
基于NLMS算法的自适应AQM控制机制的研究
2011-03-17 01:44郜亚丽李世勇
河北工程大学学报(自然科学版) 2011年2期
郜亚丽,李世勇
(1.济源职业技术学院实验实训中心,河南济源454650;2.北京交通大学 电子信息工程学院下一代互联网互联设备国家工程实验室,北京100044)
随着Intenet网络规模的迅速扩大,网络上开放的业务种类不断增加,网络应用的不断深入,导致网络吞吐量急剧降低,严重时甚至发生网络崩溃,这就是网络拥塞现象。网络拥塞已经成为制约网络发展和应用的瓶颈。随着网络规模的增大,仅仅依靠TCP拥塞控制机制来提高网络的服务质量是远远不够的,因此路由器作为网络的中间节点也必须参与到网络拥塞控制中来。近年来,主动队列管理(active queue management,简称AQM)[1]成为网络拥塞控制研究中的一个技术热点。它通过网络中间节点由控制的分组丢弃机制,实现了较低的排队延时和较高的有效吞吐量。研究人员提出了多种 AQM 算法,如 RED[2], REM[3],PI[4],LRC-RED[5]等。最早经典的当数由Floyd等于1993年提出的随机早期丢弃RED (Random Early Drop)算法。该算法是目前最常用的一种AQM算法。
RED算法以平均队列长度作为拥塞指示来控制包的丢失。在动态网络中,这些算法对突发流不敏感,使得队列长度波动较大[6]。本文通过引入加权队列长度作为拥塞指示,使用归一化最小均方(NLMS)算法,结合对分组丢弃概率的更合理的计算,将瞬时队列长度控制在一个较为稳定的范围内。并通过算法仿真实验和性能比较,验证了该算法在保持队列稳定的同时丢包率也有所降低。
1 归一化最小均方(NLMS)算法
LMS(Least mean square)中文是最小均方算法,是经典的自适应滤波器算法[7],具有实现简单,计算量小等优点。原理图如图1所示,分为波束赋形和自适应权重控制两个部分,通过迭代的方法来求解MMSE准则下的最优权重。NLMS算法是改进的LMS算法,又称为归一化最小均方算法,是采用变步长的方法来缩短自适应收敛过程。
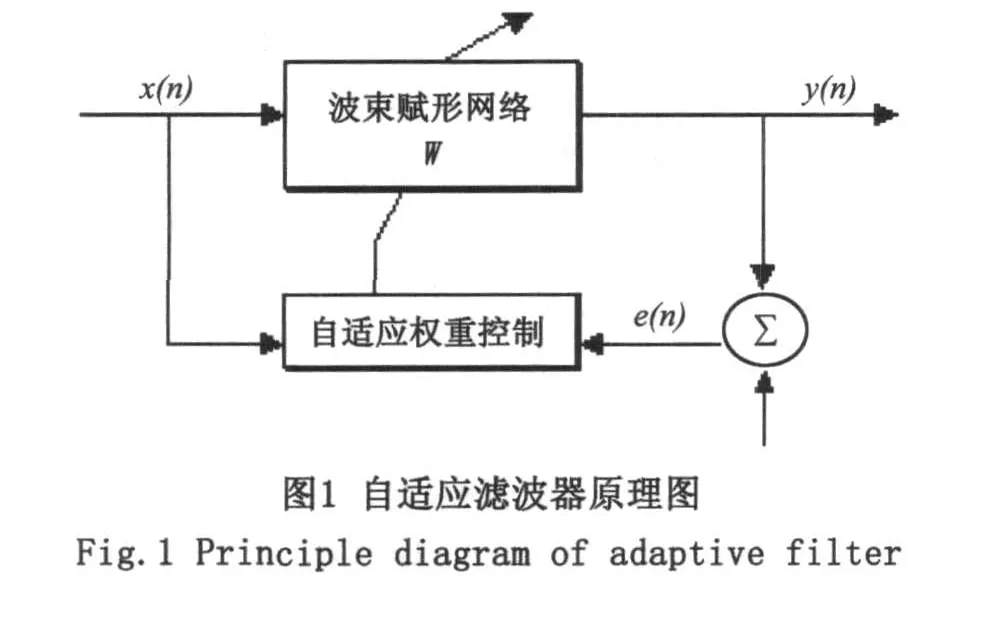
以自适应系统辨识[8]为例,x(n)是输入参考信号,y(n)是未知系统的输出信号。则自适应滤波器输出的y(n)的预估值为

