
海量数据批量写库方法的研究与实现
2011-05-11 04:02韩海花王孝广刘佩贤
制造业自动化 2011年9期
韩海花,王孝广,刘佩贤,赵 燕
(1. 北京化工大学 北方学院,廊坊 065201;2. 北京中交通信科技有限公司,北京 100011)
海量数据批量写库方法的研究与实现
韩海花1,王孝广2,刘佩贤1,赵 燕1
(1. 北京化工大学 北方学院,廊坊 065201;2. 北京中交通信科技有限公司,北京 100011)
0 引言
目前,大多数应用系统的并发数据量较少,对数据库写库性能要求不高,即在小数据量并发的情况下,数据库以接收一条,分析一条,写入一条的方式入库,基本可以满足系统应用要求。但在大数据量并发情况下,由于数据库写库瓶颈的存在,写库效率大大降低。本方法将应用系统中的应用数据进行预处理和数据写入数据库的过程并行,即数据经过预处理后存入缓存,当缓存中的数据达到预设数据量时,将该数据一次性写入数据库,并将该数据从缓存中删除。此方法的数据处理速度和写入速度较快,尤其适用于海量数据并发的应用系统。
1 设计方案
该方案设计的批量写库方法采用已成熟的TCP/IP协议及数据库存储方面的知识,主要服务于应用系统相关运行模块,为应用系统产生的海量数据提供独立的数据预处理、写库服务的功能。
主要由TCP通讯组件、协议分析组件、写库管理组件、写库组件等模块构成。对外主要通过入库接口的收取应用数据,通过批量写库组件将数据实时入库。
本方法降低了应用系统与数据库之间的耦合关系;同时也为入库的操作提供数据缓冲,通过缓冲数据结构降低对数据库的海量冲击,从而提升数据库的整体运行性能。

图1 系统架构
1.1 TCP通讯组件
该组件接采用TCP协议接收来自应用系统的不同协议数据包,即将拆分为很多IP数据包的车辆GPS定位信息,按照封包序号将IP数据包重新顺序排列,并一层层剥离PDU的包头数据,提取出里面的应用数据,重构定位数据。然后采用哈希模式来实现不同包的动态分配,且哈希函数采用数字分析法来构建,即当分析一组数据,平台在较短时间内接收到的车辆GPS定位数据时,平台接收的定位点中的年、月、日、小时的这几位数据大体相同,这样的话,出现冲突的几率就会很大。但是年、月、日、小时的后几位表示分钟和秒的数据差别较大,如果用后面的数据来构成散列地址,则冲突的几率就会降低。因此采用数字分析法找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。

图2 TCP通讯组件结构
本组件主要与应用系统进行数据对接,主要实现应用程序与本方法之间按照自定协议的方式,实现数据的正常通信。
1.2 协议分析组件
本组件主要完成对接收的不同协议数据包根据不同的业务类型调用不同的业务类完成业务数据包的拆解。主要算法如下:依据字节流模式,通过字节流的解析,完成对数据包的解析。
主要分析流程过程如图3所示。

图3 协议分析组件数据分析流程
从消息流中可以看出,收到消息包后,进行消息包的header进行解析,然后,根据解析的情况进行分解业务细节。
1.3 批量写库组件
本组件主要完成将分解后的数据包,调用不同的存储过程,实现数据的入库动作。本组件主要通过独立的线程,完成数据的独立入库过程,每个写库任务对象(CWriteDataTask)对应一个独立的会话对象。写库任务对象将解析后的数据完成数据的批量入库。
批量写库类定义如下:

本组件算法主要实现将数据包写入缓冲,当缓冲满了后,则进行入库,入库的过程就是调用在数据库中已经建立好的数据库存储过程对象实现。主要过程如下:组件收到数据后,将数据依次提交到队列中,不同的业务字段提交到不同的字段队列中,然后针对不同的字段队列调用不同的业务存储过程,实现数据的批量入库。
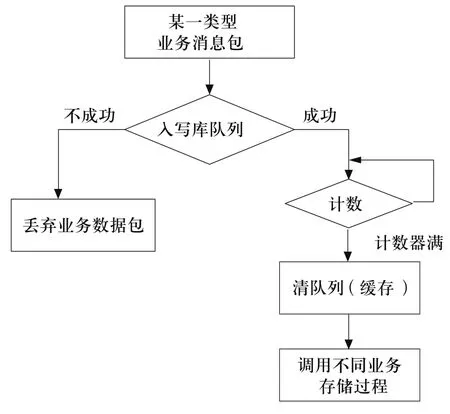
图4 批量写库组件的写库流程
2 系统测试及结果
系统测试采用20000个并发业务数据包,每个协议包由30个字节组成,按照自定义协议格式,往数据库入库接口同时发送。
方案一:insert循环插入
采用foreach循环函数,将20000条数据经解包后,采用insert into的方式,循环插入数据库中,共耗时00:00:29.7336000。
方案二:批量入库方式
采用本方案,将20000条数据,解包、处理写入缓存后,调用业务存储过程,批量插入数据库中,共耗时00:00:00.3276000。
根据上述比对结果,批量写库的方案与循环插入的方式相比,写库时间大大缩短、写库效率明显提高。
3 结论
本文所讨论的方法是项目实施过程中总结出的一种有效的大批数据录入的方法。我们在公司GPS车辆监管项目(系统设计的并发GPS数据为15000条/S)中利用此方法成功实施了大批量GPS数据的入库。实践证明在大批量数据录入时,采用本文提出批量数据插入的方法,可以大大提高数据录入效率,提高系统运行效率。
[1]汤庸,毛承洁.信息系统批量数据录入的工程方法[J].微机发展,1996,6.
[2]汤庸.教据库应用系统开发指南[M].人民邮电出版社,1996.
[3]A.Segev,J.L.Zhao. Data management for large ruleSystems.In:Proceed-ings of 17th International Conference on Very Large Data Bases.1991.
[4]Simson W.The Point-to-Point Protocol(PPP),RFC1661,July 1994.
The research of batch writing massive amounts of data and implementation of database method
HAN Hai-hua1, WANG Xiao-guang2, LIU Pei-xian1, ZHAO Yan1
本文研究了一种将海量数据写入数据库的方法,提出了一种数据处理及数据入库并行的方法,解决了海量数据写库效率较低的问题,提高了应用系统中海量数据的数据处理速度和写库速度,大幅度提高了系统的运行效率。
海量数据;写库;批量存储
韩海花(1982 -),女,山东人,助教,硕士研究生,研究方向为智能控制。
TP391
A
1009-0134(2011)5(上)-0029-03
10.3969/j.issn.1009-0134.2011.5(上).11
2010-11-01
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2021年10期)2021-11-22
科学家(2021年24期)2021-04-25
中国食品(2021年4期)2021-03-22
中国食品(2021年2期)2021-02-24
制造技术与机床(2019年11期)2019-12-04
当代陕西(2019年14期)2019-08-26
中学数学杂志(初中版)(2016年5期)2016-11-01
人间(2015年8期)2016-01-09
导航定位学报(2015年2期)2015-06-05
