减少了每轮扫描的事务量及提高查找速度,从而提高整体性能。
2 改进的Apriori算法
Apriori算法主要依赖于迭代性质产生频繁项集。候选(k+1)-项集 ck+1的产生是在判断频繁 k-项集 I1、I2能够连接的基础上产生的。显然,在按照单个频繁项集为一个节点的情况下,需要大部分时间来判断I1、I2是否能够连接。如果频繁项集不是很大,则这个连接也不会花很多时间;但若频繁项集很大,这个判断过程将会花费很多时间。同时,在计算候选项集计数时,也将花费很多时间用于查找频繁项集。
对方以礼相见,秦铁崖不免要客套:“幸会,幸会!前次在居庸关,未能结识贤昆仲,至今深感遗憾。今日得偿心愿,幸甚至哉!”
2.1 数据结构
Apriori算法数据结构中的类主要包括以下几种:
(1)LkSet所有候选k-项集或频繁k-项集集合,关键属性 isets为 LkISet集合,Items为当前 Lk中所有的项集合,Iflags为对应Items的简约表示,min最小支持度计数;
(2)LkISet所有第一项相同的候选k-项集或频繁k-项集集合,关键属性first为项集的第一项,nodes为LkN-ode集合;
(3)LkNode具有相同前缀(记为 pres)的候选 k-项集或频繁k-项集集合。其中LkNode还有两个关键的属性,一是rigths,是节点中所有候选项集或频繁项集的最后一项的集合体;二是degrees,是节点中所有候选项集或频繁项集的计数的集合体。
2.2 算法描述
(1)初始条件:所有事务和项集都按照一定的原则对项进行排序;扫描数据库,产生 L1、Items和 Iflags,其中Items为当前Lk中所有项的集合。
(2)根据得到的 L1,由事务数据库直接产生 C2,并对C2进行剪枝产生 L2,同时更新 Items和 Iflags。
(3)由 Lk连接产生 Ck+1:CkfromLk(begin,end)。
(4)扫描事务数据库 D,对 Ck+1计数:Updatedegrees(D);对任意 d∈D:LkfromCk(d)。 其中在 Updatedegrees(D)中首先根据Items筛选有效地数据记录,然后在根据事务的规模决定是否进入函数LkfromCk()。
(5)删除计数小于 min 的 ck+1:DeleteByMin-(begin)。
(6)更 新 Items 和 Iflags:UpdateItems()。
然后重复(3)~(6)步,直到 Lk=Ø。
以下是一些函数的具体描述:

由于大型数据库的候选项集规模庞大,若一次性得到所有候选项集,再进行剪枝,可能会受到设备的限制,因没有足够大的内存而导致OutOfMemoryError。通过增加begin、end参数,能够有效地控制当前候选项集的规模,不过这样增加了计算支持度计数时访问数据库的次数。但是,通过这些参数可以很方便地运用到分布式处理,能够使各个块互补干扰,且所有块的频繁项集之和就为整个数据库的频繁项集。在合成Ck+1的同时,删除Lk中不需要的节点。
(2)LkfromCk(d)函数用来计算事务d对Ck计数的变化。 对∀ck∈Ck,若 ck⊂d,则该项集支持度计数加 1。 其具体表述为:

(3)DeleteByMin(begin)函数用来修剪 Ck。其中参数begin用来控制iset的起始点。对于一次迭代,需要分段处理时,每一分段处理后得到的频繁项集都属于最终频繁项集,与其他分段是互补干扰的,因此begin用来确认当前分段的初始iset,这样使得这次的Updatedegrees(D)不会对前面分段产生影响,同时也提高了查找速度。其具体表述为:

3 实验及性能分析
本数据来源于http://grouplens.org网站。首先预处理数据:select user,isbn from bxxbookratings where user in(select user from bxxusers)and isbn in(select isbn from bxxbooks),最终得到记录 1 031 177条,其中共有 92 107个 user和 269 862种 book,事务的平均规模为 11.2。
运行环境:MyEclipse6.01;PC内存:2GB;绘图环境:Matlab7.0。
由于内存的消耗主要用于存储候选项集和频繁项集,因此内存消耗主要取决于当前情况下候选项集和频繁项集的个数及k值。假设当前情况下,频繁k-项集个数及节点个数分别为 Nk、Pk,候选(k+1)-项集个数节点个数分别为 Nk+1、Pk+1,改进前后的内存消耗分别记为SA、OSA,A与 OA差记为 S,则:

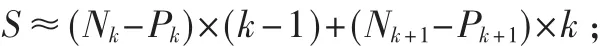
由此可知,任何情况下,改进后的Apriori算法内存消耗都不可能多于改进前的Apriori算法内存消耗;且随着事务数据库越稠密,节点个数与项集个数差越大,S越大;此外,随着 k的增加,S越大,即改进后的算法空间占用越少。因此,对比实验主要针对时间消耗进行分析。
3.1 对比实验
对于同一事物数据库,频繁项集挖掘的效率和结果主要取决于最小支持度阈值;最小支持度阈值越大,运行越快,得到的频繁项集越少。对于同一事物数据库,min越小,每次迭代产生的频繁项集和候选项集越多。图1所示为对于同一事务数据库,随min的不同,所需时间的对比情况。

对于规模相同、稠密度不同的事务数据库,在min相同时,事务数据库越稠密,每次迭代产生的频繁项集和候选项集越多。此种性质类似于同一事务数据库不同min时的性质。因此,对于不同稠密度事务数据库的比较实验,可以参照同一事物数据库不同min的比较实验。由图1可知,事务数据库越稠密,改进的 Apriori算法优势越明显。表1给出了min=12时,候选k-项集和频繁k-项集的个数及其节点个数;图2给出了min=12时,两种算法在每次迭代中各个步骤所花时间的比较情况。

表1 项集个数表
根据算法自身的特点可知,DeletebyMin()只需要一次遍历所有候选项集的支持度计数;改进后的CkfromLk()只需要一次遍历所有频繁项集,而非改进时,还需要判断两个频繁项集是否能连接,而存在某些频繁项集多次访问;Updatedegrees()与事务相关联,大量候选项集需要多次访问。结合算法的特点,从理论及实际上,证明了总体运行时间主要取决于计数步,而随着数据集越稠密,改进后的算法优势更明显。

3.2 模拟分布式处理
令 min=12、k=4,平均分为 n 段(n=1,…,8)进行分段处理,以模拟分布式处理,得到结果如图3所示。
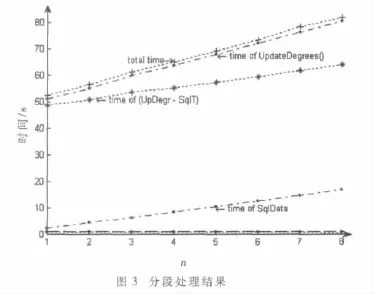
从图3看出,在一定误差范围内,剪枝步和合成候选项集并没有随着n的变化而变化;计数所花时间随着n的增加有细微的增加;访问数据库所花时间随着n的增加大而成倍数增加;总体时间的变化主要取决于访问数据库所花时间。
在深入研究Apriori算法及其相关算法的基础上,结合“桶”技术、压缩组合原理、数据重组等思想,针对大型数据库提出了基于前缀的频繁项集挖掘算法,并且根据实际情况,对频繁k-项集的产生采用了直接从数据库得出的、有别与其他频繁项集产生的特殊处理方法。理论和实验表明,改进后的Apriori算法在时间和空间上都有改进,且能够进行分段处理并运行到分布式处理中。在用于分段处理时,如何确定有分段使运行效果最优,还有待进一步研究。
[1]AGRAWAL R,IMIELINSKI T,SWAMI A.Database mining:a performance perspective[J].IEEE Transactions on Knowledge and Data Engineering,1993,5(6):914-925.
[2]AGRAWAL R,SRIKANT R.Fast algorithms for mining association rules in large databases[C].In Proc.Of the 20th Int.Conf.on Very Large Data Bases(VLDB),Santiago,Chile,Septemer,1994(2):478-499.
[3]HAN Jiawei,MICHELINE K.数据挖掘概念与技术[M].北京:机械工业出版社,2006.
[4]PARK J S,CHEN M S,YU P S.Using a hashbased method with transaction trimming for mining association rules[J].IEEE Trans on Knowledges Data Engineering,1997,9(5):813-825.
[5]向程冠,姜季春,陈梅,等.AprioriTid算法的改进[J].计算机工程与设计,2009,30(15):3581-3583.
[6]胡斌,蒋外文,蔡国民,等.基于位阵的更新最大频繁项集算法[J].计算机工程,2007,28(2):59-61.
[7]王锋,李勇华,毋国庆.基于矩阵的改进的Apriori算法[J].计算机工程与设计,2009,30(10):2435-2438.
[8]Liu Yongmei,Guan Yong.FP_growth algorithm for application in research of market basket analysis[J].Computational Cybernetics,2008.ICCC 2008.IEEE International Conference on,2008:269-272.
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
小学生学习指导(低年级)(2021年9期)2021-10-14
河南水利年鉴(2020年0期)2020-06-09
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
天津科技大学学报(2018年4期)2018-08-22
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
大连理工大学学报(2017年5期)2017-09-20
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