式中N—滤波器的阶数;{{hi(n)|i=0,1,…,N-1}—第n次迭代后自适应滤波器的系数。


该算法在输入信号较大的情况下避免梯度噪声放大的干扰,因而具有较好的收敛性能[8]。
2 NLMS算法在主动队列管理中的实现
2.1 算法的描述
基于NLMS算法的基本原理是:引入加权队列长度作为拥塞指示,通过对过去N个时刻的瞬时队列长度信息分别赋以不同权重,并采用NLMS算法中的参数调整方法对权重自适应调整来得到加权队列长度。由于权重因子可以自适应调节,且采用了过去时刻的瞬时队列值,因此加权队列长度比RED算法中的平均队列长度更及时地反映网络流量变化情况,从而对拥塞作出反应。
算法的实现主要分三步:
第一步:计算加权队列长度。第二步:结合加权队列长度和网络负载流量进行丢包决策。第三步:采用NLMS的方法更新权值,回到第一步。
2.2 加权队列长度计算及权值更新
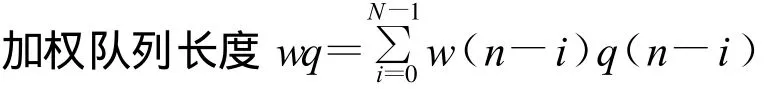
式中wq—加权队列长度;w(n-i)—过去第i个时刻的瞬时队列值所占的权重;q(n-i)—过去第i个时刻的瞬时队列值。
权重因子在加权队列长度和当前瞬时队列长度之差的基础上动态更新。误差e(n)计算为e (n)=q(n)-wq,由式(1)得到队列权重的更新

μ为NLMS的比例因子,由下式决定
式中 μ0取1得以保证收敛,a取1得以保证分母不为零。
2.3 丢包决策
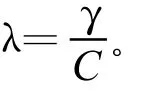
式中λ—负载因子(load factor);γ—包到达速率; C—链路的服务速率(即链路带宽)。
在进行分组丢弃概率计算时,考虑了链路负载和队列长度信息,分组的丢弃概率p计算如下

式中wq—估计的队列长度;B—缓存的大小。
通过这种概率丢弃使得(被接纳的)包到达速率与链路容量达到平衡,同时还考虑了队列长度,队列长度越长则分组被丢弃的概率也越大。
具体丢包策略如下:
3 仿真实验与性能比较
利用网络仿真软件NS-2来验证算法的性能。采用NLMS(实验中称为NAQM)算法、RED算法、REM算法、LRC-RED算法进行仿真比较。实验环境为多瓶颈链路,实验网络拓扑结构如图2所示。在图2中,从左到右的五条链路带宽均为15M,延时20ms。sender为发送端,receiver为接收端。其中,senderl到 receiverl是 100个TCP流, sender2到receiver2是30个TCP流,sender3到receiver3是30个TCP流。在实验中,瓶颈链路r2-r3的特性和r4-r5的特性类似,而链路r1-r2、r3 -r4、r5-r6基本不会出现拥塞。因此仅分析r2-r3之间的性能。
3.1 负载固定情况下的性能
实验中,考虑随时间变化负载固定的情况下,考察各算法在队列长度的稳定性、丢包率大小的变化。其中,sendersl,senders2,senders3分别同时启动100个,30个,30个TCP连接,仿真时间为50s。下面是各种性能指标的仿真结果。
队列长度的变化。图3所示的是在负载固定的情况下,各算法在维持队列稳定性方面的性能。由图中四种算法的对比可以看出,在多瓶颈链路中,NAQM算法能够很好的维持在200附近,并且波动较小,因此稳定性也最好。LRC-RED算法的队列长度也基本保持在200附近,但队列的波动比NAQM算法稍大一些。RED算法所维持的队列长度波动较大。REM算法基本处于满队列,无法保持在期望值附近,且波动大。由此可见,在多瓶颈链路中,负载固定时,NAQM算法所表现出的性能是最好的,其队列最稳定,能够很好的保持在期望值附近,队列波动小,且响应时间短。
丢包率的变化。表1所示为静态情况下节点r2-r3之间的链路的各算法丢包率。通过表中四个算法的比较,RED与NAQM算法的丢包率较为接近,约为3.3%左右。其次是LRC-RED,丢包率最大的是REM算法。
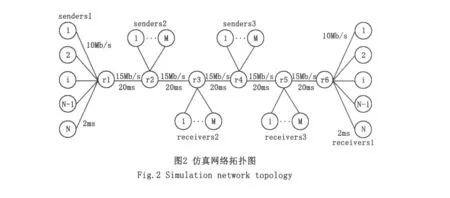

表1 静态时各算法在链路r2-r3之间的丢包率Tab.1 The packet loss rate of each algorithm between link r2 and link r3 in static state


3.2 负载变化环境下的性能
实验中,考虑负载随时间变化的情况下,考察各算法在队列长度的稳定性、丢包率大小的变化方面的性能。其中,sendersl分别在0s,5s,10s,20s, 30s启动20组TCP连接,senders2、senders3分别在0s启动30组TCP连接,仿真时间为50s。下面是各种性能指标的仿真结果。

表2 动态时各算法在链路r2-r3之间的丢包率Tab.2 The packet loss rate of each algorithm between link r2 and link r3 in dynamic state
队列长度的变化。图4所示的是在负载变化的情况下,各算法在维持队列稳定性方面的性能。由图中四种算法的对比可以看出,在动态多瓶颈链路中,NAQM算法能够很好地维持在200附近,并且波动较小。LRC-RED算法次之,RED算法的队列长度波动较大,并且在每次增加负载时,队列有波动。REM算法基本处于满队列,无法保持在期望值附近。由此可见,在多瓶颈链路中,负载变化时,NAQM算法所表现出的性能是最好的,其队列最稳定,能够很好地保持在期望值附近,队列波动小,且响应时间较短。
丢包率的变化。表2所示为动态情况下节点r2-r3之间链路的各算法丢包率。通过表中四个算法的比较,RED算法的丢包率最小,REM和NAQM算法的丢包率相近,约为2.8%左右。丢包率最大的是LRC-RED算法,约为3.2%左右。
4 结论
1)主动队列管理在保证高吞吐量的同时,能有效控制缓冲队列的长度,减小网络时延。
2)采用归一化最小均方(Normal Least Mean Square,NLMS)的方法对权值自适应调整,结合负载因子对分组进行更为合理的丢弃,将队列长度的变化稳定在一个理想的水平。
3)仿真实验表明该算法具有较好的动静态性能,且能提高队列稳定性,降低丢包率。尤其在多瓶颈链路中,算法的队列稳定性最好。
[1]朱小艳,李向丽.主动式队列管理(AQM)算法研究[J].微计算机信息,2006(1):2-3.
[2]魏涛,张顺颐.一种模糊自调整的PD-RED算法[J].计算机工程与应用,2007,43(5):124-126.
[3]苏聪,陈元琰,罗晓曙.基于模糊理论的主动队列管理算法-FBLUE[J].计算机工程与应用,2006,42(23):117-120.
[4]朱华,向少华.一种模糊自适应PI算法在网络拥塞控制中的应用[J].大众科技,2009,123(11):32-34.
[5]任丰原,林闯,刘卫东.IP网络中的拥塞控制[J].计算机学报,2003,26(9):1025-1034.
[6]薛质,潘理,李建华.基于模糊RED算法的IP拥塞控制机制[J].计算机工程,2002,28(3):60-61.
[7]谷源涛,唐 昆,崔慧娟,等.变步长归一化最小均方算法[J].清华大学学报(自然科学版),2002,42(1):15 -18.
[8]HAYKIN S.自适应滤波器原理(第三版)[M].北京:电子工业出版社,1998.
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
舰船科学技术(2022年10期)2022-06-17
计算机与数字工程(2022年1期)2022-02-16
农业工程与装备(2021年1期)2021-05-17
今日中国·法文版(2020年7期)2020-07-04
中国环境监察(2016年11期)2016-10-24
中国卫生(2016年1期)2016-01-24
铁道科学与工程学报(2015年4期)2015-12-24
中国卫生(2015年4期)2015-11-08
电力建设(2015年2期)2015-07-12
